 sed命令替换匹配行
sed命令替换匹配行
# 简介
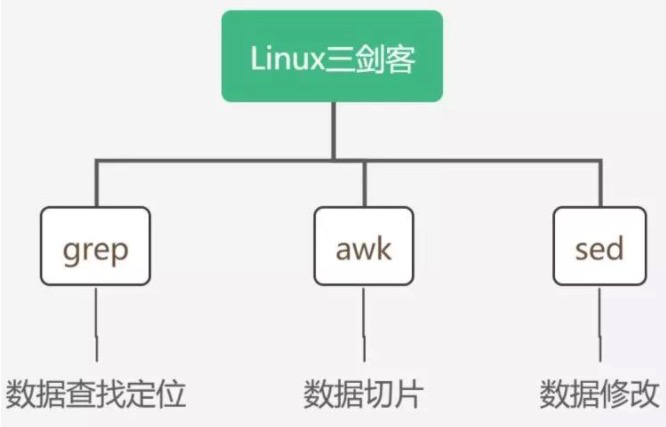
awk、grep、sed是linux操作文本的三大利器,合称文本三剑客,也是必须掌握的linux命令之一。三者的功能都是处理文本,但侧重点各不相同,其中属awk功能最强大,但也最复杂。
- grep更适合单纯的查找或匹配文本,
- sed更适合编辑匹配到的文本,
- awk更适合格式化文本,对文本进行较复杂格式处理。
# grep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红)。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
egrep = grep -E:扩展的正则表达式 (除了**< , > , \b** 使用其他正则都可以去掉\)
# sed
sed 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(patternspace ),接着用sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’ 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出或-i。
功能:主要用来自动编辑一个或多个文件, 简化对文件的反复操作
# awk
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
awk其实不仅仅是工具软件,还是一种编程语言。不过,本文只介绍它的命令行用法,对于大多数场合,应该足够用了。
# grep命令
Linux grep 命令用于查找文件里符合条件的字符串。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
# 语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示行数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
参数:
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
- -B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
- -c 或 --count : 计算符合样式的列数。
- -C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
- -d <动作> 或 --directories=<动作> : 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
- -e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式。
- -E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。
- -f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
- -F 或 --fixed-regexp : 将样式视为固定字符串的列表。
- -G 或 --basic-regexp : 将样式视为普通的表示法来使用。
- -h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。
- -H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
- -i 或 --ignore-case : 忽略字符大小写的差别。
- -l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。
- -L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。
- -n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
- -o 或 --only-matching : 只显示匹配PATTERN 部分。
- -q 或 --quiet或--silent : 不显示任何信息。
- -r 或 --recursive : 此参数的效果和指定"-d recurse"参数相同。
- -s 或 --no-messages : 不显示错误信息。
- -v 或 --invert-match : 显示不包含匹配文本的所有行。
- -V 或 --version : 显示版本信息。
- -w 或 --word-regexp : 只显示全字符合的列。
- -x --line-regexp : 只显示全列符合的列。
- -y : 此参数的效果和指定"-i"参数相同。
# 实例
1、在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test *file
结果如下所示:
$ grep test test* #查找前缀有“test”的文件包含“test”字符串的文件
testfile1:This a Linux testfile! #列出testfile1 文件中包含test字符的行
testfile_2:This is a linux testfile! #列出testfile_2 文件中包含test字符的行
testfile_2:Linux test #列出testfile_2 文件中包含test字符的行
2
3
4
2、以递归的方式查找符合条件的文件。例如,查找指定目录/etc/acpi 及其子目录(如果存在子目录的话)下所有文件中包含字符串"update"的文件,并打印出该字符串所在行的内容,使用的命令为:
grep -r update /etc/acpi
输出结果如下:
$ grep -r update /etc/acpi #以递归的方式查找“etc/acpi”
#下包含“update”的文件
/etc/acpi/ac.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of IO.)
Rather than
/etc/acpi/resume.d/85-anacron.sh:# (Things like the slocate updatedb cause a lot of
IO.) Rather than
/etc/acpi/events/thinkpad-cmos:action=/usr/sbin/thinkpad-keys--update
2
3
4
5
6
7
3、反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含test 的行,此时,使用的命令为:
grep -v test *test*
结果如下所示:
$ grep-v test* #查找文件名中包含test 的文件中不包含test 的行
testfile1:helLinux!
testfile1:Linis a free Unix-type operating system.
testfile1:Lin
testfile_1:HELLO LINUX!
testfile_1:LINUX IS A FREE UNIX-TYPE OPTERATING SYSTEM.
testfile_1:THIS IS A LINUX TESTFILE!
testfile_2:HELLO LINUX!
testfile_2:Linux is a free unix-type opterating system.
2
3
4
5
6
7
8
9
# sed命令【要点】
# 简介语法
使用sed命令替换匹配行; 替换文件中部分字段重写;
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
- -e
<script>或--expression=<script>以选项中指定的script来处理输入的文本文件。 - -f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
- -h或--help 显示帮助。
- -n或--quiet或--silent 仅显示script处理后的结果。
- -V或--version 显示版本信息。
动作说明:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :替换取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
示范:
文本直接替换
#把skip-grant-tables 变成 #skip-grant-tables
sed -i "s/\(skip-grant-tables\).*/#skip-grant-tables/" /etc/my.cnf
#时区America/Los_Angeles变成Asia/Shanghai时区
sed -i "" "s/Asia\/Shanghai/America\/Los_Angeles/" app/utils/date-utils.js
2
3
4
5
去除字符串中的空格
- 字符 's' 表示替换;
- 字符 '/' 表示作为分隔符;
- 字符 '^' 表示开头;
- 字符 '$' 表示结尾;
- 字符 '[ ]' 表示匹配指定字符范围内的任意单个字符,[ ]包含一个空格;
- 字符 '*' 作为通配符,匹配0个或任意多个;
- 字符 'g’ 表示全部匹配;
var=' aa bb '
echo "${#var}" # 12 其中,${#var}表示获取字符串的长度
#表示使用空字符匹配**行首为空格**的字符串;
sed ‘s/^[ ]*//g
#去除行尾空格
var2=$(echo "${var}" |sed 's/[ ]*$//g')
echo "${#var2}"# 10
#去除所有空格
var3=$(echo "${var}" |sed 's/[[:space:]]//g')
echo "${#var3}"# 4
2
3
4
5
6
7
8
9
10
11
12
13
其他相关
在定位行前面插入字符2
sed -i ‘/字符/i\字符2‘ file在定位行后插入字符2
sed -i ‘/字符/a\字符2’ file查找包含字符的行,并且把A替换为B
sed -i ‘/字符/s/A/B/g’ file把A替换为B
sed -i ‘s/A/B/g’删除括号(替换括号为空)
sed ‘s’[()]//g’把所有的大写转化为小写
sed ‘s/[A-Z]/\l&/g’\l在sed中是转换后面的字符为小写
&代指匹配的模式
将 test.txt 内每一行结尾若为 . 则换成 !
sed -i "" "s/\.$/\!/g" test.txt
# 单/双引号替换
在shell中, 使用sed进行替换的时候,因为替换命令本身就是在引号中的,所以书写的时候,就需要注意书写的格式,这里总结几种写法。简单的是 echo "this is''' test\" string" | sed $'s/\'//g'
# shell中使用sed替换单引号
echo "this is''' test\" string" | sed $'s/\'//g'
this is test" string
# shell中使用sed替换双引号
echo "this is''' test\" string" | sed $'s/\"//g'
this is''' test string
# shell中使用sed替换双引号和单引号
echo "this is''' test\" string" | sed "s/[\'\"]//g"
this is test string
# shell中使用sed替换双引号和单引号
echo "this is''' test\" string" | sed "s/[\x27\x22]//g"
this is test string
# shell中使用sed替换双引号和单引号
echo "this is''' test\" string" | sed $'s/[\'\"]//g'
this is test string
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 结合说明
# 将
test.txt文件内的以1开头的行,替换为"aa/bb"
sed -i ".bak" "s/1.*/aa\/bb/" test.txt
-i ".bak"是直接操作文件并添加.bak作为备份文件名称,如果不需要备份文件,则使用-i "";/s代表’“substitue”,即替换;1.*代表以1开头的所有字符串,.在正则表达式中表示所有字符;aa\/bb使用了转义字符表示aa/bb;注意最后还需要一个分界符/,否则会提示unterminated substitute in regular expression;
分界符/也可使用|,那么特殊符号就不需要转义字符了,命令就变成:
sed -i ".bak" "s|1.*|aa/bb|" test.txt如果需要在文件中替换多个相同的字符串,需要添加global参数g,即:
sed -i ".bak" "s/1.*/aa\/bb/g" test.txt #或者 sed -i ".bak" "s|1.*|aa/bb|g" test.txt1
2
3
# 以hello字符串为主,包含大写类型,一行多个hello等情况
sed (-l) 's/old_text/new_text/(g)' [file]: 输出文件[file]中每行第1个old_text替换成new_text的结果,最后加g表示替换所有匹配;➜ sed -l 's/hello/hi/' hello.txt hi world hi boys she is saying hi hi hello HELLO everyone ➜ sed 's/hello/hi/' hello.txt hi world hi boys she is saying hi hi hello HELLO everyone ➜ sed 's/hello/hi/g' hello.txt hi world hi boys she is saying hi hi hi HELLO everyone1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18sed -i "" 's/old_text/new_text/' [file]: 替换字符串并写入文件;➜ sed -i "" 's/hello/hi/' hello.txt ➜ cat hello.txt hi world hi boys she is saying hi hi hello -->由于未加g参数,所以第二个hello未替换 HELLO everyone1
2
3
4
5
6
7sed -e 's/old_text1/new_text1/' -e 's/old_text2/new_text2/' [file]: 对文件[file]内容将old_text1替换成new_text1或将old_text2替换成new_text2;➜ sed -e 's/boys/men/' -e 's/she/he/' hello.txt hi world hi men he is saying hi hi hello HELLO everyone1
2
3
4
5
6sed -n 'line_num,/^$/p' [file]: 打印从行号line_num到下一个空行之间的内容,/p表示打印;➜ sed -n '1,/^$/p' hello.txt hi world hi boys ➜ head -4 hello.txt hi world hi boys she is saying hi1
2
3
4
5
6
7
8
9sed -i "" '1,100d' 404.log:删除文件的前100行,注意mac上要加个空字符串sed -n '5,8p' 1156_success.txt:查看文件若干行;输出文件的5-8行sed -n '5,8p' 1156_success.txt >11.txt:输出文件的5-8行至11.txtcat 503.log |grep NewHomeActivity >503Home.log:从一个文件过滤出包含字符串的行到另一个文件find "$tmp" -type f -exec sed -i "s/${targetsubstring}/${newsubstring}/g" {} \;For support on both OSX and Linux, I use a simple if check to see if the bash script is running on OSX or Linux, and adjust the command's
-iargument based on that.if [[ "$OSTYPE" == "darwin"* ]]; then sed -i '' -e 's|$iconPath|images-theme-dark/$iconfile|g' "{}" else sed -i -e 's|$iconPath|images-theme-dark/$iconfile|g' "{}" fi1
2
3
4
5
# 案例
# 全路径替换
替换配置文件中baseApi地址:
获取当前脚本的路径:curDir=$(cd "$(dirname "$0")"; pwd)
以上面获取的路径,做绝对路径操作处理;
#!/bin/bash
###
# @Author: samy
# @email: yessz#foxmail.com
# @time: 2021-03-11 15:59:05
# @modAuthor: samy
# @modTime: 2021-03-12 16:18:04
# @desc: 构建部署脚本
# Copyright © 2015~2021 BDP FE
###
curDir=$(cd "$(dirname "$0")"; pwd)
distWebDir=dist/web
distAdmDir=dist/admin
echo "====wdp-web项目===环境依赖==node版本====="
node -v
echo "====wdp-web项目===环境依赖===="
npm i -g bower --registry=https://registry.npm.taobao.org
rm -rf ${curDir}/dist
mkdir -p ${curDir}/${distWebDir} ${curDir}/${distAdmDir}
cd ${curDir}/ambari-web
if [[ "$OSTYPE" == "darwin"* ]]; then
sed -i "" "s#^App.apiPrefix.*#App.apiPrefix = '/api/v1'; #g" ${curDir}/ambari-web/app/config.js
else
sed -i "s#^App.apiPrefix.*#App.apiPrefix = '/api/v1'; #g" ${curDir}/ambari-web/app/config.js
fi
echo "==wdp-web==web项目==config中的apiPrefix===替换成功===="
npm i --registry=https://registry.npm.taobao.org
npm run build
echo "==wdp-web==web项目===构建成功===="
cp -R public/* ${curDir}/${distWebDir}/
echo "==wdp-web==web项目===拷贝成功===="
cd ${curDir}/ambari-admin/main/resources/ui/admin-web/
bower install # 这一步下载估计会很慢
npm i --registry=https://registry.npm.taobao.org
npm run build
echo "==wdp-web==admin项目===构建成功===="
cp -R dist/* ${curDir}/${distAdmDir}/
echo "==wdp-web==admin项目===拷贝成功===="
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 替换单个key default value
#!/bin/bash
defaultFile=$(pwd)/env/default.env
targetFile=$(pwd)/env/en.env
curDir=$(cd "$(dirname "$0")"; pwd)
webDir=${curDir}/web
function getEnvConf() {
param=$1
value1=$(sed -E '/^#.*|^ *$/d' $defaultFile | sed s/[[:space:]]//g | awk -F "${param}=" "/${param}=/{print \$2}" | tail -n1)
value2=$(sed -E '/^#.*|^ *$/d' $targetFile | sed s/[[:space:]]//g | awk -F "${param}=" "/${param}=/{print \$2}" | tail -n1)
if [ ! -n "$value2" ]; then
value=$value1
else
value=$value2
fi
echo $value
}
replacePro() {
varKey=$2
defaultValue=$3
varValue=$4
echo $varKey $varValue $defaultValue
if [[ "$OSTYPE" == "darwin"* ]]; then
sed -i "" "s#^var ${varKey} = ${defaultValue}.*#var ${varKey} = ${varValue};#g" $1
else
sed -i "s#^var ${varKey} = ${defaultValue}.*#var ${varKey} = ${varValue};#g" $1
fi
}
isPro=$(getEnvConf isPro)
dafaultLang=$(getEnvConf dafaultLang)
isOnlyEn=$(getEnvConf isOnlyEn)
replacePro ${webDir}/app/conf.js isPro false $isPro
replacePro ${webDir}/app/conf.js dafaultLang 'zh' $dafaultLang
replacePro ${webDir}/app/conf.js isOnlyEn false $isOnlyEn
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 简化key value替换【推荐】
#!/bin/bash
defaultFile=$(pwd)/env/default.env
targetFile=$(pwd)/env/en.env
curDir=$(
cd "$(dirname "$0")"
pwd
)
webDir=${curDir}/web
function getEnvConf() {
param=$1
value1=$(sed -E '/^#.*|^ *$/d' $defaultFile | sed s/[[:space:]]//g | awk -F "${param}=" "/${param}=/{print \$2}" | tail -n1)
value2=$(sed -E '/^#.*|^ *$/d' $targetFile | sed s/[[:space:]]//g | awk -F "${param}=" "/${param}=/{print \$2}" | tail -n1)
if [ ! -n "$value2" ]; then
value=$value1
else
value=$value2
fi
echo $value
}
replacePro() {
varKey=$2
varValue=$3
echo $varKey $varValue
if [[ "$OSTYPE" == "darwin"* ]]; then
sed -i "" "s/\(${varKey} =\).*/\1 ${varValue};/" $1
else
sed -i "s#^var ${varKey} = ${defaultValue}.*#var ${varKey} = ${varValue};#g" $1
fi
}
isPro=$(getEnvConf isPro)
defaultLang=$(getEnvConf defaultLang)
isOnlyEn=$(getEnvConf isOnlyEn)
replacePro ${webDir}/app/conf.js isPro $isPro
replacePro ${webDir}/app/conf.js defaultLang $defaultLang
replacePro ${webDir}/app/conf.js isOnlyEn $isOnlyEn
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# awk命令
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
# 语法
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
2
3
选项参数说明:
- -F fs or --field-separator fs 指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
- -v var=value or --asign var=value 赋值一个用户定义变量。
- -f scripfile or --file scriptfile 从脚本文件中读取awk命令。
- -mf nnn and -mr nnn 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
- -W compact or --compat, -W traditional or --traditional 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
- -W copyleft or --copyleft, -W copyright or --copyright 打印简短的版权信息。
- -W help or --help, -W usage or --usage 打印全部awk选项和每个选项的简短说明。
- -W lint or --lint 打印不能向传统unix平台移植的结构的警告。
- -W lint-old or --lint-old 打印关于不能向传统unix平台移植的结构的警告。
- -W posix 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替^和^=;fflush无效。
- -W re-interval or --re-inerval 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
- -W source program-text or --source program-text 使用program-text作为源代码,可与-f命令混用。
- -W version or --version 打印bug报告信息的版本。
# 基本用法
log.txt文本内容如下:
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo
2
3
4
用法一:
awk '{[pattern] action}' {filenames} # 行匹配语句 awk '' 只能用单引号
实例:
# 每行按空格或TAB分割,输出文本中的1、4项
$ awk '{print $1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
# 格式化输出
$ awk '{printf "%-8s %-10s\n",$1,$4}' log.txt
---------------------------------------------
2 a
3 like
This's
10 orange,apple,mongo
2
3
4
5
6
7
8
9
10
11
12
13
14
15
用法二:
awk -F #-F相当于内置变量FS, 指定分割字符
实例:
# 使用","分割
$ awk -F, '{print $1,$2}' log.txt
---------------------------------------------
2 this is a test
3 Are you like awk
This's a test
10 There are orange apple
# 或者使用内建变量
$ awk 'BEGIN{FS=","} {print $1,$2}' log.txt
---------------------------------------------
2 this is a test
3 Are you like awk
This's a test
10 There are orange apple
# 使用多个分隔符.先使用空格分割,然后对分割结果再使用","分割
$ awk -F '[ ,]' '{print $1,$2,$5}' log.txt
---------------------------------------------
2 this test
3 Are awk
This's a
10 There apple
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
用法三:
awk -v # 设置变量
实例:
$ awk -va=1 '{print $1,$1+a}' log.txt
---------------------------------------------
2 3
3 4
This's 1
10 11
$ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt
---------------------------------------------
2 3 2s
3 4 3s
This's 1 This'ss
10 11 10s
2
3
4
5
6
7
8
9
10
11
12
用法四:
awk -f {awk脚本} {文件名}
实例:
$ awk -f cal.awk log.txt
# 运算符
| 运算符 | 描述 |
|---|---|
| = += -= *= /= %= ^= **= | 赋值 |
| ?: | C条件表达式 |
| || | 逻辑或 |
| && | 逻辑与 |
| ~ 和 !~ | 匹配正则表达式和不匹配正则表达式 |
| < <= > >= != == | 关系运算符 |
| 空格 | 连接 |
| + - | 加,减 |
| * / % | 乘,除与求余 |
| + - ! | 一元加,减和逻辑非 |
| ^ *** | 求幂 |
| ++ -- | 增加或减少,作为前缀或后缀 |
| $ | 字段引用 |
| in | 数组成员 |
过滤第一列大于2的行
$ awk '$1>2' log.txt #命令
#输出
3 Are you like awk
This's a test
10 There are orange,apple,mongo
2
3
4
5
过滤第一列等于2的行
$ awk '$1==2 {print $1,$3}' log.txt #命令
#输出
2 is
2
3
过滤第一列大于2并且第二列等于'Are'的行
$ awk '$1>2 && $2=="Are" {print $1,$2,$3}' log.txt #命令
#输出
3 Are you
2
3
# 内建变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段分隔符,默认值与输入字段分隔符一致。 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
$ awk 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt
FILENAME ARGC FNR FS NF NR OFS ORS RS
---------------------------------------------
log.txt 2 1 5 1
log.txt 2 2 5 2
log.txt 2 3 3 3
log.txt 2 4 4 4
$ awk -F\' 'BEGIN{printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n","FILENAME","ARGC","FNR","FS","NF","NR","OFS","ORS","RS";printf "---------------------------------------------\n"} {printf "%4s %4s %4s %4s %4s %4s %4s %4s %4s\n",FILENAME,ARGC,FNR,FS,NF,NR,OFS,ORS,RS}' log.txt
FILENAME ARGC FNR FS NF NR OFS ORS RS
---------------------------------------------
log.txt 2 1 ' 1 1
log.txt 2 2 ' 1 2
log.txt 2 3 ' 2 3
log.txt 2 4 ' 1 4
# 输出顺序号 NR, 匹配文本行号
$ awk '{print NR,FNR,$1,$2,$3}' log.txt
---------------------------------------------
1 1 2 this is
2 2 3 Are you
3 3 This's a test
4 4 10 There are
# 指定输出分割符
$ awk '{print $1,$2,$5}' OFS=" $ " log.txt
---------------------------------------------
2 $ this $ test
3 $ Are $ awk
This's $ a $
10 $ There $
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 使用正则,字符串匹配
# 输出第二列包含 "th",并打印第二列与第四列
$ awk '$2 ~ /th/ {print $2,$4}' log.txt
---------------------------------------------
this a
2
3
4
~ 表示模式开始。// 中是模式。
# 输出包含 "re" 的行
$ awk '/re/ ' log.txt
---------------------------------------------
3 Are you like awk
10 There are orange,apple,mongo
2
3
4
5
# 忽略大小写
$ awk 'BEGIN{IGNORECASE=1} /this/' log.txt
---------------------------------------------
2 this is a test
This's a test
2
3
4
# 模式取反
$ awk '$2 !~ /th/ {print $2,$4}' log.txt
---------------------------------------------
Are like
a
There orange,apple,mongo
$ awk '!/th/ {print $2,$4}' log.txt
---------------------------------------------
Are like
a
There orange,apple,mongo
2
3
4
5
6
7
8
9
10
# awk脚本
关于 awk 脚本,我们需要注意两个关键词 BEGIN 和 END。
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
$ cat score.txt
Marry 2143 78 84 77
Jack 2321 66 78 45
Tom 2122 48 77 71
Mike 2537 87 97 95
Bob 2415 40 57 62
2
3
4
5
6
我们的 awk 脚本如下:
$ cat cal.awk
#!/bin/awk -f
#运行前
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#运行中
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#运行后
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
我们来看一下执行结果:
$ awk -f cal.awk score.txt
NAME NO. MATH ENGLISH COMPUTER TOTAL
---------------------------------------------
Marry 2143 78 84 77 239
Jack 2321 66 78 45 189
Tom 2122 48 77 71 196
Mike 2537 87 97 95 279
Bob 2415 40 57 62 159
---------------------------------------------
TOTAL: 319 393 350
AVERAGE: 63.80 78.60 70.00
2
3
4
5
6
7
8
9
10
11
# 另外一些实例
AWK 的 hello world 程序为:
BEGIN { print "Hello, world!" }
计算文件大小
$ ls -l *.txt | awk '{sum+=$5} END {print sum}'
--------------------------------------------------
666581
2
3
从文件中找出长度大于 80 的行:
awk 'length>80' log.txt
打印九九乘法表
seq 9 | sed 'H;g' | awk -v RS='' '{for(i=1;i<=NF;i++)printf("%dx%d=%d%s", i, NR, i*NR, i==NR?"\n":"\t")}'
# 相关链接
https://www.cnblogs.com/binliubiao/p/13471975.html
https://www.runoob.com/linux/linux-comm-grep.html
https://www.runoob.com/linux/linux-comm-sed.html
https://www.runoob.com/linux/linux-comm-awk.html