 cdp&FusionInsight相关对标
cdp&FusionInsight相关对标
# 对标CDH/CDP (opens new window)
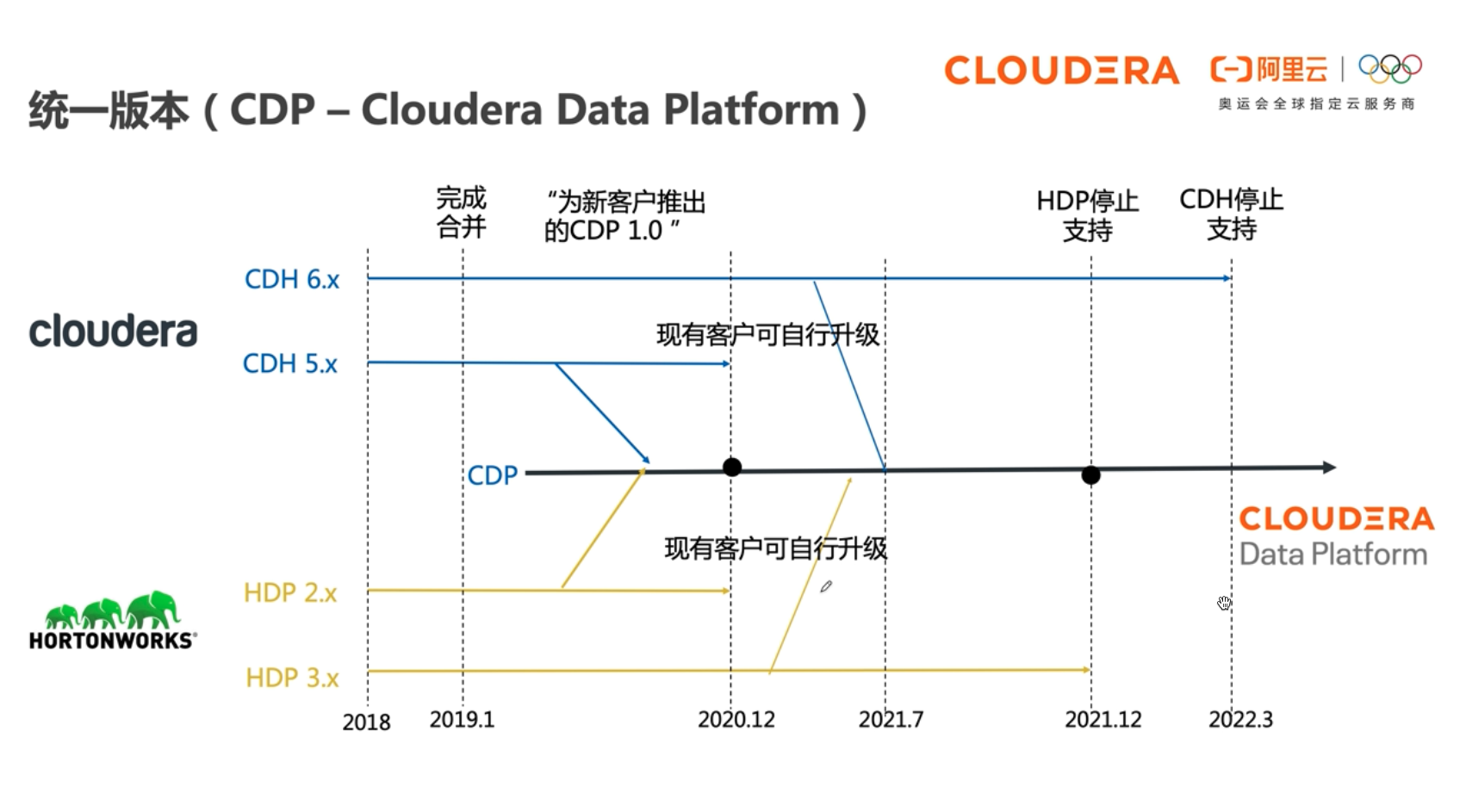
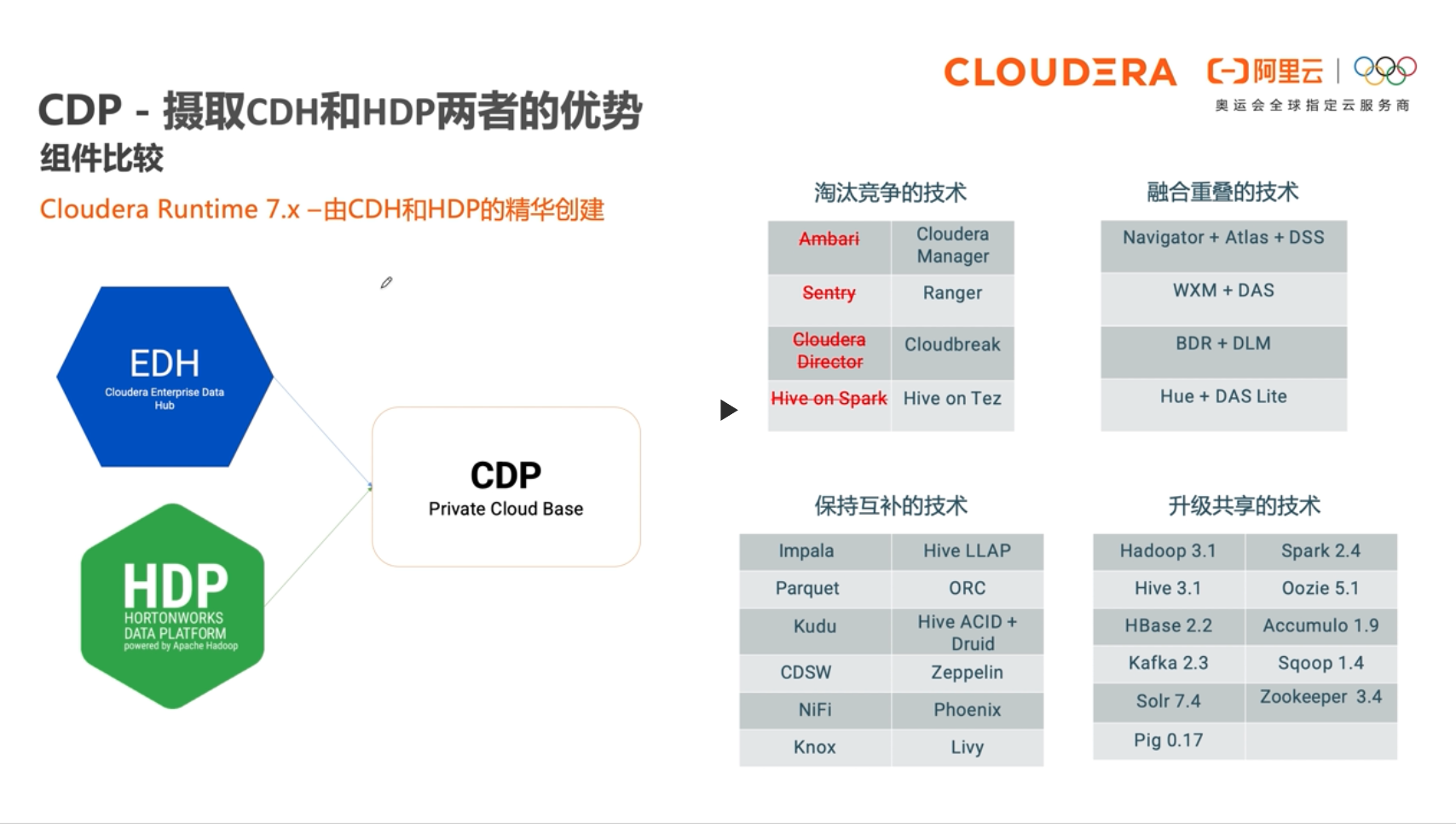
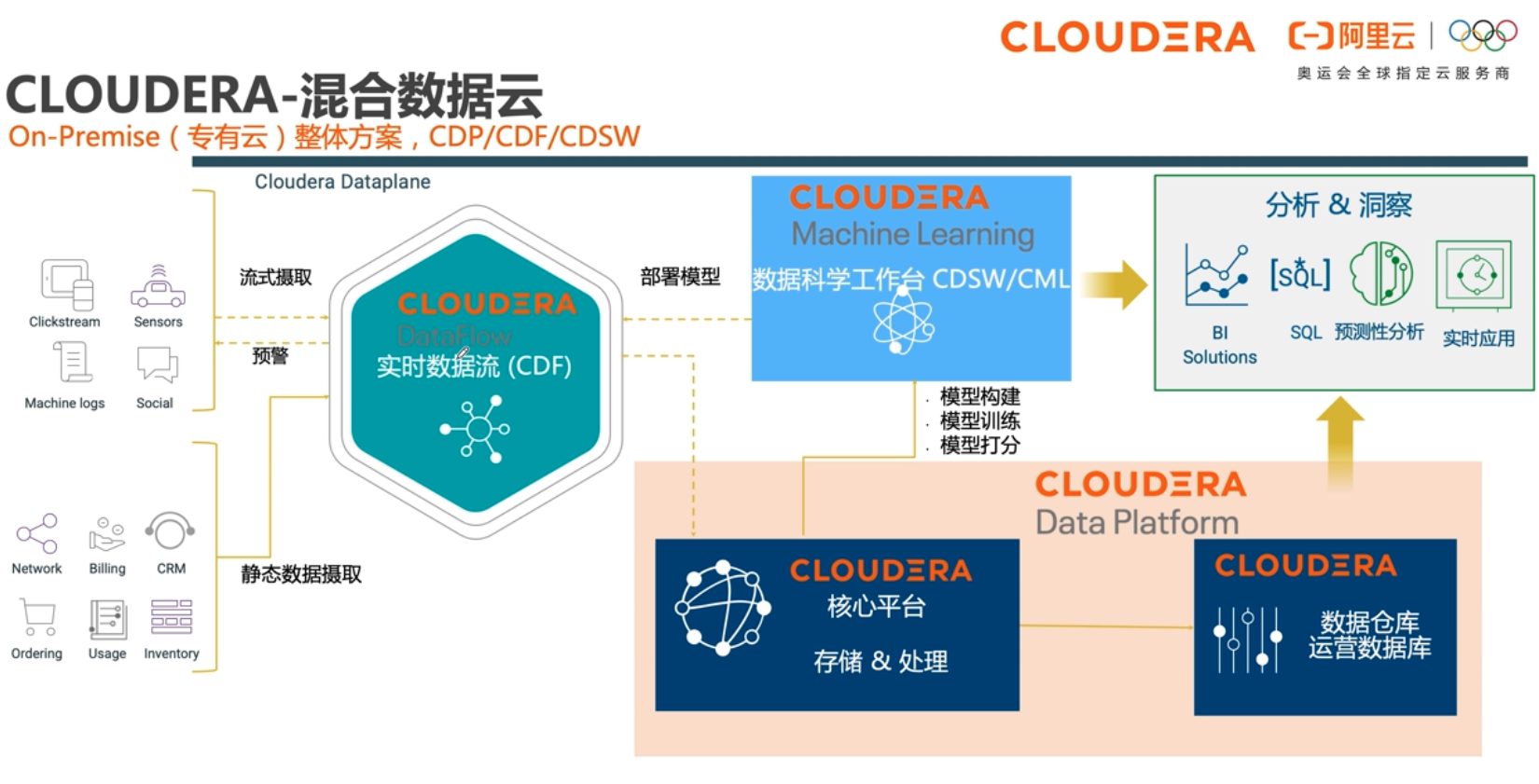
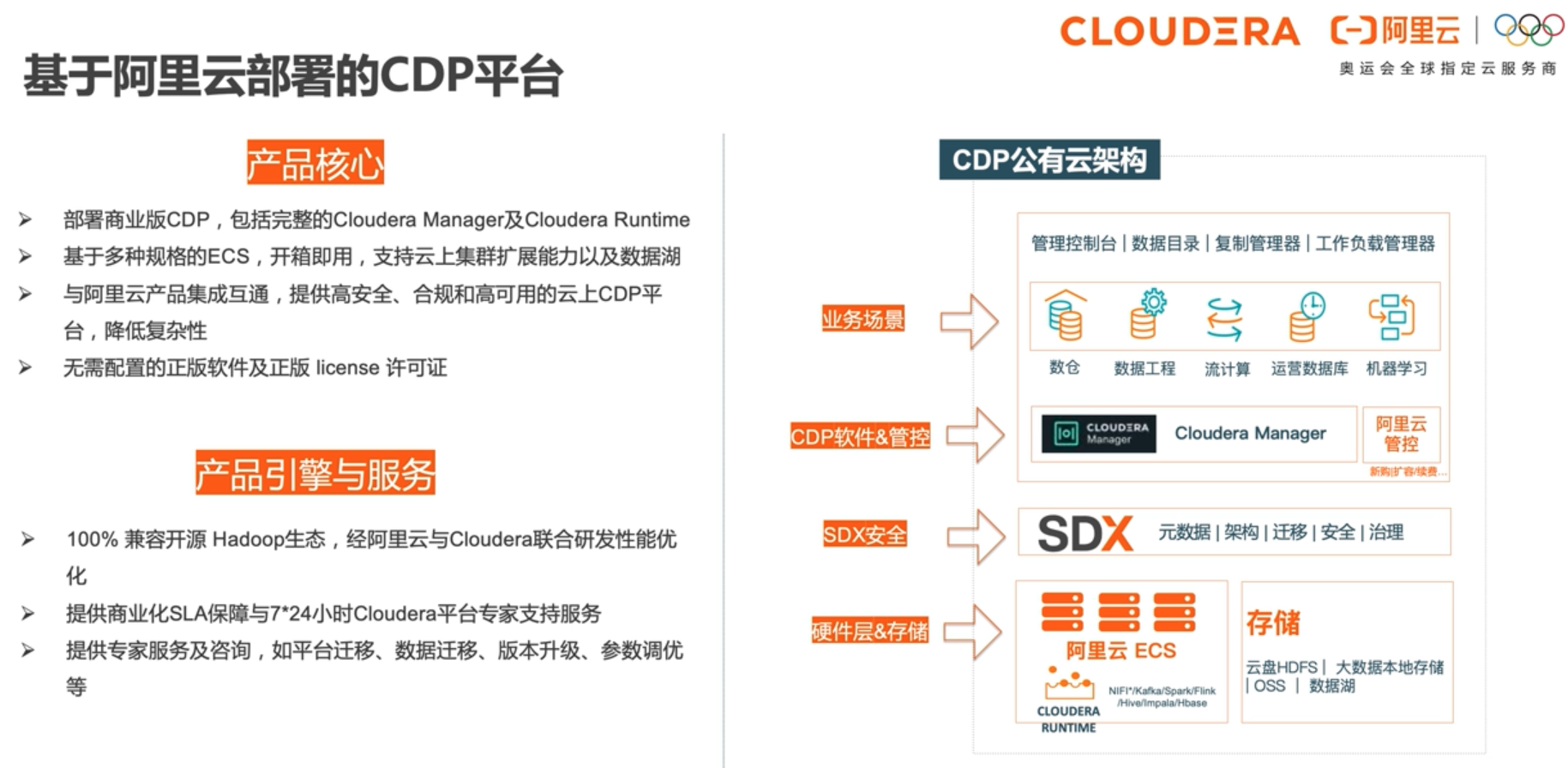
CDP(Cloudera Data Platform)是Cloudera和Hortonworks合并后,选择原CDH和HDP中的精华组件,合并成新一代数据平台。阿里云与Cloudera联合打造了阿里云上的半托管形态CDP企业数据云平台。该平台可以灵活地运⾏各种企业⼯作负载,⽀持从边缘计算到⼈⼯智能的多功能数据分析,提供企业级的安全模型来保证客户数据安全。
Cloudera Manager是用于管理、配置和监控CDP集群和Cloudera Runtime服务的应用程序。
Cloudera Manager服务器在CDP部署中的主机上运行,并使用在集群中每个主机上运行的Cloudera Manager代理来管理一个或多个集群。
Cloudera Manager是用于管理集群的端到端应用程序。借助Cloudera Manager,您可以轻松地部署和集中操作完整的Cloudera Runtime堆栈和其他托管服务。该应用程序可自动执行安装和升级过程,并为您提供主机和正在运行的服务的整个群集的实时视图。Cloudera Manager管理控制台提供了一个中央控制台,您可以在其中对整个集群进行配置更改,并结合了各种报告和诊断工具来帮助您优化性能和利用率。Cloudera Manager还管理安全性和加密功能。使用Cloudera Manager管理控制台,您可以启动和停止集群以及单个服务、配置和添加新服务、管理安全性以及升级集群。您还可以使用Cloudera Manager API以编程方式执行管理任务。
Cloudera Manager的单个实例可以管理多个集群,包括较旧版本的Cloudera Runtime和CDH。
CDP还包括以下工具来管理和保护您的部署:
- Cloudera Manager允许您使用Cloudera Manager管理控制台的Web应用程序或Cloudera Manager API管理、监控和配置集群和服务。
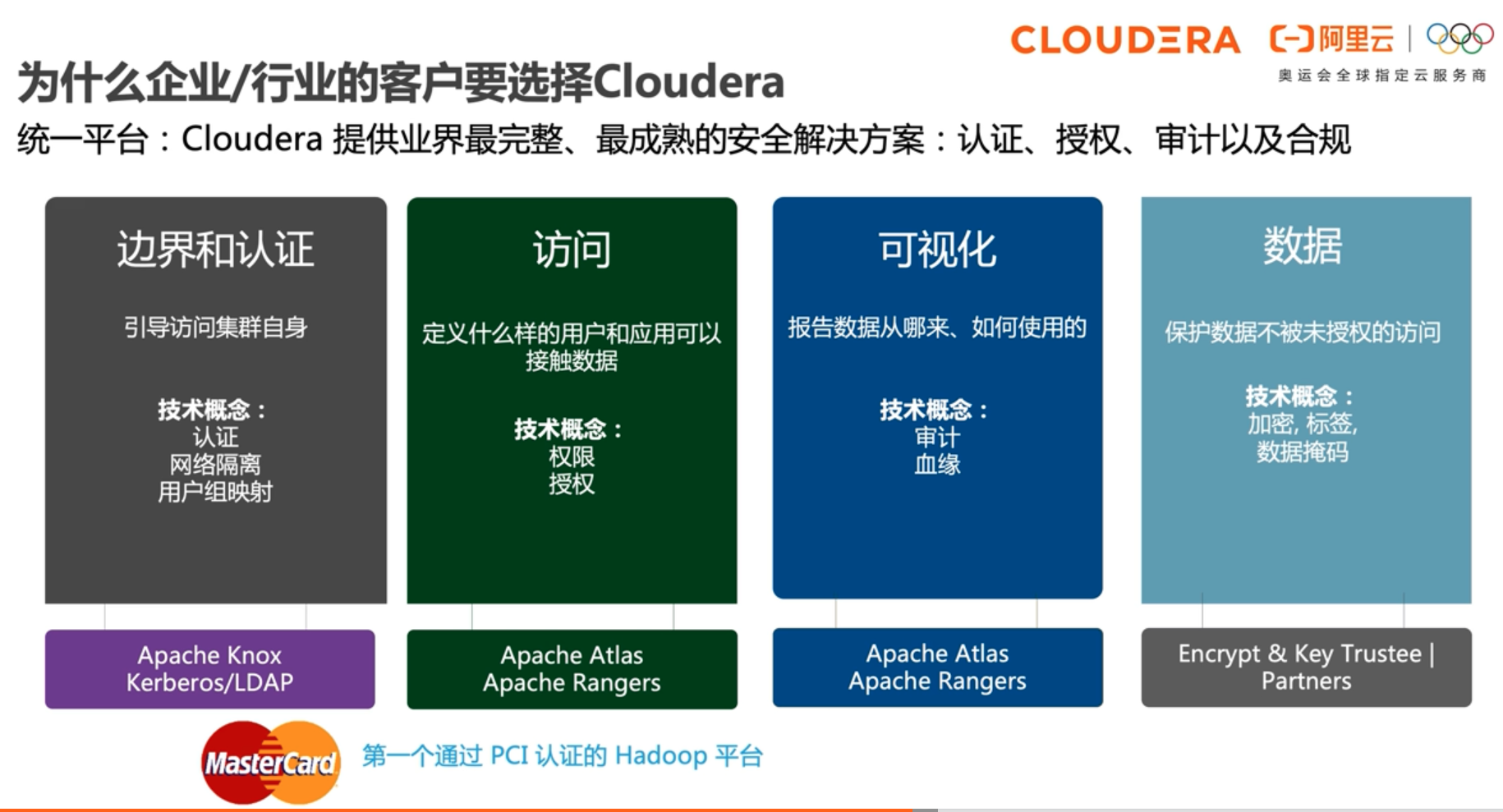
- Apache Atlas提供了一组元数据管理和治理服务,使您能够管理CDP集群资产。
- Apache Ranger通过用户界面管理访问控制,以确保CDP集群中一致的策略管理。
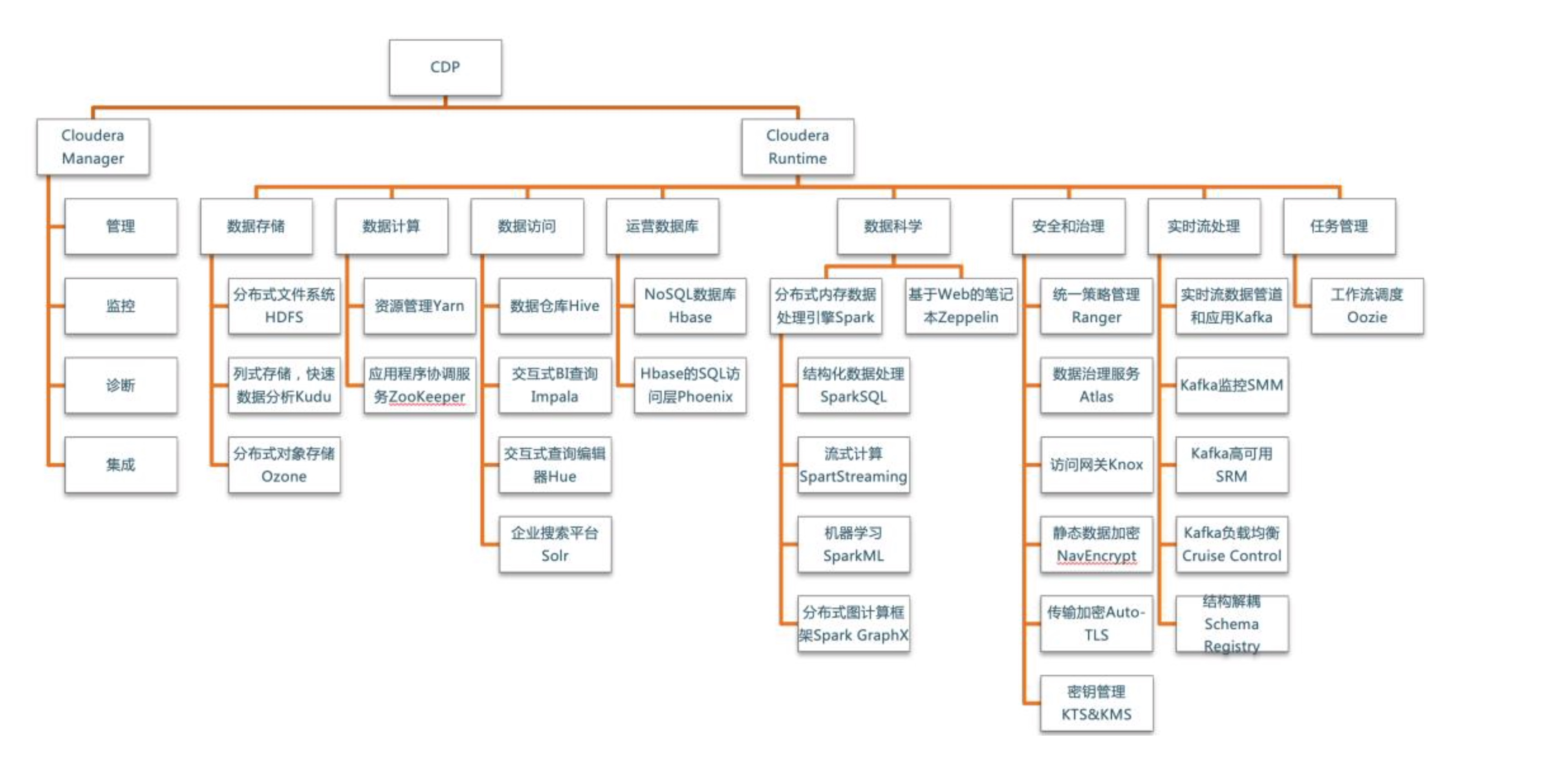
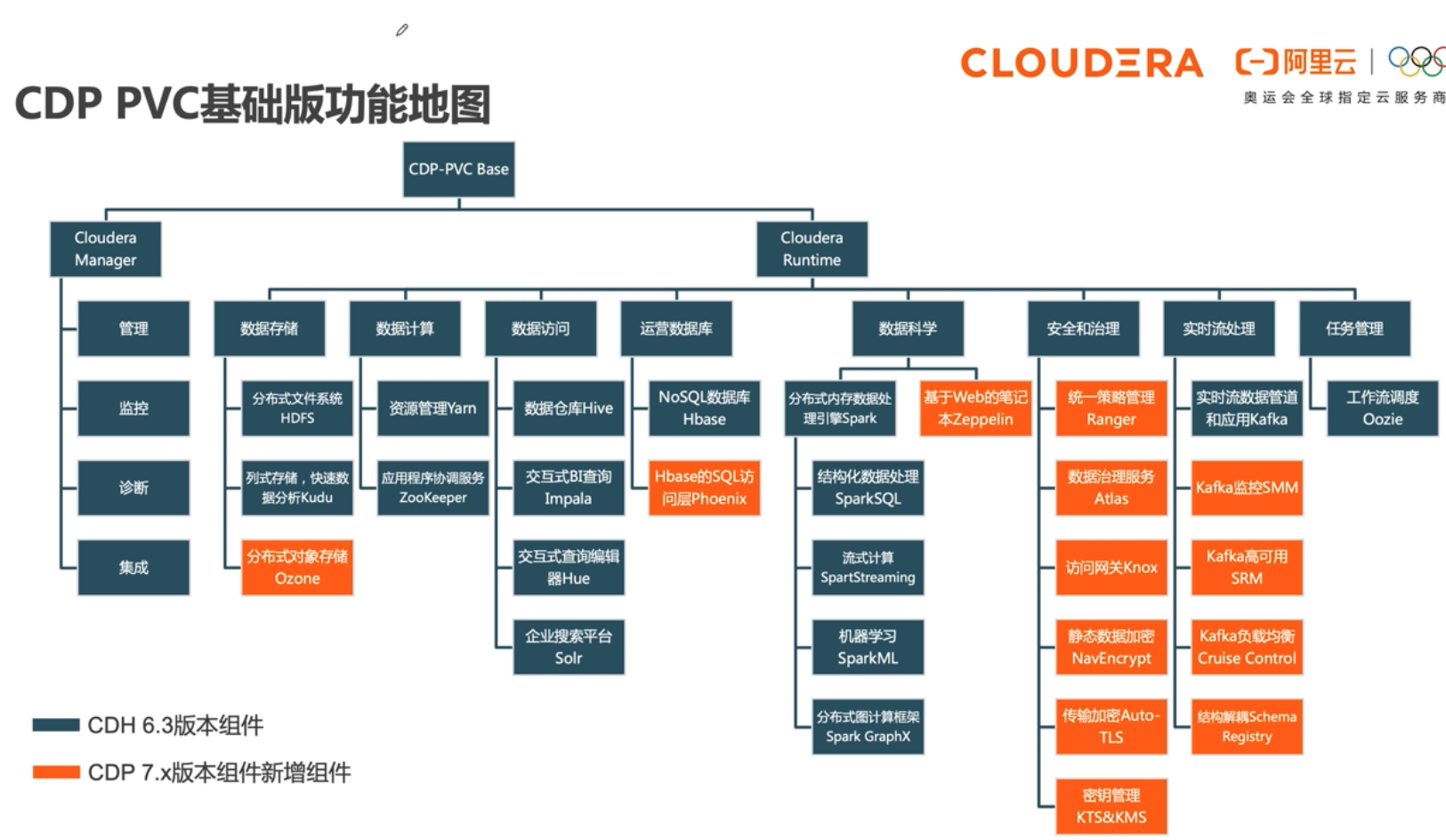
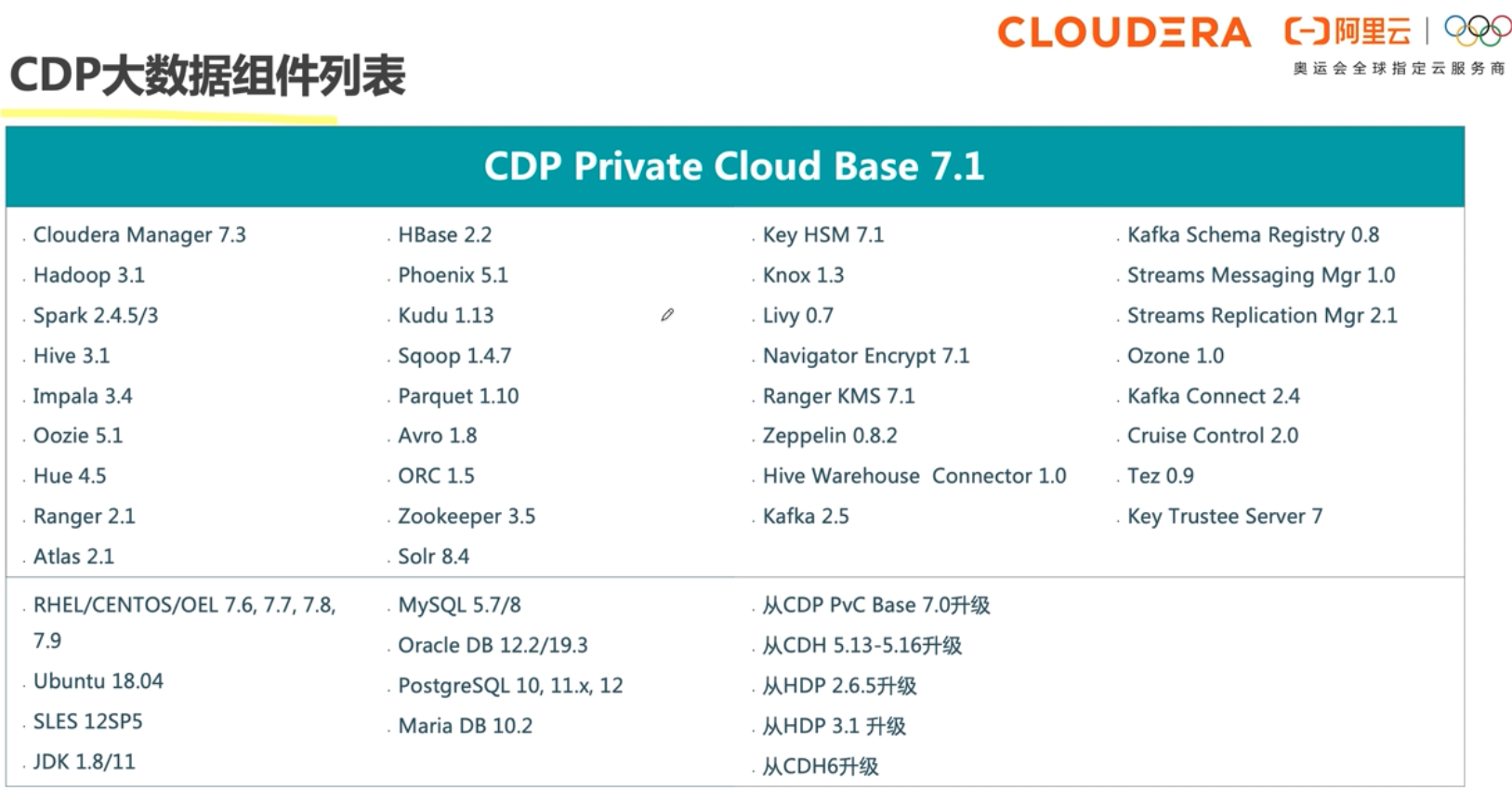
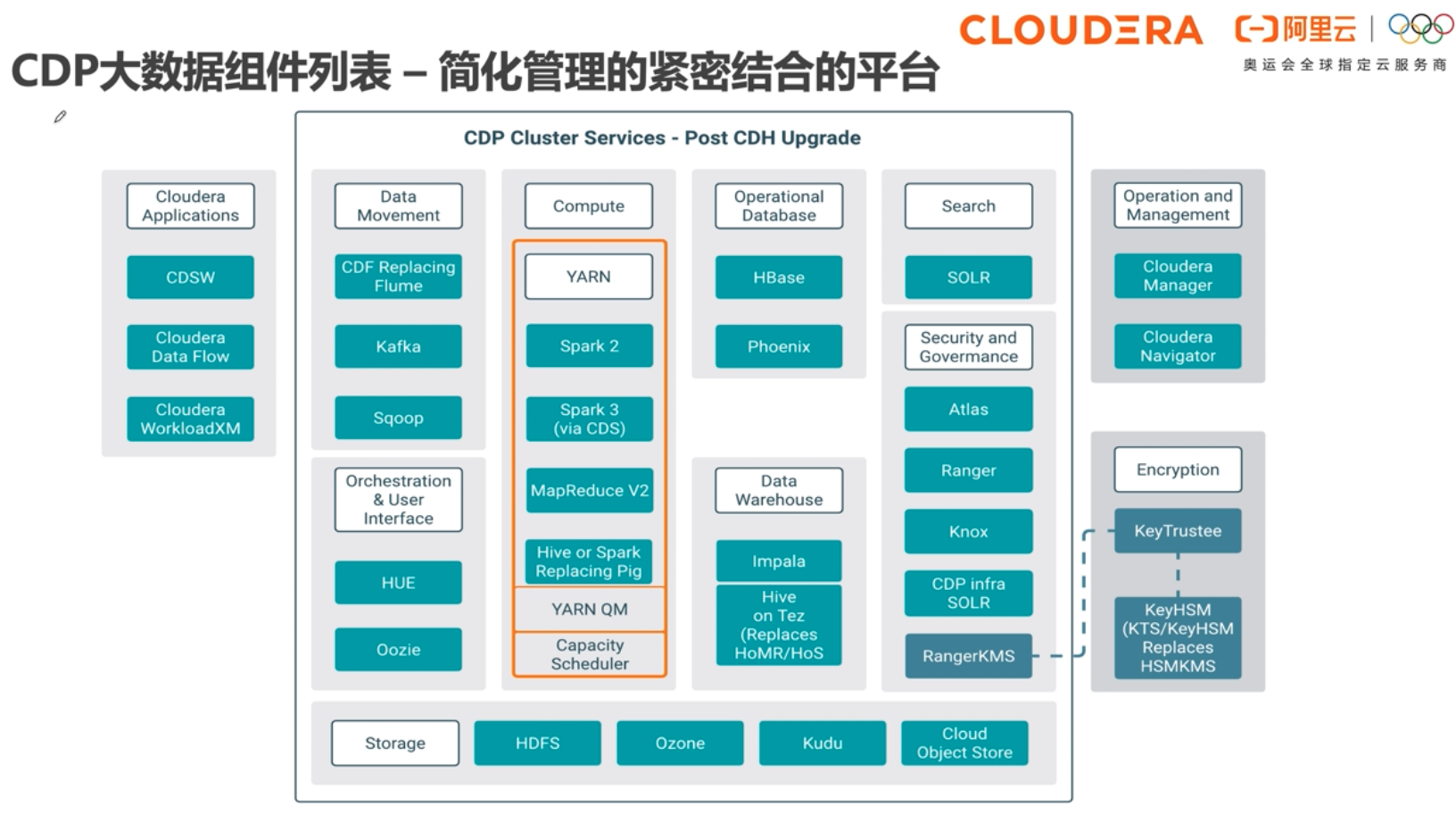
Cloudera Runtime是CDP Private Cloud Base中的核心开源软件发行版。Cloudera Runtime包括大约50个开源项目,这些项目构成CDP中数据管理工具的核心分发。

# 产品架构
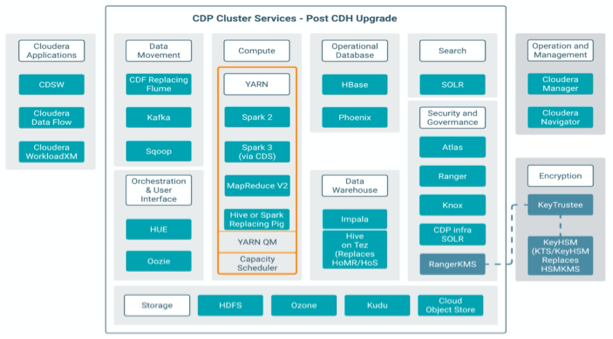
# 功能地图
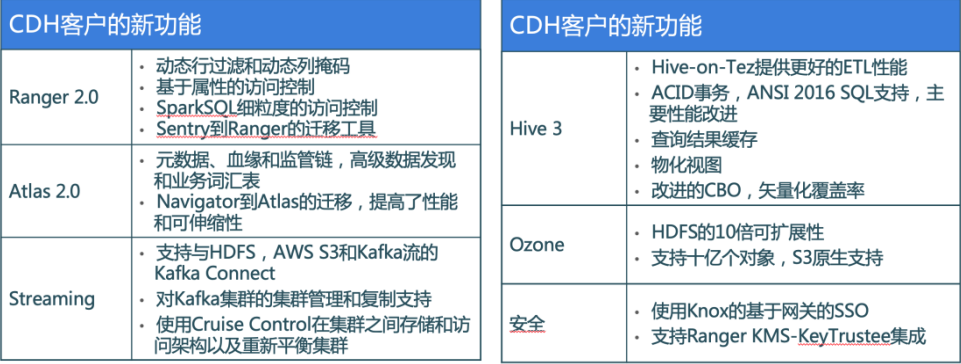
# 新功能
从 CDH 到 CDP 的新功能
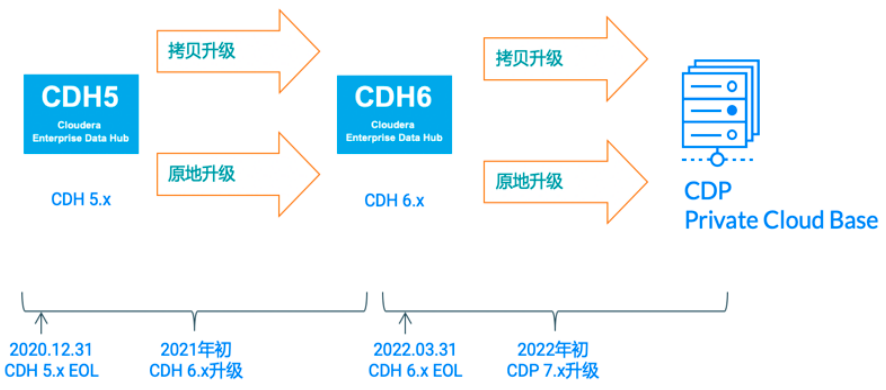
# 其他功能


# 参考链接
- https://help.aliyun.com/product/428836.html?spm=5176.23732685.J_5138397340.4.48db50abBbZAIb
- https://help.aliyun.com/document_detail/429897.html?spm=a2c4g.11186623.0.0.47417c58Wl48zk
- 阿里社区 (opens new window)
# 对标FusionInsight M (opens new window)
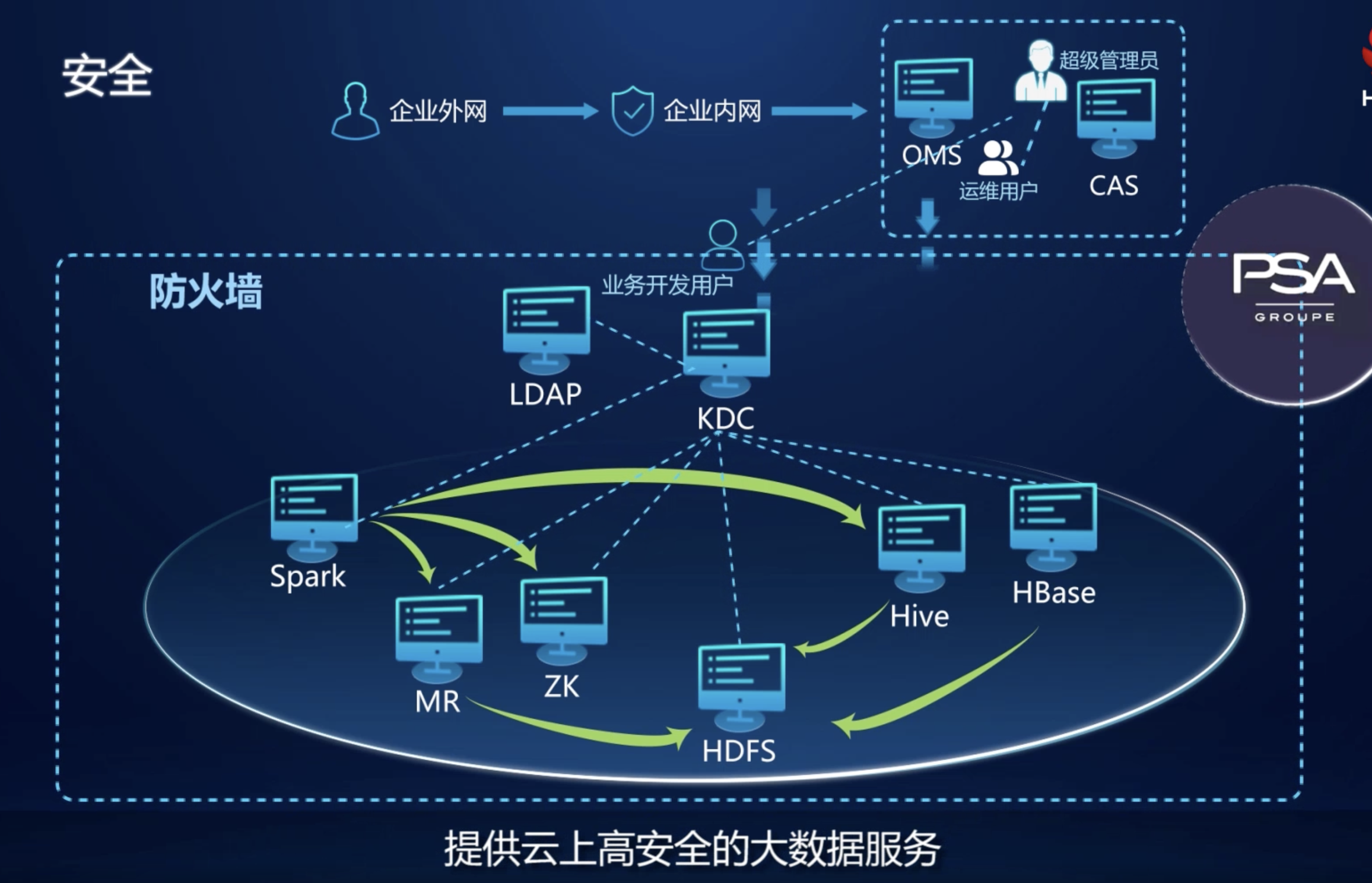
Fusion Insight Manager:企业级大数据的操作运维系统,提供高可靠、安全、容错、易用的集群管理能力,支持大规模集群的安装部署、监控、告警、用户管理、权限管理、审计、服务管理、健康检查、问题定位、升级和补丁等功能。
# 参考链接
- https://support.huaweicloud.com/usermanual-mrs/admin_guide_000002.html
- https://support.huaweicloud.com/usermanual-mrs/mrs-usermanual.pdf
# 对标EMR阿里云 (opens new window)
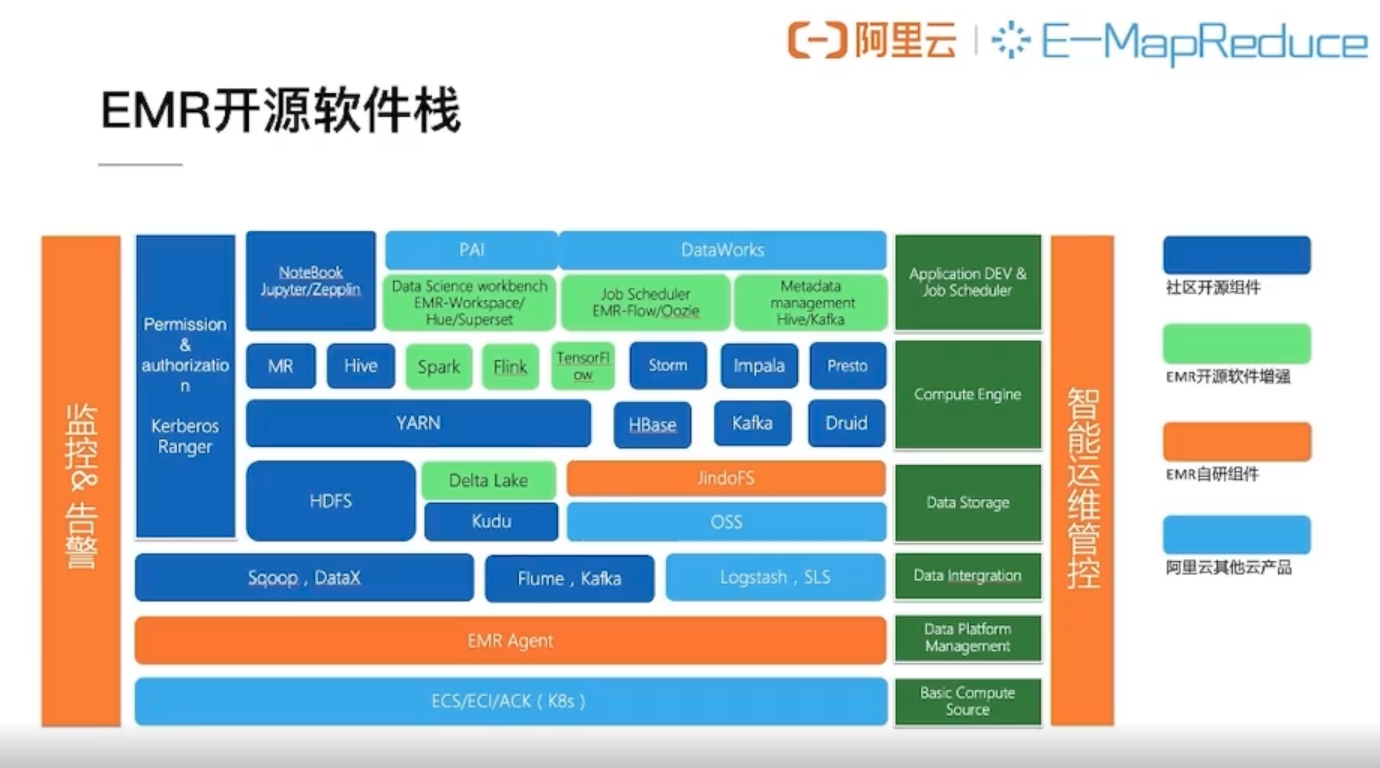
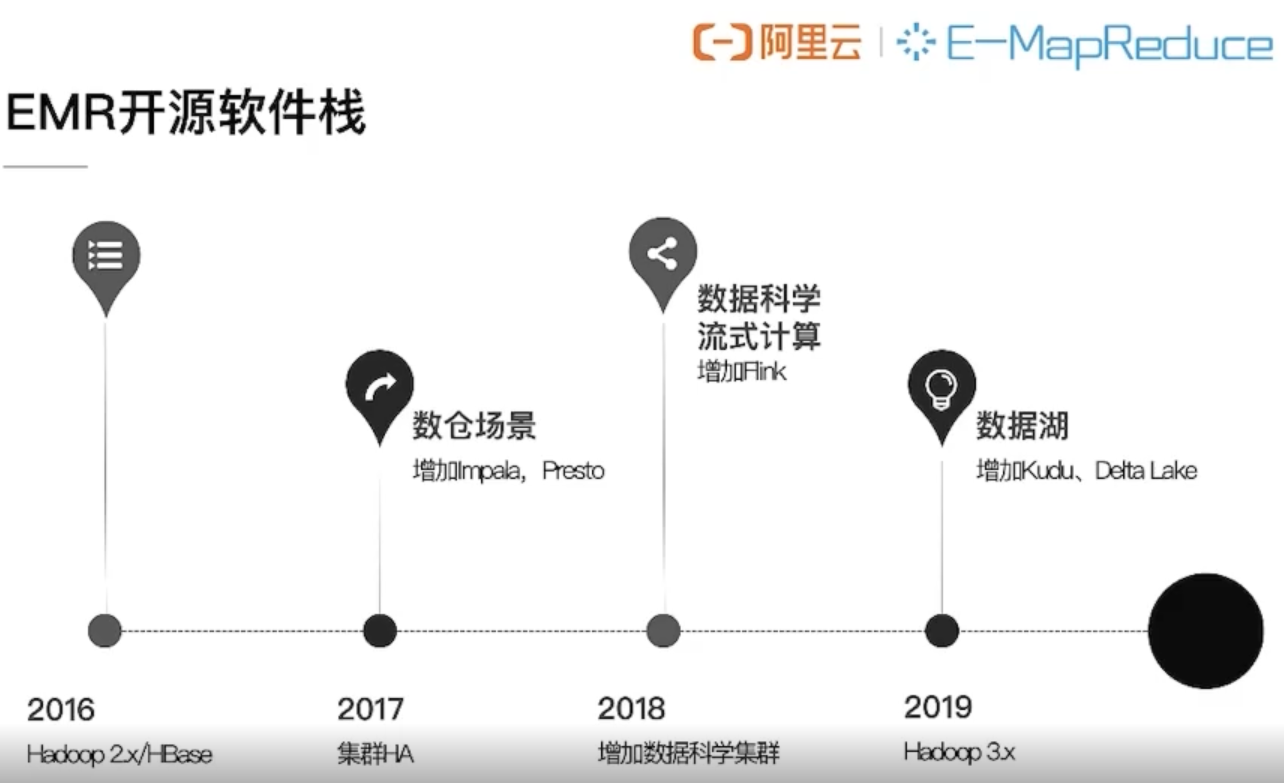
开源大数据开发平台E-MapReduce(简称EMR),是运行在阿里云平台上的一种大数据处理的系统解决方案。
# 简介
开源大数据开发平台EMR构建于云服务器ECS上,基于开源的Apache Hadoop和Apache Spark,让您可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿里云OSS和RDS等)进行数据传输。
开源大数据开发平台EMR的SmartData组件是EMR Jindo引擎的主要存储部分,为开源大数据开发平台EMR各个计算引擎提供统一的存储优化、缓存优化、计算缓存加速优化和多个存储功能扩展。


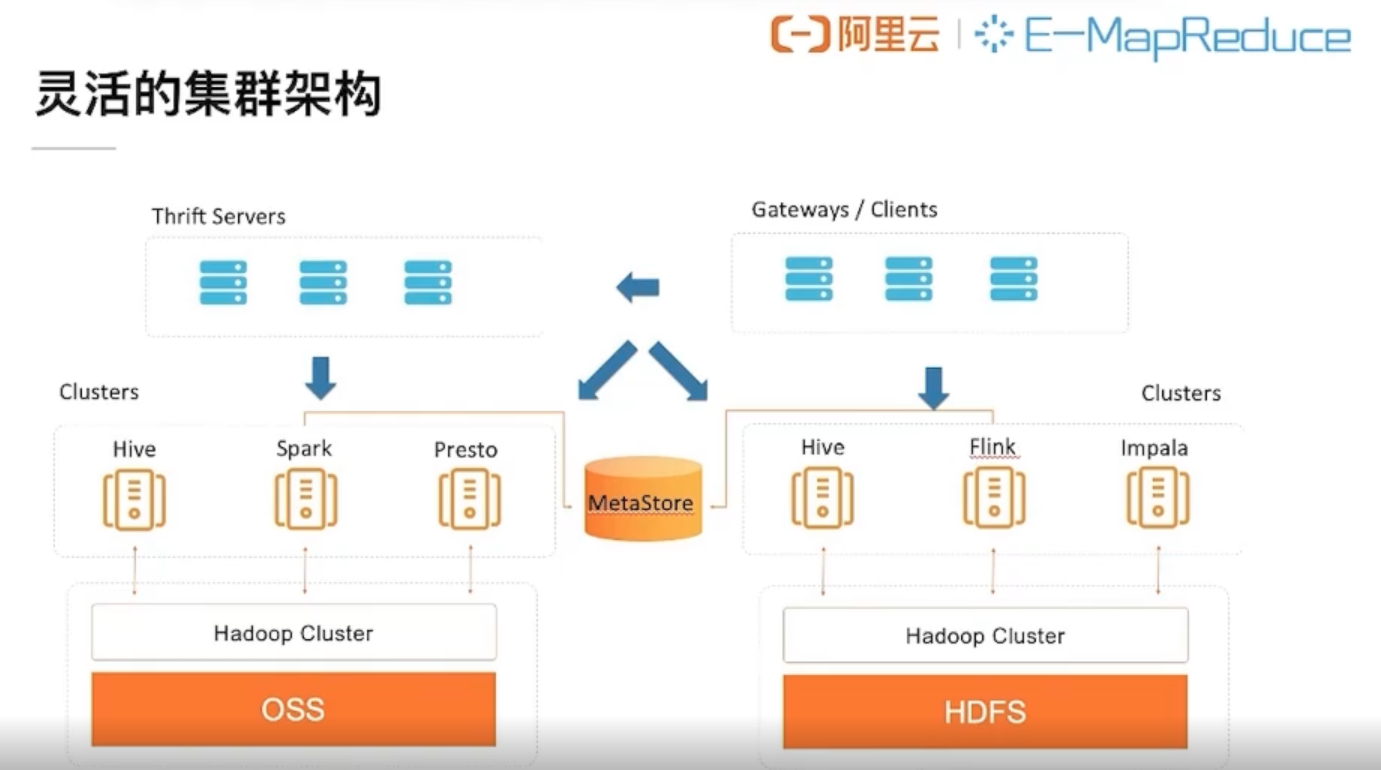

# 架构
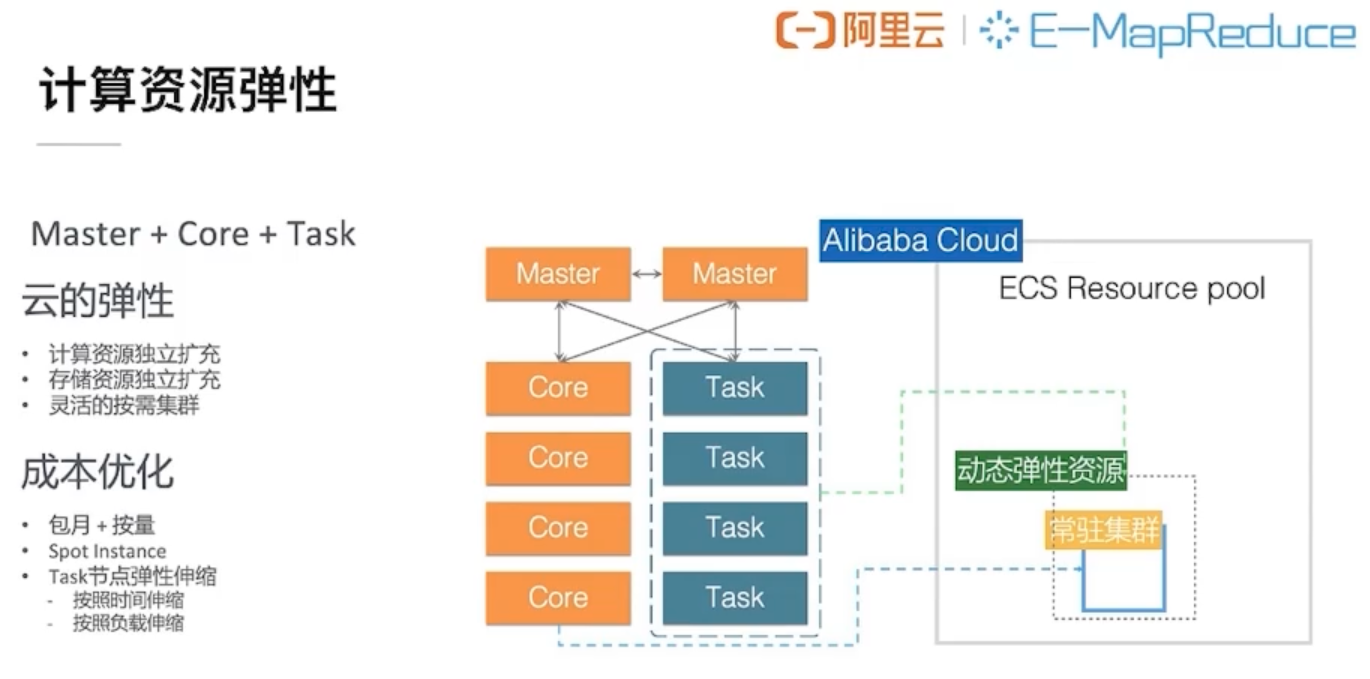
EMR的产品架构如下图所示。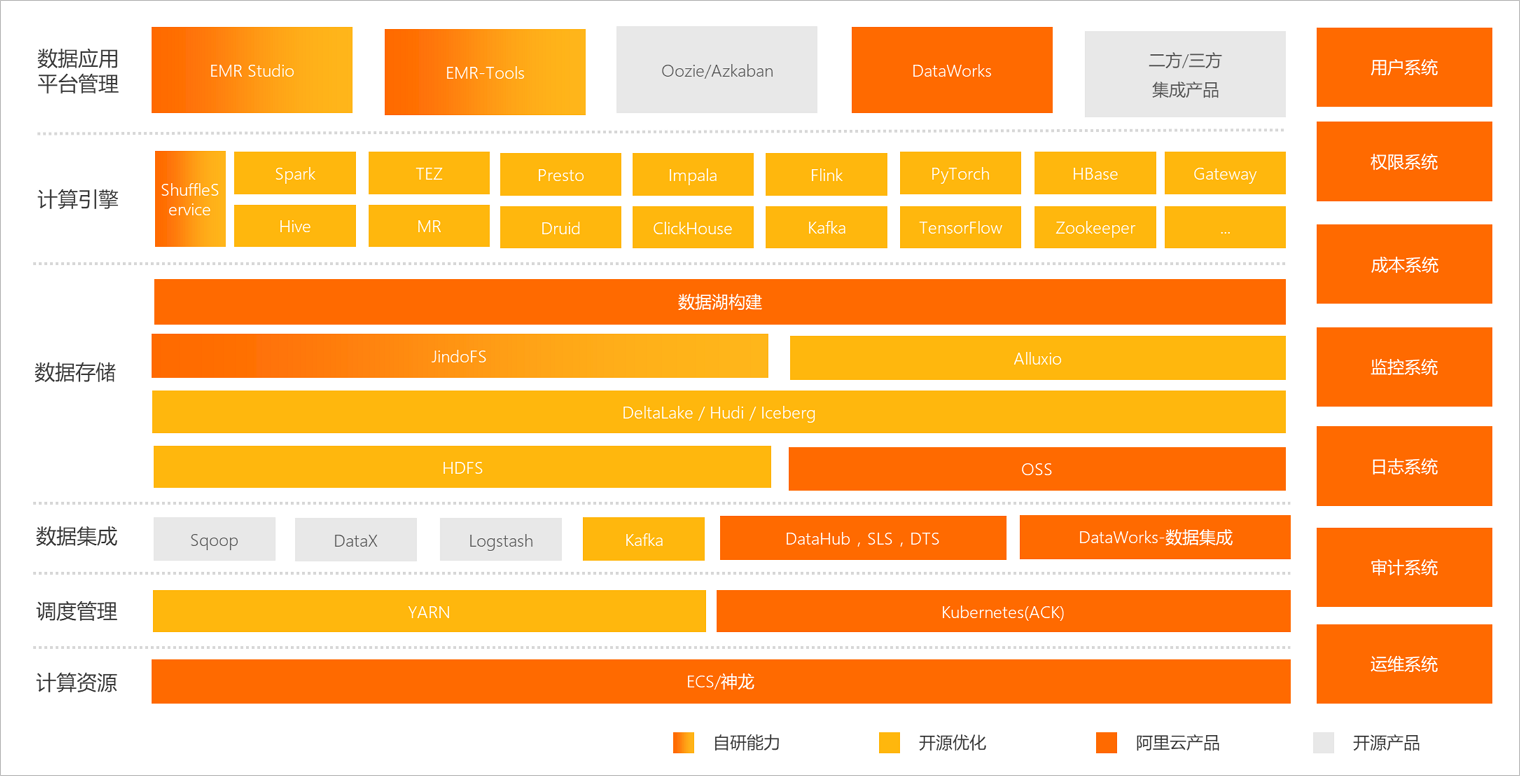
# 应用场景
E-MapReduce集群适用多种使用场景,同时支持Hadoop EcoSystem和Spark能够支持的所有场景。
E-MapReduce本质是Hadoop和Spark的集群服务,您完全可以将其使用的阿里云ECS主机视为您专属的物理主机。以下示例列出了E-MapReduce使用的经典场景:
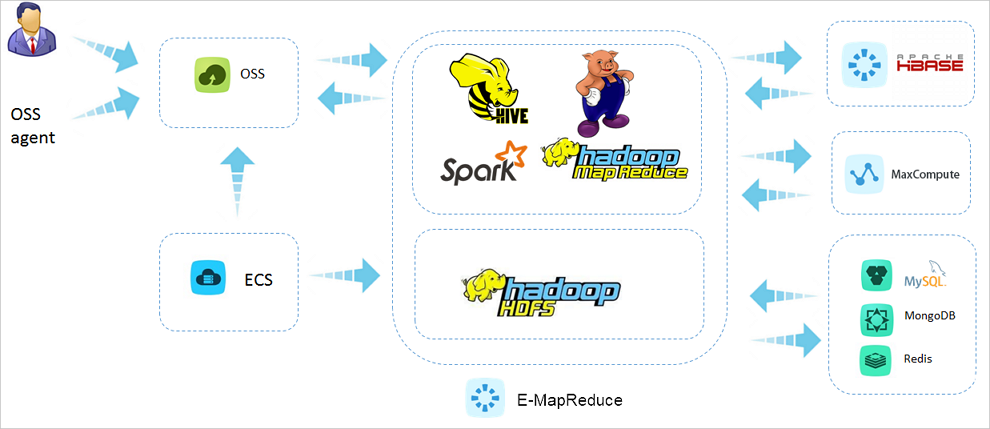
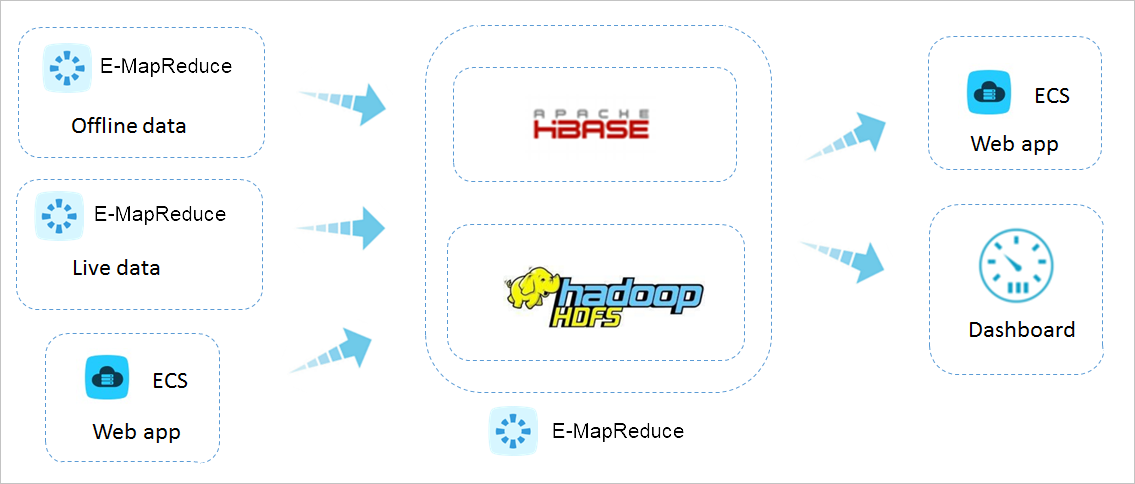
# 批量数据处理
将海量日志同步到E-MapRedue的数据节点后,您可以借助于Hue等工具使用Hive、Spark和Presto等主流计算框架快速获取数据洞察力。您还可以使用Sqoop等工具加载分散于各RDS或其他存储引擎的数据,并把分析后的数据同步到RDS,为数据可视化产品提供数据支撑。
# Ad hoc数据分析查询
E-MapReduce将海量数据通过导入或者外表等形式引入到OLAP分析引擎里,例如,Clickhouse、Presto和Impala,提供高效、实时和灵活的数据分析能力,满足用户画像、人群圈选、BI报表和业务分析等一系列的业务场景。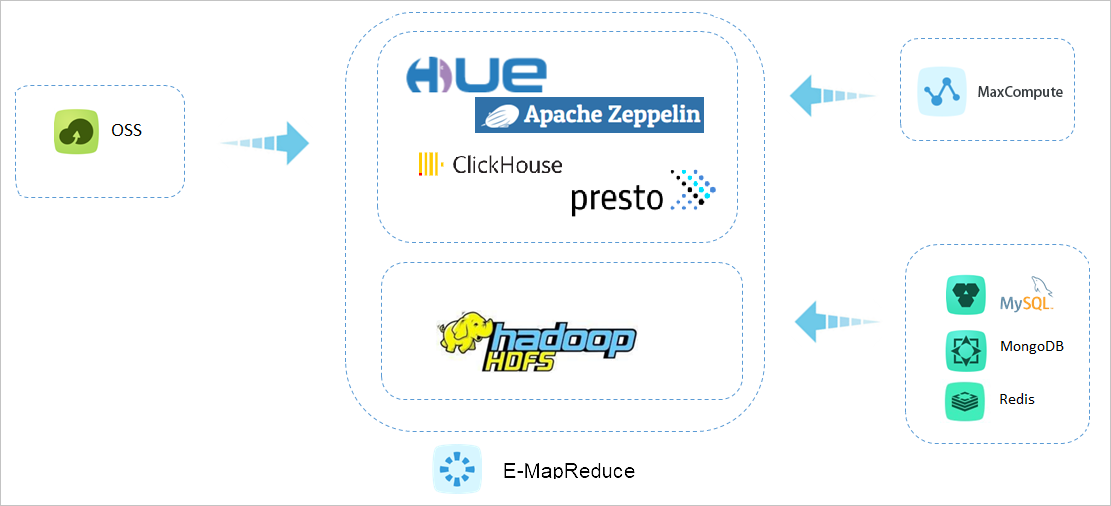
# 海量数据在线服务
E-MapReduce基于Web和移动应用程序等生成的PB级别的结构化、半结构化或非结构化数据进行在线分析,以方便Web应用或者数据可视化产品获取分析结果进行实时展示。
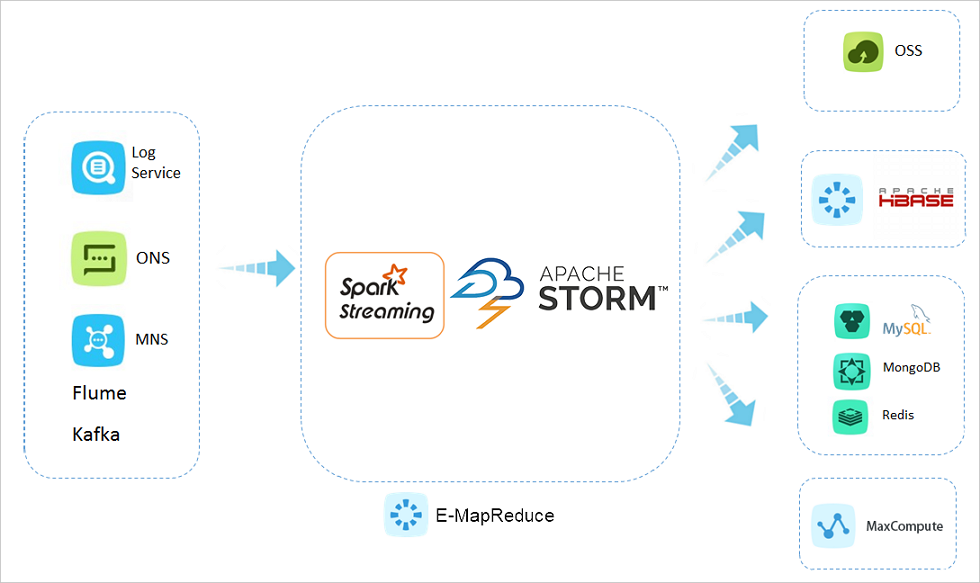
# 流式数据处理
通过Spark Streaming和Storm,使用和处理来自阿里云日志服务Log Service、阿里云消息队列ONS(Message Queue)、阿里云消息服务MNS(Message Service)、Apache Kafka或其他数据流的实时数据。
采用容错方式执行流式数据分析,并将相应结果写入阿里云对象存储服务OSS(Object Storage Service)或HDFS中。
# DataWorks (opens new window)
# 技术架构选型
在数据模型设计之前,您需要首先完成技术架构的选型。本教程中使用阿里云大数据产品MaxCompute配合DataWorks,完成整体的数据建模和研发流程。
完整的技术架构图如下图所示。其中,DataWorks的数据集成负责完成数据的采集和基本的ETL。MaxCompute作为整个大数据开发过程中的离线计算引擎。DataWorks则包括数据开发、数据质量、数据安全、数据管理等在内的一系列功能。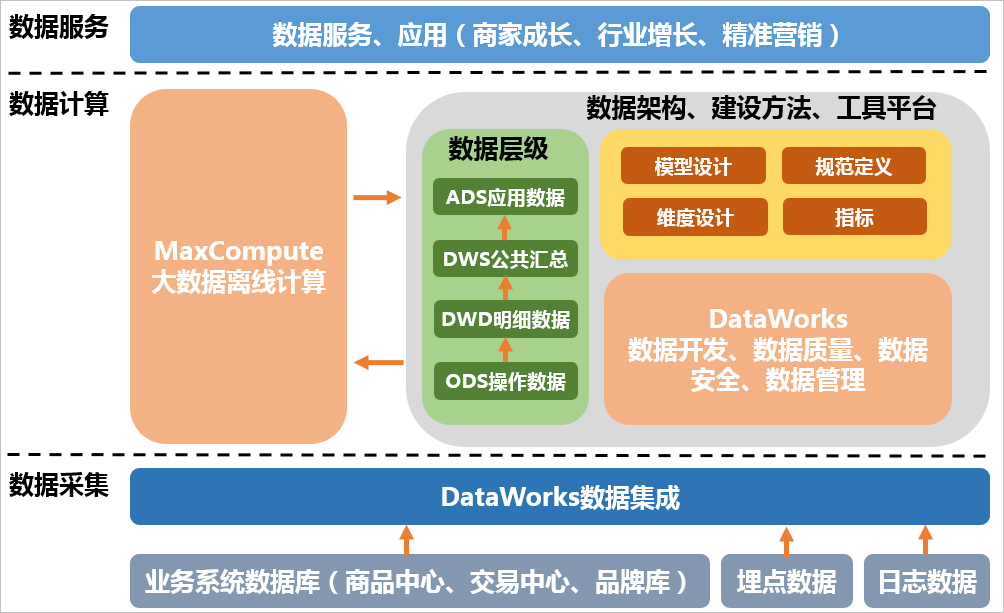
# 数仓分层
在阿里巴巴的数据体系中,我们建议将数据仓库分为三层,自下而上为:数据引入层(ODS,Operation Data Store)、数据公共层(CDM,Common Data Model)和数据应用层(ADS,Application Data Service)。
数据仓库的分层和各层级用途如下图所示。
数据引入层ODS(Operation Data Store):存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主要完成基础数据引入到MaxCompute的职责,同时记录基础数据的历史变化。
数据公共层CDM(Common Data Model,又称通用数据模型层),包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
公共维度层(DIM):基于维度建模理念思想,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险。
公共维度层的表通常也被称为逻辑维度表,维度和维度逻辑表通常一一对应。
公共汇总粒度事实层(DWS):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表。
公共汇总粒度事实层的表通常也被称为汇总逻辑表,用于存放派生指标数据。
明细粒度事实层(DWD):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
明细粒度事实层的表通常也被称为逻辑事实表。
数据应用层ADS(Application Data Service):存放数据产品个性化的统计指标数据。根据CDM与ODS层加工生成。
该数据分类架构在ODS层分为三部分:数据准备区、离线数据和准实时数据区。整体数据分类架构如下图所示。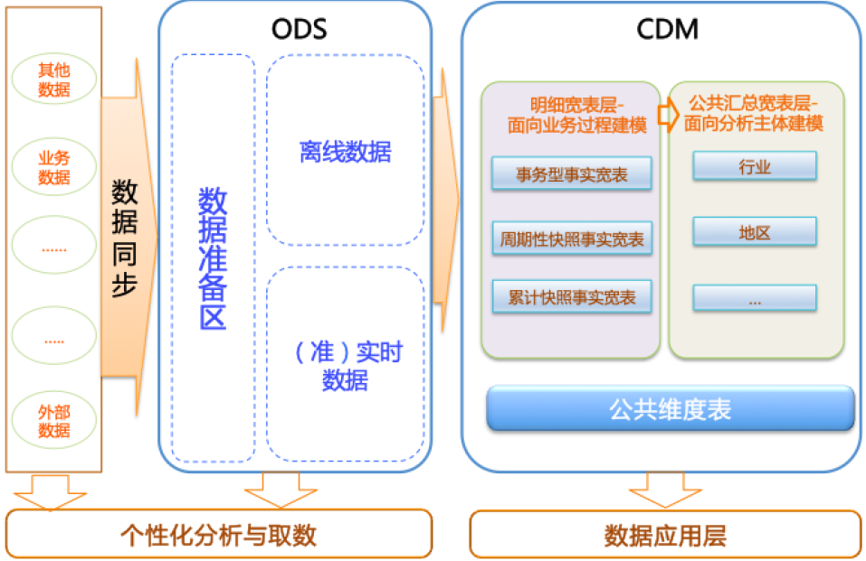 在本教程中,从交易数据系统的数据经过DataWorks数据集成,同步到数据仓库的ODS层。经过数据开发形成事实宽表后,再以商品、地域等为维度进行公共汇总。
在本教程中,从交易数据系统的数据经过DataWorks数据集成,同步到数据仓库的ODS层。经过数据开发形成事实宽表后,再以商品、地域等为维度进行公共汇总。
整体的数据流向如下图所示。其中,ODS层到DIM层的ETL(萃取(Extract)、转置(Transform)及加载(Load))处理是在MaxCompute中进行的,处理完成后会同步到所有存储系统。ODS层和DWD层会放在数据中间件中,供下游订阅使用。而DWS层和ADS层的数据通常会落地到在线存储系统中,下游通过接口调用的形式使用。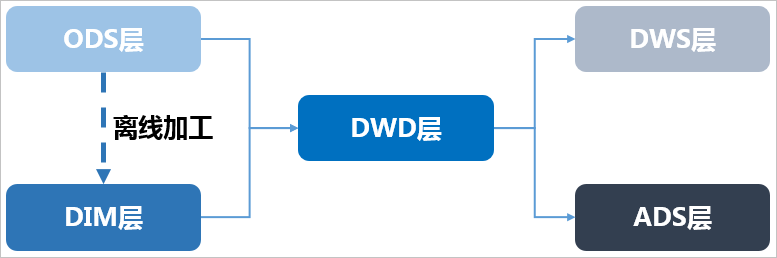
# 参考链接
- https://help.aliyun.com/product/28066.html?spm=a2c4g.11186623.0.0.6ce06c8cYjxUka
# 对标EasyMR袋鼠云 (opens new window)
# 简介
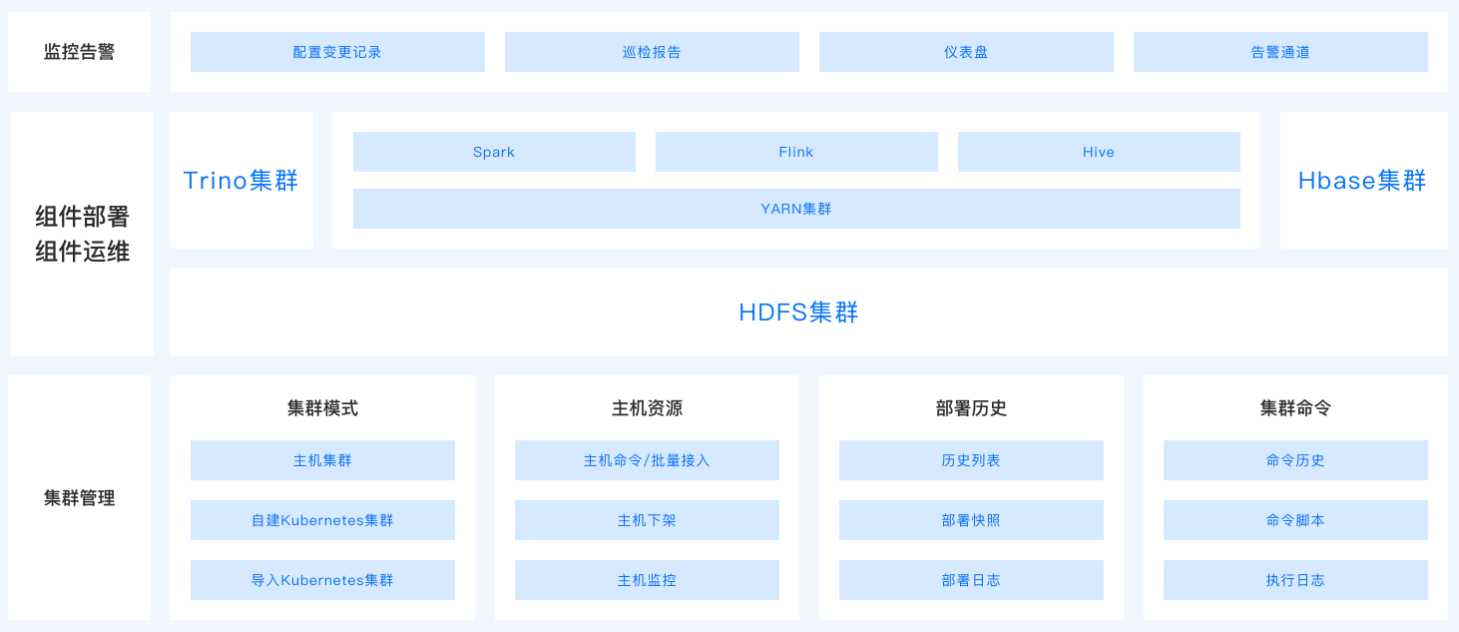
大数据基础平台(EasyMR),提供Hadoop、Hive、Spark、Trino、HBase、Kafka等组件,完全兼容Apache开源生态;支持企业级安全管控,一键开启LDAP+Kerberos+Ranger认证权限体系;提供一站式运维管理平台,帮助企业快速构建大数据平台,降低运维成本;
# 产品架构
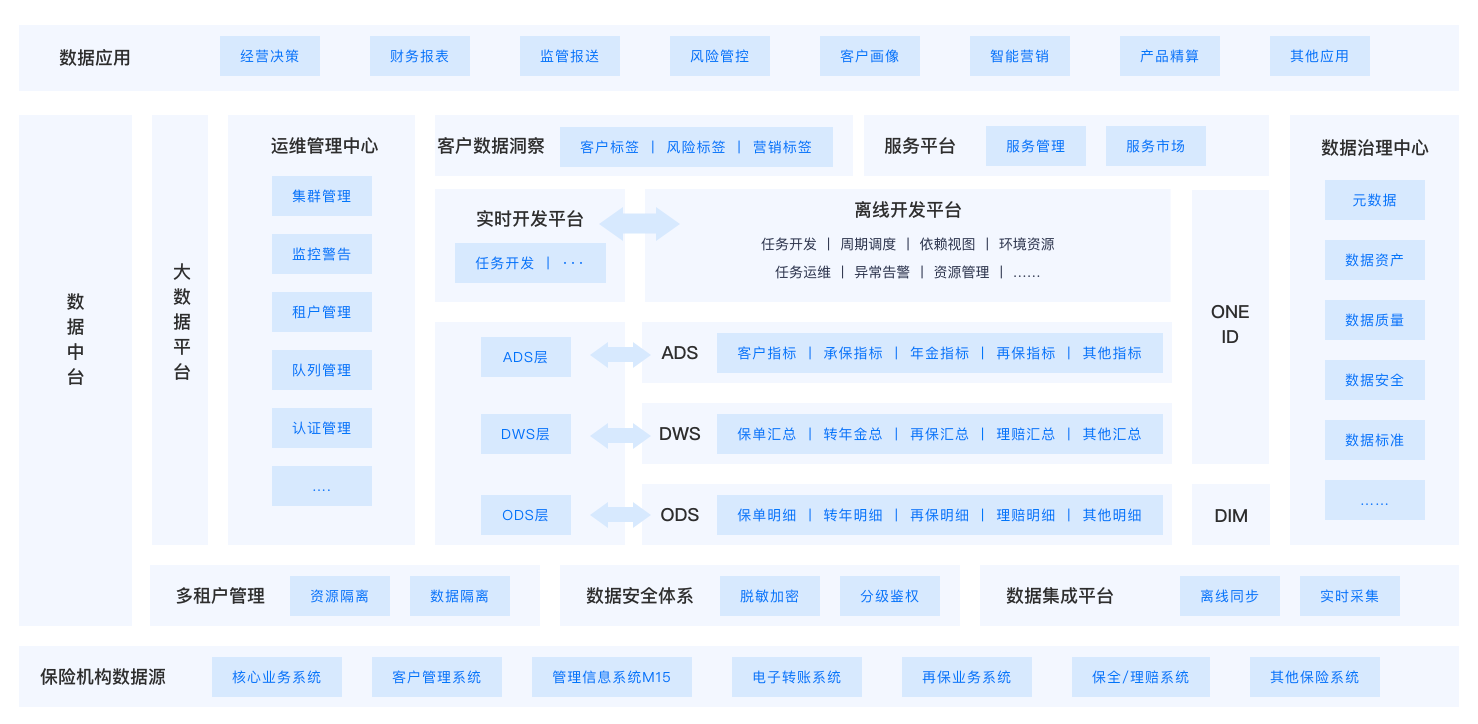
保险行业
# 参考链接
- https://www.dtstack.com/dtengine/easymr