 http协议相关
http协议相关
# HTTP
# 名称说明
# URI
即统一资源标识符,服务器上每一种资源,比如文档、图像、视频片段、程序 都由一个通用资源标识符(Uniform Resource Identifier, 简称"URI")进行定位。
# 概念及发展历史
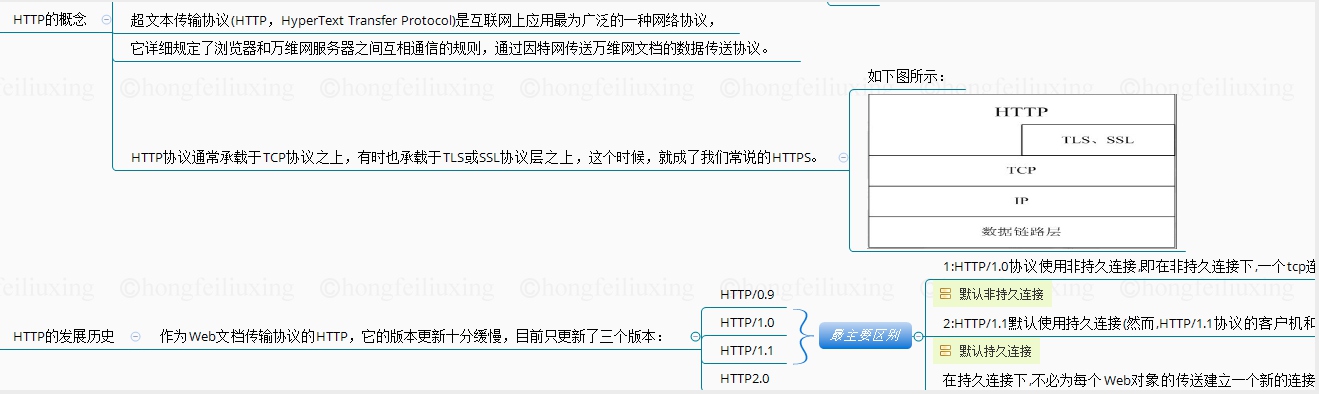
# http版本的比较【要点】
| 版本 | 内容 |
|---|---|
| http0.9 | 只允许客户端发送 GET 这一种请求;且不支持请求头,协议只支持纯文本;无状态性,每个访问独立处理,完成断开;无状态码 |
| http1.0 | 解决 0.9 的缺点,增加 If-modify-since(last-modify)和 expires 缓存属性 |
| http1.x | 增加keep-alive, cache-control 和 If-none-match(etag)缓存属性 |
| http2.0 | 采用二进制格式传输;多路复用;报头压缩;服务器推送 |
| http3.0 | 采用 QUIC 协议,自定义连接机制;自定义重传机制;无阻塞的多路复用 |
# HTTP 0.9
- 只允许客户端发送 GET 这一种请求;
- 且不支持请求头,协议只支持纯文本;
- 无状态性,每个访问独立处理,完成断开;
- 无状态码。
# HTTP 1.0
有身份认证,三次握手; 请求与响应支持头域; 请求头内容;
| 属性名 | 含义 |
|---|---|
| Accept | 可接受的 MIME 类型 |
| Accept-Encoding | 数据可解码的格式 |
| Accept-Language | 可接受语言 |
| Connection | 值 keep-alive 是长连接 |
| Host | 主机和端口 |
| Pragma | 是否缓存,指定 no-cache 返回刷新 |
| Referer | 页面路由 |
| If-Modified-Since | 值为时间 |
响应头内容;
| 属性名 | 含义 |
|---|---|
| Connection | 值 keep-alive 是长连接 |
| Content-Type | 返回文档类型,常见的值有 text/plain,text/html,text/json |
| Date | 消息发送的时间 |
| Server | 服务器名字 |
| Last-Modified | 值为时间,s 返回的最后修改时间 |
| Expires | 缓存过期时间,b 和 s 时间做对比 |
注意
- expires 是响应头内容,返回一个固定的时间, 缺陷是时间到了服务器要重新设置;
- 请求头中如果有 If-Modified-Since,服务器会将时间与 last-modified 对比,相同返回 304;
- 响应对象以一个响应状态行开始;
- 响应对象不只限于超文本;
- 支持 GET、HEAD、POST 方法;
- 有状态码;
- 支持长连接(但默认还是使用短连接)、缓存机制以及身份认证。
# HTTP 1.1
请求头增加 Cache-Control, If-None-Match
| 属性名 | 含义 |
|---|---|
| Cache-Control | 在1.1 引入的方法,指定请求和响应遵循的缓存机制,值有:public(b 和 s 都缓存),private(b 缓存),no-cache(不缓存),no-store(不缓存),max-age(缓存时间,s 为单位),min-fresh(最小更新时间),max-age=3600 |
| If-None-Match | 上次请求响应头返回的 etag 值响应头增加 Cache-Control,表示所有的缓存机制是否可以缓存及哪种类型 etag 返回的哈希值,第二次请求头携带去和服务器值对比 |
注意: Cache-Control 的 max-age 返回是缓存的相对时间 Cache-Control 优先级比 expires 高; 缺点:不能第一时间拿到最新修改文件
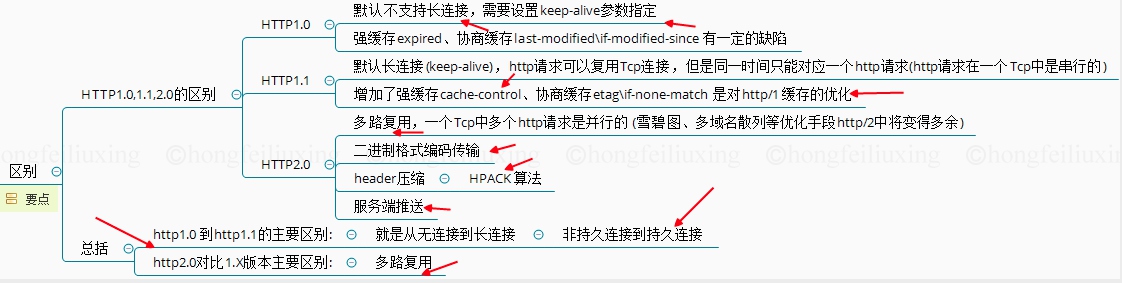
# HTTP 2.0
# http2 与 http1.1 有什么不同
- 采用二进制格式传输; 分帧传输;
- 多路复用,其实就是将请求数据分成帧乱序发送到 TCP 中。TCP 只能有一个 steam,所以还是会阻塞;
- 报头压缩;
- 服务器推送主动向 B 端发送静态资源,避免往返延迟。(server push)
HTTP/2主要的目标就是改进性能,兼容HTTP/1.1
问题1: HTTP/1.1 中只优化了 body ( gzip 压缩)并没有对头部进行处理
问题2: HTTP/1.1 问题在于当前请求未得到响应时,不能复用通道再次发送请求。需要
开启新的TCP连接发送请求这就是我们所谓的管线化,但是后续的响应要遵循FIFO原则,如果第一个请求没有返回会被阻塞 **HTTP****队头阻塞问题。 (最多并发的请求是6个)
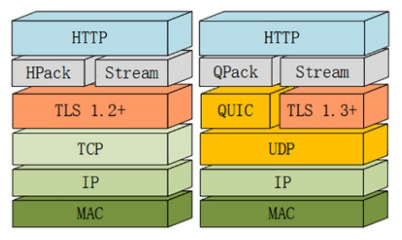
# HTTP 3.0
是基于 QUIC 协议,基于 UDP; HTTP/3 目前还处于草案阶段;
HTTP2 帧中需要封装流, HTTP3 则可以直接使用 Quic 里的stream
特点:
自定义连接机制:TCP 以 IP/端口标识,变化重新连接握手,UDP 是一 64 位 ID 标识,是无连接;自定义重传机制:TCP 使用序号和应答传输,QUIC 是使用递增序号传输;无阻塞的多路复用:同一条 QUIC 可以创建多个 steam。
解决TCP中队头阻塞问题
TCP为了保证可靠传输,如果在传输的过程中发生丢包,可能此时其他包已经接受完毕,但是仍要等待客户端重传丢失的包。这就是TCP协议本身队头阻塞的问题。
QUIC 协议
HTTP/3中关键的改变,那就是把下层的 TCP 换成了 UDP 。 UDP 无序从而解决了队头
阻塞的问题
- QUIC 基于 UDP 之前说过 UDP 是无连的,接速度比 TCP 快
- QUIC 基于 UDP 实现了可靠传输、流量控制,引入流和多路复用
- QUIC 全面采用加密通信, QUIC 使用了 TLS 1.3,首次连接只需要 1RTT
- 支持链接迁移,不受 IP 及 port 影响而发生重连,通过 ConnectionID 进行链接
- 使用 QPACK 进行头部压缩, HPACK 要求传输过程有序(动态表),会导致队头阻塞。
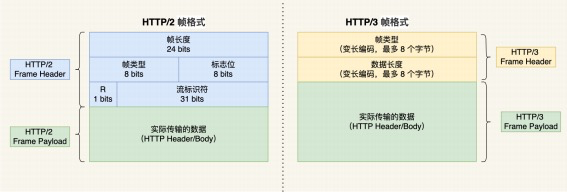
# HTTP2与HTTP3格式比较
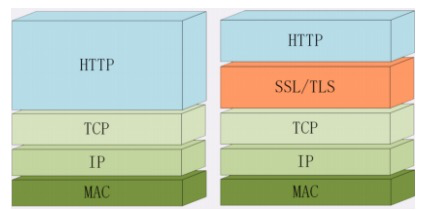
# HTTPS
- 1.https 是在 http 协议的基础上加了个 SSL;
- 2.主要包括:握手(凭证交换和验证)和记录协议(数据进行加密)。
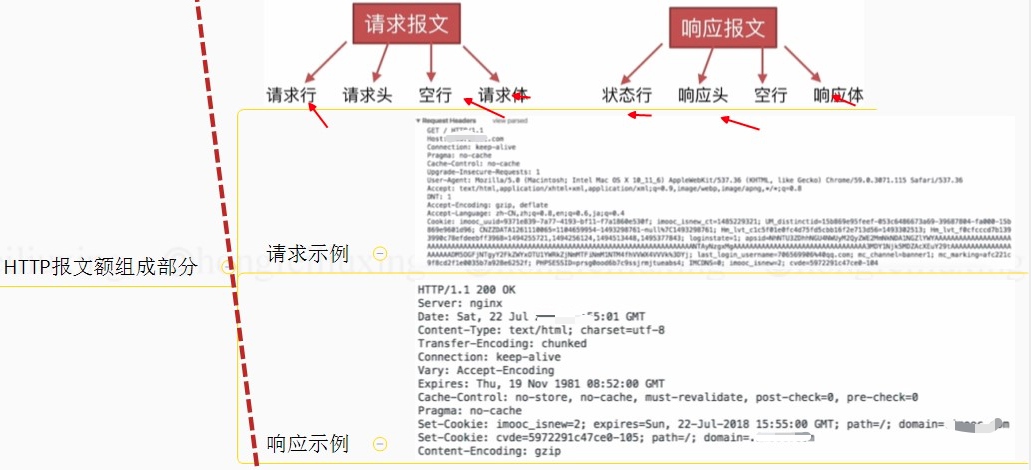
# 报文格式、请求及响应示例
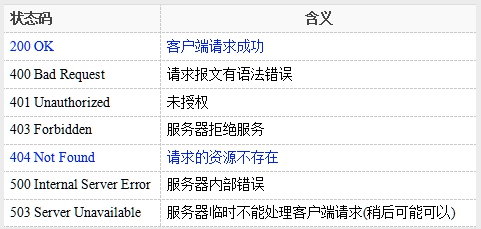
# HTTP状态码【要点】
# 比较分类
| 序列 | 详情 |
|---|---|
| 1XX(通知) | 代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束。101 Switching Protocols |
| 2XX(成功) | 200(成功)、201(服务器创建)、202(服务器接收未处理)、203(非授权信息)、204(未返回内容)、205(重置内容)、206(部分内容) |
| 3XX(重定向) | 301(永久移动)、302(临时移动)、303(查看其他位置)、304(未修改)、305(使用代理)、307(临时重定向) |
| 4XX(客户端错误) | 400(错误请求)、401(未授权)、403(禁止)、404(未找到)、405(方法禁用)、406(不接受)、407(需要代理授权) |
| 5XX(服务器错误) | 500(服务器异常)、501(尚未实施)、502(错误网关)、503(服务不可用)、504(网关超时)、505(HTTP 版本不受支持) |
总括:
- 1xx:指示信息–表示请求已接收,继续处理。
- 2xx:指示成功–表示请求已被成功接收、理解、接受。
- 3xx:指示重定向–要完成请求必须进行更进一步的操作。
- 4xx:指示客户端错误–请求有语法错误或请求无法实现。
- 5xx:指示服务器端错误–服务器未能实现合法的请求。

# 常见的状态码
- 200 表示请求成功, 最喜欢见到的状态码
- 201 (Created)【post请求】
- 204 未返回内容【put请求】
- 301 永久重定向;一般是用在域名换了;http升级到https;
- 302 临时重定向;一般是访问某个网站的资源需要权限时,会需要用户去登录,跳转到登录页面之后登录之后,还可以继续访问。
- 304 自上次请求,未修改的文件
- 400 错误的请求
- 401 未被授权,需要身份验证,例如token信息等等
- 403 请求被拒绝
- 404 资源缺失,接口不存在,或请求的文件不存在等等
- 405 (Method Not Allowed)
- 422 参数有误
- 500 服务器端的未知错误
- 502 网关错误;收到了上游响应但无法解析
- 503 服务暂时无法使用
- 504 网关超时;上游响应超时
# 特殊状态码
- 301:请求的资源被永久转移到其他地方(重定向);
- 302:临时转移;
- 501, 505(koa中有处理)
- 206:range范围请求; range范围请求【206】;显示一个请求文件的多少行 模拟: `curl -r 0-10 http://127.0.0.1:9527/LICENSE (10行)
- 304:缓存(新鲜度) Request Headers跟 Response Headers 中的 Last-Modified/ETag一样,才确保是新鲜的304;
# http 状态码中 301,302和307有什么区别
301,Moved Permanently。永久重定向,该操作比较危险,需要谨慎操作:如果设置了301,但是一段时间后又想取消,但是浏览器中已经有了缓存,还是会重定向。
302,Fount。临时重定向,但是会在重定向的时候改变 method: 把 POST 改成 GET,于是有了 307
307,Temporary Redirect。临时重定向,在重定向时不会改变 method
# http 状态码 502 和 504 有什么区别
- 502 Bad Gateway The server was acting as a gateway or proxy and received an invalid response from the upstream server. 收到了上游响应但无法解析
- 504 Gateway Timeout The server was acting as a gateway or proxy and did not receive a timely response from the upstream server. 上游响应超时
# http 向 https 做重定向应该使用哪个状态码
一般用作 301 的较为多,但是也有使用 302,如果开启了 HSTS 则会使用 307
如知乎使用了 302,淘宝使用了 301;
$ curl --head www.zhihu.com
HTTP/1.1 302 Found
Date: Tue, 24 Dec 2019 00:13:54 GMT
Content-Length: 22
Connection: keep-alive
Server: NWS_TCloud_IPV6
Location: https://www.zhihu.com/
X-NWS-LOG-UUID: 0e28d9a1-6aeb-42cd-9f6b-00bd6cf11500
$ curl --head www.taobao.com
HTTP/1.1 301 Moved Permanently
Server: Tengine
Date: Tue, 24 Dec 2019 00:13:58 GMT
Content-Type: text/html
Content-Length: 278
Connection: keep-alive
Location: https://www.taobao.com/
Via: cache20.cn1480[,0]
Timing-Allow-Origin: *
EagleId: 6f3f38a815771464380412555e
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# HTTP动词
常用的HTTP动词有下面五个
- GET(SELECT):从服务器取出资源(一项或多项)。//200
- POST(CREATE):在服务器新建一个资源。//201
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。//204
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
# 几种请求方法
GET、POST、PUT、DELETE、HEAD、CONNECT、OPTIONS、TRACE;
常用的5+1种【CRUD操作+ H+P】
| methods | CRUD | 幂等 | 缓存 |
|---|---|---|---|
| GET | Read | ✓ | ✓ |
| POST | Create | ||
| PUT | Update/Replace | ✓ | |
| PATCH | Update/Modify | ||
| DELETE | Delete | ✓ |
# POST 和 PUT 的区别
POST 是新建 (create) 资源, 非幂等, 同一个请求如果重复 POST 会新建多个资源. PUT 是 Update/Replace, 幂等, 同一个 PUT 请求重复操作会得到同样的结果.
# get和post区别
| 请求方式 | GET | POST |
|---|---|---|
| 参数位置 | 参数拼接到url的后面 | 参数在请求体中 |
| 参数大小 | 受限于浏览器url大小,一般不超过32K | 1G |
| 服务器数据接收 | 接收1次 | 根据数据大小,可分多次接收 |
| 适用场景 | 从服务器端获取数据 | 向服务器提交数据 |
| 安全性 | 参数携带在url中,安全性低 | 相对于GET请求,安全性更高 |
接触 RESTful 才意识到, 这两个东西最根本的差别是语义, 引申了看, 协议 (protocol) 这种东西就是人与人之间协商的约定, 什么行为是什么作用都是"约定"好的, 而不是强制使用的, 非要把 GET 当 POST 这样不遵守约定的做法我们也爱莫能助. 简而言之, 讨论这二者的区别最好从 RESTful 提倡的语义角度来讲_image/02.http协议相关_image/02.http协议相关比较符合当代程序员的逼格_image/02.http协议相关_image/02.http协议相关比较合理.
# get请求传参长度的误区
误区:我们经常说get请求参数的大小存在限制,而post请求的参数大小是无限制的。
强调下面几点:
- HTTP 协议 未规定 GET 和POST的长度限制;
- GET的最大长度显示是因为 浏览器和 web服务器限制了 URI的长度;
- 不同的浏览器和WEB服务器,限制的最大长度不一样;
- 要支持IE,则最大长度为2083byte,若只支持Chrome,则最大长度 8182byte;
//MAX_GET_URL_LENGTH: 2048,
var doGetAsPost = function(opt) {
var delimiterPos = opt.url.indexOf('?');
var fieldsIndex = opt.url.indexOf('&fields');
opt.type = "POST";
opt.headers["X-Http-Method-Override"] = "GET";
if (delimiterPos !== -1) {
var query = fieldsIndex !== -1 ? opt.url.substring(delimiterPos + 1, fieldsIndex) : opt.url.substr(delimiterPos + 1);
opt.data = JSON.stringify({
"RequestInfo": {"query" : query}
});
if (fieldsIndex !== -1) {
opt.url = opt.url.substr(0, delimiterPos) + '?' + opt.url.substr(fieldsIndex + 1) + '&_=' + App.dateTime();
} else {
opt.url = opt.url.substr(0, delimiterPos) + '?_=' + App.dateTime();
}
} else {
opt.url += '?_=' + App.dateTime();
}
return opt;
};
if (opt.url && opt.url.length > this.get('MAX_GET_URL_LENGTH')) {
opt = doGetAsPost(opt);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# get和post在缓存方面的区别
- get请求类似于查找的过程,用户获取数据,可以不用每次都与数据库连接,所以可以使用缓存。
- post不同,post做的一般是修改和删除的工作,所以必须与数据库交互,所以不能使用缓存。因此get请求适合于请求缓存。
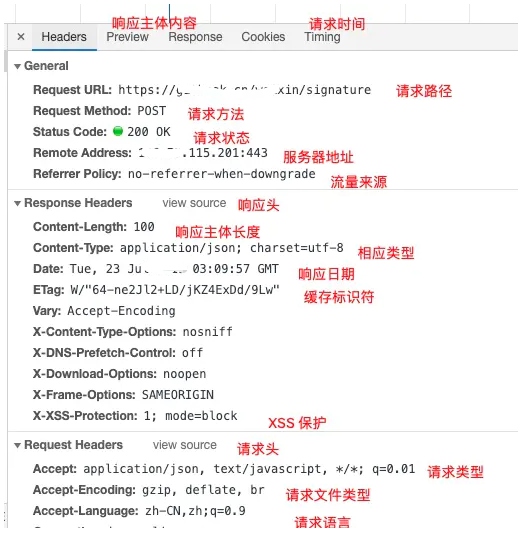
# 请求响应头说明
常用请求头:1.请求和响应报文的通用Header; 2.常用的响应Header; 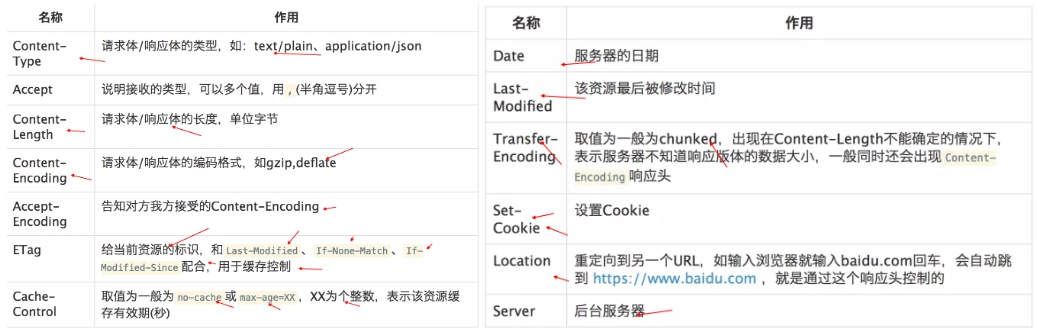
# Cookie
Set-Cookie/Cookie用户第一次访问服务器的时候,服务器会写入身份标识,下次再请求的时候会携带 cookie 。通过Cookie可以实现有状态的会话
# 管线化
如果值创建一条 TCP 连接来进行数据的收发,就会变成 "串行" 模式,如果某个请求过慢就会发生阻塞问题。 Head-of-line blocking, HTTP/1.1中采用了管线化的方式,对一个域名同时发起多个长连接实现并发。 默认 chrome 为6个。同一个域名有限制,那么我就多开几个域名 域名分片
# 长链接Keep-Alive
# 要点
- HTTP Keep-Alive 简单说就是保持当前的TCP连接,避免了重新建立连接。
- HTTP 长连接不可能一直保持; 例如
Keep-Alive: timeout=5, max=100,表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开。 - HTTP 是一个无状态协议,这意味着每个请求都是独立的,Keep-Alive 没能改变这个结果。另外,Keep-Alive也不能保证客户端和服务器之间的连接一定是活跃的,在 HTTP1.1 版本中也如此。唯一能保证的就是当连接被关闭时你能得到一个通知,所以不应该让程序依赖于 Keep-Alive 的保持连接特性,否则会有意想不到的后果。
# 使用长连接后,客户端、服务器如何知道本次传输结束?(两部分)
判断传输数据是否达到了Content-Length 指示的大小;
动态生成的文件没有 Content-Length ,它是分块传输(chunked),这时候就要根据 chunked 编码来判断,chunked 编码的数据在最后有一个空 chunked 块,表明本次传输数据结束
# 作用
在 http 1.1 中,在响应头中设置 keep-alive 可以在一个 TCP 连接上发送多个 http 请求
- 避免了重开 TCP 连接的开销; 刷新时重新建立 SSL 连接的开销
- 避免了QPS过大时,服务器的连接数过大;
- 解决无连接和无状态;
- 无连接:可以通过自身属性 Keep-Alive。
- 无状态:HTTP 协议本身无法解决这个状态,只有通过 cookie 和 session 将状态做贮存,常见的场景是登录状态保持;
在服务器端使用响应头开启 keep-alive; 但是,keep-alive并不是免费的午餐,长时间的tcp连接容易导致系统资源无效占用。配置不当的keep-alive,有时比重复利用连接带来的损失还更大。所以,正确地设置keep-alive timeout时间非常重要。
Connection: Keep-Alive
Keep-Alive: timeout=5, max=1000
#表示这个TCP通道可以保持5秒,max=100,表示这个长连接最多接收100次请求就断开
2
3
# 处理长连接的方式
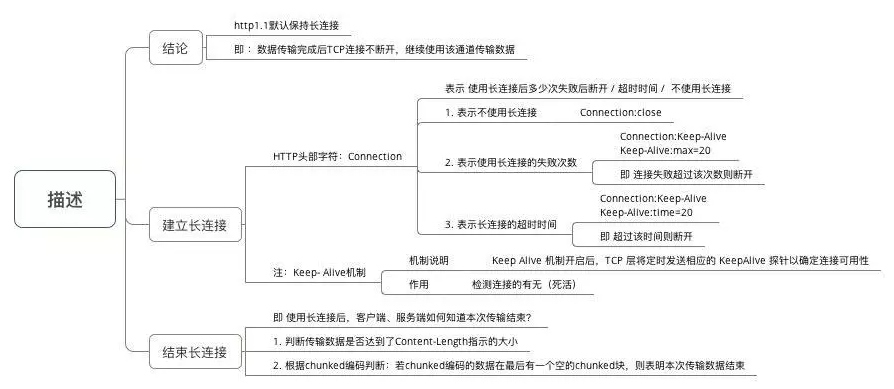
# 既然 http 是无状态协议,那它是如何保持登录状态
通过 cookie 或者 Authorization header 来传递凭证,在服务端进行认证
# 如何从 http 的报文中得知该服务使用的技术栈
一般有两个 response header,有时服务端为了隐蔽自己真实的技术栈会隐蔽这两个字段
X-Powerd-ByServer
可在nginx中关闭屏蔽这几个字段;
# content-type
如果 content-type 为 application/octet-stream, 代表二进制流,一般用以下载文件;
'content-type': 'application/x-www-form-urlencoded'// Is set automatically
'content-type': 'multipart/form-data'
// res.setHeader('Content-Type', 'text/plain');
res.setHeader('Content-Type', 'text/html');
2
3
4
5
# 编码格式
服务端返回压缩包的时候告诉浏览器一声,这其实是一个gz压缩包,浏览器你使用前先解压一下。而这个通知就是我们之前判断是否开启gzip压缩的请求头字段,Response Headers里的 content-encoding: gzip。req.headers['accept-encoding'] // gzip deflate
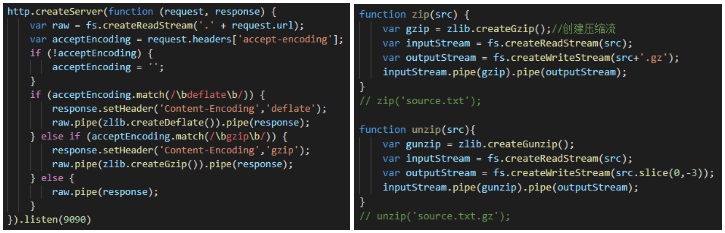
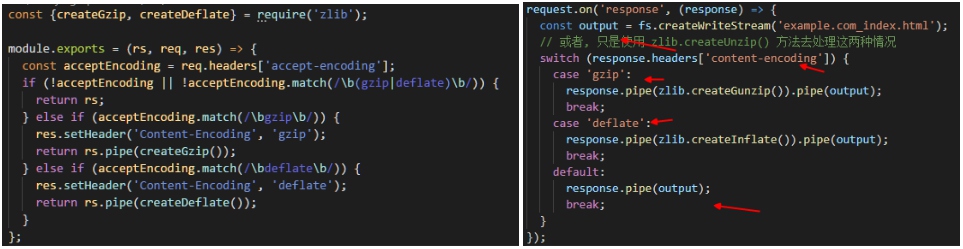
const {createGzip, createDeflate} = require('zlib');
module.exports = (rs, req, res) => {
const acceptEncoding = req.headers['accept-encoding'];
if (!acceptEncoding || !acceptEncoding.match(/\b(gzip|deflate)\b/)) {
return rs;
} else if (acceptEncoding.match(/\bgzip\b/)) {
res.setHeader('Content-Encoding', 'gzip');
return rs.pipe(createGzip());
} else if (acceptEncoding.match(/\bdeflate\b/)) {
res.setHeader('Content-Encoding', 'deflate');
return rs.pipe(createDeflate());
}
};
2
3
4
5
6
7
8
9
10
11
12
13
const fs = require('fs');
const path = require('path');
const Handlebars = require('handlebars');
const promisify = require('util').promisify;
const stat = promisify(fs.stat);
const readdir = promisify(fs.readdir);
const mime = require('./mime');
const compress = require('./compress');
const range = require('./range');
const isFresh = require('./cache');
const tplPath = path.join(__dirname, '../template/dir.tpl');
// const source = fs.readFileSync(tplPath, 'utf-8');
const source = fs.readFileSync(tplPath);//toString()
const template = Handlebars.compile(source.toString());
module.exports = async function (req, res, filePath, config) {
try {
const stats = await stat(filePath);
if (stats.isFile()) {
const contentType = mime(filePath);
res.setHeader('Content-Type', contentType);
if (isFresh(stats, req, res)) {//缓存【304】
res.statusCode = 304;
res.end();
return;
}
let rs;
const { code, start, end } = range(stats.size, req, res);
if (code === 200) {
res.statusCode = 200;
rs = fs.createReadStream(filePath);
} else {// range范围请求【206】;显示一个请求文件的多少行
// 模拟:curl -r 0-10 http://127.0.0.1:9527/LICENSE (10行)
res.statusCode = 206;
rs = fs.createReadStream(filePath, { start, end });
}
if (filePath.match(config.compress)) {//压缩 compress: /\.(html|js|css|md)/,
rs = compress(rs, req, res);
}
rs.pipe(res);//要点
} else if (stats.isDirectory()) {
const files = await readdir(filePath);
res.statusCode = 200;
// res.setHeader('Content-Type', 'text/plain');
res.setHeader('Content-Type', 'text/html');
const dir = path.relative(config.root, filePath);
// this渲染
const data = {
title: path.basename(filePath),
dir: dir ? `/${dir}` : '',
files: files.map(file => {
return {
file,
icon: mime(file)
}
})
};
res.end(template(data));
}
} catch (ex) {
console.error(ex);
res.statusCode = 404;
res.setHeader('Content-Type', 'text/plain');
res.end(`${filePath} is not a directory or file\n ${ex.toString()}`);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
# 完整的HTTP的工作流程【要点】
输入网址到显示网页的过程, 打开浏览器从输入网址到网页呈现在大家面前,背后原理;
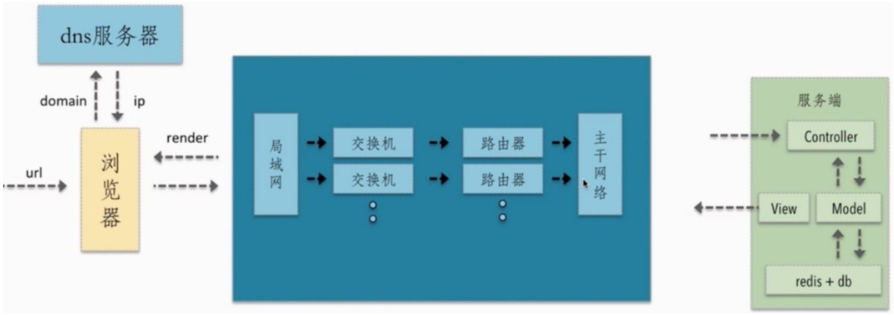 总体流程图,具体步骤请看下文分解!总体来说分为以下几个过程:
总体流程图,具体步骤请看下文分解!总体来说分为以下几个过程:
域名解析过程,三次握手过程,发起HTTP请求,响应HTTP请求并得到HTML代码,浏览器解析HTML代码,浏览器对页面进行渲染呈现给用户;
在浏览器中输入url地址 ->> 显示主页的过程
打开一个网页,整个过程会使用哪些协议
域名解析过程:和三次握手过程; SEQ和ACK,序列号与确认号
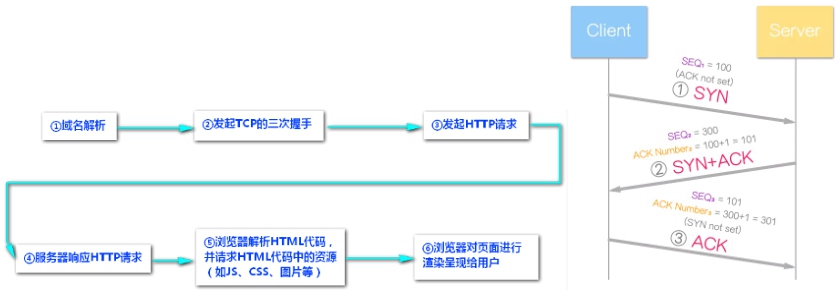
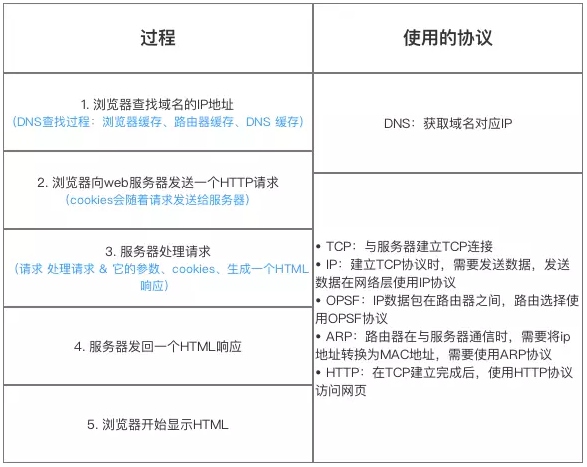
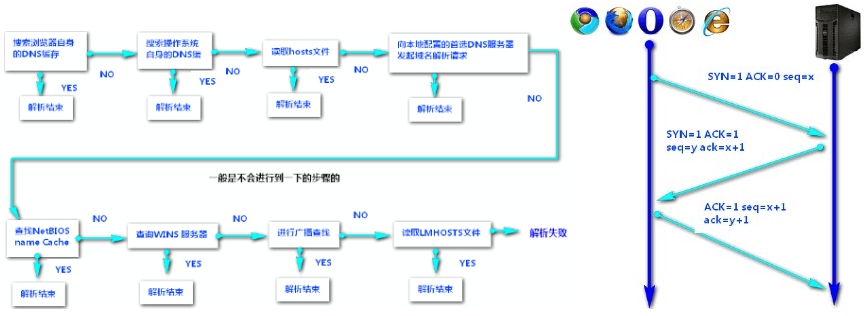
# 从URL输入到页面展现内部过程(8步)
总体流程:(八部曲):谐音 **【输缓域三,请响解四】
浏览器的地址栏输入URL并按下回车;
浏览器查找当前URL是否存在缓存,并比较缓存是否过期;
DNS 解析: 将域名解析成 IP 地址;
根据IP建立TCP连接(三次握手);
发送 HTTP 请求;
服务器处理请求,浏览器接收HTTP响应。
浏览器通过渲染引擎将网页呈现在用户面前。
- 根据 HTML 解析出 DOM 树
- 根据 CSS 解析生成 CSS 规则树
- 结合 DOM 树和 CSS 规则树,生成渲染树
- 根据渲染树计算每一个节点的信息
- 根据计算好的信息绘制页面
断开TCP连接:TCP 四次挥手 ;
详细步骤:
TCP 三次握手结束后,开始发送 HTTP 请求报文。 请求报文由请求行(request line)、请求头(header)、请求体
1.请求行包含请求方法、URL、协议版本
2.请求头包含请求的附加信息,由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。 比如:Host,表示主机名,虚拟主机;Connection,HTTP/1.1 增加的,使用 keepalive,即持久连接,一个连接可以发多个请求;User-Agent,请求发出者,兼容性以及定制化需求。
3.请求体,可以承载多个请求参数的数据,包含回车符、换行符和请求数据,并不是所有请求都具有请求数据
首先浏览器发送过来的请求先经过控制器,控制器进行逻辑处理和请求分发,接着会调用模型,这一阶段模型会获取 redis db 以及 MySQL 的数据,获取数据后将渲染好的页面,响应信息会以响应报文的形式返回给客户端,
最后浏览器通过渲染引擎将网页呈现在用户面前。
- 根据 HTML 解析出 DOM 树
- 根据 CSS 解析生成 CSS 规则树
- 结合 DOM 树和 CSS 规则树,生成渲染树
- 根据渲染树计算每一个节点的信息
- 根据计算好的信息绘制页面
当数据传送完毕,需要断开 tcp 连接,此时发起 tcp 四次挥手。
# Http性能测试(AB测试)

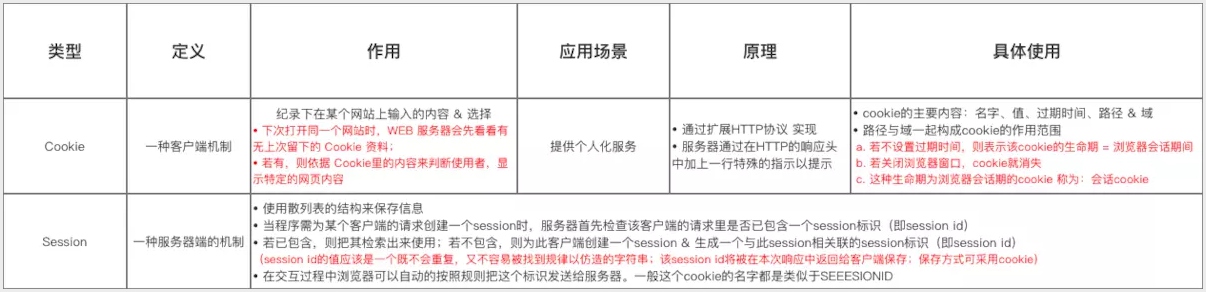
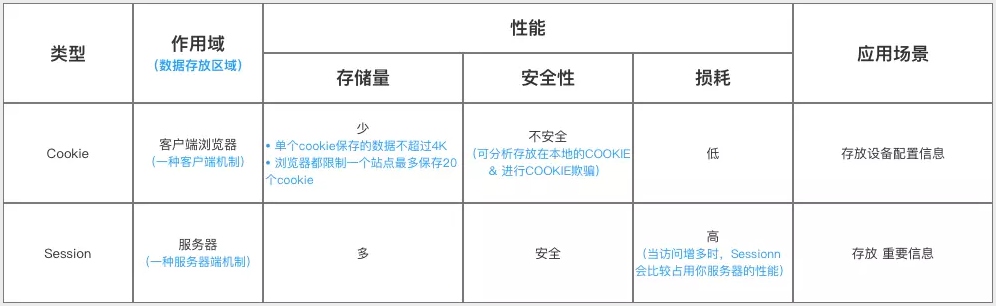
# Cookie 与 Session
- session 是另一种记录服务器和客户端会话状态的机制
- session 是基于 cookie 实现的,session 存储在服务器端,sessionId 会被存储到客户端的cookie 中
区别
- 安全性: Session 比 Cookie 安全,Session 是存储在服务器端的,Cookie 是存储在客户端的。
- 存取值的类型不同:Cookie 只支持存字符串数据,想要设置其他类型的数据,需要将其转换成字符串,Session 可以存任意数据类型。
- 有效期不同: Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭(默认情况下)或者 Session 超时都会失效。
- 存储大小不同: 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie,但是当访问量过多,会占用过多的服务器资源。
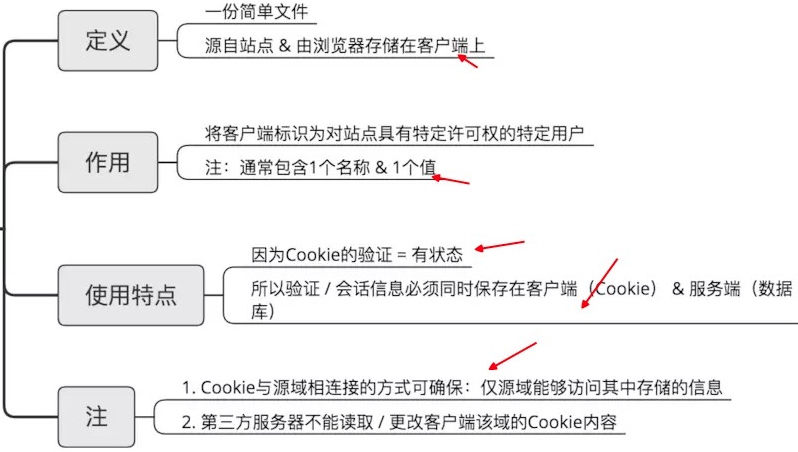
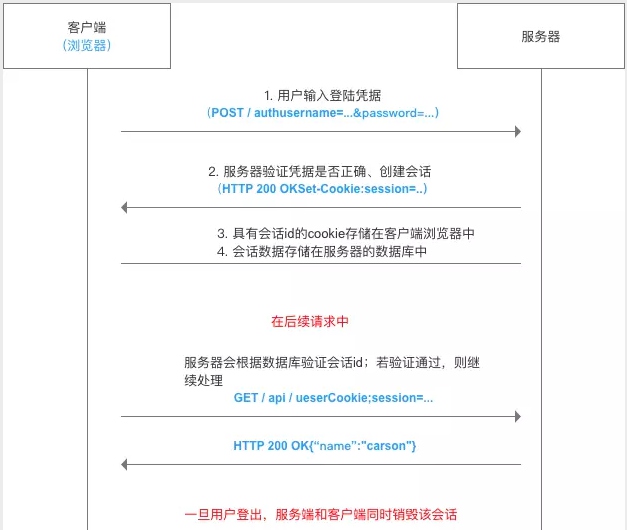
# Cookie 与 Token
基于Cookie,Token的身份验证 & 验证流程
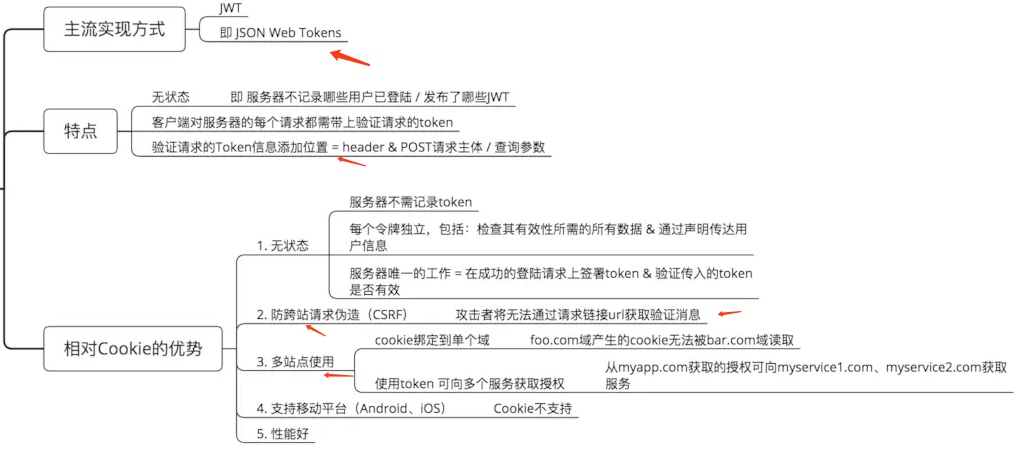
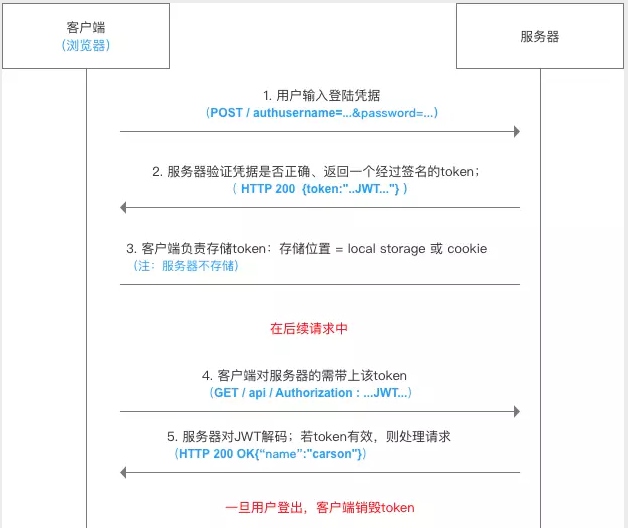
# token
登录注册,及权限认证;
JWT(即Json Web Token)目前最流行的跨域身份验证解决方案之一。它的工作流程是这样的:
- 前端向后端传递用户名和密码
- 用户名和密码在后端核实成功后,返回前端一个token(或存在cookie中)
- 前端拿到token并进行保存
- 前端访问后端接口时先进行token认证,认证通过才能访问接口。
那么在koa中我们需要做哪些事情?
在生成token阶段:首先是验证账户,然后生成token令牌,传给前端。
在认证token阶段: 完成认证中间件的编写,对前端的访问做一层拦截,token认证过后才能访问后面的接口。
授权登录:google登录(通过跳板登录,通过用户的帐号及密码获取到token,再跳板机中拿到token取获取google的用户信息),
跳板机设置:确保可以翻墙
'use strict';
const Controller = require('egg').Controller;
const {OAuth2Client} = require('google-auth-library');
const CLIENT_ID = 'xx332824282550-u22223uikjlf63c2qbhj1c8gi5egr9k3.apps.googleusercontent.com';
const client = new OAuth2Client(CLIENT_ID);
class HomeController extends Controller {
async index() {
const { ctx } = this;
ctx.body = 'hi, egg';
}
async google() {
const { ctx } = this;
let token = ctx.request.body.token
const ticket = await client.verifyIdToken({
idToken: token,
audience: CLIENT_ID// Specify the CLIENT_ID of the app that accesses the backend
// Or, if multiple clients access the backend:
//[CLIENT_ID_1, CLIENT_ID_2, CLIENT_ID_3]
});
const payload = ticket.getPayload();
let user = {
provider: 'google',
google_id: payload['sub'],
email: payload['email'],
nickname: payload['name'],
avatar: payload['picture'],
given_name: payload['given_name'],
family_name: payload['family_name'],
language: payload['locale'],
}
// If request specified a G Suite domain:
//const domain = payload['hd'];
ctx.body = user
}
}
module.exports = HomeController;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
role权限验证:后面的方式不同于之前的方式,提前判断返回ctx.fail(xxx),还处理了status;
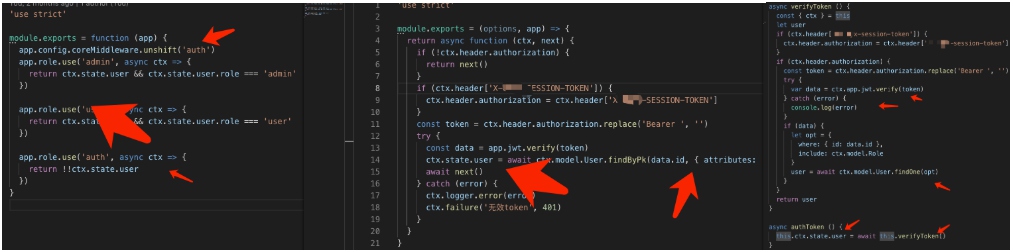
//config/role.js
module.exports = function (app) {
app.role.failureHandler = function (ctx, action) {
// console.log('+++++++++++++++++', ctx.acceptJSON, action)
if (!ctx.state.user || ctx.state.user.status === 1) {
ctx.failure('无效token', 401, 42010011)
} else {
ctx.failure('Forbidden, required role: ' + action, 403)
}
}
app.role.use('admin', async ctx => {
await ctx.service.auth.authToken()
return ctx.state.user && ctx.state.user.role && ctx.state.user.role.name === 'admin' && !ctx.state.user.status
})
app.role.use('user', async ctx => {
await ctx.service.auth.authToken()
return ctx.state.user && ctx.state.user.role && ctx.state.user.role.name === 'user' && !ctx.state.user.status
})
app.role.use('auth', async ctx => {
await ctx.service.auth.authToken()
return ctx.state.user && !ctx.state.user.status
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 会话跟踪
# 会话
客户端打开与服务器的连接发出请求到服务器响应客户端请求的全过程称之为会话。
# 会话跟踪
会话跟踪指的是对同一个用户对服务器的连续的请求和接受响应的监视。
# 会话跟踪必要
浏览器与服务器之间的通信是通过HTTP协议进行通信的,而HTTP协议是”无状态”的协议,它不能保存客户的信息,即一次响应完成之后连接就断开了,下一次的请求需要重新连接,这样就需要判断是否是同一个用户,所以才有会话跟踪技术来实现这种要求。
# 会话跟踪常用的方法
# URL 重写
URL(统一资源定位符)是Web上特定页面的地址,URL重写的技术就是在URL结尾添加一个附加数据以标识该会话,把会话ID通过URL的信息传递过去,以便在服务器端进行识别不同的用户。
# 隐藏表单域
将会话ID添加到HTML表单元素中提交到服务器,此表单元素并不在客户端显示
# Cookie
Cookie 是Web 服务器发送给客户端的一小段信息,客户端请求时可以读取该信息发送到服务器端,进而进行用户的识别。对于客户端的每次请求,服务器都会将 Cookie 发送到客户端,在客户端可以进行保存,以便下次使用。
客户端可以采用两种方式来保存这个 Cookie 对象,一种方式是保存在客户端内存中,称为临时 Cookie,浏览器关闭后这个 Cookie 对象将消失。另外一种方式是保存在客户机的磁盘上,称为永久 Cookie。以后客户端只要访问该网站,就会将这个 Cookie 再次发送到服务器上,前提是这个 Cookie 在有效期内,这样就实现了对客户的跟踪。Cookie 是可以被客户端禁用的。
# Session
每一个用户都有一个不同的 session,各个用户之间是不能共享的,是每个用户所独享的,在 session 中可以存放信息。
在服务器端会创建一个 session 对象,产生一个 sessionID 来标识这个 session 对象,然后将这个 sessionID 放入到 Cookie 中发送到客户端,下一次访问时,sessionID 会发送到服务器,在服务器端进行识别不同的用户。
Session 的实现依赖于 Cookie,如果 Cookie 被禁用,那么 session 也将失效。
# 缓存
# 分类【要点】
# 按协议分
- 非http协议层缓存:利用
meta标签的http-equiv属性值 ;Expires,set-cookie。 - 协议层缓存:利用 http 协议头属性值设置;
# 协议层缓存再分类
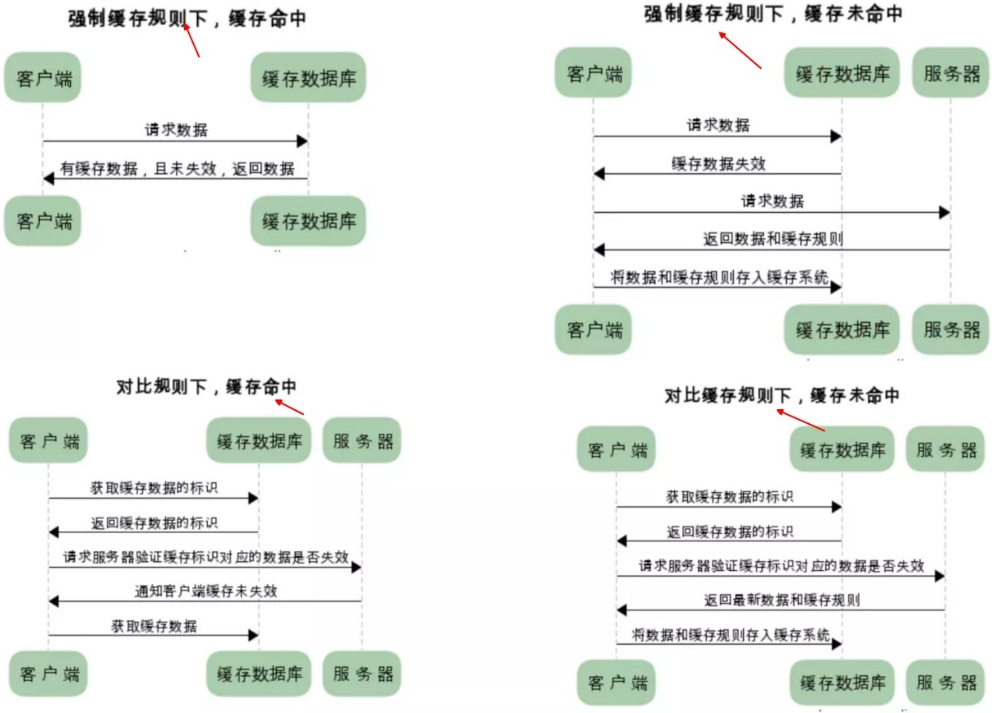
- 强缓存:利用 cache-control 和 expires 设置,直接返回一个过期时间,所以在缓存期间不请求;
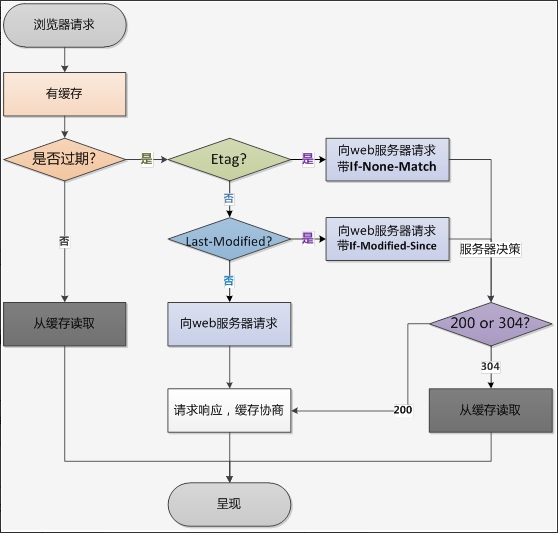
- 协商缓存:响应头返回 etag 或 last-modified 的哈希值,第二次请求头 If-none-match 或 IF-modify-since 携带上次哈希值,一致则返回 304。
| 类型 | 特性 |
|---|---|
| 强缓存 | 通过 expires 和 cache-control 设置,属性值是时间,所以在时间内不用请求 |
| 协商缓存 | 通过 If-none-match(etag)设置,etag 属性是哈希值,所以要请求和服务器值对比 |
# 缓存比较
强制缓存的优先级高于协商缓存,当执行强制缓存时,如若缓存命中,则直接使用缓存数据库数据,不在进行缓存协商。
协商缓存对比: etag 优先级高于 last-modified; etag 精度高,last-modified 精度是 s,1s 内 etag 修改多少次都会被记录; last-modified 性能好,etag 要得到 hash 值。
如果不是强制刷新,而且请求头带上了if-modified-since和if-none-match两个字段,则先判断etag,再判断last-modified。
# 校验过期机制
- 校验是否过期: Expires, Cache-Control(max-age)
- 协议Etag头信息校验; Etag
- 协议中Last-Modified头信息校验;Last-Modified
# 应用
webpack可以让在打包的时候,在文件的命名上带上hash值。可以得出一个较为合理的缓存方案:
- HTML:使用协商缓存。
- CSS&JS&图片:使用强缓存,文件命名带上hash值。
entry:{
main: path.join(__dirname,'./main.js'),
vendor: ['react', 'antd']
},
output:{
path:path.join(__dirname,'./dist'),
publicPath: '/dist/',
filname: 'bundle.[chunkhash].js'
}
2
3
4
5
6
7
8
9
# 哈希的设置
webpack有三种哈希值计算方式,分别是hash、chunkhash和contenthash。
- hash:跟整个项目的构建相关,构建生成的文件hash值都是一样的,只要项目里有文件更改,整个项目构建的hash值都会更改。
- chunkhash:根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的hash值。
- contenthash:由文件内容产生的hash值,内容不同产生的contenthash值也不一样。
显然,是不会使用第一种的。改了一个文件,打包之后,其他文件的hash都变了,缓存自然都失效了。
那chunkhash和contenthash的主要应用场景是什么呢?在实际在项目中,我们一般会把项目中的css都抽离出对应的css文件来加以引用。如果我们使用chunkhash,当我们改了css代码之后,会发现css文件hash值改变的同时,js文件的hash值也会改变。这时候,contenthash就派上用场了。
# 相关设置参数【要点】
# Expires
Exprires的值为服务端返回的数据到期时间
Expires是一个绝对时间,即服务器时间。浏览器检查当前时间,如果还没到失效时间就直接使用缓存文件。但由于服务端时间和客户端时间可能有误差,这也将导致缓存命中的误差,另一方面,Expires是HTTP1.0的产物,故现在大多数使用Cache-Control替代。
# Cache-Control
cache-control中的max-age保存一个相对时间。例如Cache-Control: max-age = 484200,表示浏览器收到文件后,缓存在484200s内均有效。如果同时存在cache-control和Expires,浏览器总是优先使用cache-control。
# 相关属性
private:客户端可以缓存 ;
public:客户端和代理服务器都可以缓存 【记】; public,max-age=3600 max-age=t:缓存内容将在t秒后失效 【记】;
no-cache:需要使用协商缓存来验证缓存数据 【记】;
no-store:所有内容都不会缓存
# 请求响应头字段
Cache-Control 作为请求头字段 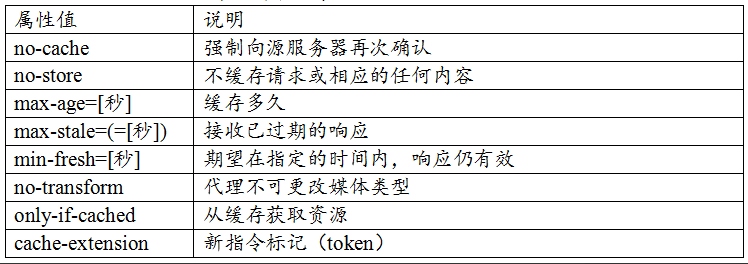 Cache-Control 作为响应头字段
Cache-Control 作为响应头字段 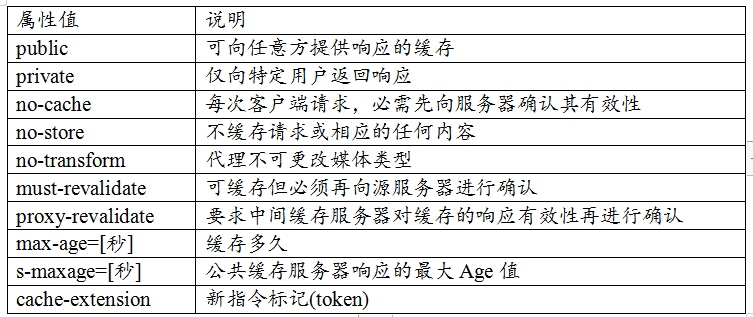 http1.1版本后请求头部字段 & 响应头部字段添加了新字段;
http1.1版本后请求头部字段 & 响应头部字段添加了新字段;
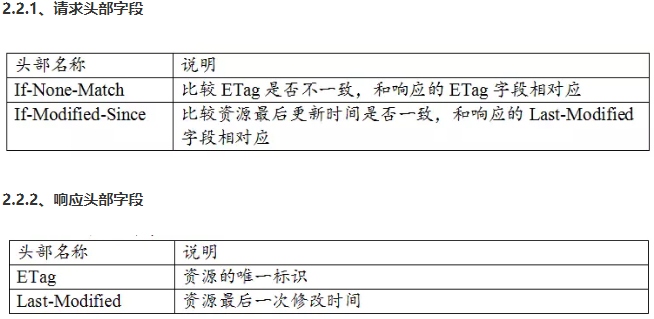
注意:If-None-Match(etag)的优先级比If-Modified-Since(last-modified)高,两者同时存在时,遵从前者。
参数
可缓存性:public, private(当前浏览器可以缓存), no-cache(要服务器协商验证) 到期: max-age=<seconds> ,s-maxage=<seconds> , max-stale=<seconds> 重新验证:must-revalidate, proxy-revalidate
其他:no-store(本地,代理,都不能缓存), no-transform
# Last-Modified/If-Modified-Since
last-modified是第一次请求资源时,服务器返回的字段,表示最后一次更新的时间。下一次浏览器请求资源时就发送if-modified-since字段。服务器用本地Last-modified时间与if-modified-since时间比较,如果不一致则认为缓存已过期并返回新资源给浏览器;如果时间一致则发送304状态码,让浏览器继续使用缓存。
# Etag/ If-None-Match
Etag:资源的实体标识(哈希字符串),当资源内容更新时,Etag会改变。服务器会判断Etag是否发生变化,如果变化则返回新资源,否则返回304。
# 总括要点(4个)【CEEL】
# 优先级
- 强制缓存的优先级高于协商缓存,当执行强制缓存时,如若缓存命中,则直接使用缓存数据库数据,不在进行缓存协商。
- 如果不是强制刷新,而且请求头带上了if-modified-since和if-none-match两个字段,则先判断etag,再判断last-modified。
- 处理顺序:强制缓存 > 协商缓存; cache-control > Expires > Etag > Last-modified
作用: 减少网络传输的损耗以及降低服务器压力。
强缓存
- Expires
- cache-control
协商缓存 , Cache-control 设置为no-cache,max-age=t过期时;
- Last-Modified 和 If-Modified-Since
- Etag 和 If-None-Match
# nodejs自己设置
res.setHeader('Cache-Control',public, max-age=${maxAge});res.setHeader('Expires', (new Date(Date.now() + maxAge * 1000)).toUTCString());res.setHeader('ETag',${stats.size}-${stats.mtime.toUTCString()});res.setHeader('Last-Modified', stats.mtime.toUTCString());
# http 响应头中的 Date 与 Last-Modified 有什么不同,网站部署时需要注意什么
简而言之,一个静态资源没有设置 Cache-Control 时会以这两个响应头来设置强制缓存时间,而非直接进行协商缓存。在涉及到 CDN 时,表现更为明显,体现在更新代码部署后,界面没有更新。
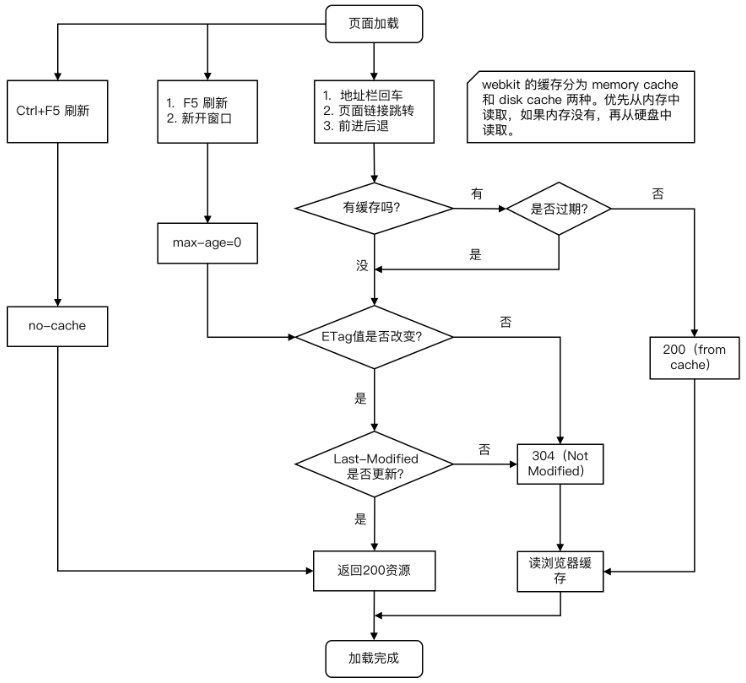
# 浏览器读取缓存流程(4步骤)
F5 刷新会忽略强缓存不会忽略协商缓存,ctrl+f5 都失效
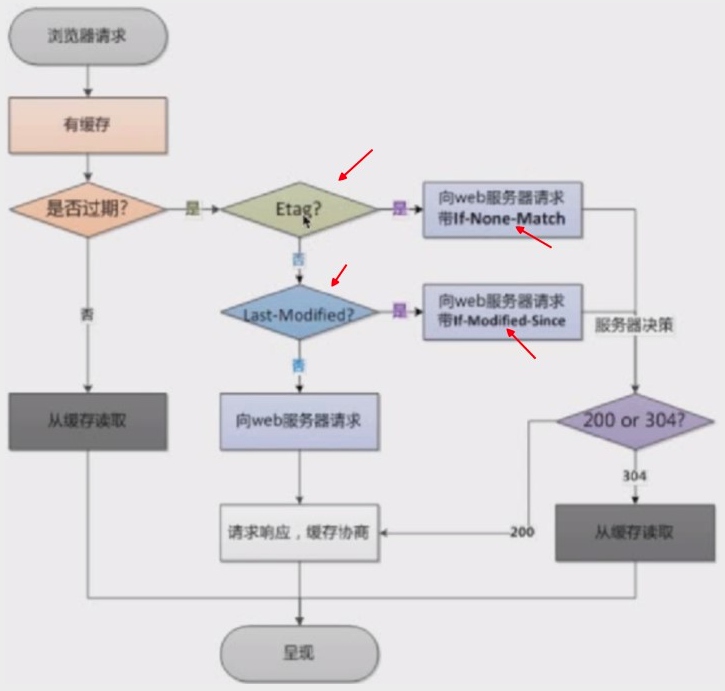
- 会先判断强缓存;Cache-Control(max-age) no-cache=true, public ;Expires,
- 再判断协商缓存
etag及last-modified是否存在;存在利用属性 If-None-match(etag)If-Modified-since(last-modified)携带值(这一步叫做数据签名); - 请求服务器,服务器对比 etag(last-modified),生效返回 304
图示流程:
代码处理示例:
# 缓存的优点
- 减少了冗余的数据传递,节省宽带流量
- 减少了服务器的负担,大大提高了网站性能
- 加快了客户端加载网页的速度 这也正是HTTP缓存属于客户端缓存的原因。
# 缓存的流程图【要点】
# 不同刷新的请求执行过程
浏览器地址栏中写入URL,回车 浏览器发现缓存中有这个文件了,不用继续请求了,直接去缓存拿.(最快)
F5 F5就是告诉浏览器,别偷懒,好歹去服务器看看这个文件是否有过期了。于是浏览器就胆胆襟襟的发送一个请求带上If-Modify-since。
Ctrl+F5 告诉浏览器,你先把你缓存中的这个文件给我删了,然后再去服务器请求个完整的资源文件下来。于是客户端就完成了强行更新的操作.
# 200 From cache和200 OK有什么区别
- 顾名思义是form cache是强缓存,不会和服务器通信,
- 而200 OK即为服务器处理结果正确。以此可以从浏览器缓存、输入url回车、刷新页面以及强制刷新等方面展开缓存方面的讲解。
# 能不能说下 304 的过程,以及影响缓存的头部属性有哪些?
写那个缓存流程图即可;
- 1、对于强制缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行比较缓存策略;
- 2、对于比较缓存,将缓存信息中的Etag和Last-Modified通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存;
# 服务器处理缓存
# etag的生成
**nginx 中 etag 由响应头的 Last-Modified 与 Content-Length 表示为十六进制组合而成。**而 last_modified 又由 mtime 组成;
源码: ngx_http_core_modules.c (opens new window)
etag->value.len = ngx_sprintf(etag->value.data, "\"%xT-%xO\"",
r->headers_out.last_modified_time,
r->headers_out.content_length_n)
- etag->value.data;
2
3
4
由 etag 计算 Last-Modified 与 Content-Length,使用 js 计算如下,结果相符
> new Date(parseInt('5cbee66d', 16) * 1000).toJSON()
"2019-04-23T10:18:21.000Z"
> parseInt('264', 16)
612
2
3
4
# 如果 http 响应头中 ETag 值改变了,是否意味着文件内容一定已经更改
不一定,由服务器中 ETag 的生成算法决定。
比如 nginx 中的 etag 由 last_modified 与 content_length 组成,而 last_modified 又由 mtime 组成
当编辑文件却未更改文件内容时,或者 touch file,mtime 也会改变,此时 etag 改变,但是文件内容没有更改。
# Last-Modified的生成
Last-Modified 是由一个 unix timestamp 表示,则意味着它只能作用于秒级的改变
一般会选文件的 mtime,表示文件内容的修改时间;
nginx 也是这样处理的,源码见: ngx_http_static_module.c (opens new window)
r->headers_out.status = NGX_HTTP_OK;
r->headers_out.content_length_n = of.size;
r->headers_out.last_modified_time = of.mtime;
2
3
# node处理示例
**在Express中,使用了fresh (opens new window)这个包来判断是否是最新的资源。**主要源码如下:
可以看到,如果不是强制刷新,而且请求头带上了if-modified-since和if-none-match两个字段,则先判断etag,再判断last-modified。当然,如果你不喜欢这种策略,也可以自己实现一个。
function fresh (reqHeaders, resHeaders) {
// fields
var modifiedSince = reqHeaders['if-modified-since']
var noneMatch = reqHeaders['if-none-match']
// unconditional request
if (!modifiedSince && !noneMatch) {
return false
}
// Always return stale when Cache-Control: no-cache
// to support end-to-end reload requests
// https://tools.ietf.org/html/rfc2616#section-14.9.4
var cacheControl = reqHeaders['cache-control']
if (cacheControl && CACHE_CONTROL_NO_CACHE_REGEXP.test(cacheControl)) {
return false
}
// if-none-match
if (noneMatch && noneMatch !== '*') {
var etag = resHeaders['etag']
if (!etag) {
return false
}
var etagStale = true
var matches = parseTokenList(noneMatch)
for (var i = 0; i < matches.length; i++) {
var match = matches[i]
if (match === etag || match === 'W/' + etag || 'W/' + match === etag) {
etagStale = false
break
}
}
if (etagStale) {
return false
}
}
// if-modified-since
if (modifiedSince) {
var lastModified = resHeaders['last-modified']
var modifiedStale = !lastModified || !(parseHttpDate(lastModified) <= parseHttpDate(modifiedSince))
if (modifiedStale) {
return false
}
}
return true
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
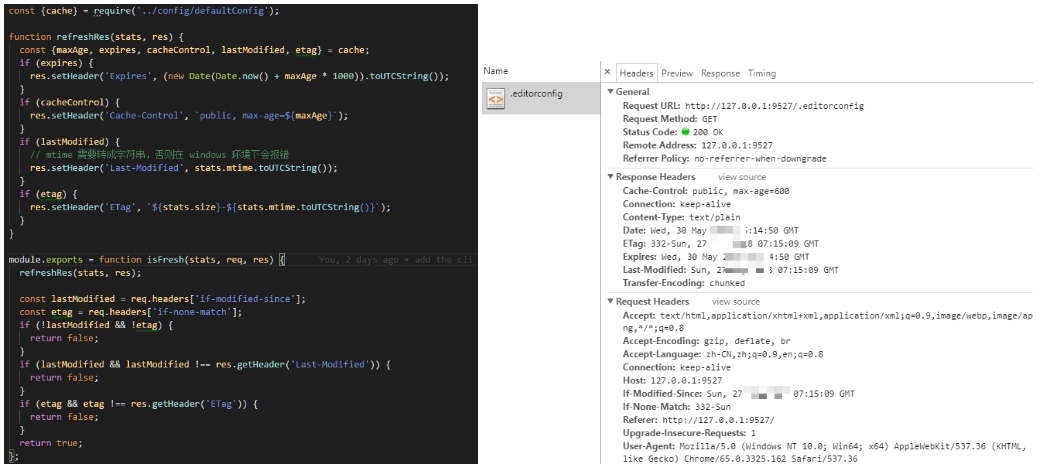
自己实现的缓存处理;cache.js
const {cache} = require('../config/defaultConfig');
function refreshRes(stats, res) {
const {maxAge, expires, cacheControl, lastModified, etag} = cache;
if (cacheControl) {
res.setHeader('Cache-Control', `public, max-age=${maxAge}`);
}
if (expires) {
res.setHeader('Expires', (new Date(Date.now() + maxAge * 1000)).toUTCString());
}
if (etag) {
res.setHeader('ETag', `${stats.size}-${stats.mtime.toUTCString()}`);
}
if (lastModified) {// mtime 需要转成字符串,否则在 windows 环境下会报错
res.setHeader('Last-Modified', stats.mtime.toUTCString());
}
}
module.exports = function isFresh(stats, req, res) {
refreshRes(stats, res);
//304请求跟提交的对比
const lastModified = req.headers['if-modified-since'];
const etag = req.headers['if-none-match'];
if (!lastModified && !etag) {
return false;
}
if (etag && etag !== res.getHeader('ETag')) {
return false;
}
// Request Headers跟 Response Headers 中的 Last-Modified一样;
if (lastModified && lastModified !== res.getHeader('Last-Modified')) {
return false;
}
return true;
};
//route.js
if (isFresh(stats, req, res)) {//缓存【304】
res.statusCode = 304;
res.end();
return;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# HTTP中的优化
# 优化【要点】
- 减少网站中使用的域名 域名越多 , DNS 解析花费的时间越多。
- 减少网站中的重定向操作,重定向会增加请求数量。
- 选用高性能的Web服务器 Nginx 代理静态资源 。
- 资源大小优化:对资源进行压缩、合并(合并可以减少请求,也会产生文件缓存问题), 使用 gzip/br 压缩。
- 给资源添加强制缓存和协商缓存。
- 升级 HTTP/1.x 到 HTTP/2
- 付费、将静态资源迁移至 CDN;
# Timing
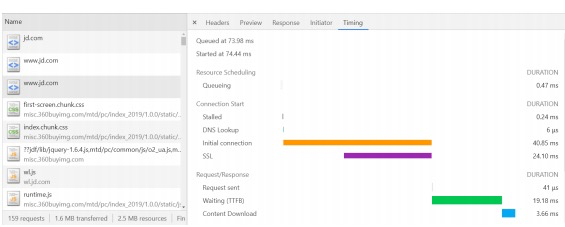
- Queuing : 请求发送前会根据优先级进行排队,同时每个域名最多处理6个TCP链接,
- 超过的也会进行排队,并且分配磁盘空间时也会消耗一定时间。
- Stalled :请求发出前的等待时间(处理代理,链接复用)
- DNS lookup :查找 DNS 的时间
- initial Connection :建立TCP链接时间
- SSL : SSL 握手时间( SSL 协商)
- Request Sent :请求发送时间(可忽略)
- Waiting ( TTFB ) :等待响应的时间,等待返回首个字符的时间
- Content Dowloaded :用于下载响应的时间
# CDN
CDN 的全称是Content Delivery Network,受制于网络的限制,访问者离服务器越远访问速度就越慢
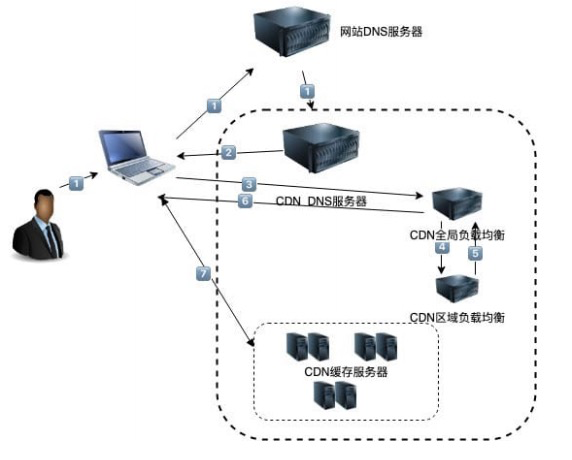
核心就是离你最近的服务器给你提供数据 (代理 + 缓存)
- 先在全国各地架设 CDN 服务器
- 正常访问网站会通过 DNS 解析,解析到对应的服务器解析1:我们通过 CDN 域名访问时,会被解析到 CDN 专用 DNS 服务器。并返回 CDN 全
- 解析1:我们通过 CDN 域名访问时,会被解析到 CDN 专用 DNS 服务器。并返回 CDN 全局负载均衡服务器的 IP 地址。
- 解析2:向全局负载均衡服务器发起请求,全局负载均衡服务器会根据用户 IP 分配用户所属区域的负载均衡服务器。并返回一台 CDN 服务器 IP 地址
- 用户向 CDN 服务器发起请求。如果服务器上不存在此文件。则向上一级缓存服务器请求,直至查找到源服务器,返回结果并缓存到 DNS 服务器上。
# HTTPS
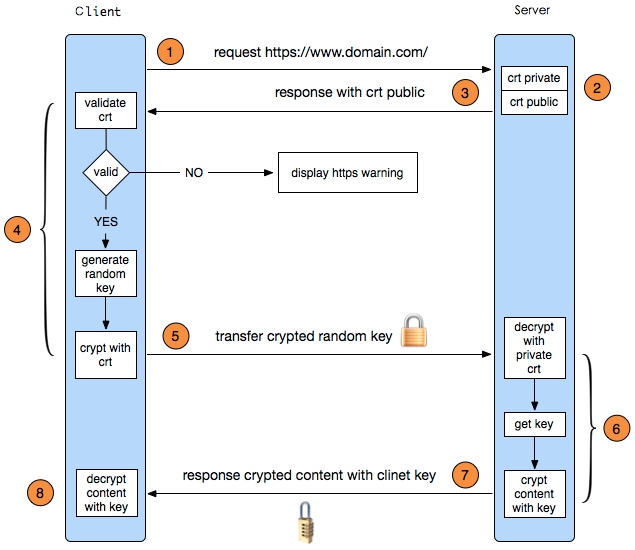
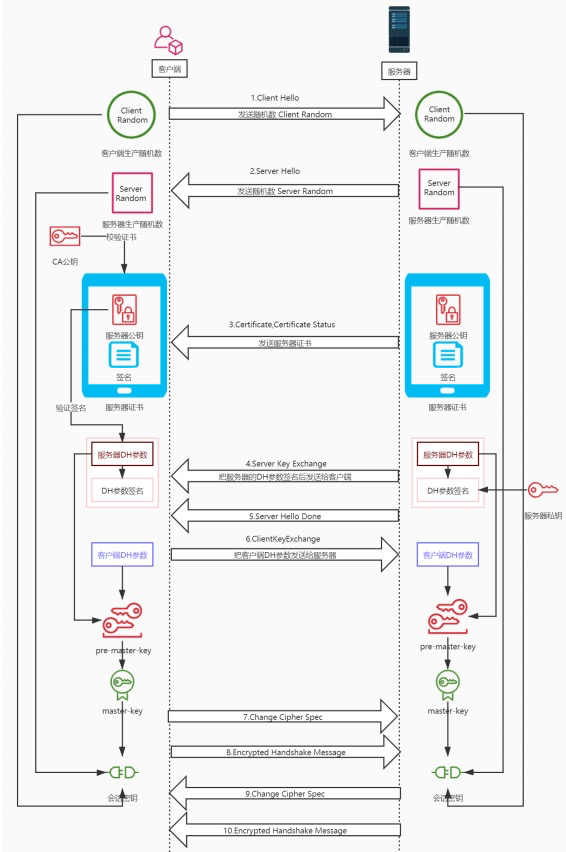
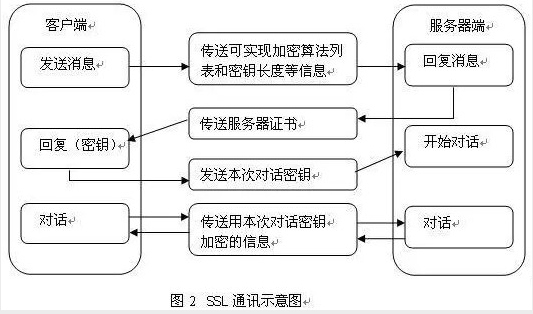
# https传输过程
HTTPS其实是有两部分组成:HTTP + SSL / TLS,也就是在HTTP上又加了一层处理加密信息的模块。 服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据。具体是如何进行加密,解密,验证的,且看下图。
https并不是直接通过非对称加密传输过程,而是有握手过程,握手过程主要是和服务器做通讯,生成私有秘钥,最后通过该秘钥对称加密传输数据。还有验证证书的正确性。 证书验证过程保证了对方是合法的,并且中间人无法通过伪造证书方式进行攻击。
# 主要解决三个安全问题
- 内容隐私
- 防篡改
- 确认对方身份
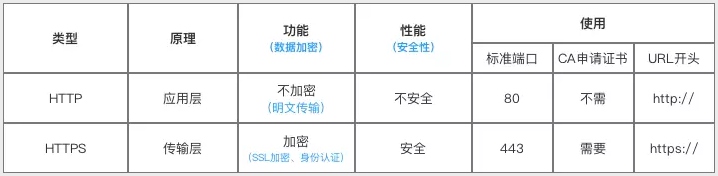
# HTTP 与HTTPS的区别
# 问题
# https用哪些端口进行通信,这些端口分别有什么用
- 443端口用来验证服务器端和客户端的身份,比如验证证书的合法性
- 80端口用来传输数据(在验证身份合法的情况下,用来数据传输)
# 身份验证过程中会涉及到密钥, 对称加密,非对称加密,摘要的概念,请解释一下
- 密钥:密钥是一种参数,它是在明文转换为密文或将密文转换为明文的算法中输入的参数。密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上。
- 对称加密:
对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密,常见的对称加密算法有DES、3DES、TDEA、Blowfish、RC5和IDEA。 - 非对称加密:
非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密。 - 摘要:
摘要算法又称哈希/散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。算法不可逆。
# 中间人攻击
HTTPS 的过程并不是密不透风的,HTTPS 有若干漏洞,给**中间人攻击(Man In The Middle Attack,简称 MITM)**提供了可能。
所谓中间人攻击,指攻击者与通讯的两端分别建立独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。在中间人攻击中,攻击者可以拦截通讯双方的通话并插入新的内容。
# 为什么需要CA机构对证书签名
如果不签名会存在中间人攻击的风险,签名之后保证了证书里的信息,比如公钥、服务器信息、企业信息等不被篡改,能够验证客户端和服务器端的“合法性”。
# https验证身份也就是TSL/SSL身份验证的过程
简要图解如下:
# RESTful
一种比较成熟的应用程序的API设计理论;URL定位资源,用HTTP动词(GET,POST,DELETE,DETC)描述操作。
作为开发者尽量按照这种API设计风格设置,方便对接前端及第三方使用;
# 格式
GET /api/v2/topics 200
GET /api/v2/topics/57ea257b3670ca3f44c5beb6 200
POST /api/v2/topics 201
PUT /api/v2/topics/57ea257b3670ca3f44c5beb6 204
2
3
4
# HTTP动词【CRUD PHO】
对于资源的具体操作类型,由HTTP动词表示。
常用的HTTP动词有下面五个(括号里是对应的SQL命令)。
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
还有两个不常用的HTTP动词。
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
下面是一些例子。
- GET /zoos:列出所有动物园
- POST /zoos:新建一个动物园
- GET /zoos/ID:获取某个指定动物园的信息
- PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
- PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
- DELETE /zoos/ID:删除某个动物园
- GET /zoos/ID/animals:列出某个指定动物园的所有动物
- DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物

# 过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
- ?limit=10:指定返回记录的数量
- ?offset=10:指定返回记录的开始位置。
- ?page=2&per_page=100:指定第几页,以及每页的记录数。
- ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
- ?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
# 状态码(Status Codes)
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的HTTP动词)。
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
状态码的完全列表参见这里 (opens new window)。
# 错误处理(Error handling)
如果状态码是4xx,就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
{ error: "Invalid API key" }1
2
3
# 返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
- GET /collection:返回资源对象的列表(数组)
- GET /collection/resource:返回单个资源对象
- POST /collection:返回新生成的资源对象
- PUT /collection/resource:返回完整的资源对象
- PATCH /collection/resource:返回完整的资源对象
- DELETE /collection/resource:返回一个空文档
# Hypermedia API
RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。
比如,当用户向api.example.com的根目录发出请求,会得到这样一个文档。
{"link": { "rel": "collection https://www.example.com/zoos", "href": "https://api.example.com/zoos", "title": "List of zoos", "type": "application/vnd.yourformat+json" }}1
2
3
4
5
6
上面代码表示,文档中有一个link属性,用户读取这个属性就知道下一步该调用什么API了。rel表示这个API与当前网址的关系(collection关系,并给出该collection的网址),href表示API的路径,title表示API的标题,type表示返回类型。
Hypermedia API的设计被称为HATEOAS (opens new window)。Github的API就是这种设计,访问api.github.com (opens new window)会得到一个所有可用API的网址列表。
{ "current_user_url": "https://api.github.com/user", "authorizations_url": "https://api.github.com/authorizations", // ... }1
2
3
4
5
从上面可以看到,如果想获取当前用户的信息,应该去访问api.github.com/user (opens new window),然后就得到了下面结果。
{ "message": "Requires authentication", "documentation_url": "https://developer.github.com/v3" }1
2
3
4
上面代码表示,服务器给出了提示信息,以及文档的网址。
# 其他
(1)API的身份认证应该使用OAuth 2.0 (opens new window)框架。
(2)服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
# egg的 URL 定义
eggjs如果想通过 RESTful 的方式来定义路由, 我们提供了 `app.resources('routerName', 'pathMatch', controller) 快速在一个路径上生成 CRUD (opens new window) 路由结构。
router.resources('users', '/api/v1/users', controller.v1.users); // app/controller/v1/users.js
const methods = [ 'head', 'options', 'get', 'put', 'patch', 'post', 'delete', 'del', 'all', 'resources' ];
2
3
// app/router.js
module.exports = app => {
const { router, controller } = app;
router.resources('posts', '/api/posts', controller.posts);
router.resources('users', '/api/v1/users', controller.v1.users); // app/controller/v1/users.js
//如果要考虑授权的情况下,会这样设置;
const { router, controller, config } = app
const { baseAPI } = config.adm
const categories = controller.categories
const module = 'categories'
// router.resources('categories', '/categories', controller.categories)
const nsRouter = router.namespace(`${baseAPI}/${module}`)//namespace(prefix, ...middlewares) {
nsRouter.post('/', app.role.can('auth'), categories.create)
nsRouter.put('/:id', app.role.can('auth'), categories.update)
nsRouter.delete('/:id', app.role.can('auth'), categories.destroy)
nsRouter.get('/:id', categories.show)
nsRouter.get('/', categories.index)
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
上面代码就在 /posts 路径上部署了一组 CRUD 路径结构,对应的 Controller 为 app/controller/posts.js 接下来, 你只需要在 posts.js 里面实现对应的函数就可以了。
| Method | Path | Route Name | Controller.Action |
|---|---|---|---|
| GET | /posts | posts | app.controllers.posts.index |
| GET | /posts/new | new_post | app.controllers.posts.new |
| GET | /posts/:id | post | app.controllers.posts.show |
| GET | /posts/:id/edit | edit_post | app.controllers.posts.edit |
| POST | /posts | posts | app.controllers.posts.create |
| PUT | /posts/:id | post | app.controllers.posts.update |
| DELETE | /posts/:id | post | app.controllers.posts.destroy |
# egg中的curl及request
# 通过 app/ctx 使用 HttpClient
框架在应用初始化的时候,会自动将 HttpClient (opens new window) 初始化到 app.httpclient。 同时增加了一个 app.curl(url, options) 方法,它等价于app.httpclient.request(url, options)。这样就可以非常方便地使用 app.curl 方法完成一次 HTTP 请求。
框架在 Context 中同样提供了 ctx.curl(url, options) 和ctx.httpclient,保持跟 app 下的使用体验一致。 这样就可以在有 Context 的地方(如在 controller 中)非常方便地使用ctx.curl() 方法完成一次 HTTP 请求。

# 基本 HTTP 请求(封装后跟requet库操作类似)
HttpClient 的默认 method 会设置为 GET。
返回值
result会包含 3 个属性:status、headers和datastatus: 响应状态码,如200,302,404,500等等headers: 响应头,类似{ 'content-type': 'text/html', ... }data: 响应 body,默认 HttpClient 不会做任何处理,会直接返回 Buffer 类型数据。 一旦设置了options.dataType,HttpClient 将会根据此参数对data进行相应的处理。
完整的请求参数 options 和返回值 result 的说明请看下文的 options 参数详解 (opens new window) 章节。
以下例子都会在 controller 代码中对 https://httpbin.org 发起请求来完成。
//get 读取数据几乎都是使用 GET 请求,它是 HTTP 世界最常见的一种,也是最广泛的一种,它的请求参数也是最容易构造的。
const result = await ctx.curl('https://httpbin.org/get?foo=bar');
//post 创建数据的场景一般来说都会使用 POST 请求,它相对于 GET 来说多了请求 body 这个参数。
const result = await ctx.curl('https://httpbin.org/post', {
method: 'POST', // 必须指定 method
contentType: 'json',// 通过 contentType 告诉 HttpClient 以 JSON 格式发送
dataType: 'json',// 明确告诉 HttpClient 以 JSON 格式处理返回的响应 body
data: {
hello: 'world',
now: Date.now(),
},
});
//put PUT 与 POST 类似,它更加适合更新数据和替换数据的语义。 除了 method 参数需要设置为 PUT,其他参数几乎跟 POST 一模一样。
const result = await ctx.curl('https://httpbin.org/put', {
method: 'PUT',
contentType: 'json',
dataType: 'json',
data: {
update: 'foo bar',
},
});
//delete 删除数据会选择 DELETE 请求,它通常可以不需要加请求 body,但是 HttpClient 不会限制。
const result = await ctx.curl('https://httpbin.org/delete', {
method: 'DELETE',
dataType: 'json',
});
ctx.body = result.data;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
request/request-promise 库使用示例:
//request request-promise 库使用示例
const rp = require('request-promise');
var options = {
method: 'POST',
uri: `https://devpython.iwifi.com:8082/Meet/face/V1804261328.U.JSON`,//设备状态;
// headers: {
// /* 'content-type': 'application/x-www-form-urlencoded' */ // Is set automatically
/* 'content-type': 'multipart/form-data' */
// },
json: true, // Automatically stringifies the body to JSON
//qs: reqData,
body: reqData,//POST data to a JSON REST API
// form: reqData,//POST like HTML forms do
//formData: reqData,//if you want to include a file upload then use options.formData:
};
rp(options)
.then(function(parsedBody) {
// POST succeeded...
console.log(parsedBody);
})
.catch(function(err) {
// POST failed...
console.log(err);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
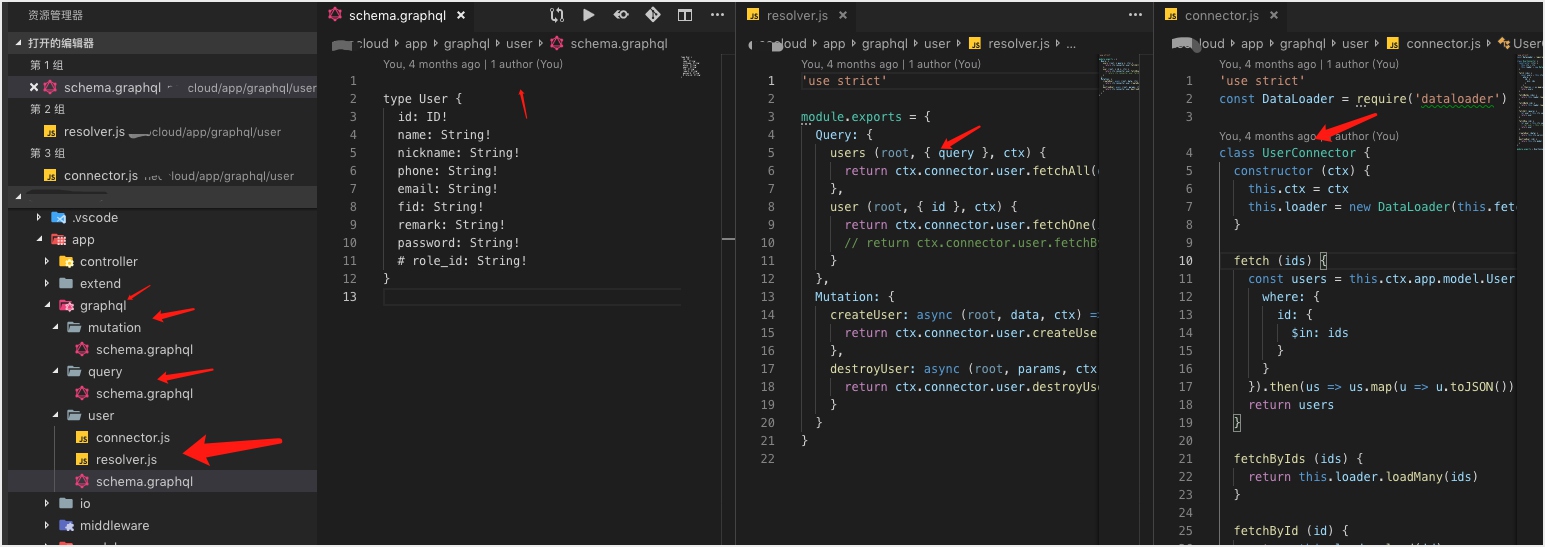
# Graphql
# 参考链接
http://www.ruanyifeng.com/blog/2014/05/restful_api.html