 redis持久化、缓存及淘汰策略
redis持久化、缓存及淘汰策略
# 持久化分类
Redis 为了内部数据的安全考虑,会把本身的数据以文件的形式保存到硬盘中一份,在服务器重启后会自动把硬盘的数据恢复到内存(Redis)里面
- RDB 持久化(默认):
原理是将 Reids 在内存中的数据库记录定时 dump 到磁盘上的 RDB 持久化。 - AOF(append only file)持久化:
原理是将 Redis 的操作日志以追加的方式写入文件。开启AOF持久化(redis.conf): appendonly yes
RDB持久化可以手动执行,也可以配置定期执行,可以把某个时间的数据状态保存到RDB文件中,反之,我们可以用RDB文件还原数据库状态。
AOF持久化是通过保存服务器执行的命令来记录状态的。还原的时候再执行一遍即可。
# 两者的区别:
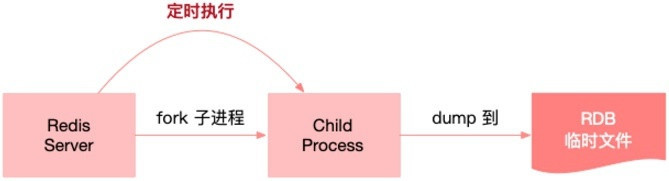
RDB 持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是 fork 一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF 持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,服务器重启的时候会**重新执行这些命令来恢复**原始的数据,可以打开文件看到详细的操作记录。

# 优缺点比较:
RDB 优点
- RDB 是紧凑的二进制文件,比较合适备份,全量复制等场景;
- RDB 恢复数据远快于 AOF。
缺点
- RDB 无法实现实时或者秒级持久化;
- 新老版本无法兼容 RDB 格式。
AOF 优点
- 可以更好地保护数据不丢失;
- appen-only 模式写入性能比较高;
- 适合做灾难性的误删除紧急恢复。
缺点:
- 对于同一份文件,AOF 文件要比 RDB 快照大;
- AOF 开启后,写的 QPS 会有所影响,相对于 RDB 来说 写 QPS 要下降;
- 数据库恢复比较慢, 不合适做冷备。
# 总结
- 如果你对
数据安全性非常重视的话,你应该同时使用两种持久化功能 - 如果你承受
数分钟以内的数据丢失,你可以只使用RDB 持久化
二者选择的标准,就是看是否愿意牺牲一些性能,换取更高的缓存一致性(AOF),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行 save 的时候,再做备份(RDB)。
注: 未来 Redis 可能会将 AOF 和 RDB 整合成单个持久化模型.
RDB和AOF如何选择
(1)不要仅仅使用RDB,因为那样会让你丢失很多的数据
(2)也不要仅仅使用AOF,因为RDB做冷备份数据更快,恢复数据也更快,而且bug更少
(3)综合使用AOF和RDB两种备份数据
# 缓存的更新策略
缓存的更新策略包含:
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存
策略一:先更新数据库,再更新缓存
- 这种策略会导致线程安全问题
例如:线程 1 更新了数据库,线程 2 也更新数据库, 这时候由于某种原因,线程 2 首先更新了缓存,线程 1 后续更新。 这样就导致了脏数据的问题。 因为目前数据库中存储的线程 2 更新后的数据,而缓存存储的是线程1更新的老数据。
- 更新缓存的复杂度相对较高
数据写入数据库之后,一般存入缓存的数据都要经过一系列的加工计算,然后写入缓存。 这时候更新缓存相比较于直接删除缓存要比较复杂。
策略二:先删除缓存,再更新数据库
这种策略可能导致数据不一致的问题。线程 1 写数据删除缓存;这时候有线程 2 查询该缓存,发现不存在,则去访问数据库,得到旧值放入缓存;线程 1 更新数据库。这时候就出现了数据不一致的问题。 如果缓存没有过期时间,这个脏数据一直存在。
解决方案:在写数据库成功之后, 再次淘汰缓存一次。
策略三:先更新数据库,再删除缓存
可能会造成比较短暂的数据不一致。在更新完成数据库, 还没有删除缓存的时刻,如果有缓存数据访问, 就会造成数据不一致的情形。 但这种如果数据同步机制比较科学,一般都会比较快, 不一致的影响比较小。
# 缓存常见异常及解决方案
缓存使用过程当中,我们经常遇到的一些问题总结有四点:
- 缓存穿透
- 缓存雪崩 3. 缓存预热 2. 缓存降级
# 缓存穿透
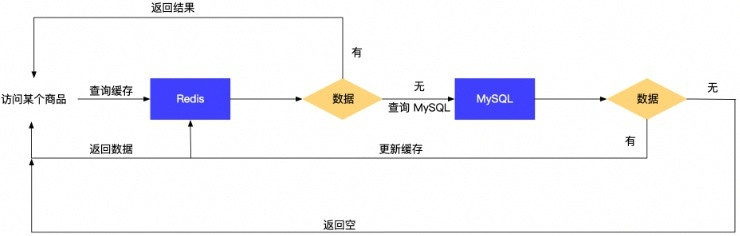
一般访问缓存的流程,如果缓存中存在查询的商品数据,那么直接返回。 如果缓存中不存在商品数据, 就要访问数据库。
由于不恰当的业务功能实现,或者外部恶意攻击不断地请求某些不存在的数据内存,由于缓存中没有保存该数据,导致所有的请求都会落到数据库上,对数据库可能带来一定的压力,甚至崩溃。
 解决方案:
解决方案:
针对缓存穿透的情况, 简单的对策就是将不存在的数据访问结果, 也存储到缓存中,避免缓存访问的穿透。最终不存在商品数据的访问结果也缓存下来。有效的避免缓存穿透的风险。
# 缓存雪崩
当缓存重启或者大量的缓存在某一时间段失效, 这样就导致大批流量直接访问数据库, 对 DB 造成压力, 从而引起 DB 故障,系统崩溃。
举例来说, 我们在准备一项抢购的促销运营活动,活动期间将带来大量的商品信息、库存等相关信息的查询。 为了避免商品数据库的压力,将商品数据放入缓存中存储。 不巧的是,抢购活动期间,大量的热门商品缓存同时失效过期了,导致很大的查询流量落到了数据库之上。对于数据库来说造成很大的压力。
解决方案:
- 将商品
根据品类热度分类, 购买比较多的类目商品缓存周期长一些, 购买相对冷门的类目商品,缓存周期短一些; - 在
设置商品具体的缓存生效时间的时候, 加上一个随机的区间因子, 比如说 5~10 分钟之间来随意选择失效时间; 提前预估 DB 能力, 如果缓存挂掉,数据库仍可以在一定程度上抗住流量的压力
这三个策略能够有效的避免短时间内,大批量的缓存失效的问题。
# 缓存击穿
是针对缓存中没有但数据库有的数据。
场景是,当Key失效后,假如瞬间突然涌入大量的请求,来请求同一个Key,这些请求不会命中Redis,都会请求到DB,导致数据库压力过大,甚至扛不住,挂掉。
解决方案:
1、设置热点Key,自动检测热点Key,将热点Key的过期时间加大或者设置为永不过期,或者设置为逻辑上永不过期
2、加互斥锁。当发现没有命中Redis,去查数据库的时候,在执行更新缓存的操作上加锁,当一个线程访问时,其它线程等待,这个线程访问过后,缓存中的数据会被重建,这样其他线程就可以从缓存中取值。
# 缓存预热
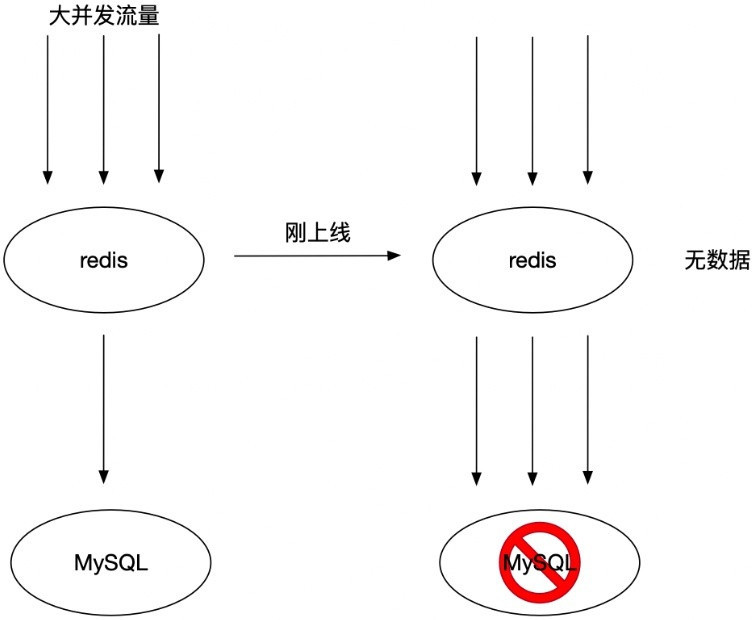
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题。用户直接查询事先被预热的缓存数据。
如果不进行预热, 那么 Redis 初识状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
如图所示:
 解决方案:
解决方案:
- 数据量不大的时候,工程启动的时候进行加载缓存动作;
- 数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
- 数据量太大的时候,优先保证热点数据进行提前加载到缓存。
# 缓存降级
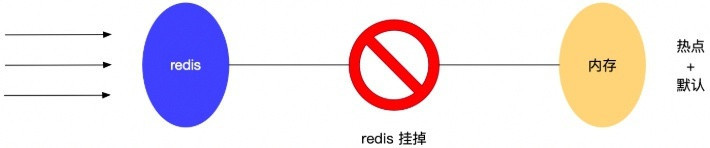
降级的情况,就是缓存失效或者缓存服务挂掉的情况下,我们也不去访问数据库。我们直接访问内存部分数据缓存或者直接返回默认数据。 举例来说:
对于应用的首页,一般是访问量非常大的地方,首页里面往往包含了部分推荐商品的展示信息。这些推荐商品都会放到缓存中进行存储,同时我们为了避免缓存的异常情况,对热点商品数据也存储到了内存中。同时内存中还保留了一些默认的商品信息。
降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
如下图所示:
# 重点情况
# 缓存穿透及解决方案
缓存穿透是指缓存中查询一个不存在的数据,需要去数据库中获取。
如果数据库也查不到结果,将不会同步到缓存,导致这个不存在数据每次请求都要到数据库查询,失去了缓存的意义。
解决方法有两个:
1. 布隆过滤(Bloom filter) 将所有查询的参数都存储到一个 bitmap 中,在查询缓存之前,先再找个 bitmap 里面进行验证。
如果 bitmap 中存在,则进行底层缓存的数据查询; 如果 bitmap 中不存在查询参数,则进行拦截,不再进行缓存的数据查询。
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
2. 缓存空对象 如果查询返回的数据为空,仍然把这个空结果进行缓存。那么再次用相同 key 获取数据的时候,即使不存在的数据,缓存也可以直接返回空值,避免重复访问 DB。
缓存空对象有两个不足之处:
- 缓存层将存储更多的键值对,如果是恶意的随机访问,将造成很多内存空间的浪费。
这个不足之处可以通过将这类数据设置很短的过期时间来控制。 - DB 与缓存数据不一致。
这种可以考虑通过异步消息来进行数据更新的通知,在一定程度上减少这类不一致的时间。
3. 以上总括
1:对查询结果为空的情况也进行缓存,这样,再次访问时,缓存层会直接返回空值。缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。具体请看布隆过滤器
# 缓存雪崩及解决方案
在集中的一段时间内,有大量的缓存失效,导致大量的访问没有命中缓存,从而将所有查询进行数据库访问,导致数据库的压力增大,从而造成了缓存雪崩。
比如,如果要做一个促销活动,我们将商品信息都刷新到缓存, 过期时间统一为 30 分钟。那么在 30 分钟之后,这批商品将全部过期。这时候这批商品的访问查询,都落到了数据库,对于数据库而言,这一刻的压力会非常大。从而造成系统整体性风险。
解决方案:
方法 1:分散失效时间
分析缓存数据的特点,尽量将热点缓存的失效时间均匀分布。 比如说将相同类型的缓存的失效时间设置成一个在一定区间内的随机值。从而有效的分散失效时间。让Key的失效时间分散开,可以在统一的失效时间上再加一个随机值,或者使用更高级的算法分散失效时间。
方法 2:DB 访问限制
对数据的访问进行限流性质的操作。比如说对数据库访问进行加锁的处理或者限流相关的处理。对存储层增加限流措施,当请求超出限制,提供降级服务(一般就是返回错误即可)
方法 3:多级缓存设计
一级缓存为基础缓存,缓存失效时间设置一个较长时间, 二级缓存为应用缓存,失效时间正常设置,一般会比较短。 **当二级缓存失效的时候,再从一级缓存里面获取。**多级缓存:比如增加本地缓存,减小redis压力。
方法4:构建多个redis实例
个别节点挂了还有别的可以用。
# 淘汰策略
# 简介
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
Redis 可以看作是一个内存数据库,通过 Maxmemory 指令配置 Redis 的数据集使用指定量的内存。设置 Maxmemory 为 0,则表示无限制。
当内存使用达到 Maxmemory 极限时,需要使用某种淘汰算法来决定清理掉哪些数据,以保证新数据的存入。
# redis 提供 6种数据淘汰策略:
- no-enviction(驱逐):禁止驱逐数据; 当内存使用达到上限,所有需要申请内存的命令都会异常报错。
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰;淘汰一部分最近使用较少的(LRC),但只限于过期设置键。
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰; 优先移除具有更早失效时间的 key。
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰; 随机淘汰某一个键。
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰; 先试图移除一部分最近未使用的 key。
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰; 随机淘汰某一个键。
# 常见的淘汰算法
FIFO:First In First Out
先进先出。判断被存储的时间,离目前最远的数据优先被淘汰。
LRU:Least Recently Used
最近最少使用。判断最近被使用的时间,目前最远的数据优先被淘汰。
LFU:Least Frequently Used
最不经常使用。在一段时间内,数据被使用次数最少的,优先被淘汰。
# LRU的具体实现
LRU全称是Least Recently Used,即最近最久未使用的意思。
LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
redis原始的淘汰算法简单实现:当需要淘汰一个key时,随机选择3个key,淘汰其中间隔时间最长的key。**基本上,我们随机选择key,淘汰key效果很好。后来随机3个key改成一个配置项"N随机key"。但把默认值提高改成5个后效果大大提高。考虑到它的效果,你根本不用修改他。
# 缓存失效策略
策略有:定时删除策略,惰性删除策略,定期删除策略。
定时删除策略
在设置 key 的过期时间的同时,为该 key 创建一个定时器,让定时器在 key 的过期时间来临时,对 key 进行删除。
- 优点:保证内存尽快释放。
- 缺点:若 key 过多,删除这些 key 会占用很多 CPU 时间, 而且每个 key 创建一个定时器,性能影响严重。
惰性删除策略
key 过期的时候不删除,每次从数据库获取 key 的时候去检查是否过期,若过期,则删除,返回 null。
- 优点:CPU 时间占用比较少。
- 缺点:若 key 很长时间没有被获取, 将不会被删除,可能造成内存泄露。
定期删除策略
每隔一段时间执行一次删除(在 redis.conf 配置文件设置 hz,1s 刷新的频率)过期 key 操作。
- 优点:可以控制删除操作的时长和频率,来减少 CPU 时间占用,可以避免惰性删除时候内存泄漏的问题。
- 缺点:对内存友好方面,不如定时策略;对 CPU 友好方面,不如惰性策略
Redis 一般采用:惰性策略 + 定期策略两个相结合。
# 缓存命中率
# 缓存命中率简介
- 命中:
可以直接通过缓存获取到需要的数据。 - **不命中:**无法直接通过缓存获取到想要的数据,需要再次查询数据库或者其他数据存储载体的操作。原因
可能是由于缓存中根本不存在,或者缓存已经过期。
缓存命中率 = 缓存中获取数据次数/获取数据总次数
通常来说,缓存命中率越高,缓存的收益越高,应用的性能也就越好。表示使用缓存作用越好,性能越高(响应时间越短、吞吐量越高),并发能力也越好。
# 提高缓存命中率
重点关注访问频率高且时效性相对低一些的业务数据上,利用预加载(预热)、扩容、优化缓存粒度、更新缓存等手段来提高命中率。
通常的手段有:
- 缓存预加载
- 增加缓存存储量
- 调整缓存存储数据类型
- 提升缓存更新频次
# 案例
场景:数据库中有1000w的数据,而redis中只有50w数据,如何保证redis中10w数据都是热点数据?
方案:限定 Redis 占用的内存,Redis 会根据自身数据淘汰策略,留下热数据到内存。所以,计算一下 50W 数据大约占用的内存,然后设置一下 Redis 内存限制即可,并将淘汰策略为volatile-lru或者allkeys-lru。
设置Redis最大占用内存:打开redis配置文件,设置maxmemory参数,maxmemory是bytes字节类型
# In short... if you have slaves attached it is suggested that you set a lower
# limit for maxmemory so that there is some free RAM on the system for slave
# output buffers (but this is not needed if the policy is 'noeviction').
#
# maxmemory <bytes>
maxmemory 268435456
2
3
4
5
6
设置过期策略:
maxmemory-policy volatile-lru
# 问题
如果 AOF 文件的数据出现异常, Redis 服务怎么处理?
如果 AOF 文件出现异常, Redis 在重启的时候将会拒绝加载 AOF 文件,从而保证数据的一致性。这时候,可以试着对 AOF 文件进行修复:redis-check-aof -fix。
MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
Redis 内存数据集大小上升到一定大小的时候, 就会施行数据淘汰策略
Redis 的内存用完了会发生什么?
如果达到设置的上限, Redis 的写命令会返回错误信息(但是读命令还可以正常返回) 或者你可以将 Redis 当缓存来使用配置淘汰机制,当 Redis 达到内存上限时会冲刷掉旧的内容。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。 于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。