 redis简介、安装及配置
redis简介、安装及配置
# Redis简介
Redis 全称为:Remote Dictionary Server(远程数据服务),是一个基于内存且支持持久化的高性能 key-value 数据库。整个数据库加载在内存当中进行操作, 定期通过异步操作把数据库数据 flush 到硬盘上进行保存。
具备一下几个基本特征:
- 多数据类型
- 持久化机制
- 主从同步
# Redis 的特点
- Redis 本质上是一个 key-value 类型的数据库
- 整个数据库都是
在内存中进行操作,可定期刷新到磁盘进行持久化存储 - 由于是在内存操作,读写能力非常好,
每秒可以处理 10 万次读写操作 - Redis 支持多种数据结构,提供了丰富的数据类型选择
- Redis 同时
支持数据备份,主从配置 - Redis 的所有操作都是
原子性的 - Redis 支持数据持久化存储,可以将数据存储在磁盘中,机器重启数据将从磁盘重新加载数据;
- Redis 支持数据的备份,即
Master-Slave 模式的数据备份。
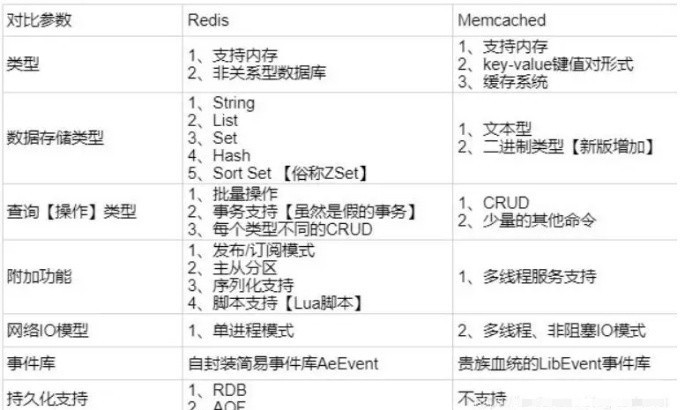
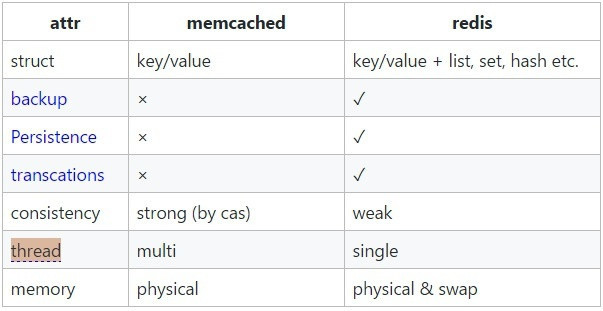
# Redis与Memcache的区别
- 存储方式不同:Memcache 把数据全部存在内存之中,断电后会丢失。Redis 所有数据加载在内存,但也会持久化到磁盘,保证数据的持久性。
- 支持数据类型不同:Memcache 对数据类型支持相对简单,只支持 key-value 结构。Redis 有复杂的数据类型。Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- 底层模型不同:底层实现方式以及客户端通信应用协议不一样。 Redis 直接自己构建了 VM 机制。
- 运行环境不同:Redis 目前官方只支持 Linux 上运行。
- Memcached是多线程,非阻塞IO复用的网络模型;Redis使用
单线程的多路 IO 复用模型。 - 集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是
原生支持 cluster 模式的. - Redis 的出色之处不仅仅是性能, Redis 最大的魅力是支持保存多种数据结构, 此外单个value 的最大限制是 1GB, 不像 memcached 只能保存 1MB 的数据;
图示区别:
# Redis相比 Memcached 优势
- Memcached 所有的值均是简单的字符串,Redis 作为其替代者,支持更为丰富的数据类型
- Redis 的速度比 Memcached 快很多
- Redis 可以持久化其数据
- Redis 的主要缺点是数据库容量受到物理内存的限制, 不能用作海量数据的高性能读写, 因此 Redis 适合的场景主要局限在较小数据量的高性能操作和运算上
# Redis作为缓存数据库和MySQL结构化数据库进行对比
- 从数据库类型上,Redis是NoSQL半结构化缓存数据库,MySQL是结构化关系型数据库;
- 从读写性能上,MySQL是持久化硬盘存储,读写速度较慢, Redis数据存储读取都在内存,同时也可以持久化到磁盘,读写速度较快;
- 从使用场景上,Redis一般作为 MySQL数据读取性能优化的技术选型,彼此配合使用。
# Redis通讯协议及特点
- Redis的通信协议是 Redis Serialization Protocol,简称 RESP。有如下特性:
- 是二进制安全的
- 在TCP层
- 基于请求—响应的模式
# 通信协议
首先是以行来划分,每行以\r\n行结束。每一行都有一个消息头,消息头共分为5种分别如下:
- (+) 表示一个正确的状态信息,具体信息是当前行+后面的字符。
- (-) 表示一个错误信息,具体信息是当前行-后面的字符。
- (*) 表示消息体总共有多少行,不包括当前行,*后面是具体的行数。
- ()表示下一行数据长度,不包括换行符长度\r\n,后面则是对应的长度的数据。
- (😃 表示返回一个数值,:后面是相应的数字节符。
举个例子:【使用Wireshark 追踪Redis通信】
```
*3\r\n #消息一共有三行
$3\r\n #第一行有长度为3
set\r\n #第一行的消息
$4\r\n #第二行长度为4
demo\r\n #第二行的消息
$6\r\n #第三行长度为6
123456\r\n #第三行的消息
+OK\r\n #操作成功
```
ps:
无论是java的客户端Jredis 还是说 针对php的redis客户端扩展,原理其实是一样的。这些客户端只是把我们的
命令翻译成为了redis请求报文格式,发送给server端的6379端口,server端响应请求之后, 客户端拿到信息,解析成为java变量或者php变量等等而已, 这些工具包所提供的功能经此而已。
我们自己完全
可以使用socket进行编程, 按照redis客户端请求报文规范,一样能访问和操作redis。只不过,我们的主要精力在工作的业务代码逻辑上,而非是在处理redis的操作上,所以没必要自己去搞一个工具库。不过,这样能够让你对于理解redis客户端和服务端通信过程更加深刻和理解。 每当操作redis的时候,我们的脑海中自然出现了底层实际发送数据流向的画面, 自然以后排查错误就知根知底了
# 应用场景设计
# Redis 适用场景有哪些
适用场景:
数据(热点)高并发的读写海量数据的读写对扩展性要求高的数据
不适场景:
- 需要
事务支持(非关系型数据库) - 基于 SQL 结构化查询储存,
关系复杂
# Redis 常用的业务场景
- **热点数据缓存:**由于 Redis 访问速度块、支持的数据类型比较丰富,所以 Redis 很适合用来存储热点数据
- **限时业务实现:**expire 命令设置 key 的生存时间,到时间后自动删除 key。收集验证码、优惠活动等业务场景。
- 计数器实现:
incrby 命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成。比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。 - **排行榜实现:**借助
SortedSet 进行热点数据的排序。例如:下单量最多的用户排行榜,最热门的帖子(回复最多)等。Redis在内存中对数字进行递增或递减的操作实现的非常好。 - **布式锁实现:**利用 Redis 的 setnx 命令进行。后面会有详细的实现介绍。
- **队列机制实现:**Redis 有 list push 和 list pop 这样的命令,所以能够很方便的执行队列操作。Reids 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用
- **会话缓存(Session Cache):**最常用的一种使用 Redis 的情景是会话缓存(session cache)。用 Redis 缓存会话比其他存储(如 Memcached) 的优势在于:Redis 提供持久化。
- **发布/订阅:**发布/订阅的使用场景确实非常多。已看见人们在社交网络连接中使用, 还可作为基于发布/订阅的脚本触发器, 甚至用 Redis 的发布/订阅功能来建立聊天系统。
# 其他相关
# 设置 Redis 的最大连接数, 查看 Redis 的最大连接数, 查看 Redis 的当前连接数
- 设置 Redis 的最大连接数使用命令:
redis-server -maxclients 50000 - 查看 Redis 最大连接数使用命令:
config get maxclients] - **查看 Redis 连接数:**使用 info 命令;在 redis-cli 端输入 info 命令即可查看
# 介绍一些 Redis 常用的安全设置
1. 网络安全
除了信任的客户端发出的请求以外,其他所有请求都拒绝。对于暴露到外网的服务,使用防火墙阻止外部访问 Redis 端口。
2. 身份验证
Redis 提供了简单的身份验证功能,在 redis.conf 文件中进行配置生效。客户端可以通过发送(AUTH 密码)命令进行身份认证。
3. 禁用特定的命令集
Redis 可以选择禁止使用某些命令,这样即使是正常的客户端也无法使用这些命令集合。
# 安装配置
# 安装
Docker方式启动:
docker create volum db_redis
docker volum inspect db_redis
docker run -p 6379:6379 -v $PWD/data:/data -d redis:3.2 redis-server --appendonly yes
mkdir -p ~/redis ~/redis/data //端口映射,data目录映射,配置文件映射(在当前目录下进行启动)。
docker run -p 6379:6379 --name myredis \n
-v $PWD/conf/redis.conf:/etc/redis/redis.conf -v $PWD/data:/data -d redis:3.2 redis-server \n
/etc/redis/redis.conf --appendonly yes
2
3
4
5
6
7
docker-compose方式启动安装:【推荐】-用alpine方式;
docker-compose -f docker-compose.dev.yml up -d
docker-compose -f docker-compose.dev.yml down
2
version: '3'
services:
redis:
image: redis:3.2-alpine
command: redis-server --appendonly yes # --requirepass password
# volumes:
# - ./data:/data
ports:
- 6379:6379
2
3
4
5
6
7
8
9
# 配置
配置可以外部访问,和Docker bull-ui版本配合使用**:daemonize yes **
- 方式一:[推荐],安全起见,建议修改redis的端口;或者做密码验证; bind 127.0.0.1 服务器的内网IP 服务器的IP #注意空格
- 方式二: bind 0.0.0.0 protected-mode no
ps aux | grep redis//查看redis的端口号service redis-server restart//重启redis-cli -h 192.168.11.17 (-p 6379) (-a 123456)//外部客户端测试外部连接
# 启动设置常用命令:
service redis-server restart (ubuntu)
redis-server /etc/redis/6379.conf
redis-cli shutdown
redis-cli -h 192.168.1.22 -p 6379 -a 123456
//远程访问方式:
redis-cli -h 129.204.51.145 -p 6379 -a 123456
ps axu|grep redis
redis-cli shutdown
redis-server& //启动不阻塞;
2
3
4
5
6
7
8
9
# 修改配置不重启 Redis 会实时生效?
针对运行实例, 有许多配置选项可以通过 CONFIG SET 命令进行修改, 而无需执行任何形式的重启。从 Redis 2.2 开始, 可以从 AOF 切换到 RDB 的快照持久性或其他方式而不需要重启 Redis。 *检索 ‘CONFIG GET ’ 命令获取更多信息。 但偶尔重新启动是必须的, 如为升级 Redis 程序到新的版本, 或者当你需要修改某些目前CONFIG 命令还不支持的配置参数的时候
# 问题
Redis是单线程的吗?
Redis是单线程处理网络指令请求,所以不需要考虑并发安全问题。所有的网络请求都是一个线程处理。但不代表所有模块都是单线程。
Redis是单线程的, 如何提高多核 CPU 的利用率?
可以在同一个服务器部署多个 Redis 的实例, 并把他们当作不同的服务器来使用, 在某些时候, 无论如何一个服务器是不够的,所以, 如果你想使用多个 CPU, 你可以考虑一下分片(shard)。
单线程的redis为什么这么快?(其实就是历史遗留问题,非要吹的这么好)
(一)纯内存操作 (二)单线程操作,避免了频繁的上下文切换 (三)采用了非阻塞I/O多路复用机制
为什么 Redis 需要把所有数据放到内存中?
追求最快的数据读取速度,如果直接磁盘读取会非常慢;
为了保证数据安全,也会异步方式将数据写入磁盘;
可以设置 Redis 最大使用的内存,若达到内存限值后将不能继续存入数据。
Redis 为了达到
最快的读写速度将数据都读到内存中, 并通过异步的方式将数据写入磁盘。所以 Redis 具有快速和数据持久化的特征。如果不将数据放在内存中, 磁盘 I/O 速度为严重影响 Redis 的性能。在内存越来越便宜的今天, Redis 将会越来越受欢迎。
为什么Redis的操作是原子性的,怎么保证原子性的?
对于Redis而言,命令的原子性指的是:一个操作的不可以再分,操作要么执行,要么不执行。 Redis的操作之所以是原子性的,是因为Redis是单线程的。 Redis本身提供的所有API都是原子操作,Redis中的事务其实是要保证批量操作的原子性。 多个命令在并发中也是原子性的吗?不一定, 将get和set改成单命令操作,incr 。使用Redis的事务,或者使用Redis+Lua等等的方式实现.
如何实现本地缓存?请描述一下你知道的方式?
程序中定义内存数据结构来实现, 比如说:
- 定义一个成员变量Map 或者 List 均可以实现
- 使用开源的缓存框架 Ehcache,Ehcache 封装了对于内存操作的功能
- Guava Cache 是 Google 开源的工具集, 提供了缓存的边界操作工具
介绍一下HyperLogLog?
HyperLogLog 是一种概率数据结构,用来估算数据的基数。数据集可以是网站访客的 IP 地址,E-mail 邮箱或者用户 ID。
基数就是指一个集合中不同值的数目,比如 a, b, c, d 的基数就是 4,a, b, c, d, a 的基数还是 4。虽然 a 出现两次,只会被计算一次。
使用 Redis 统计集合的基数一般有三种方法,分别是使用 Redis 的 HashMap,BitMap 和 HyperLogLog。前两个数据结构在集合的数量级增长时,所消耗的内存会大大增加,但是 HyperLogLog 则不会。
Redis 的 HyperLogLog 通过牺牲准确率来减少内存空间的消耗,只需要12K内存,在标准误差0.81%的前提下,能够统计2^64个数据。所以 HyperLogLog 是否适合在比如统计日活月活此类的对精度要不不高的场景。
这是一个很惊人的结果,以如此小的内存来记录如此大数量级的数据基数。