 wdp功能介绍
wdp功能介绍
# 基本介绍
# 产品背景
随着移动互联网技术的高速发展,运营商的数据量呈指数级增长。如何利用海量数据资源进行价值和商业变现,成为运营商提高核心竞争力、抢占市场先机的关键。目前市场上的主流版本CDH/HDP 都面临停止更新,原厂技术支持成本较高,组件不齐备和较为老旧的问题。 WDP(大数据平台) 是企业级的大数据处理环境,是一个分布式数据处理系统,对外提供大容量的数据存储、分析查询和实时流式数据处理分析能力,HJ在大数据产品技术方面沉淀多年的技术体现和产品实现,能够为企业提供稳定,功能齐备的大数据平台。
# 产品定位
结合多年的大数据技术研发和运营服务支撑经验,提供了自主可控的大数据发行版本,具备商用能力的企业级大数据平台产品。产品覆盖HJ在大数据实施方面所使用的技术栈和相关组件,并且提供一体化的部署运维能力,解决在过往CDH大数据平台实施过程中,由于组件的缺少需要手工部署某些组件,比如KAFKA,FLINK,SPARK等运维成本过高,兼容适配问题多等痛点。
通过WDP的监控和运维管理端,实现大数据组件的可视化,快速部署和实施,并且最大程度的避免兼容性问题,为上层应用提供统一稳定可靠的自主大数据底座。
# 产品价值
通过统一的运维监控平台集成开源的HADOOP组件,并且进行定制化开发和兼容性适配,实现大数据组件的一体化部署和运维平台。平台是自主可控的,涉及的HADOOP开源组件,依赖于多年的研发经验,具备技术兜底能力,提供给客户和应用可靠稳定的自主大数据平台底座。
WDP具备高度的可扩展和定制化产品能力,于HJ的相关产品能够高度集成,例如通过HJ的SIMS平台,能够实现一键轻松部署,HJ数据工厂完全对接WDP组件,兼容性能够得到最大限度的保证。
作为HJ的自主大数据平台,具备大数据组件的高度可扩展能力,能够引入新的技术组件或者进行版本迭代升级,满足不同的应用对底座的功能或者性能的需求,无需应用因为其他大数据平台由于缺乏某些组件或者版本无法升级,带来很多兼容和运维的难题。
WDP是HJ企业数据中台的可靠底座,具备管理大规模HADOOP大数据集群的能力,对开源组件进行封装和增强,对外提供稳定的大容量的数据存储、查询和分析能力。
# 产品特点
# 集群统一管控
通过对集群的统一管控,WDP的能够对接集群的物理主机,对所有主机进行组件角色的分配和相关软件的安装。支持通过界面和向导交互式页面,对主机进行维护管理,解决开源版本的HADOOP组件部署麻烦的痛点,运维人员只需要关注WDP的管理端,即可对集群的主机进行组件的定制与分配,也能对某台特定的主机进行单独维护,比如下线,重新部署HADOOP组件等需求。也支持对集群进行扩展,在线添加主机纳入统一管控。
# 组件向导式安装
所有的HADOOP组件,包括HDFS,HBASE,HIVE,SPARK等,都可以通过向导方式进行定制化安装,无需通过手工或者脚本的方式在主机上进行安装。安装过程清晰简明,并且默认给出合理的配置项,如果需要进行定制化的参数配置,也可以在安装过程中进行调整。
进度可视化:每个组件安装过程中,根据主机的维度,组件详细项的列表,进行进度的详细展现,包括安装的成功,安装失败,安装中止等状态。
安装信息反馈:安装过程中,出现异常的状态,能够返回对应的错误信息,方便运维人员进行问题定位。
# 组件运维管理能力
支持对集成的HADOOP组件进行界面可视化运维:支持对HDFS,HIVE,SPARK等组件通过界面的按钮进行服务启停,进入维护模式,组件下线,下载客户端配置等操作;对集成的组件进行统一的配置管理,在组件集中配置界面中,能够完成组件的常用配置和高级配置的设置。
# 运行指标采集与告警
1.主机基本指标采集与展现
WDP系统能够对接入管控的主机指标进行基本的采集与展现。包括基本的主机信息:CPU,内存,磁盘,网络等信息。并且可以通过图表方式进行可视化展现,直观的了解系统当前的负载情况,并且对于系统的异常情况,能够自动给出告警信息,提醒运维人员关注。
2. 组件指标采集与告警
支持对HADOOP组件的运行指标进行采集和告警监控。比如集群负载较高的情况下,能够通过图表方式实现当前系统的HDFS网络负载,组件占用内存,HBASE的GC情况等常用指标,并且系统能够通过端口测试等方式,监听组件是否运行正常,组件出现异常,连接不上等情况,能够主动给出告警信息。
告警信息可以进行定制化开发,根据需要可以接入更多的监控指标和配置告警数据的阈值等客制化需求。
# 支持插拔式组件扩展
WDP管理的HADOOP组件是高度可定制化的,支持嵌入不同版本的hadoop组件和引入新的组件。引入新的组件只需要配置符合WDP规范的安装包和配置文件路径,WDP管理平台即可接管引入的组件,并且在集群管控的主机进行统一安装和配置。整体保持高度的灵活性,不会固定或者在WDP管理节点固定特定组件的特定版本,上层封装了统一规划的接口,需要在引入组件的中,配置好相关的配置文件和控制脚本即可。 WDP管理平台基本上和HADOOP组件是分离的,管理平台可以支持不同版本的HADOOP组件或者引入更多的大数据组件,并且和已有的组件进行联动。比如引入的FLINK组件,可以自动配置到YARN组件中,使用ON YARN模式一件启动FLINK,并且可以在YARN队列中进行配置。
# 提供API接口
WDP提供了API接口用于应用集成和二次开发,包括指标监控接口,单点登录接口,租户授权接口。利用API接口,应用端可以进行系统的深度集成,比如HJ的数据工厂利用API接口,实现对接WDP的库表管理和权限管理的集成。
# 多租户安全性增强
WDP支持KERBEROS进行多租户方式的鉴权方式,通过一键方式启动kerberos的组件集成,通过集成ranger,实现多租户的权限分配。HDFS,HIVE,HBASE等组件统一通过ranger组件进行权限控制。并且也支持KAFKA,presto等组件的权限分配。
# 系统架构
# 系统架构
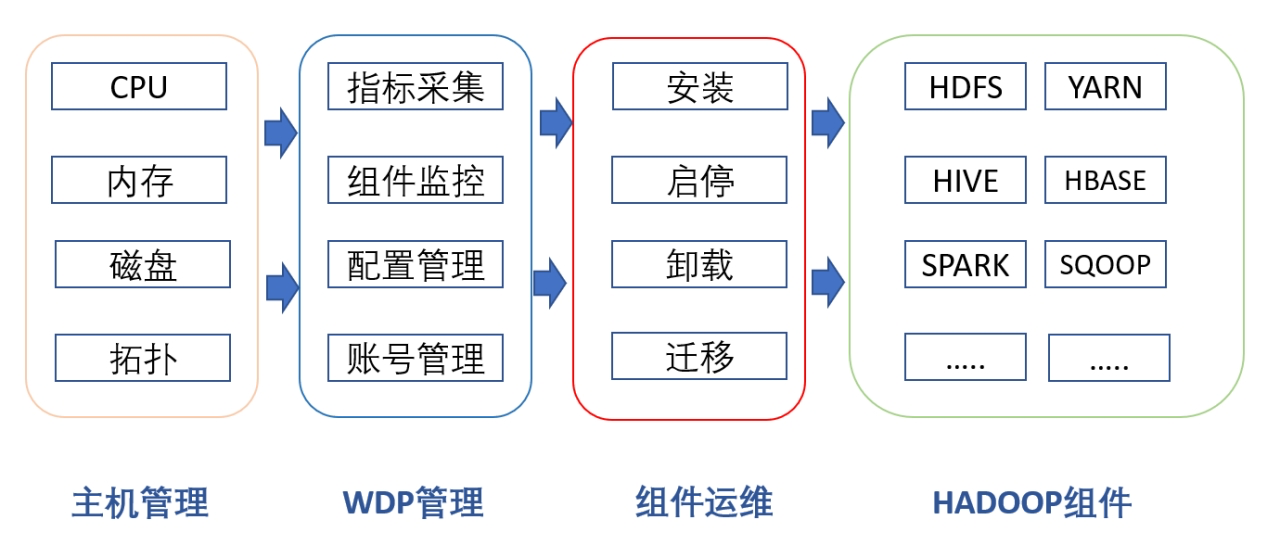
架构主要分成主机管理,WDP系统管理,HADOOP组件运维,和集成的HADOOP组件这几块。
主机管理功能使得WDP能够把集群的所有主机纳入托管状态,系统能够获取主机的配置信息,用于后续进行安装HADOOP组件的依据。系统管理功能和WDP的核心,可以在托管的主机之上,对HADOOP组件进行运维,包括安装,启停,组件分配,组件迁移到多种功能。支持多种HADOOP组件的管理,满足不同的业务场景需求。
# 功能架构
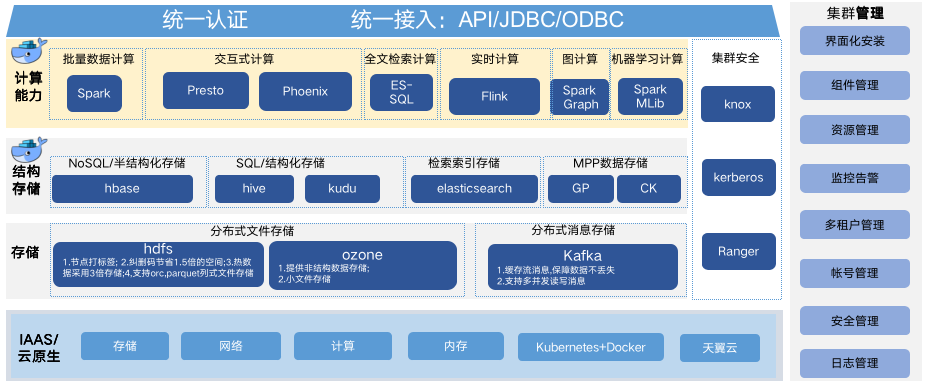
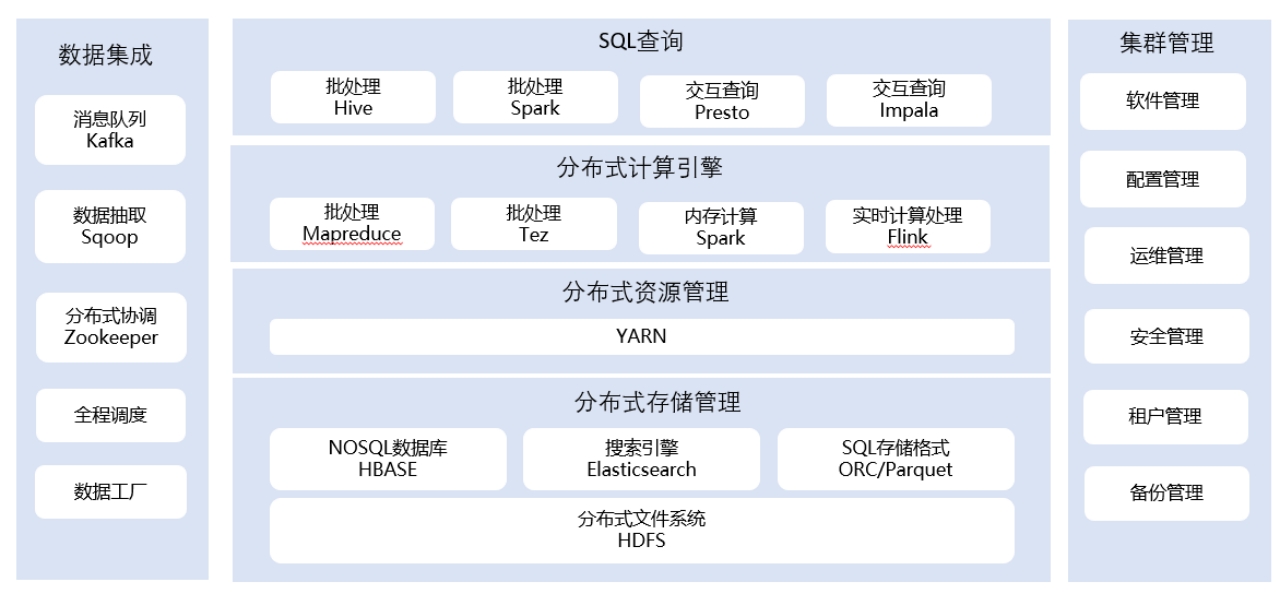
WDP包括集群管理,分布式存储,分布式资源管理,分布式计算引擎,SQL查询引擎,数据集成等模块
- 集群管理:主要有HADOOP软件源管理,组件啊配置管理,运维监控,安全管理,租户管理,备份管理等功能
- **分布式存储管理:**使用分布式文件系统HDFS作为底层的存储,支持NOSQL查询数据库HBASE,ES索引,ORC,PARQUET存储格式等。
- **分布式资源原理:**使用HADOOP组件YARN作为集群资源队列管理器,分布式计算作业都统一提交到YARN上运行
- **分布式计算引擎:**支持经典的HADOOP分布式计算引擎MR, 默认使用新一代的TEZ内存计算引擎作为HIVE的计算引擎,集成内存计算SPARK,实时计算框架FLINK
- **SQL查询引擎:**支持主流的批量SQL处理引擎HIVE-SQL, SPARK-SQL,引入了实时交互查询引擎 Presto,IMPALA
- **数据集成:**集成SQOOP模块作为关系型数据库导入到HIVE库的组件,集成KAFKA消息中间件。通过对接全程调度和数据工厂,支持复杂的ETL作业和数据开发
# 技术架构
# 后端
- Server code: Java 1.8
- Agent scripts: Python
- Database: Postgres, Oracle, MySQL
- ORM: EclipseLink
- Security: Spring Security with remote LDAP integration and local database
- REST server: Jersey (JAX-RS)
- Dependency Injection: Guice
- Unit Testing: JUnit
- Mocks: EasyMock
- Configuration management: Python
# 前端
- Frontend code: JavaScript
- Client-side MVC framework: Ember.js / AngularJS
- Templating: Handlebars.js (integrated with Ember.js)
- DOM manipulation: jQuery
- Look and feel: Bootstrap 2
- CSS preprocessor: LESS
- Unit Testing: Mocha
- Mocks: Sinon.js
- Application assembler/tester: Brunch / Grunt / Gulp