 js事件循环及优化
js事件循环及优化
# 异步
# async/await
详细见【js异步】
# 事件机制
# 单线程
# 为什么JavaScript是单线程?
JavaScript语言的一大特点就是单线程,也就是说,同一个时间只能做一件事。那么,为什么JavaScript不能有多个线程呢?这样能提高效率啊。
JavaScript的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成了这门语言的核心特征,将来也不会改变。
为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
JavaScript从诞生起就是单线程。原因大概是不想让浏览器变得太复杂,因为多线程需要共享资源、且有可能修改彼此的运行结果,对于一种网页脚本语言来说,这就太复杂了。后来就约定俗成,JavaScript为一种单线程语言。(Worker API可以实现多线程,但是JavaScript本身始终是单线程的。)
# Event Loop
# 简介
JS 的执行是单线程的,所谓的单线程就是事件任务要排队执行,前一个任务结束,才会执行后一个任务,这就是同步任务,为了避免前一个任务执行了很长时间还没结束,那下一个任务就不能执行的情况,引入了异步任务的概念。
简单说,就是在程序中设置两个线程:
- 一个负责程序本身的运行,称为"主线程";
- 另一个负责主线程与其他进程(主要是各种I/O操作)的通信,被称为"Event Loop线程"(可译为"消息线程");
# 流程
JS 运行机制简单来说可以按以下几个步骤:
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。主线程发现有异步任务,就在“任务队列”之中加入一个任务事件。
一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列"(先进先出原则)。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
主线程不断重复上面的第三步。也就是常说的事件循环(Event Loop)。
一旦执行栈为空,Event Loop 就会从 Task 队列中拿出需要执行的代码并放入执行栈中执行,所以本质上来说 JS 中的异步还是同步行为。
# 浏览器与Node的Event Loop差异
浏览器环境下,microtask的任务队列是每个macrotask执行完之后执行。 而在Node.js中,microtask会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行microtask队列的任务
浏览器和Node 环境下,microtask 任务队列的执行时机不同
- 浏览器端,microtask 在事件循环的 macrotask 执行完之后执行 ,间接插入;
- Node端,microtask 在事件循环的各个阶段之间执行,阶段插入;
# 浏览器
浏览器中相对简单,共有两个事件队列,当主线程空闲时会清空Microtask queue(微任务队列)依次执行Task Queue(宏任务队列)中的回调函数,每执行完一个之后再清空Microtask queue。不同类型的任务进入对应的Event Queue; js借助Event Loop实现异步,实质是用同步的方法去模拟的
# 执行顺序
从宏任务的script(全局任务)(同步任务)开始,然后按序执行所有的微任务,之后再执行宏任务最前的任务(过程中遇到微任务依次加入任务队列),完成后再读取执行微任务,以此类推;
# 事件循环的流程
- 所有任务都在主线程上执行,形成一个执行栈。
- 主线程发现有异步任务,就在“任务队列”之中加入一个任务事件。
- 一旦“执行栈”中的所有同步任务执行完毕,系统就会读取“任务队列”(先进先出原则)。那些对应的异步任务,结束等待状态,进入执行栈并开始执行。
- 主线程不断重复上面的第三步,这样的一个循环称为事件循环。
# Event loop流程(加入了任务)
如果任务队列中有多个异步任务,那么先执行哪个任务呢?于是在异步任务中,也进行了等级划分,分为宏任务(macrotask)和微任务(microtask);
- 执行同步代码,这属于宏任务(macrotask);(script第一步)
- 执行过程中如果遇到微任务就加入微任务队列,遇到宏任务就加入宏任务队列;
- 执行栈为空,查询是否有微任务需要执行;宏任务执行完毕后,检查当前微任务队列,如果有,就依次执行(一轮事件循环结束)
- 必要的话渲染 UI;
- 然后开始下一轮 Event loop,执行宏任务中的异步代码;
通过上述的 Event loop 顺序可知,如果宏任务中的异步代码有大量的计算并且需要操作 DOM 的话,为了更快的 界面响应,我们可以把操作 DOM 放入微任务中。
图示流程:
 
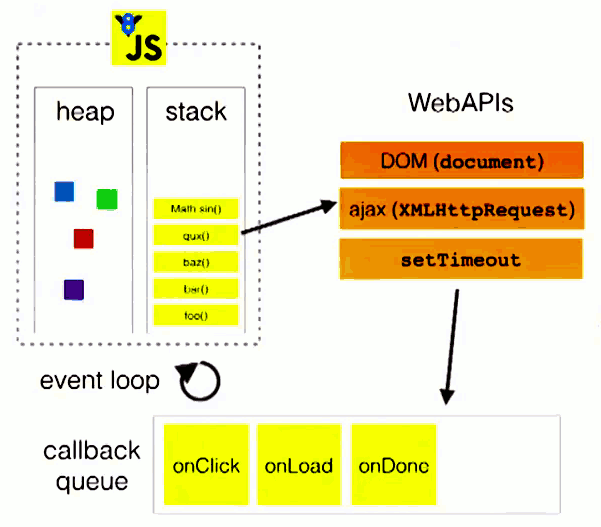
上图中,主线程运行的时候,产生堆(heap)和栈(stack),栈中的代码调用各种外部API,它们在"任务队列"中加入各种事件(click,load,done)。只要栈中的代码执行完毕,主线程就会去读取"任务队列",依次执行那些事件所对应的回调函数。执行栈中的代码(同步任务),总是在读取"任务队列"(异步任务)之前执行
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function (){};
req.onerror = function (){};
req.send();
2
3
4
5
上面代码中的req.send方法是Ajax操作向服务器发送数据,它是一个异步任务,意味着只有当前脚本的所有代码执行完,系统才会去读取"任务队列"。所以,它与下面的写法等价。
var req = new XMLHttpRequest();
req.open('GET', url);
req.send();
req.onload = function (){};
req.onerror = function (){};
2
3
4
5
也就是说,指定回调函数的部分(onload和onerror),在send()方法的前面或后面无关紧要,因为它们属于执行栈的一部分,系统总是执行完它们,才会去读取"任务队列"。
# nodejs
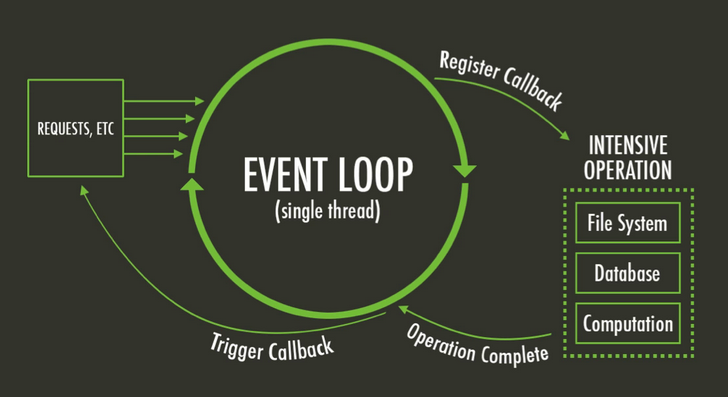
node中机制和浏览器有一些差异。node中的task queue是分为几个阶段,清空micro-task是在一个阶段结束之后(浏览器中是每一个任务结束之后),各个阶段如下: 这里我们主要关注其中的3个阶段:timer、poll和check,其中poll队列相对复杂:
图示比较:


# Node.js的运行机制【解调执回】
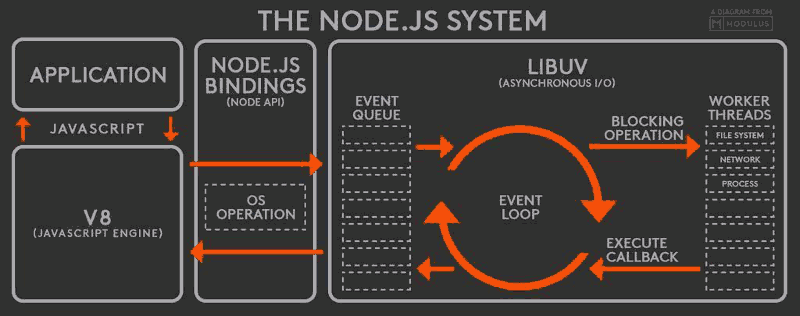
4个步骤,解调执回
- V8引擎解析JavaScript脚本。
- 解析后的代码,调用Node API。
- libuv库 (opens new window)负责Node API的执行。它将不同的任务分配给不同的线程,形成一个Event Loop(事件循环),以异步的方式将任务的执行结果返回给V8引擎。
- V8引擎再将结果返回给用户。
# 6个阶段【PCCTII】【要点】
其中libuv引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
从上图中,大致看出node中的事件循环的顺序:
外部输入数据【第0步】-->轮询阶段(poll)【第1步】-->检查阶段(check)【第2步】-->关闭事件回调阶段(close callback)【第3步】-->
定时器检测阶段(timer)【第4步】-->I/O事件回调阶段(I/O callbacks)【第5步】-->闲置阶段(idle, prepare)【第6步】-->轮询阶段(按照该顺序反复运行)...
- timers 阶段:这个阶段执行timer(setTimeout、setInterval)的回调【第4步】
- I/O callbacks 阶段:处理一些上一轮循环中的少数未执行的 I/O 回调【第5步】
- idle, prepare 阶段:仅node内部使用【第6步】
- poll 阶段:获取新的I/O事件, 适当的条件下node将阻塞在这里【第1步】
- check 阶段:执行 setImmediate() 的回调【第2步】
- close callbacks 阶段:执行 socket 的 close 事件回调【第3步】
注意:上面六个阶段都不包括 process.nextTick()(下文会介绍)
# process.nextTick()
这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段(6个)完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行。
process.nextTick 并不属于 Event loop 中的某一个阶段, 而是在 Event loop 的每一个阶段结束后, 直接执行 nextTickQueue 中插入的 "Tick", 并且直到整个 Queue 处理完;
process.nextTick 是 Nodejs 的 API,比 Promise 更早执行。
事实上,process.nextTick 是不会进入异步队列的,而是直接在主线程队列尾强插一个任务,虽然不会阻塞主线程,但是会阻塞异步任务的执行,如果有嵌套的 process.nextTick,那异步任务就永远没机会被执行到了。
使用的时候要格外小心,除非你的代码明确要在本次事件循环结束之前执行,否则使用 setImmediate 或者 Promise 更保险。
# Micro-Task 与 Macro-Task
# 简介
如果任务队列中有多个异步任务,那么先执行哪个任务呢?于是在异步任务中,也进行了等级划分,分为宏任务(macrotask)和微任务(microtask);不同的API注册的任务会依次进入自身对应的队列中,然后等待事件循环将它们依次压入执行栈中执行。
# 分类
浏览器端事件循环中的异步队列有两种:macro(宏任务)队列和 micro(微任务)队列。宏任务队列可以有多个,微任务队列只有一个。 在 ES6 规范中,microtask 称为 jobs,macrotask 称为 task。【2主微】【超红】
规范中规定 task 分为两大类,分别是宏任务(macro task)和微任务 (micro task),并且每个 macro task 结束后,都要清空所有的 micro task。 想起来vue中的nextTick的内部实现;【PM SS】
常见的micro-task(微任务)
比如:process.nextTick, promise.then(),Object.observe(已废弃)、MutationObserver(html5新特性) 等。 process.nextTick优先级高于Promise.then
常见的macro-task(宏任务)
比如:script(整体代码)、setImmediate、setTimeout、setInterval、I/O 操作、UI 渲染(rendering)、promise中的executor等。
process.nextTick和setImmidate是只支持Node环境的。
在浏览器环境中
常见的创建 macro task 的方法有
- setTimeout、setInterval、postMessage、MessageChannel(队列优先于setTimeiout执行)
- 网络请求IO
- 页面交互:DOM、鼠标、键盘、滚动事件
- 页面渲染
常见的创建 micro task 的方法
- Promise.then
- MutationObserve
- process.nexttick
| 宏任务 | 浏览器 | Node |
|---|---|---|
| I/O | ✅ | ✅ |
| setTimeout | ✅ | ✅ |
| setInterval | ✅ | ✅ |
| setImmediate | ❌ | ✅ |
| requestAnimationFrame | ✅ | ❌ |
| 微任务 | 浏览器 | Node |
|---|---|---|
| Promise.prototype.then catch finally | ✅ | ✅ |
| process.nextTick | ❌ | ✅ |
| MutationObserver | ✅ | ❌ |
宏任务中包括了 script ,浏览器会先执行一个宏任务,接下来有异步代码的话就先执行微任务。【要点】
应该理解为:macro 取一个宏任务;micro 清空微任务队列
一次执行多个微任务;但是一次只能执行一个宏任务;【三步走:1:同步;2:微任务;3:宏任务;】
用一段代码形象介绍 task的执行顺序:
for (macroTask of macroTaskQueue) {
handleMacroTask();
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}
2
3
4
5
6
# 定时器
# 简介
定时器功能主要由setTimeout()和setInterval()这两个函数来完成,它们的内部运行机制完全一样,区别在于前者指定的代码是一次性执行,后者则为反复执行
setTimeout
setTimeout(fn,0)的含义是,指定某个任务在主线程最早可得的空闲时间执行,也就是说,尽可能早得执行。它在"任务队列"的尾部添加一个事件,因此要等到同步任务和"任务队列"现有的事件都处理完,才会得到执行。
HTML5标准规定了setTimeout()的第二个参数的最小值(最短间隔),不得低于4毫秒,如果低于这个值,就会自动增加。在此之前,老版本的浏览器都将最短间隔设为10毫秒。另外,对于那些DOM的变动(尤其是涉及页面重新渲染的部分),通常不会立即执行,而是每16毫秒执行一次。这时使用requestAnimationFrame()【RAF】的效果要好于setTimeout()。
需要注意的是,setTimeout()只是将事件插入了"任务队列",必须等到当前代码(执行栈)执行完,主线程才会去执行它指定的回调函数。要是当前代码耗时很长,有可能要等很久,所以并没有办法保证,回调函数一定会在setTimeout()指定的时间执行。
setImmediate与setTimeout
- 二者非常相似,区别主要在于调用时机不同。
- setImmediate 设计在poll阶段完成时执行,即check阶段;
- setTimeout 设计在poll阶段为空闲时,且设定时间到达后执行,但它在timer阶段执行
- process.nextTick() 在当前调用栈结束后立即处理; nextTick()的回调函数执行的优先级要高于setImmediate();
- 在具体实现上,process.nextTick()的回调函数保存在一个数组中, setImmediate()的结果则是保存在链表中. 在行为上,process.nextTick()在每轮循环中会将数组中的回调函数全部执行完. 而setImmediate()在每轮循环中执行链表中的一个回调函数.
- 尽量使用setImmediate(); setImmediate 一旦轮询阶段完成,执行回调函数; setTimeout() 在某个时间值后尽快执行函数; 跟是否同步及异步有关
- 重要的区别:setImmediate回调只会等待事件队列中的I/O事件被处理完就会执行, 而setTimeout回调则会等待所有事件被处理完才会执行
# setImmediate与setTimeout
setTimeout(() => {
console.log('setTimeout');
}, 0);
setImmediate(() => {
console.log('setImmediate');
})
// 这里可能会输出 setTimeout,setImmediate;可能也会相反的输出,这取决于性能
// 因为可能进入 event loop 用了不到 4 毫秒,这时候会执行 setImmediate;否则会执行 setTimeout
var fs = require('fs')
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
}); //setImmediate,setTimeout
// 因为 readFile 的回调在 poll 中执行,发现有 setImmediate ,所以会立即跳到 check 阶段执行回调
// 再去 timer 阶段执行 setTimeout;所以以上输出一定是 setImmediate,setTimeout
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
对于以上代码来说,setTimeout 可能执行在前,也可能执行在后。
首先 setTimeout(fn, 0) === setTimeout(fn, 4),这是由源码决定的; 进入事件循环也是需要成本的,如果在准备时候花费了大于 4ms 的时间,那么在 timer 阶段就会直接执行 setTimeout 回调;
如果准备时间花费小于 4ms,那么就是 setImmediate 回调先执行了;
但当二者在异步i/o callback内部调用时,总是先执行setImmediate,再执行setTimeout;
# 结论
- 在 文件I/O 、 网络I/O中 setImmediate会 先于 settimeout ;
- 否则一般情况下 setTimeout 会先于 setImmediate;
# 性能比较
通过上面的解释, 我们大致能看出, setImmediate(callback)执行效率会优于setTimeout(callback, 0), 事实也的确如此, 下面是一段简单的测试代码:
const Suite = require("benchmark").Suite;
const suite = new Suite();
suite.add(
"setImmediate()",
deferred => setImmediate(() => deferred.resolve()),
{ defer: true }
);
suite.add(
"setTimeout(callback, 0)",
deferred => setTimeout(() => deferred.resolve(), 0),
{ defer: true }
);
suite
.on("cycle", event => console.log(event.target.toString()))
.on("complete", () =>
console.log(`Fastest is ${suite.filter("fastest").map("name")}`)
)
.run({ async: true });
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
使用Node 10.3.0环境运行的输出结果是:
setImmediate() x 704,985 ops/sec ±1.03% (83 runs sampled)
setTimeout(callback,0) x 645 ops/sec ±1.06% (61 runs sampled)
Fastest is setImmediate()
2
3
可以看到setImmediate运行效率是setTimeout的1000倍! 除了检查机制不一样外, W3C规范也对setTimeout的多层嵌套运行做了限制:
Timers can be nested; after five such nested timers, however, the interval is forced to be at least four milliseconds.
当有五层以上的setTimeout嵌套时, 延迟必须大于等于4毫秒!
# 示例
console.log('start');
setImmediate(() => {
console.log('--setImmediate-->');
})
setTimeout(() => {
console.log('--setTimeout-->');
}, 0)
// 注意: 每次事件轮询后,在额外的I/O执行前,next tick队列都会优先执行。
// 递归调用nextTick callbacks 会阻塞任何I/O操作,就像一个while(true); 循环一样。
process.nextTick(() => {
console.log('--nextTick-->');
process.nextTick(() => {
console.log('--nextTick.nextTick-->');
})
})
console.log('scheduled');
// start
// scheduled
// --nextTick-->
// --nextTick.nextTick-->
// --setTimeout-->
// --setImmediate-->
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
//加入两个nextTick()的回调函数
process.nextTick(function () {
console.log('nextTick延迟执行1');
});
process.nextTick(function () {
console.log('nextTick延迟执行2');
})
//加入两个setImmediate()的回调函数
setImmediate(function () {
console.log('setImmediate延迟执行1');
process.nextTick(function () {//进入下次循环
console.log("强势插入!!");
});
});
setImmediate(function () {
console.log("setImmediate延迟执行2");
});
console.log("正常执行");
// 正常执行
// nextTick延迟执行1
// nextTick延迟执行2
// setImmediate延迟执行1
// setImmediate延迟执行2
// 强势插入!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
setImmediate(function (){
setImmediate(function A() {
console.log(1);
setImmediate(function B(){console.log(2);});
});
setTimeout(function timeout() {
console.log('TIMEOUT FIRED');
}, 0);
});// 1 TIMEOUT FIRED 2
2
3
4
5
6
7
8
9
# setImmediate与process.nextTick
process.nextTick和setImmediate的一个重要区别:多个process.nextTick语句总是在当前"执行栈"一次执行完,多个setImmediate可能则需要多次loop才能执行完。事实上,这正是Node.js 10.0版添加setImmediate方法的原因,否则像下面这样的递归调用process.nextTick,将会没完没了,主线程根本不会去读取"事件队列"!
process.nextTick(function foo() {
process.nextTick(foo);
});
2
3
事实上,现在要是你写出递归的process.nextTick,Node.js会抛出一个警告,要求你改成setImmediate。
另外,由于process.nextTick指定的回调函数是在本次"事件循环"触发,而setImmediate指定的是在下次"事件循环"触发,所以很显然,前者总是比后者发生得早,而且执行效率也高(因为不用检查"任务队列")。
# 示例分析
new Promise(resolve => {
resolve(1);
Promise.resolve().then(() => console.log(2));
console.log(4);
}).then(t => console.log(t));
console.log(3);//最后输出的顺序是4 3 2 1。
2
3
4
5
6
分析过程:
- 首先new Promise执行,resolve(1)表示创建的promise对象的状态变为resolved
- Promise.resolve()相当于创建了一个promise对象,then里面的匿名回调函数进入微任务队列,此时的微任务队列是
[() => console.log(2)] - 输出 4
- new Promise的then函数里面的匿名回调进入微任务队列, 此时的微任务队列是
[() => console.log(2), t => console.log(t)] - 输出 3
console.log('start')
setTimeout(function() {
console.log('timeout');
}, 0)
new Promise(function(resolve) {
console.log('promise');
//注意这边调用resolve//不然then方法不会执行
resolve()
}).then(function() {
console.log('then');
})
console.log('end');
// start
// promise
// end
// then
// timeout
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
分析一下执行流程:
- 刚开始打印
start - 遇到setTimeout,放入宏任务中,等待执行
- 遇到new Promise的回调函数,同步执行,打印
promise - 当resolve后,then方法会放入微任务,等待执行
- 打印
end,这时整个执行栈清空了,宏任务和微任务队列各有一个回调方法 - 先执行微任务队列,打印
then - 执行宏任务,打印
timeout
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
new Promise((resolve) => {
console.log('Promise')
resolve()
}).then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start => Promise => script end => promise1 => promise2 => setTimeout
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
集合promise及async的示例及分析:
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
async1()
console.log('script end')
2
3
4
5
6
7
8
9
10
因此,如果把上面代码进行如下改写,会好理解很多:
async function async1() {
console.log('async1 start')
new Promise(function(resolve){
console.log('async2')
resolve()
}).then(function(){
console.log('async1 end')
})
}
async1()
console.log('script end')
//async1 start –> async2 –> script end –> async1 end。
2
3
4
5
6
7
8
9
10
11
12
最后完整示例:
async function async1() {
console.log('async1 start');//2
await async2();
console.log('async1 end');//7
}
async function async2() {
console.log('async2');//3
}
console.log('script start');//1
setTimeout(function() {
console.log('setTimeout');//9
}, 0);
async1();
new Promise(function(resolve) {
console.log('promise1');//4
resolve();
}).then(function() {
console.log('promise2');//8
});
process.nextTick(() => {
console.log('nextTick');//6
})
console.log('script end');//5
// script start
// async1 start
// async2
// promise1
// script end
// promise2
// async1 end
// setTimeOut
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
分析上面示例: 一次执行多个微任务;但是一次只能执行一个宏任务后再检查
- 输出
script start - WebAPIs在0s(哦,好像最短是4ms)之后把
setTimeout里面的匿名回调函数丢进宏任务队列,简记为['setTimeout'](请记得丢进任务队列里的是回调函数,函数!) - 输出
async1 start - 输出
async2 - 要输出
async1 end代码被丢进微任务队列,此时的微任务队列为['async1 end'] - 输出
promise1 promise对象状态变为resolvedpromise.then里的匿名函数进入微任务队列,此时的微任务队列为['async1 end', 'promise2']nextTick插队到微任务队列对首,['nextTick', 'async1 end', 'promise2']- 输出
script end - 执行栈空
- 输出
nextTick - 输出
async1 end - 输出
promise2 - 微任务队列为空
- 输出
setTimeout
setTimeout(function(){console.log(1)},0);
new Promise(function(resolve,reject){
console.log(2);
resolve();
}).then(function(){console.log(3)
}).then(function(){console.log(4)});
process.nextTick(function(){console.log(5)});
console.log(6);
//输出2,6,5,3,4,1
2
3
4
5
6
7
8
9
# 其他
# requestAnimationFrame(RAF)
requestAnimationFrame 并不是定时器,但和 setTimeout 很相似,在没有 requestAnimationFrame 的浏览器一般都是用 setTimeout 模拟。
requestAnimationFrame 跟屏幕刷新同步,大多数屏幕的刷新频率都是 60Hz,对应的 requestAnimationFrame 大概每隔 16.7ms 触发一次,如果屏幕刷新频率更高,requestAnimationFrame 也会更快触发。基于这点,在支持 requestAnimationFrame 的浏览器还使用 setTimeout 做动画显然是不明智的。
在不支持 requestAnimationFrame 的浏览器,如果使用 setTimeout/setInterval 来做动画,最佳延迟时间也是 16.7ms。 如果太小,很可能连续两次或者多次修改 dom 才一次屏幕刷新,这样就会丢帧,动画就会卡;如果太大,显而易见也会有卡顿的感觉。
有趣的是,第一次触发 requestAnimationFrame 的时机在不同浏览器也存在差异,Edge 中,大概 16.7ms 之后触发,而 Chrome 则立即触发,跟 setImmediate 差不多。按理说 Edge 的实现似乎更符合常理。
(function testRequestAnimationFrame() {
const label = 'requestAnimationFrame';
console.time(label);
requestAnimationFrame(() => {
console.timeEnd(label);
});
})();
2
3
4
5
6
7
Edge 输出:requestAnimationFrame: 16.66 毫秒
Chrome 输出:requestAnimationFrame: 0.698ms
但相邻两次 requestAnimationFrame 的时间间隔大概都是 16.7ms,这一点是一致的。当然也不是绝对的,如果页面本身性能就比较低,相隔的时间可能会变大,这就意味着页面达不到 60fps。
# 内存管理机制
# 调用栈信息【事件环】
览器环境下 JavaScript 的异步执行机制,即事件循环机制, JavaScript 主线程不断的循环往复的从任务队列中读取任务(异步事件回调),放入调用栈中执行。调用栈又称执行上下文栈(执行栈),是用来管理函数执行上下文的栈结构。
在浏览器中获取调用栈信息 两种方式:
- 一种是断点调试,这种很简单,我们日常开发中都用过。
- 一种是
console.trace()
function sum(){
return add()
}
function add() {
console.trace()
return 1
}
sum()// 函数调用
2
3
4
5
6
7
8
# 总体流程机制【要点】
JavaScript 的存储机制分为代码空间、栈空间以及堆空间,代码空间用于存放可执行代码,栈空间用于存放基本类型数据和引用类型地址,堆空间用于存放引用类型数据,当调用栈中执行完成一个执行上下文时,需要进行垃圾回收该上下文以及相关数据空间,存放在栈空间上的数据通过 ESP 指针来回收,存放在堆空间的数据通过副垃圾回收器(新生代)与主垃圾回收器(老生代)来回收。
# 为啥要垃圾回收
在Chrome中,V8被限制了内存的使用(64位约1.4G/1464MB , 32位约0.7G/732MB),为什么要限制呢?
- 表层原因:V8最初为浏览器而设计,不太可能遇到用大量内存的场景
- 深层原因:V8的垃圾回收机制的限制(如果清理大量的内存垃圾是很耗时间,这样回引起JavaScript线程暂停执行的时间,那么性能和应用直线下降)
前面说到栈内的内存,操作系统会自动进行内存分配和内存释放,而堆中的内存,由JS引擎(如Chrome的V8)手动进行释放,当我们的代码没有按照正确的写法时,会使得JS引擎的垃圾回收机制无法正确的对内存进行释放(内存泄露),从而使得浏览器占用的内存不断增加,进而导致JavaScript和应用、操作系统性能下降。
# JS 内存机制【要点】
JavaScript 中的内存空间主要分为三种类型:
- 代码空间:主要用来存放可执行代码;
- 栈空间:调用栈的存储空间就是栈空间。
- 堆空间
代码空间主要用来存放可执行代码的。栈空间及堆空间主要用来存放数据的。接下来我们主要介绍栈空间及堆空间。
JavaScript 中的变量类型有 8 种,可分为两种:基本类型、引用类型
基本类型:【SSBNNU BO】
symbolstringbooleannumbernullundefinedbigint
引用类型:
object
其中,基本类型是保存在栈内存中的简单数据段,而引用类型保存在堆内存中。
# 栈空间
基本类型在内存中占有固定大小的空间,所以它们的值保存在栈空间,我们通过 按值访问 。
一般栈空间不会很大。
# 堆空间
引用类型,值大小不固定,但指向值的指针大小(内存地址)是固定的,所以把对象放入堆中,将对象的地址放入栈中,这样,在调用栈中切换上下文时,只需要将指针下移到上个执行上下文的地址就可以了,同时保证了栈空间不会很大。
当查询引用类型的变量时, 先从栈中读取内存地址, 然后再通过地址找到堆中的值。对于这种,我们把它叫做 按引用访问 。
一般堆内存空间很大,能存放很多数据,但它内存分配与回收都需要花费一定的时间。
举个例子帮助理解一下:
var a = 1
function foo() {
var b = 2
var c = { name: 'an' }
}
// 函数调用
foo()
2
3
4
5
6
7
8
基本类型(栈空间)与引用类型(堆空间)的存储方式决定了:基本类型赋值是值赋值,而引用类型赋值是地址赋值。
// 值赋值
var a = 1
var b = a
a = 2
console.log(b)
// 1
// b 不变
// 地址赋值
var a1 = {name: 'an'}
var b1 = a1
a1.name = 'bottle'
console.log(b1)
// {name: "bottle"}
// b1 值改变
2
3
4
5
6
7
8
9
10
11
12
13
14
15
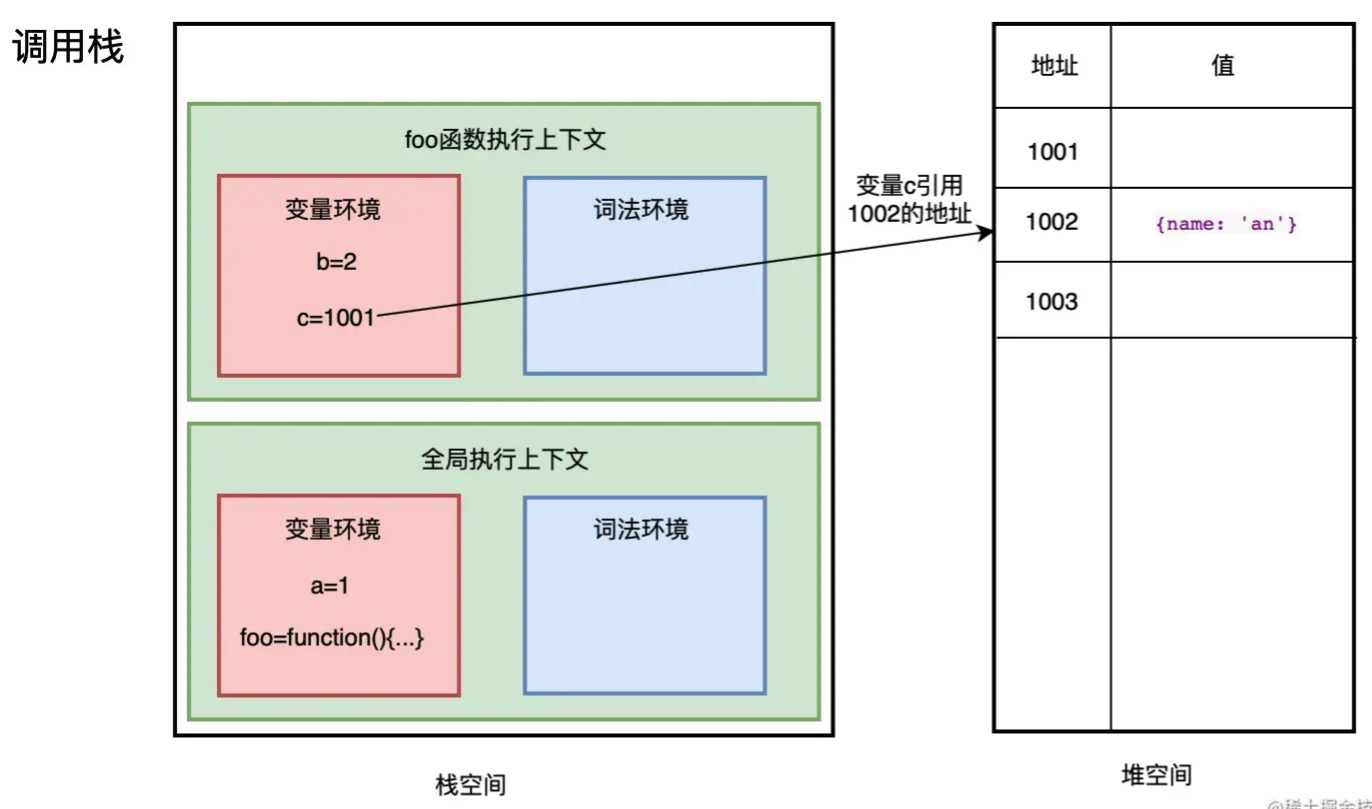
接着垃圾回收案例;
# 回收栈空间
在 JavaScript 执行代码时,主线程上会存在 ESP【扩展栈指针寄存器】指针,用来指向调用栈中当前正在执行的上下文,如下图,当前正在执行 foo 函数:
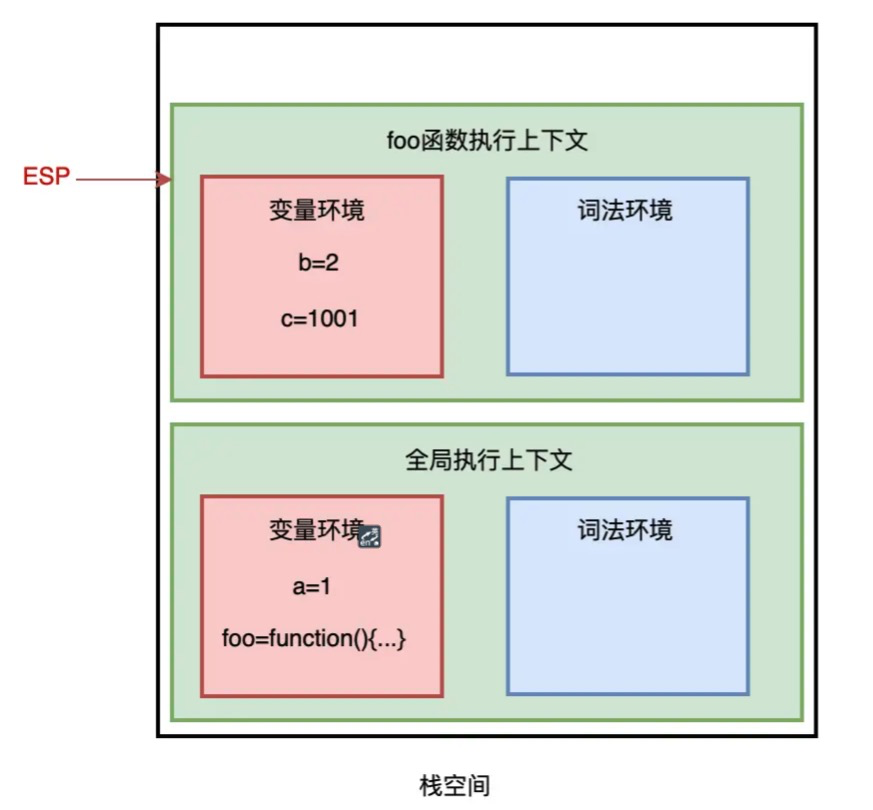
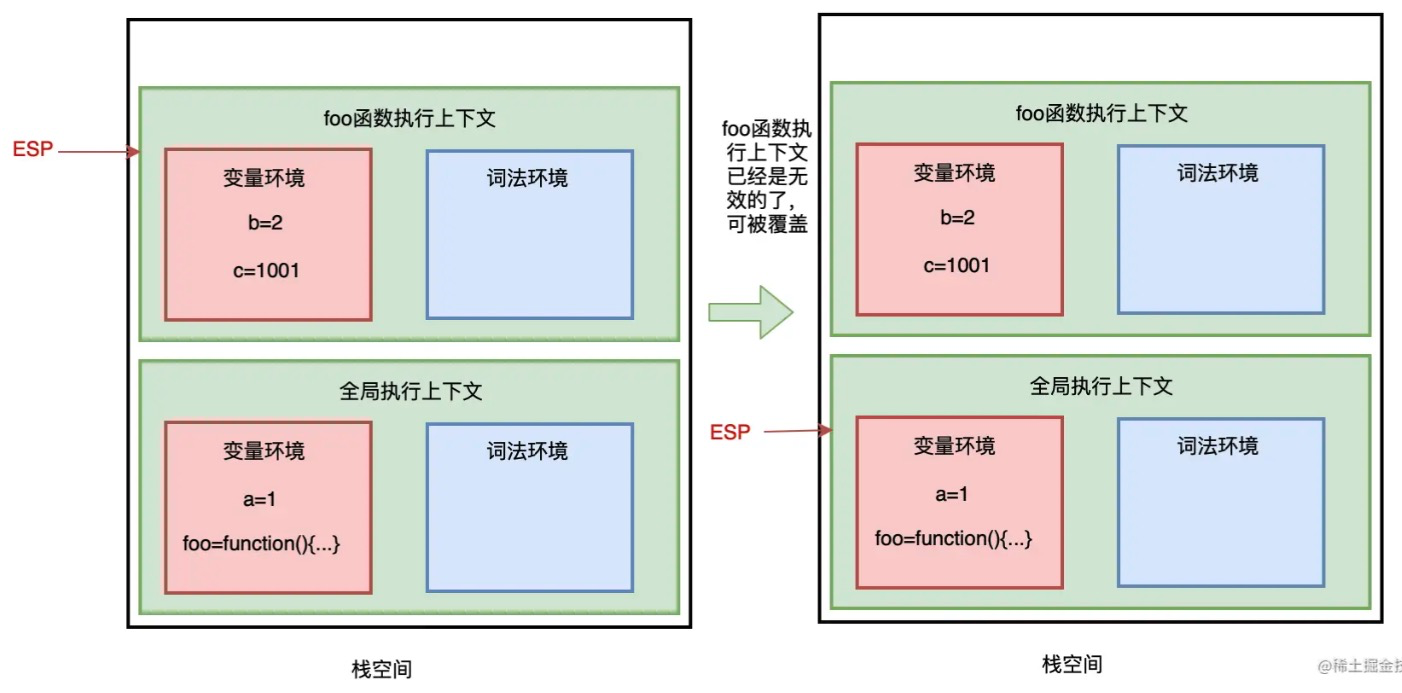
当 foo 函数执行完成后,ESP 向下指向全局执行上下文,此时需要销毁 foo 函数。
怎么销毁?
当 ESP 指针指向全局执行上下文,foo 函数执行上下文已经是无效的了,当有新的执行上下文进来时,可以直接覆盖这块内存空间。即:JavaScript 引擎通过向下移动 ESP 指针来销毁存放在栈空间中的执行上下文。
# 回收堆空间
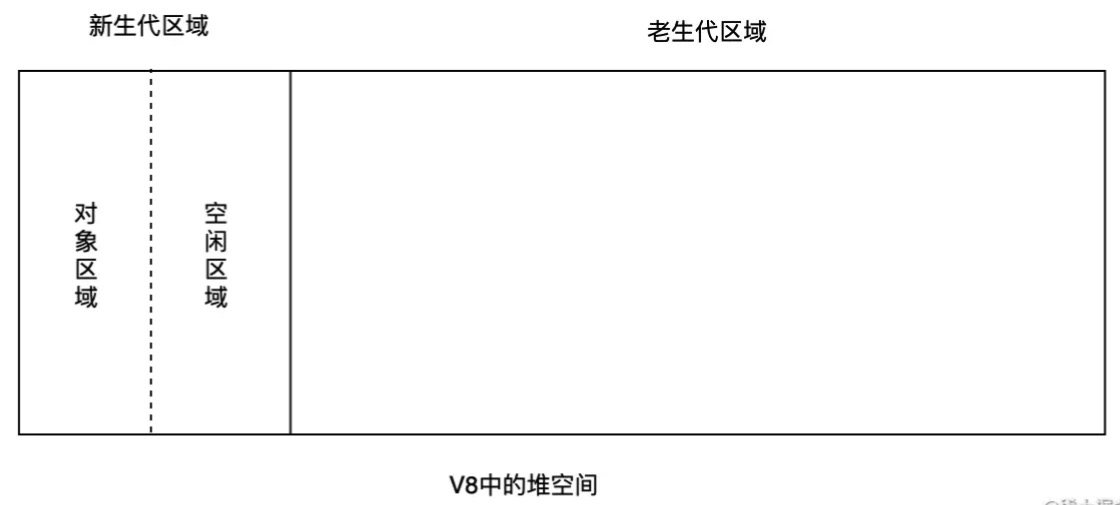
V8 中把堆分成新生代与老生代两个区域:
- 新生代:用来存放生存周期较短的小对象,一般只支持1~8M的容量
- 老生代:用来存放生存周期较长的对象或大对象
V8 对这两块使用了不同的回收器:【新小副/老主大】
- 新生代使用副垃圾回收器
- 老生代使用主垃圾回收器
新生代通常只有1-8M的容量,而老生代的容量就大很多了。对于这两块区域,V8分别使用了不同的垃圾回收器和不同的回收算法,以便更高效地实施垃圾回收
副垃圾回收器 + Scavenge算法:主要负责新生代的垃圾回收主垃圾回收器 + Mark-Sweep && Mark-Compact算法:主要负责老生代的垃圾回收
# 回收执行流程
其实无论哪种垃圾回收器,都采用了同样的流程(三步走):
- 标记: 标记堆空间中的活动对象(正在使用)与非活动对象(可回收)
- 垃圾清理: 回收非活动对象所占用的内存空间
- 内存整理: 当进行频繁的垃圾回收时,内存中可能存在大量不连续的内存碎片,当需要分配一个需要占用较大连续内存空间的对象时,可能存在内存不足的现象,所以,这时就需要整理这些内存碎片。
副垃圾回收器与主垃圾回收器虽然都采用同样的流程,但使用的回收策略与算法是不同的。
2011年,V8应用了增量标记机制。直至2018年,Chrome64和Node.js V10启动并发标记(Concurrent),同时在并发的基础上添加并行(Parallel)技术,使得垃圾回收时间大幅度缩短。
# 副垃圾回收器
它采用 Scavenge 算法及对象晋升策略来进行垃圾回收
所谓 Scavenge 算法,即把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域,如下图所示:
新加入的对象都加入对象区域,当对象区满的时候,就执行一次垃圾回收,执行流程如下:
- 标记:首先要对区域内的对象进行标记(活动对象、非活动对象)
- 垃圾清理:然后进行垃圾清理:将对象区的活动对象复制到空闲区域,并进行有序的排列,当复制完成后,对象区域与空闲区域进行翻转,空闲区域晋升为对象区域,对象区域为空闲区域
翻转后,对象区域是没有碎片的,此时不需要进行第三步(内存整理了)
但,新生代区域很小的,一般1~8M的容量,所以它很容易满,所以,JavaScript 引擎采用对象晋升策略来处理,即只要对象经过两次垃圾回收之后依然继续存活,就会被晋升到老生代区域中。
在JavaScript中,任何对象的声明分配到的内存,将会先被放置在新生代中,而因为大部分对象在内存中存活的周期很短,所以需要一个效率非常高的算法。在新生代中,主要使用Scavenge算法进行垃圾回收,Scavenge算法是一个典型的牺牲空间换取时间的复制算法,在占用空间不大的场景上非常适用。
Scavange算法将新生代堆分为两部分,分别叫from-space和to-space,工作方式也很简单,就是将from-space中存活的活动对象复制到to-space中,并将这些对象的内存有序的排列起来,然后将from-space中的非活动对象的内存进行释放,完成之后,将from space 和to space进行互换,这样可以使得新生代中的这两块区域可以重复利用。
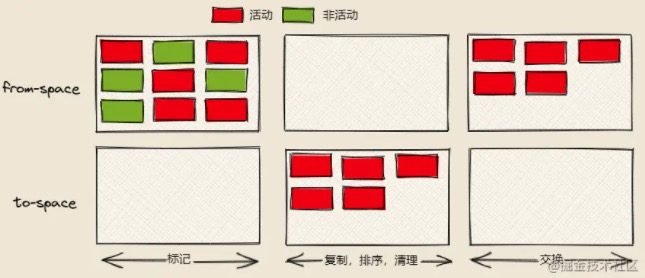
具体步骤为以下4步:
- 1、标记活动对象和非活动对象
- 2、复制
from-space的活动对象到to-space中并进行排序 - 3、清除
from-space中的非活动对象 - 4、将
from-space和to-space进行角色互换,以便下一次的Scavenge算法垃圾回收
那么,垃圾回收器是怎么知道哪些对象是活动对象,哪些是非活动对象呢?
这就要不得不提一个东西了——可达性。什么是可达性呢?就是从初始的根对象(window或者global)的指针开始,向下搜索子节点,子节点被搜索到了,说明该子节点的引用对象可达,并为其进行标记,然后接着递归搜索,直到所有子节点被遍历结束。那么没有被遍历到节点,也就没有被标记,也就会被当成没有被任何地方引用,就可以证明这是一个需要被释放内存的对象,可以被垃圾回收器回收。
新生代中的对象什么时候变成老生代的对象?
在新生代中,还进一步进行了细分。分为nursery子代和intermediate子代两个区域,一个对象第一次分配内存时会被分配到新生代中的nursery子代,如果经过下一次垃圾回收这个对象还存在新生代中,这时候我们将此对象移动到intermediate子代,在经过下一次垃圾回收,如果这个对象还在新生代中,副垃圾回收器会将该对象移动到老生代中,这个移动的过程被称为晋升
# 主垃圾回收器
老生代区域里除了存在从新生代晋升来的存活时间久的对象,当遇到大对象时,大对象也会直接分配到老生代。
所以主垃圾回收器主要保存存活久的或占用空间大的对象,此时采用 Scavenge 算法就不合适了。V8 中主垃圾回收器主要采用标记-清除法进行垃圾回收。
新生代空间的对象,身经百战之后,留下来的老对象,成功晋升到了老生代空间里,由于这些对象都是经过多次回收过程但是没有被回收走的,都是一群生命力顽强,存活率高的对象,所以老生代里,回收算法不宜使用Scavenge算法,为啥呢,有以下原因:
Scavenge算法是复制算法,反复复制这些存活率高的对象,没什么意义,效率极低Scavenge算法是以空间换时间的算法,老生代是内存很大的空间,如果使用Scavenge算法,空间资源非常浪费,得不偿失啊。。
所以老生代里使用了Mark-Sweep算法(标记清理)和Mark-Compact算法(标记整理)
Mark-Sweep(标记清理)
Mark-Sweep分为两个阶段,标记和清理阶段,之前的Scavenge算法也有标记和清理,但是Mark-Sweep算法跟Scavenge算法的区别是,后者需要复制后再清理,前者不需要,Mark-Sweep直接标记活动对象和非活动对象之后,就直接执行清理了。
- 标记阶段:对老生代对象进行第一次扫描,对活动对象进行标记
- 清理阶段:对老生代对象进行第二次扫描,清除未标记的对象,即非活动对象
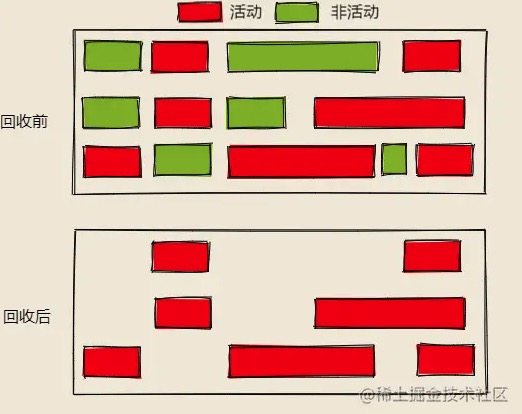
由上图,我想大家也发现了,有一个问题:清除非活动对象之后,留下了很多零零散散的空位。
Mark-Compact(标记整理)
Mark-Sweep算法`执行垃圾回收之后,留下了很多`零零散散的空位`,这有什么坏处呢?如果此时进来了一个大对象,需要对此对象分配一个大内存,先从`零零散散的空位`中找位置,找了一圈,发现没有适合自己大小的空位,只好拼在了最后,这个寻找空位的过程是耗性能的,这也是`Mark-Sweep算法`的一个`缺点
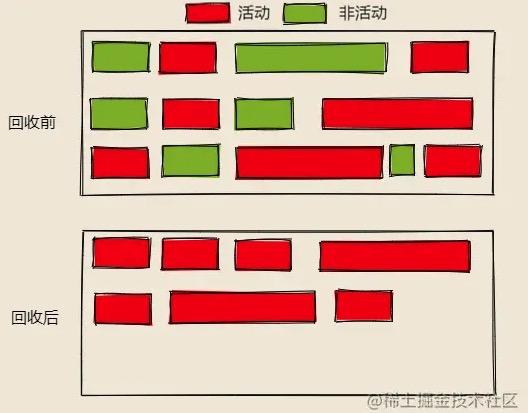
这个时候Mark-Compact算法出现了,他是Mark-Sweep算法的加强版,在Mark-Sweep算法的基础上,加上了整理阶段,每次清理完非活动对象,就会把剩下的活动对象,整理到内存的一侧,整理完成后,直接回收掉边界上的内存
主要流程如下:
- 标记:遍历调用栈,看老生代区域堆中的对象是否被引用,被引用的对象标记为活动对象,没有被引用的对象(待清理)标记为垃圾数据。
- 垃圾清理:将所有垃圾数据清理掉
- 内存整理:标记-整理策略,将活动对象整理到一起
# 增量标记
V8 浏览器会自动执行垃圾回收,但由于 JavaScript 也是运行在主线程上的,一旦执行垃圾回收,就要打断 JavaScript 的运行,可能会或多或少的造成页面的卡顿,影响用户体验,所以 V8 决定采用增量 标记算法回收:
即把垃圾回收拆成一个个小任务,穿插在 JavaScript 中执行。
# 垃圾回收再详解
JavaScript 中的垃圾数据都是由垃圾回收器自动回收的,不需要手动释放;
V8 将内存分为两类:新生代内存空间和老生代内存空间。
- 新生代内存空间:主要用来存放存活时间较短的对象。
- 老生代内存空间:主要用来存放存活时间较长的对象。
这两者通过不同的算法,对内存进行管理操作。
# 什么时候触发垃圾回收
其原理是:垃圾收集器会定期(周期性)找出那些不在继续使用的变量,然后释放其内存。
垃圾回收器周期性运行,如果分配的内存非常多,那么回收工作也会很艰巨,确定垃圾回收时间间隔就变成了一个值得思考的问题。IE6的垃圾回收是根据内存分配量运行的,当环境中存在256个变量、4096个对象、64k的字符串任意一种情况的时候就会触发垃圾回收器工作,看起来很科学,不用按一段时间就调用一次,有时候会没必要,这样按需调用不是很好吗?但是如果环境中就是有这么多变量等一直存在,现在脚本如此复杂,很正常,那么结果就是垃圾回收器一直在工作,这样浏览器就没法儿玩儿了。
微软在IE7中做了调整,触发条件不再是固定的,而是动态修改的,初始值和IE6相同,如果垃圾回收器回收的内存分配量低于程序占用内存的15%,说明大部分内存不可被回收,设的垃圾回收触发条件过于敏感,这时候把临街条件翻倍,如果回收的内存高于85%,说明大部分内存早就该清理了,这时候把触发条件置回。这样就使垃圾回收工作职能了很多
常用的垃圾回收方式
- 标记清除【最常用】;
- 引用计数;
# 合理的GC方案
GC即(Gabarage Collector,垃圾回收器)
1)Javascript引擎基础GC方案是(simple GC):mark and sweep(标记清除),即:
- 遍历所有可访问的对象。
- 回收已不可访问的对象。
2)GC的缺陷
和其他语言一样,javascript的GC策略也无法避免一个问题:GC时,停止响应其他操作,这是为了安全考虑。而Javascript的GC在100ms甚至以上,对一般的应用还好,但对于JS游戏,动画对连贯性要求比较高的应用,就麻烦了。这就是新引擎需要优化的点:避免GC造成的长时间停止响应。
3)GC优化策略
主要介绍了2个优化方案,而这也是最主要的2个优化方案:
# (1)分代回收(Generation GC)
这个和Java回收策略思想是一致的。也是V8所主要采用的。目的是通过区分“临时”与“持久”对象;多回收“临时对象”区(young generation),少回收“持久对象”区(tenured generation),减少每次需遍历的对象,从而减少每次GC的耗时
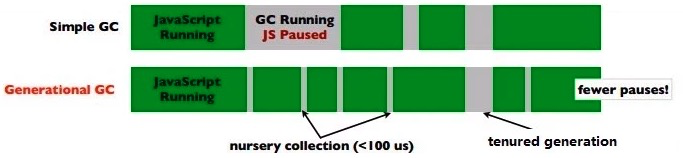
这里需要补充的是:对于tenured generation对象,有额外的开销:把它从young generation迁移到tenured generation,另外,如果被引用了,那引用的指向也需要修改。
# (2)增量GC
这个方案的思想很简单,就是“每次处理一点,下次再处理一点,如此类推”。如图:

这种方案,虽然耗时短,但中断较多,带来了上下文切换频繁的问题。
# 总结:
因为每种方案都其适用场景和缺点,因此在实际应用中,会根据实际情况选择方案。
比如:
- 低 (对象/s) 比率时,中断执行GC的频率,simple GC更低些;
- 如果大量对象都是长期“存活”,则分代处理优势也不大;
# 内存泄漏
内存泄漏指任何对象在不再拥有或需要它之后仍然存在。 垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为 0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收。
- 意外的全局变量:无法被回收。
- 定时器:未被正确关闭,导致所引用的外部变量无法被释放。 setTimeout 的第一个参数使用字符串而非函数的话,会引发内存泄漏。
- 事件监听:没有正确销毁(低版本浏览器可能出现)。
- 闭包:会导致父级中的变量无法被释放。
- DOM 引用:DOM 被删除时,内存中的引用未被正确清空。
- 闭包、控制台日志、循环(在两个对象彼此引用且彼此保留时,就会产生一个循环)
案例:
//减少全局变量
document.getElementById('btn').onclick = function () {
// a 未在外部声明过
a = new Array(1000000).fill('Sunshine_Lin')
}
//上方代码等同于
var a
document.getElementById('btn').onclick = function () {
a = new Array(1000000).fill('Sunshine_Lin')
}
document.getElementById('btn').onclick = function () {
let a = new Array(1000000).fill('Sunshine_Lin')
}
//未清除定时器
function fn() {
let arr = new Array(1000000).fill('Sunshine_Lin')
let i = 0
let timer = setInterval(() => {
if (i > 5) clearInterval(timer)
let a = arr
i++
}, 1000)
}
document.getElementById('btn').onclick = function () {
fn()
}
//合理使用闭包
function fn1() {
let arr = new Array(100000).fill('Sunshine_Lin')
return arr
}
let a = []
document.getElementById('btn').onclick = function () {
a.push(fn1())
}
//分离DOM
//<button id="btn">点击</button>
let btn = document.getElementById('btn')
document.body.removeChild(btn)
btn = null
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
枚举Javascript引擎分配内存的场景:
Object
new Object();
new MyConstructor();
{ a: 4, b: 5 }
Object.create();
2
3
4
数组
new Array();
[ 1, 2, 3, 4 ];
2
字符串
new String(“hello hyddd”);
“<p>” + e.innerHTML + “</p>”
2
随带一说,javascript的字符串和.Net一样,使用资源池和copy on write方式管理字符串。
函数对象
var x = function () { ... }
new Function(code);
2
闭包
function outer(name) {
var x = name;
return function inner() {
return “Hi, “ + name;
}
}
2
3
4
5
6
闭包和prototype不一样,以上函数为例,当调用outer时,会生成并返回一个对象(隐含变量x),每次调用都创建一个,而prototype则是每次都返回同一个而对象(即:无论多少次调用,只创建一个对象)。
# Vue中的内存泄漏问题
JS 程序的内存溢出后,会使某一段函数体永远失效(取决于当时的 JS 代码运行到哪一个函数),通常表现为程序突然卡死或程序出现异常。
这时我们就要对该 JS 程序进行内存泄漏的排查,找出哪些对象所占用的内存没有释放。这些对象通常都是开发者以为释放掉了,但事实上仍被某个闭包引用着,或者放在某个数组里面。
# 泄漏点
- DOM/BOM 对象泄漏;
- script 中存在对 DOM/BOM 对象的引用导致;
- JS 对象泄漏;
- 通常由闭包导致,比如事件处理回调,导致 DOM 对象和脚本中对象双向引用,这个是常见的泄漏原因;
# 代码关注点
主要关注的就是各种事件绑定场景,比如:
- DOM 中的
addEventLisner函数及派生的事件监听,比如 Jquery 中的on函数,Vue 组件实例的$on函数; - 其它 BOM 对象的事件监听, 比如 websocket 实例的 on 函数;
- 避免不必要的函数引用;
- 如果使用
render函数,避免在 HTML 标签中绑定 DOM/BOM 事件;
# 如何处理
- 如果在
mounted/created钩子中使用 JS 绑定了 DOM/BOM 对象中的事件,需要在beforeDestroy中做对应解绑处理; - 如果在
mounted/created钩子中使用了第三方库初始化,需要在beforeDestroy中做对应销毁处理(一般用不到,因为很多时候都是直接全局Vue.use); - 如果组件中使用了
setInterval,需要在beforeDestroy中做对应销毁处理; - 模板中不要使用表达式来绑定到特定的处理函数,这个逻辑应该放在处理函数中;
- 如果在mounted/created 钩子中使用了$on,需要在beforeDestroy 中做对应解绑($off)处理;
- 某些组件在模板中使用 事件绑定可能会出现泄漏,使用$on 替换模板中的绑定;
# vue 组件中处理 addEventListener
调用 addEventListener 添加事件监听后在 beforeDestroy 中调用 removeEventListener 移除对应的事件监听。为了准确移除监听,尽量不要使用匿名函数或者已有的函数的绑定来直接作为事件监听函数。
mounted() {
const box = document.getElementById('time-line')
this.width = box.offsetWidth
this.resizefun = () => {
this.width = box.offsetWidth
}
window.addEventListener('resize', this.resizefun)
},
beforeDestroy() {
window.removeEventListener('resize', this.resizefun)
this.resizefun = null
}
2
3
4
5
6
7
8
9
10
11
12
# 上下文绑定引起的内存泄漏
有时候使用 bind/apply/call 上下文绑定方法的时候,会有内存泄漏的隐患。
var ClassA = function(name) {
this.name = name
this.func = null
}
var a = new ClassA("a")
var b = new ClassA("b")
b.func = bind(function() {
console.log("I am " + this.name)
}, a)
b.func() // 输出: I am a
a = null // 释放a
//b = null; // 释放b
//b.func = null; // 释放b.func
function bind(func, self) { // 模拟上下文绑定
return function() {
return func.apply(self)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
使用 chrome dev tool > memory > profiles 查看内存中 ClassA 的实例数,发现有两个实例,a 和 b。虽然 a 设置成 null 了,但是 b 的方法中 bind 的闭包上下文 self 绑定了 a,因此虽然 a 释放,但是 b/b.func 没有释放,闭包的 self 一直存在并保持对 a 的引用。
# 观察者模式引起的内存泄漏
在 spa 应用中使用观察者模式的时候如果给观察者注册了被观察的方法,而没有在离开组件的时候及时移除,可能造成重复注册而内存泄漏;
举个栗子:
进入组件的时候 ob.addListener("enter", _func),如果离开组件 beforeDestroy 的时候没有 ob.removeListener("enter", _func),就会导致内存泄漏。更详细的栗子参考 (opens new window)
# 监听查看内存情况
使用 Chrome 的 Timeline(新版本 Performance)进行内存标记,可视化查看内存的变化情况,找出异常点。
# 相关链接
http://www.ruanyifeng.com/blog/2014/10/event-loop.html
https://juejin.cn/post/6996828267068014600
https://juejin.cn/post/6995706341041897486
https://juejin.cn/post/6844904134341033998