 redis事务、锁及分布式
redis事务、锁及分布式
# Redis事务
# Redis事务及原理
- Redis 中的事务是一组命令的集合,是 Redis 的最小执行单位,一个事务要么都执行,要么都不执行。
- Reids 事务保证一个事务内的命令依次执行,而不会被其他命令插入。
Redis事务的原理是先将属于一个事务的命令发送给 Redis,然后依次执行这些命令。
Redis事务的实现需要用到 MULTI 和 EXEC 两个命令,事务开始的时候先向Redis服务器发送 MULTI 命令,然后依次发送需要在本次事务中处理的命令,最后再发送 EXEC 命令表示事务命令结束。
# Redis事务相关命令
- multi 命令:标记一个事务开始。 开启Redis的事务,置客户端为事务态。
- exec 命令:执行所有事务内的命令。提交事务,执行从multi到此命令前的命令队列,置客户端为非事务态。
- discard 命令:取消事务,丢弃事务中所有命令。取消事务,置客户端为非事务态。
- watch 命令:监视一个(或多个)key,如果在执行事务之前这个(这些)key 被其他命令所改动,事务将被打断。监视键值对,作用时如果事务提交exec时发现监视的监视对发生变化,事务将被取消。
- unwatch 命令:取消 watch 命令对所有 key 的监视。
# 事务的注意点
- 不支持回滚,如果事务中有错误的操作,无法回滚到处理前的状态,需要开发者处理。
- 在执行完当前事务内所有指令前,不会同时执行其他客户端的请求。
# 为什么不支持回滚?
Redis 事务不支持回滚,如果遇到问题,会继续执行余下的命令。 这一点和关系型数据库不太一致。 这样处理的原因有:
只有语法错误,Redis才会执行失败,例如错误类型的赋值, 这就是说从程序层面完全可以捕获以及解决这些问题 支持回滚需要增加很多工作,不支持的情况下,Redis可以保持简单、速度快的特性
# Redis如何实现乐观锁
大多数是基于数据版本(version)的记录机制实现的。即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个”version”字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本号加1。此时,将提交数据的版本号与数据库表对应记录的当前版本号进行比对,如果提交的数据版本号大于数据库当前版本号,则予以更新,否则认为是过期数据。
Redis中可以使用watch命令会监视给定的key,当exec时候如果监视的key从调用watch后发生过变化,则整个事务会失败。
也可以调用watch多次监视多个key。这样就可以对指定的key加乐观锁了。注意watch的key是对整个连接有效的,事务也一样。如果连接断开,监视和事务都会被自动清除。当然了exec,discard,unwatch命令都会清除连接中的所有监视。
# Redis Pipeline(管道)
# 介绍 Redis 的 Pipeline(管道),以及使用场景
- Redis客户端与服务端通信模型使用的 TCP 协议进行连接, 那么在单个指令的执行过程中,都会存在“交互往返”的时间。
- Redis提供了
批量操作命令,例如 mget、mset 等,能够一定程度上节省这类时间,但大部分命令还是不支持批量操作。 - 因此 Pipeline功能,能够改善这一类问题。 Pipeline将一组Redis命令进行组装,一次性传输给 Redis,再将这些命令执行结果,按照顺序返回给客户端。
适用场景:有批量的数据写入 Redis,并且这些数据允许一定比例的写入失败,那么这种场景就可以适用 Pipeline。失败的数据后期进行补偿即可。
# Redis的批量命令与Pipeline区别
- 批量命令保证原子性的,Pipeline 非原子性
- 批量命令是一个命令对应多个 key,Pipeline 支持多个命令
- 批量命令是 Redis 服务端实现,而 Pipeline 是需要服务端和客户端共同实现
# Redis锁机制的几种实现方式
- redis能用的的加锁命令分表是
INCR、SETNX、SET
# 第一种锁命令INCR
这种加锁的思路是, key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作进行加一。 然后其它用户在执行 INCR 操作进行加一时,如果返回的数大于 1 ,说明这个锁正在被使用当中。
# 第二种锁SETNX
这种加锁的思路是,如果 key 不存在,将 key 设置为 value
如果 key 已存在,则 SETNX 不做任何动作
# 第三种锁SET
上面两种方法都有一个问题,会发现,都需要设置 key 过期。
那么为什么要设置key过期呢?如果请求执行因为某些原因意外退出了,导致创建了锁但是没有删除锁,那么这个锁将一直存在,以至于以后缓存再也得不到更新。于是乎我们需要给锁加一个过期时间以防不测。
但是借助 Expire 来设置就不是原子性操作了。所以还可以通过事务来确保原子性,但是还是有些问题,所以官方就引用了另外一个,使用 SET 命令本身已经从版本 2.6.12 开始包含了设置过期时间的功能。
# 锁的相关
# 其它问题
虽然上面一步已经满足了我们的需求,但是还是要考虑其它问题? 1、 redis发现锁失败了要怎么办?中断请求还是循环请求? 2、 循环请求的话,如果有一个获取了锁,其它的在去获取锁的时候,是不是容易发生抢锁的可能? 3、 锁提前过期后,客户端A还没执行完,然后客户端B获取到了锁,这时候客户端A执行完了,会不会在删锁的时候把B的锁给删掉?
# 解决办法
针对问题1:使用循环请求,循环请求去获取锁 针对问题2:针对第二个问题,在循环请求获取锁的时候,加入睡眠功能,等待几毫秒在执行循环 针对问题3:在加锁的时候存入的key是随机的。这样的话,每次在删除key的时候判断下存入的key里的value和自己存的是否一样
自己实现:
上锁
通过 set 命令传入 setnx、expire 扩展参数开始上锁占坑,上锁成功返回,上锁失败进行重试,在 lockTimeout 指定时间内仍未获取到锁,则获取锁失败。
释放锁
释放锁通过 redis.eval(script) 执行我们定义的 redis lua 脚本。
const Redis = require("ioredis");
const redis = new Redis(6379, "127.0.0.1");
const uuidv1 = require('uuid/v1');
const redisLock = new RedisLock(redis);
function sleep(time) {
return new Promise((resolve) => {
setTimeout(function() {
resolve();
}, time || 1000);
});
}
async function test(key) {
try {
const id = uuidv1();
await redisLock.lock(key, id, 20);
await sleep(3000);
const unLock = await redisLock.unLock(key, id);
console.log('unLock: ', key, id, unLock);
} catch (err) {
console.log('上锁失败', err);
}
}
test('name1');
test('name1');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
官方推荐redlock :
Redis 官网 redis.io/topics/distlock 提供了一个使用 Redis 实现分布式锁的规范算法 Redlock,中文翻译版参考 http://redis.cn/topics/distlock.html
const Redis = require("ioredis");
const client1 = new Redis(6379, "127.0.0.1");
const Redlock = require('redlock');
const redlock = new Redlock([client1], {
retryDelay: 200, // time in ms
retryCount: 5,
});
// 多个 Redis 实例
// const redlock = new Redlock(
// [new Redis(6379, "127.0.0.1"), new Redis(6379, "127.0.0.2"), new Redis(6379, "127.0.0.3")],
// )
async function test(key, ttl, client) {
try {
const lock = await redlock.lock(key, ttl);
console.log(client, lock.value);
// do something ...
// return lock.unlock();
} catch(err) {
console.error(client, err);
}
}
test('name1', 10000, 'client1');
test('name1', 10000, 'client2');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
测试
对同一个 key name1 两次上锁,由于 client1 先取到了锁,client2 无法获取锁,重试 5 次之后报错 LockError: Exceeded 5 attempts to lock the resource "name1".
# 分布式锁简介及作用
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。 在单机或者单进程环境下,多线程并发的情况下,使用锁来保证一个代码块在同一时间内只能由一个线程执行。比如 Java 的 Synchronized 关键字和 Reentrantlock 类。
多进程或者分布式集群环境下,如何保证不同节点的线程同步执行呢? 这就是分布式锁。
# 分布式锁实现方式
分布式实现方式有很多种:
- 数据库乐观锁方式
- 基于 Redis 的分布式锁
- 基于 ZK 的分布式锁
1. Memcached 分布式锁: Memcached 提供了原子性操作命令 add,才能 add 成功,线程获取到锁。key 已存在的情况下,则 add 失败,获取锁也失败。
2. Redis 分布式锁: Redis 的 setnx 命令为原子性操作命令。只有在 key 不存在的情况下,才能 set 成功。和 Memcached 的 add 方法比较类似。
3. ZooKeeper 分布式锁: 利用 ZooKeeper 的顺序临时节点,来实现分布式锁和等待队列。
4. Chubby 实现分布式锁: Chubby 底层利用了 Paxos 一致性算法,实现粗粒度分布式锁服务。
# 分布式锁实现时注意的事项
分布式锁实现要保证几个基本点。
- 互斥性:任意时刻,只有一个资源能够获取到锁。
- 容灾性:在未成功释放锁的的情况下,一定时限内能够恢复锁的正常功能。
- 统一性:加锁和解锁保证同一资源来进行操作。
# Redis 怎么实现分布式锁
简单方案: 最简单的方法是使用 setnx 命令。释放锁的最简单方式是执行 del 指令。
**问题:**锁超时:如果一个得到锁的线程在执行任务的过程中挂掉,来不及显式地释放锁,这块资源将会永远被锁住(死锁),别的线程再也别想进来。
优化方案:
setnx 没办法设置超时时间,如果利用 expire 来设置超时时间,那么这两步操作不是原子性操作。
利用 set 指令增加了可选参数方式来替代 setnx。set 指令可以设置超时时间。
# 常见的应用场景
# 分布式锁
当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的操作或者访问。 与之对应有线程锁,进程锁。分布式锁可以避免不同进程重复相同的工作,减少资源浪费。 同时分布式锁可以避免破坏数据正确性的发生, 例如多个进程对同一个订单操作,可能导致订单状态错误覆盖。应用场景如下。
# 定时任务重复执行
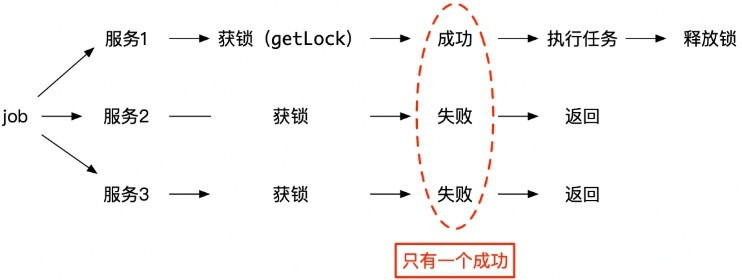
随着业务的发展,业务系统势必发展为集群分布式模式。如果我们需要一个定时任务来进行订单状态的统计。比如每 15 分钟统计一下所有未支付的订单数量。那么我们启动定时任务的时候,肯定不能同一时刻多个业务后台服务都去执行定时任务, 这样就会带来重复计算以及业务逻辑混乱的问题。
这时候,就需要使用分布式锁,进行资源的锁定。那么在执行定时任务的函数中, 首先进行分布式锁的获取,如果可以获取的到,那么这台机器就执行正常的业务数据统计逻辑计算。 如果获取不到则证明目前已有其他的服务进程执行这个定时任务,就不用自己操作执行了,只需要返回就行了。 如下图所示:
# 避免用户重复下单
Java语言加解锁方式示例:
加锁代码演示:
 解锁代码演示:
解锁代码演示:

# 分布式自增 ID
应用场景
随着用户以及交易量的增加, 我们可能会针对用户数据,商品数据,以及订单数据进行分库分表的操作。这时候由于进行了分库分表的行为,所以 MySQL 自增 ID 的形式来唯一表示一行数据的方案不可行了。 因此需要一个分布式 ID 生成器,来提供唯一 ID 的信息。
实现方式 通常对于分布式自增 ID 的实现方式有下面几种:
- 通过 UUID 来实现唯一 ID 生成
- Twitter 的 SnowFlake雪花 算法
- 数据库特性;利用数据库自增 ID 的属性
- MongoDB的ObjectId
- 利用 Redis 生成唯一 ID
在这里说 Redis 来实现唯一 ID 的形式了。使用 Redis 的 INCR 命令来实现唯一 ID。
Redis 是单进程单线程架构,不会因为多个取号方的 INCR 命令导致取号重复。因此,基于 Redis 的 INCR 命令实现序列号的生成基本能满足全局唯一与单调递增的特性。
- 当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
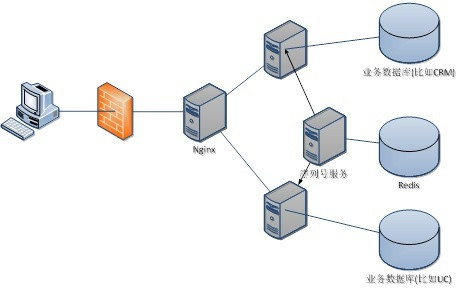
- 可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。
# 优化方案
- 一次批量获取多个,优点减少网络开销。缺点
# 综合比对
- UUID 场景token 图片ID
- snowflake ElK MQ 业务系统
- 数据库 非大型系统
- redis 大型系统