 ckman部署实践
ckman部署实践
# clickhouse包准备
# 单独命令安装
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
sudo yum install -y clickhouse-server clickhouse-client
sudo /etc/init.d/clickhouse-server start
clickhouse-client # or "clickhouse-client --password" if you set up a password.
2
3
4
5
6
# 提前离线下载包
yumdownloader --downloadonly clickhouse-server clickhouse-client
root@host116[/var/www/html/files/ckman/clickhouse]# ls -lh
总用量 120K
-rw-r--r-- 1 root root 6.4K 6月 2 2018 clickhouse-client-1.1.54385-2.x86_64.rpm
-rw-r--r-- 1 root root 31K 2月 17 22:51 clickhouse-client-22.2.2.1-2.noarch.rpm
-rw-r--r-- 1 root root 21K 6月 2 2018 clickhouse-server-1.1.54385-2.x86_64.rpm
-rw-r--r-- 1 root root 55K 2月 17 22:51 clickhouse-server-22.2.2.1-2.noarch.rpm
2
3
4
5
6
7
8
# Ckman介绍
ckman,全称是ClickHouse Management Console, 即ClickHouse管理平台。它是由擎创科技数据库团队主导研发的一款用来管理和监控ClickHouse集群的可视化运维工具。目前该工具已在github上开源,开源地址为:github.com/housepower/ckman (opens new window)。
# 为什么要有ckman
我们不妨思考一下这样的场景:如果要部署一个ClickHouse集群,需要怎么做?
首先,我们需要在所有
ClickHouse节点上安装ClickHouse的rpm包,然后,需要修改配置文件,包括但不限于config.xml、users.xml、metrika.xml。注意,是所有节点上都要修改,修改完成后需要依次启动各个节点。当集群规模不大,这些操作手动去完成可能不觉得有什么,但是如果集群规模比较大,单个集群的节点达到了上百台甚至上千台,这时候要手工去每台机器上去操作,显然变得不太现实。
如果需要往集群增加一个节点呢?
我们需要在已有的节点上的
metrika.xml配置文件中加上该节点,然后在新增节点上安装rpm包,修改metrika.xml,启动ClickHouse服务,最后还要同步其他节点上的schema表结构,至此才能完成。删除节点亦如是。
如果要升级集群呢?我们不仅需要在每个节点上重新安装升级
rpm包,还需要考虑一些其他的问题:需不需要停服务?如果升级失败了怎么办?
总之,ClickHouse的集群运维,如果靠人工去做,不仅繁琐,容易出现各种问题,当集群规模变大后,也变得不切实际。
这时候,ckman的出现,就可以完美解决上述的问题。ckman将这些运维操作都集成在管理界面中,用户只需要在web界面上通过简单的信息配置,点击鼠标,就可以完成所有的配置工作,而无需关注其他细节,也减少了出错的可能。
# ckman能做什么
ckman主要的功能是管理和监控ClickHouse集群。因此,它的操作对象只能是ClickHouse集群,而不是单个ClickHouse节点。
# 管理ClickHouse集群
- 部署
ClickHouse集群 - 导入
ClickHouse集群 - 升级
ClickHouse集群 - 增加或删除集群节点
- 对集群(或节点)进行启停
- 实现数据再均衡
# 监控ClickHouse集群
- 监控
ClickHouse Query - 监控节点系统性能指标(
CPU,Memory,IO等) - 监控
Zookeeper相关指标 - 监控集群分布式表相关指标
- 监控副本状态相关指标
- 监控慢
SQL等相关指标
# 源码编译ckman
# 编译依赖
由于ckman使用golang实现,因此需要提前安装go(请使用>=1.17版本);
如果需要编译成rpm包或deb包,需要安装nfpm:
wget -q https://github.com/goreleaser/nfpm/releases/download/v2.15.1/nfpm_2.15.1_Linux_x86_64.tar.gz
tar -xzvf nfpm_2.15.1_Linux_x86_64.tar.gz
cp nfpm /usr/local/bin
2
3
如果有编译前端的需求,需要安装node.js;可使用如下命令安装:
wget -q https://nodejs.org/download/release/v14.15.3/node-v14.15.3-linux-x64.tar.gz
tar -xzf node-v14.15.3-linux-x64.tar.gz -C /usr/local/
ln -s /usr/local/node-v14.15.3-linux-x64/bin/node /usr/local/bin
ln -s /usr/local/node-v14.15.3-linux-x64/bin/npm /usr/local/bin
ln -s /usr/local/node-v14.15.3-linux-x64/bin/yarn /usr/local/bin
2
3
4
5
# 编译命令
# tar.gz包编译
make package VERSION=x.x.x
以上命令会编译成打包成一个tar.gz安装包,该安装包解压即可用。
VERSION是指定的版本号,如果不指定,则默认取git describe --tags --dirty的结果作为版本号。
# rpm包编译
make rpm VERSION=x.x.x
# docker编译
鉴于编译环境的诸多依赖,配置起来可能比较麻烦,因此也提供了docker编译的方式,直接运行下面的命令即可:
make docker-build VERSION=x.x.x
如果想利用docker编译rpm版本,可以先进入docker环境,再编译:
make docker-sh
make rpm VERSION=x.x.x
2
# 前端单独编译
为了减少编译上的麻烦,ckman代码已经将前端代码编译好,做成静态链接放在static/dist目录下,但是仍然将前端代码以submodule的形式嵌入在frontend目录下,如果想要自己编译前端,在提前安装好前端编译依赖后,可以使用如下命令:
cd frontend
yarn
cd ..
make frontend
2
3
4
# 工具部署
prometheus(非必需)node_exporter(非必需)nacos(>1.4)(非必需)zookeeper(>3.6.0, 推荐 )mysql(当持久化策略设置为mysql时必需)
# 架构原理图
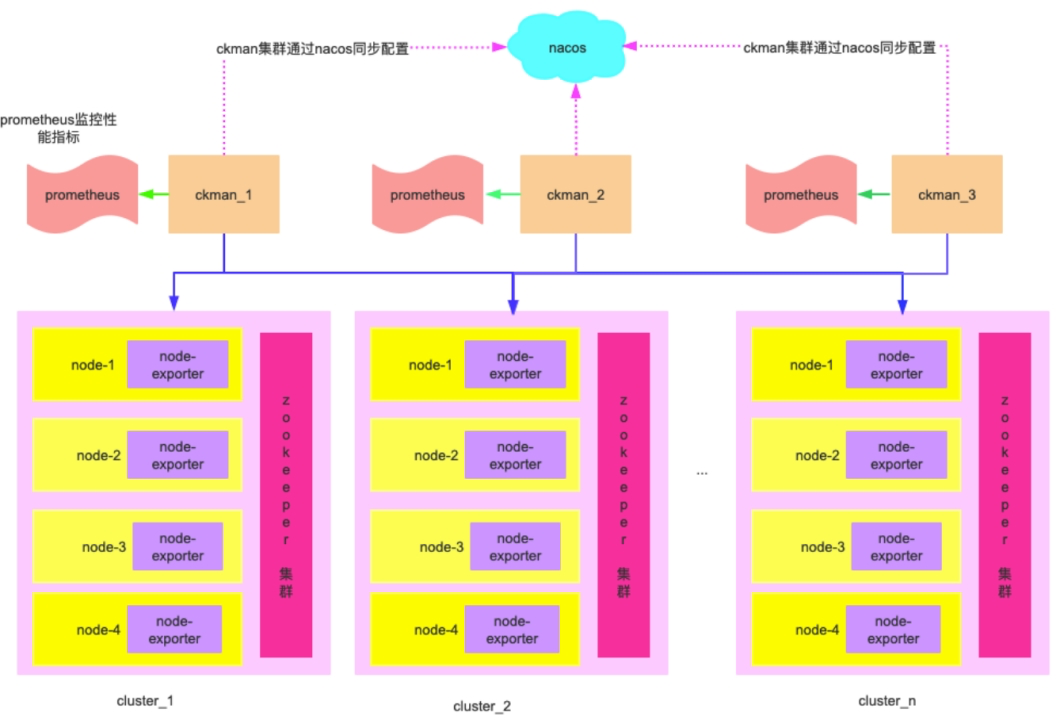
# 监控相关安装及配置
# zookeeper安装及配置
推荐安装3.6.0以上,必须使用3.5以上的版本,需要通过Zookeeper AdminServer的端口获取;
#wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3.tar.gz
#tar zxvf apache-zookeeper-3.6.3.tar.gz && mv apache-zookeeper-3.6.3 zookeeper-3.6.3
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz --no-check-certificate
tar zxvf apache-zookeeper-3.6.3-bin.tar.gz && mv apache-zookeeper-3.6.3-bin zookeeper-3.6.3
cd zookeeper-3.6.3
2
3
4
5
6
zookeeper集群是clickhouse实现分布式集群的重要组件,需要提前搭建好。由于clickhouse数据量极大,避免给zookeeper带来太大的压力,最好给clickhouse单独部署一套集群,不要和其他业务公用。
本文默认zookeeper集群已经搭建完成。我们需要在zk各节点的zoo.cfg配置文件里加上如下配置:
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpPort=7000 #暴露给promethues的监控端口
admin.enableServer=true
admin.serverPort=8086 #暴露给四字命令如mntr等的监控端口,3.5.0以上版本支持
2
3
4
完整部分:
mkdir -p /home/wdp/ckman/zookeeper/data
vi conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/wdp/ckman/zookeeper/data
# the port at which the clients will connect
clientPort=2184
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
metricsProvider.httpPort=7000
metricsProvider.exportJvmInfo=true
admin.enableServer=true
admin.serverPort=8080 #暴露给四字命令如mntr等的监控端口,3.5.0以上版本支持
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
然后依次重启zookeeper各个节点。
sh ./bin/zkServer.sh start
可能报错
# 错误: 找不到或无法加载主类 org.apache.zookeeper.server.quorum.QuorumPeerMain
原因分析:
也即是下载的是未编译的 jar 包。 注:zookeeper 好像从 3.5 版本以后,命名就发生了改变,如果是 apache-zookeeper-3.5.5.tar.gz 这般命名的,都是未编译的,而 apache-zookeeper-3.5.5-bin.tar.gz 这般命名的,才是已编译的包。
解决方案: 重新下载 apache-zookeeper-3.5.5-bin.tar.gz 包,然后解压使用。 非bin解压出来没有lib文件加,需要将bin包解压出来;

# No snapshot found, but there are log entries. Something is broken!
在下载了已编译的 apache-zookeeper-3.5.5-bin.tar.gz 包并解压,且在 conf 文件夹下拷贝并重命名了一份 zoo.cfg 文件后,在启动 bin 目录下的 zkServer.cmd(Windows) 文件时依旧闪退,错误信息如下👇
原因分析:
这个错是在启动zk恢复数据报错的,因为已经安装有 3.4.14 版本,且两个版本的 dirData 地址都没有修改(dataDir=/tmp/zookeeper),是同一个地址,所以数据也是 3.4.14 版本的数据,现在启动 3.5.5 恢复这个数据就报错了
解决方案:
将 3.5.5 版本 conf 文件夹下的 zoo.cfg 文件中的 dataDir 地址修改一下即可。
# clickhouse监控配置
ckman部署的clickhouse集群默认监听了9363端口上报metric给prometheus,因此无需做任何配置。
如果集群是导入的,请确保/etc/clickhouse-server/config.xml中有以下配置内容:
<!-- Serve endpoint for Prometheus monitoring. -->
<!--
endpoint - mertics path (relative to root, statring with "/")
port - port to setup server. If not defined or 0 than http_port used
metrics - send data from table system.metrics
events - send data from table system.events
asynchronous_metrics - send data from table system.asynchronous_metrics
status_info - send data from different component from CH, ex: Dictionaries status
-->
<prometheus>
<endpoint>/metrics</endpoint>
<port>9363</port>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
<status_info>true</status_info>
</prometheus>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# promethus监控工具安装配置
下载程序:https://prometheus.io/download/上传安装包:
- prometheus-2.35.0.linux-amd64.tar.gz
- node_exporter-1.2.2.linux-amd64.tar.gz
# 在管理节点安装监控的prometheus
1.创建用户(所有节点,包括计算节点)
groupadd prometheus
useradd -g prometheus -m -d /var/lib/prometheus -s /sbin/nologin prometheus
2
2.解压安装包:
tar xvf prometheus-2.35.0.linux-amd64.tar.gz -C /usr/local/
cd /usr/local/ && mv prometheus-2.35.0.linux-amd64/ prometheus
2
3.创建service启动脚本:
vi /usr/lib/systemd/system/prometheus.service
添加如下内容:
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/var/lib/prometheus --storage.tsdb.retention=15d --log.level=info
Restart=on-failure
[Install]
WantedBy=multi-user.target
2
3
4
5
6
7
8
9
10
11
12
# 在计算节点安装node_exporter
node_exporter是用来监控clickhouse节点所在机器的一些系统指标的一款工具,因此需要安装在ck节点所在的机器,默认监听9100端口。
tar xvf node_exporter-1.3.1.linux-amd64.tar.gz -C /usr/local/
cd /usr/local/ && mv node_exporter-1.3.1.linux-amd64/ node_exporter
chown -R prometheus.prometheus node_exporter/
2
3
4
创建启动脚本
vi /usr/lib/systemd/system/node_exporter.service
添加如下内容:
[Unit]
Description=node_export
Documentation=https://github.com/prometheus/node_exporter
After=network.target
[Service]
Type=simple
User=prometheus
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
2
3
4
5
6
7
8
9
10
11
12
13
启动node_exporter
systemctl enable node_exporter.service
systemctl start node_exporter.service
systemctl status node_exporter.service
ss -tnl | grep 9100
2
3
4
# 配置Prometheus添加监控目标
vi /usr/local/prometheus/prometheus.yml
# cat /usr/local/prometheus/prometheus.yml
2
配置以下信息:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
参考
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090','localhost:9100'] # 对本机node_exporter 监控
# 新添加的对其它node节点抓取数据
- job_name: '111.4'
#重写了全局抓取间隔时间,由15秒重写成5秒。
scrape_interval: 5s
static_configs:
- targets: ['host120:9100','host121:9100']
2
3
4
5
6
7
8
9
10
11
12
13
14
集群其他参考配置:
- job_name: 'node_exporter'
scrape_interval: 10s
static_configs:
- targets: ['192.168.0.1:9100', '192.168.0.2:9100', '192.168.0.3:9100', '192.168.0.4:9100']
- job_name: 'clickhouse'
scrape_interval: 10s
static_configs:
- targets: ['192.168.0.1:9363', '192.168.0.2:9363', '192.168.0.3:9363', '192.168.0.4:9363']
- job_name: 'zookeeper'
scrape_interval: 10s
static_configs:
- targets: ['192.168.0.1:7070', '192.168.0.2:7070', '192.168.0.3:7070']
2
3
4
5
6
7
8
9
10
11
12
13
14
# 启动Prometheus服务
chown -R prometheus.prometheus prometheus
systemctl enable prometheus.service
systemctl start prometheus.service
systemctl status prometheus.service
2
3
4
5
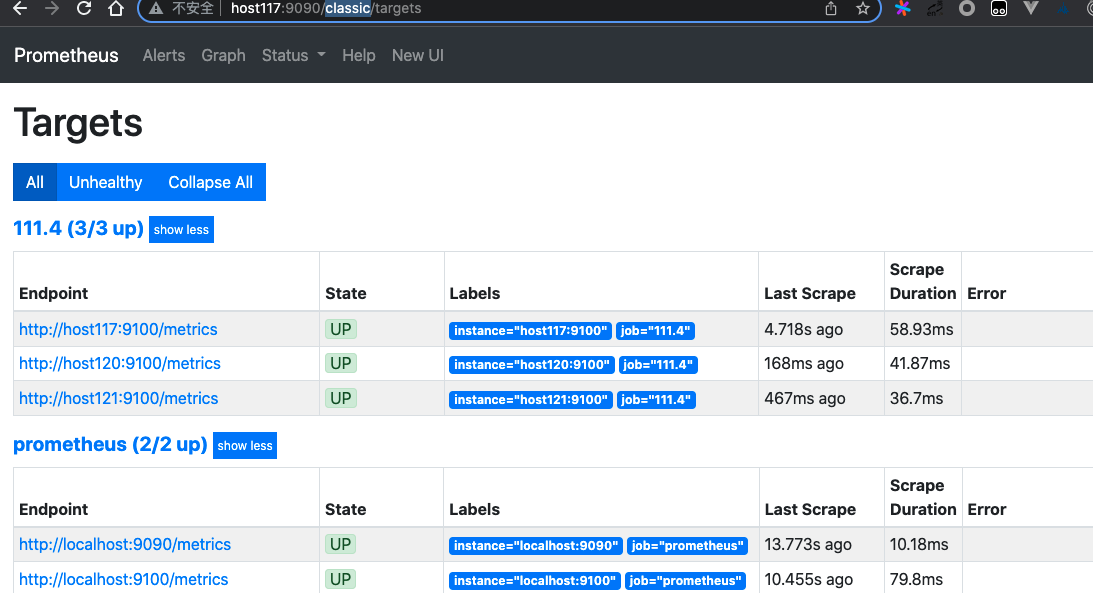
访问页面:
访问 Prometheus WEB 查看我们定义的目标主机:http://host117:9090/targets 或者http://host117:9090/classic/targets
# 安装ckman
# tar.gz安装启动
安装
可以在任意目录进行安装。安装方式为直接解压安装包即可。
tar -xzvf ckman-1.3.1-210428.Linux.x86_64.tar.gz
启动
进入ckman的工作目录,执行:
cd ckman
bin/start
2
# rpm安装启动
下载安装包,并且解压;最新安装包地址:https://github.com/housepower/ckman/releases
#安装启动方式一
wget https://github.com/housepower/ckman/releases/download/v2.2.5/ckman-2.2.5.x86_64.rpm
rpm -ivh ckman-2.2.5.x86_64.rpm
#安装完成后,在/etc/ckman目录下,会生成工作目录(日志和配置文件等都在该目录下)。
#rpm方式安装的ckman有两种启动方式:
#方式一:
/usr/local/bin/ckman -c=/etc/ckman/conf/ckman.yaml -p=/run/ckman/ckman.pid -l=/var/log/ckman/ckman.log -d
#方式二:[推荐]
systemctl start ckman
systemctl status ckman
#安装启动方式二 【推荐】
wget https://github.com/housepower/ckman/releases/download/v2.2.5/ckman-v2.2.5-220602.Linux.amd64.tar.gz
tar -xzvf ckman-v2.2.5-220602.Linux.amd64.tar.gz
cd ckman && bin/start
2
3
4
5
6
7
8
9
10
11
12
13
14
15
启动之后,在浏览器输入 http://localhost:8808 (opens new window) 跳出如下界面,说明启动成功:
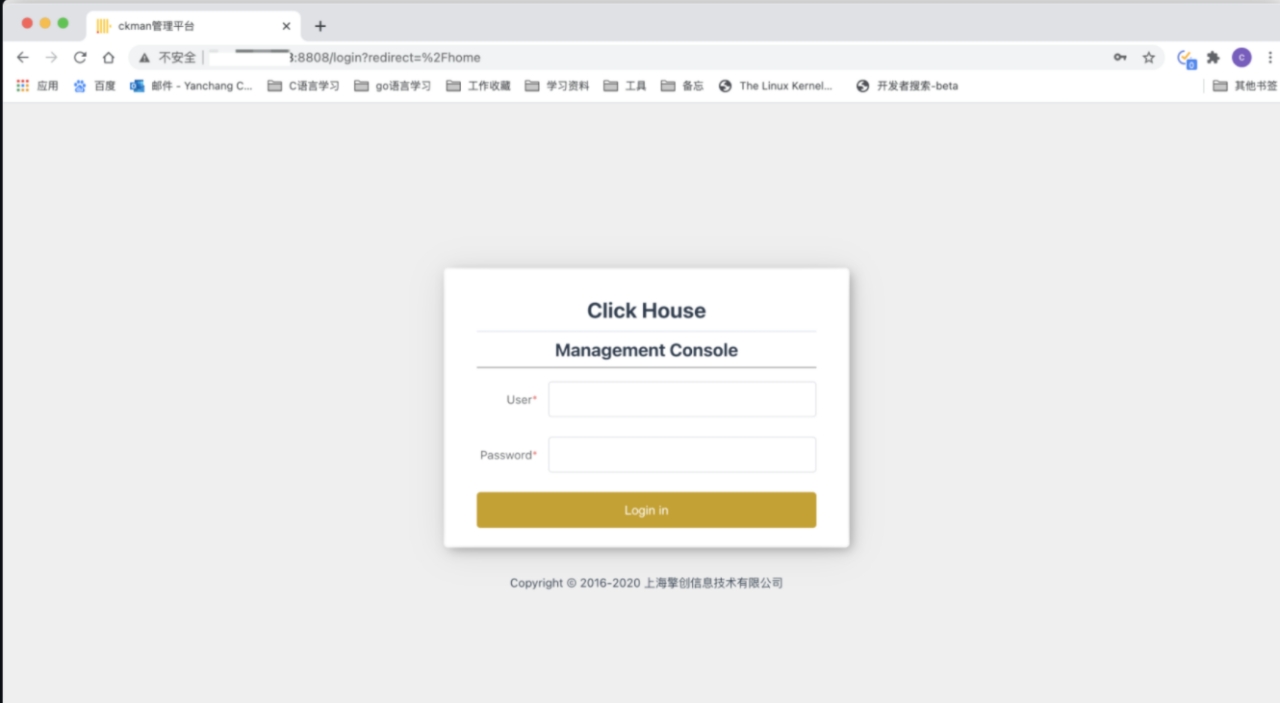
ckman默认的登录用户为ckman,密码为Ckmanx x x。
# docker安装启动
从v1.2.7版本开始,ckman支持从docker镜像启动。启动命令如下所示:
docker run -itd -p 8808:8808 --restart unless-stopped --name ckman quay.io/housepower/ckman:latest
但是需要注意的是,搭建promethues和nacos并不属于ckman程序自身的范畴,因此,从容器启动ckman默认是关闭nacos的,且前台Overview监控不会正常显示。
如果想自己配置nacos和prometheus,可以进入容器自行配置。
# 升级ckman
ckman支持rpm安装和tar.gz安装,所以升级也针对这两种安装方式做了区分。
# rpm升级
从github上下载最新版的ckman安装包 (opens new window)。 停止ckman服务:
systemctl stop ckman
#yum remove -y ckman
#几个常用的目录
/etc/ckman
/etc/clickhouse-server
2
3
4
5
6
7
升级rpm包:
rpm -Uvh ckman-x.x.x-x86_64.rpm
注意rpm升级配置文件仍然会使用旧版本的,默认的配置文件会重命名为ckman.yaml.rpmnew(password文件同理)。
重新启动ckman:
systemctl daemon-reload
systemctl start ckman
2
# tar.gz升级
从github上下载最新版的ckman安装包 (opens new window)。 进入到当前版本ckman的工作目录,停止ckman服务:
wget https://github.com/housepower/ckman/releases/download/v2.2.5/ckman-v2.2.5-220602.Linux.amd64.tar.gz
tar -xzvf ckman-v2.2.5-220602.Linux.amd64.tar.gz
#cd ckman && bin/start
bin/stop
2
3
4
5
备份配置文件:
cp conf/ckman.yaml conf/ckman.yaml.last
cp conf/password conf/password.last
2
解压最新下载的安装包覆盖掉旧版本的安装目录:
tar -xzvf ckman-x.x.x-YYDDMM.Linux.x86_64.tar.gz -C ${WORKDIR}
替换配置文件:
cp conf/ckman.yaml.last conf/ckman.yaml
cp conf/password.last conf/password
2
重新启动ckman服务:
bin/start
需要注意的是,由于tar.gz安装方式可以自行指定工作目录,如果新版本安装位置与旧版本不同,需要将conf目录下的clusters.json拷贝到新版本的工作目录下,否则无法加载集群信息。
# 卸载重装
卸载之前用yaml安装的,改用源码目前最新版本安装方式;
yum remove -y ckman
#wget https://github.com/housepower/ckman/releases/download/v2.2.5/ckman-v2.2.5-220602.Linux.amd64.tar.gz
tar -xzvf ckman-v2.2.5-220602.Linux.amd64.tar.gz
cp conf/ckman.yaml.last conf/ckman.yaml
cp conf/password.last conf/password
cd ckman && sh bin/start
2
3
4
5
6
7
8
9
# 功能介绍
# 管理创建集群
根据界面提示很容易创建集群,大致步骤如下:
- 1)上传clickhouse安装rpm包
- 2)配置监控地址和zookeeper地址
- 3)设置clickhouse实例数据目录
- 4)配置clickhouse实例主机
- 5)创建用户
- 6)创建集群
ckman部署的clickhouse集群默认监听了9363端口上报metric给prometheus,因此无需做任何配置。
如果集群是导入的,请确保/etc/clickhouse-server/config.xml中有以下配置内容:
<!-- Serve endpoint for Prometheus monitoring. -->
<!--
endpoint - mertics path (relative to root, statring with "/")
port - port to setup server. If not defined or 0 than http_port used
metrics - send data from table system.metrics
events - send data from table system.events
asynchronous_metrics - send data from table system.asynchronous_metrics
status_info - send data from different component from CH, ex: Dictionaries status
-->
<prometheus>
<endpoint>/metrics</endpoint>
<port>9363</port>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
<status_info>true</status_info>
</prometheus>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 安装包管理
在主页上点击设置按钮,进入如下的页面:
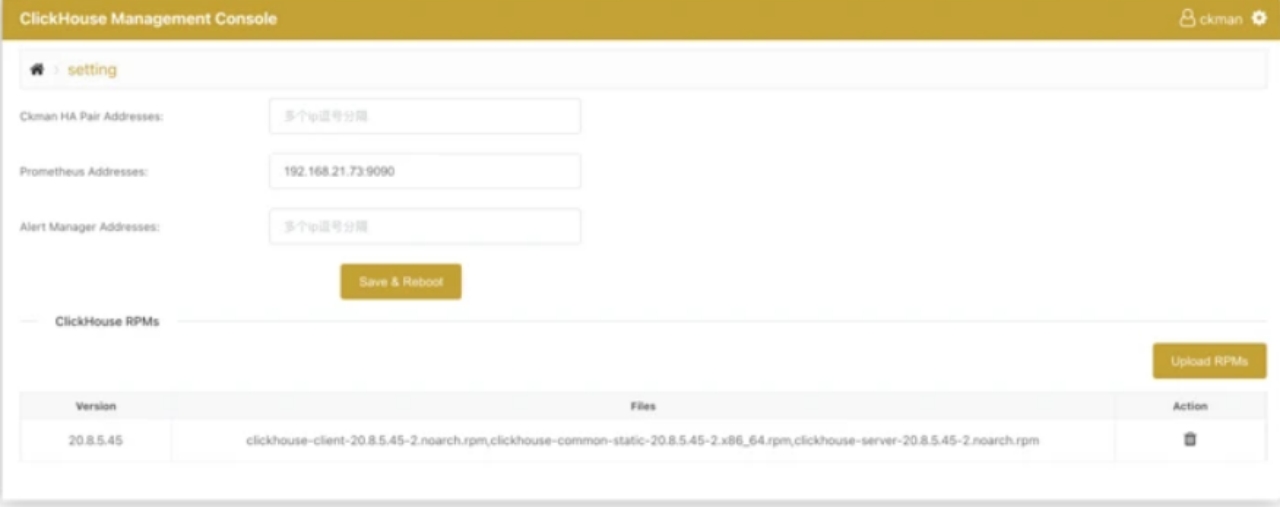
点击Upload RPMs,出现如下界面。

注意安装包上传时需要三个安装包都上传(server、client、common),上传成功后,在安装包列表下会显示新上传的记录:

| 21.8.3.44 | clickhouse-client-21.8.3.44-2.noarch.rpm,clickhouse-common-static-21.8.3.44-2.x86_64.rpm,clickhouse-server-21.8.3.44-2.noarch.rpm |
|---|
# 创建集群【要点】
点击主页的 Create a ClickHouse Cluster,就会进入创建集群的界面:

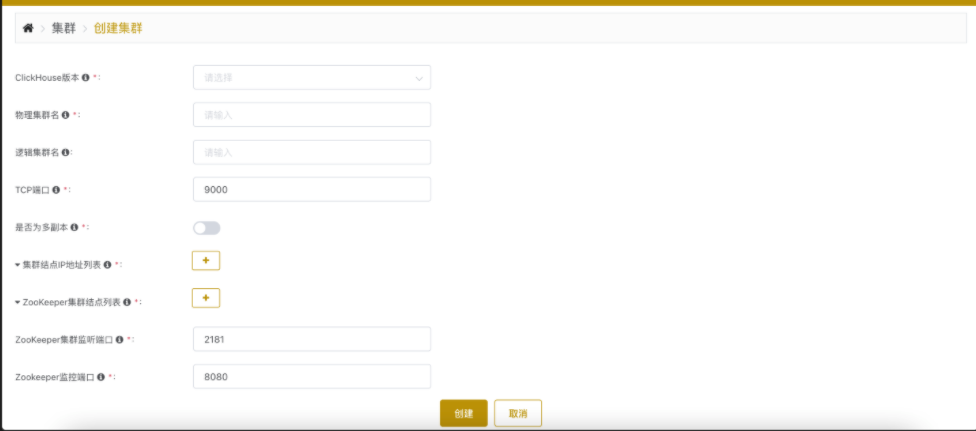
需要填写的项主要有以下:
ClickHouse Version: ck的版本,不需要自己填写,通过下拉列表选择,下拉列表中会列出ckman服务器中所有的安装包版本。
此处版本信息只会列出当前
ckman服务下的安装包版本,如果配置了多中心,其他ckman的安装包是无法看见的Cluster Name: 集群的名字,注意不要和已有的名字重合
ClickHouse TCP Port: clickhouse的TCP端口,默认是9000,当然也可以自己指定;
ClickHouse Node List: clickhouse节点列表,以逗号分隔
Replica: 是否开启副本,默认是关闭
如果开启了副本,默认是1个
shard一个副本,所以节点数量一定要是偶数,否则会报错如果要增加节点的副本数,可通过增加节点完成,创建集群时最多只能指定一个副本
如果没有开启副本,则有几个节点就有几个
shardZookeeper Node List: zk列表
ZooKeeper Port: zk端口,默认是2181
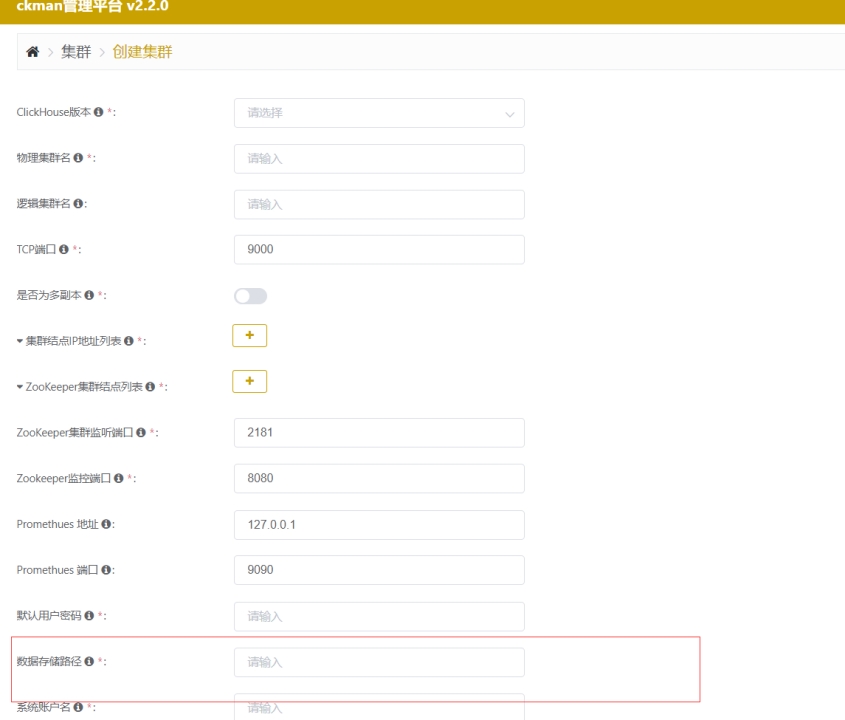
Data path: ck节点数据存放的路径; 要点路径目录;比如:
/ckdata1/Cluster Username: ck的用户名
Cluster Password: ck的密码
SSH Username: ssh登录ck节点的用户名
该用户必须具有
root权限或是root本身,否则部署无法成功,一般都是root。SSH Password: ssh登录ck节点的密码
通过此种方式安装部署成功的集群的mode就是deploy,可以对其进行删、改、rebanlance、启停、升级以及节点的增删等操作;【一定要检查各个端口是否正确;】目前在host116上面,设置的都是6相关端口;
需要注意的是:当前版本的ckman仅支持在centos7以上的系统部署ck。
检查端口及进程命令:
lsof -i tcp:9006
lsof -i tcp:2186
#zookeeper
lsof -i tcp:8086
ps -ef |grep zookeeper
2
3
4
5
6
目前的环境有:
- http://host116:9090/targets
- http://host116:8808/
# 导入集群
点击主页的 Import a ClickHouse Cluster按钮,会进去导入集群界面。
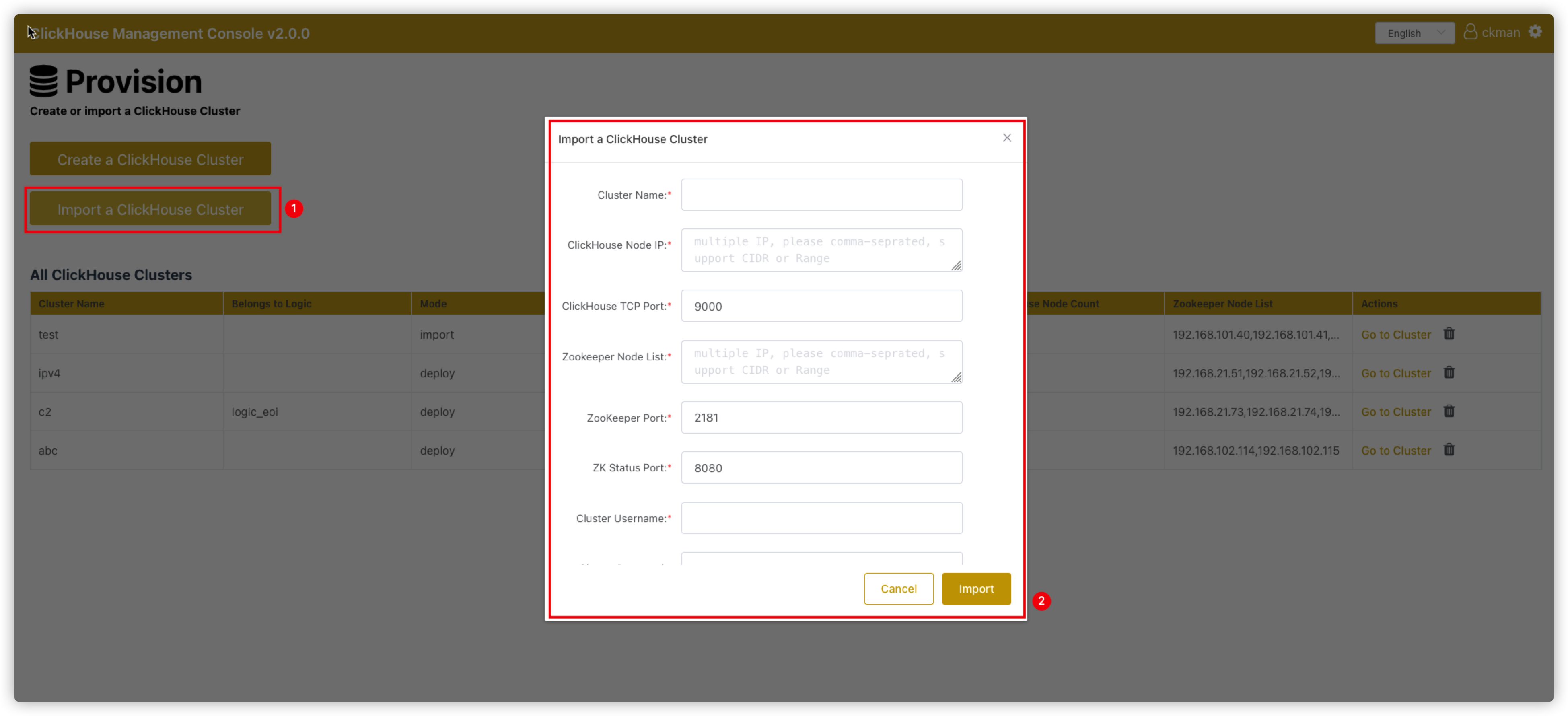
需要填写的信息如下所示:
Cluster Name: 节点名称,该名称必须是确实存在的集群名,且不能与ckman中已有的集群名字重复。ClickHouse Node IP:clickhouse节点ip列表,以逗号分隔ClickHouse TCP Port:ck节点TCP端口,默认为9000Zookeeper Node List:zk节点列表ZooKeeper Port:zk端口,默认为2181ZK Status Port:zookeeper指标监控的端口,默认8080Cluster Username:ck的用户名Cluster Password:ck的密码,非必输
导入集群有个前提是该集群必须确实存在,否则导入会出现问题。
导入的集群的mode为import,这种模式的集群不能进行修改、rebalance、启停、升级以及节点的增删等操作,但是可以删除和查看。
# 升级集群
如果上传了新版本的安装包,可以从Upgrade Cluster下拉列表中选择新版本,点击Upgrade即可进行升级。
目前支持全量升级和滚动升级两种策略。并让用户选择是否检查相同版本。
升级界面如下:

# 销毁集群
集群销毁后,该集群在物理上都不存在了。因为销毁集群动作不止会停止掉当前集群,还会将节点上的ClickHouse卸载,相关目录清空,所以该动作应该慎重操作。
# 增加节点
点击Manage页面的Add Node按钮以增加节点。
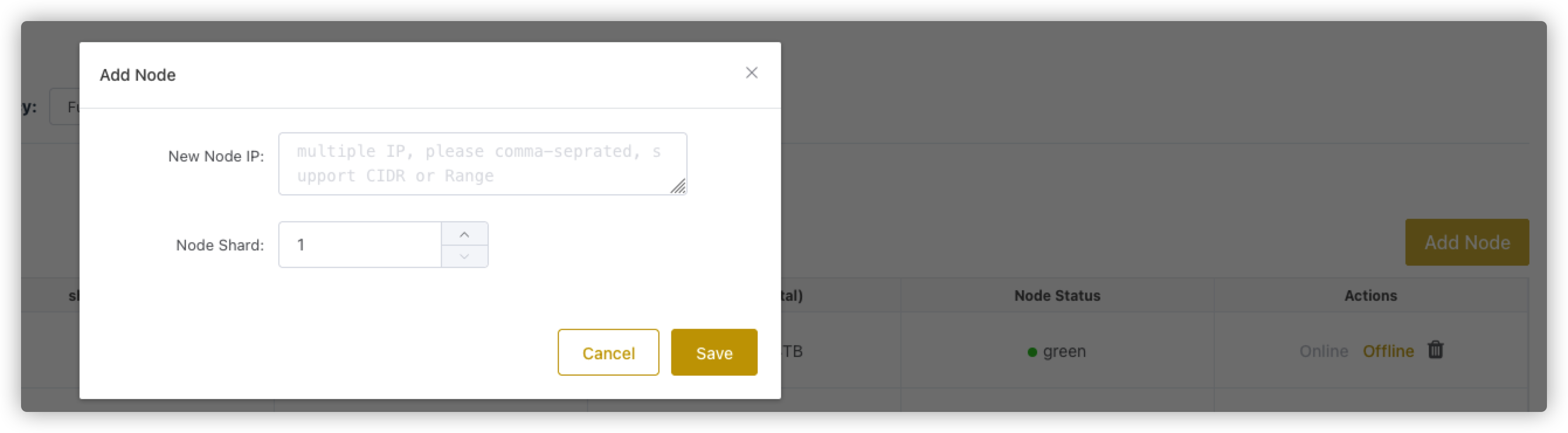
增加节点需要填写:
New Node IP: 新节点的IP,可以一次性增加多个节点,这些节点将会位于同一个shard上。Node Shard: 节点的Shard NUmber。- 如果填写的
shard是已经存在的,那么增加的节点会作为已存在shard的一个副本;如果shard不存在(一般是最大的shard编号+1,如果不是就不正确了),就会新增加一个shard。- 如果集群不支持副本模式,则每个
shard只能有一个节点,不可以给已有shard添加副本节点,如果集群支持副本模式,则可以在任意shard增加节点。
# 删除节点
删除节点时需要注意的是:删除节点并不会销毁该节点,只会停止该节点的clickhouse服务,并从clusters.json中删除掉。
删除节点时,如果某个shard有且只有一个节点,那么这个节点一般是不可以被删除的,除非该节点处于shard编号的最大位置。
# 监控管理
ckman提供了ClickHouse相关的一些指标监控项。这些监控项依赖于从prometheus中获取数据,因此,需要提前配置好prometheus。相关配置教程见ckman部署文档。
# ClickHouse Database KPIs
| 指标 | 说明 |
|---|---|
clickhouse.Query | 针对Clickhouse集群的分布式表发起的查询,按照发起时刻的分布图 |
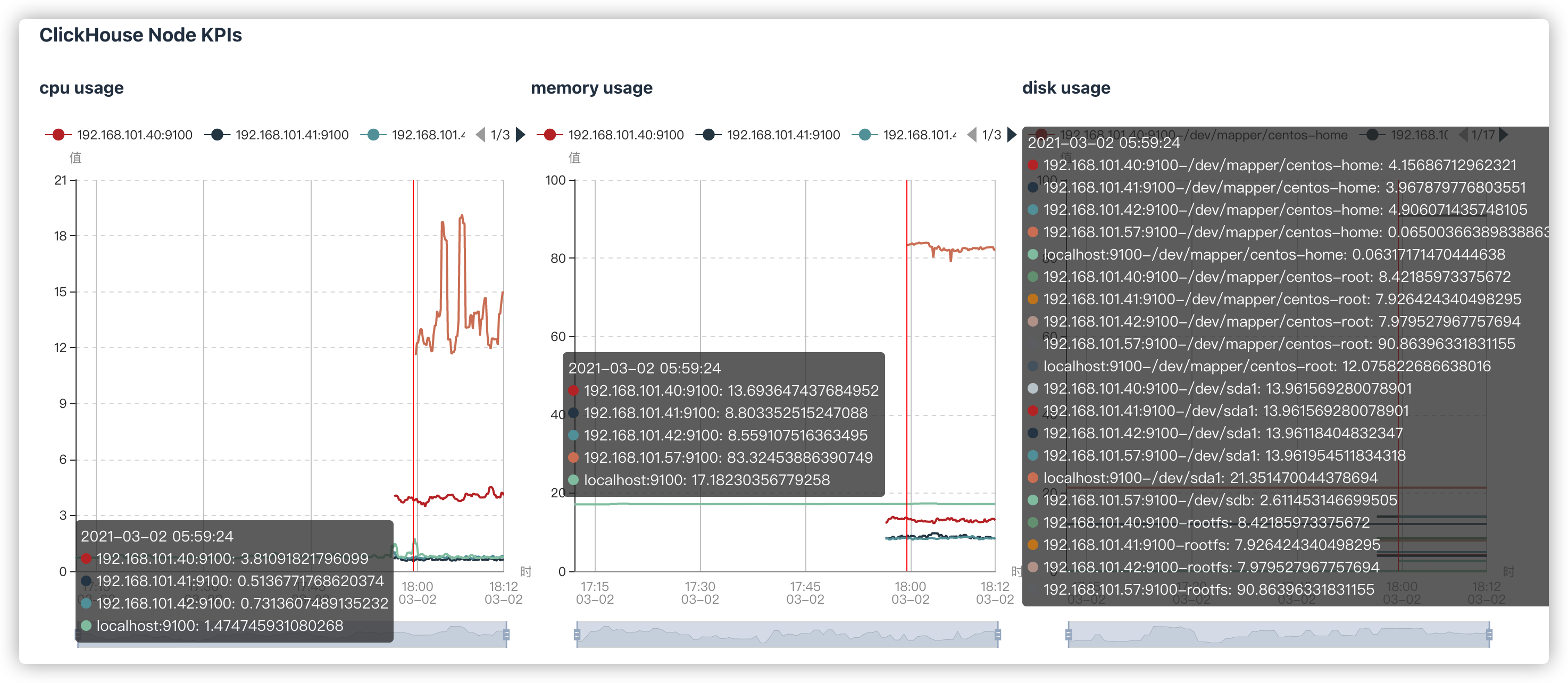
# ClickHouse Node KPIs
| 指标 | 说明 |
|---|---|
cpu usage | CPU占用情况 |
memory usage | 内存占用情况 |
disk usage | 硬盘占用情况 |
IOPS | IO指标 |
# ZooKeeper KPIs
| 指标 | 说明 |
|---|---|
znode_count | znode数 |
leader_uptime | leader存活时间 |
stale_sessions_expired | 过期的会话 |
jvm_gc_collection_seconds_count | jvm gc的次数 |
jvm_gc_collection_seconds_sum | jvm gc花费的时间 |
# 表&会话管理
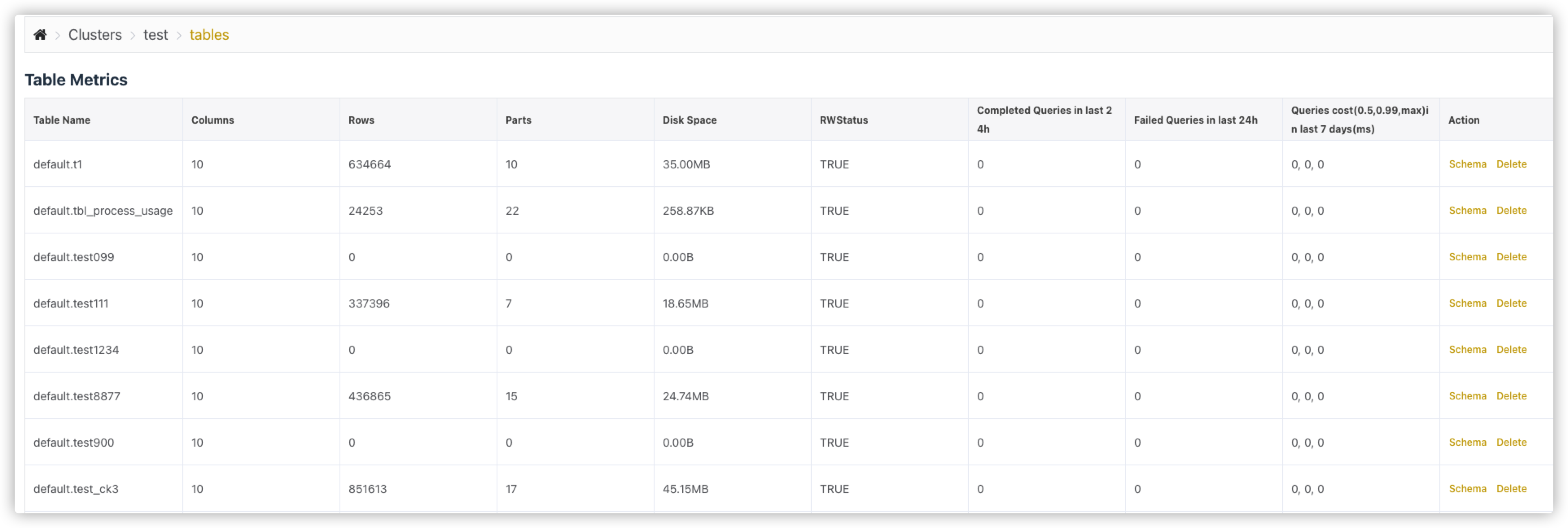
# Table Metrics
统计表的一些指标。除system数据库的表之外,其他数据库的表都会显示在下面。
指标包括:
Table Name表名Columns列数Rows行数Partitions当前所有未合并的分区数Parts Count分区数Disk Space(uncompress)使用磁盘(未压缩)Disk Space(compress)使用磁盘(压缩),该大小是最终数据落盘的占用空间RWStatus读写状态,TRUE代表可读写,FALSE代表不可读写Completed Queries in last 24h过去24小时成功的SQL条数Failed Queries in last 24h过去24小时失败的SQL条数Queries cost(0.5, 0.99, max) in last 7days(ms)过去7天SQL花费的时间。Queries Cost有三个值:0.5:过去7天50% SQL的平均耗时0.99:过去7天99% SQL的平均耗时max:过去7天SQL最大耗时
# Table Replication Status
统计复制表的一些状态。
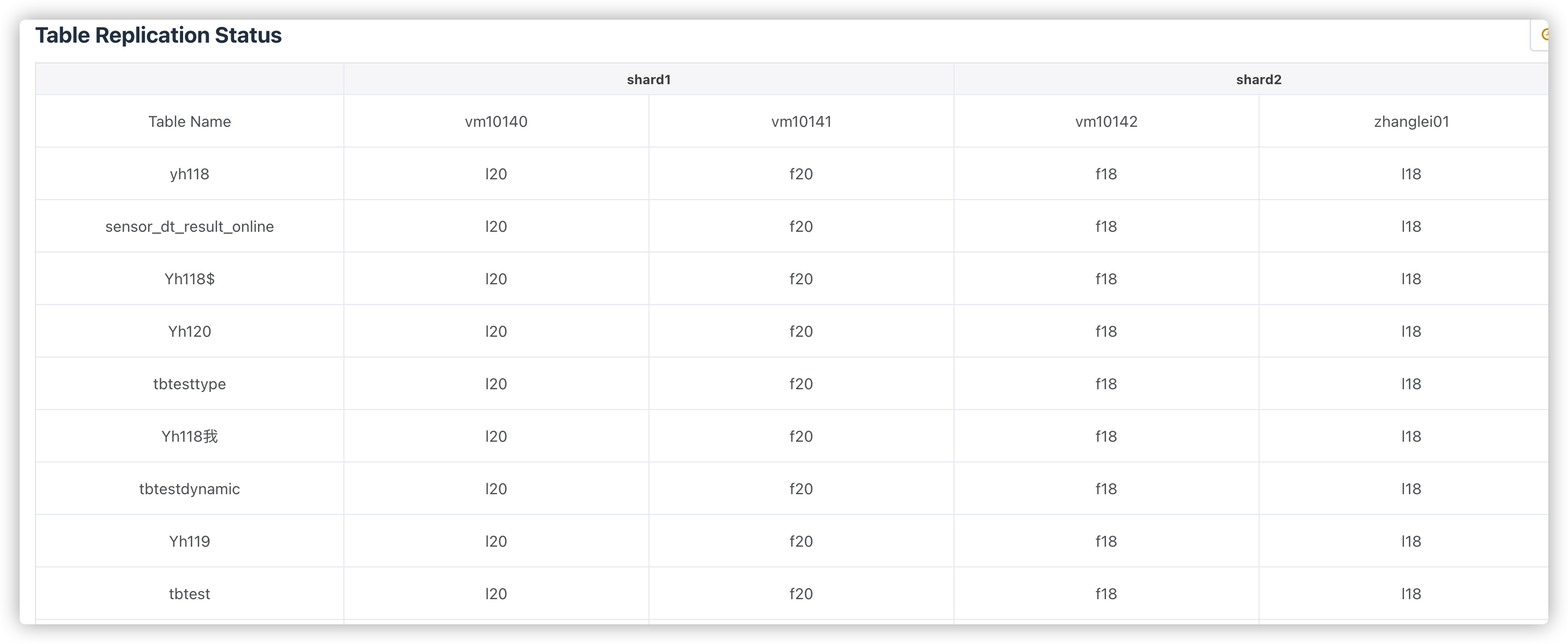
此处会统计每个shard下每张表的各副本之间的统计量。
理论上每个shard内副本之间各表的统计都应该相等的,如果有不相等,就说明有节点落后了,这时候落后的节点会标黄。如果某个副本上所有的表都落后,说明这个副本可能出问题了。
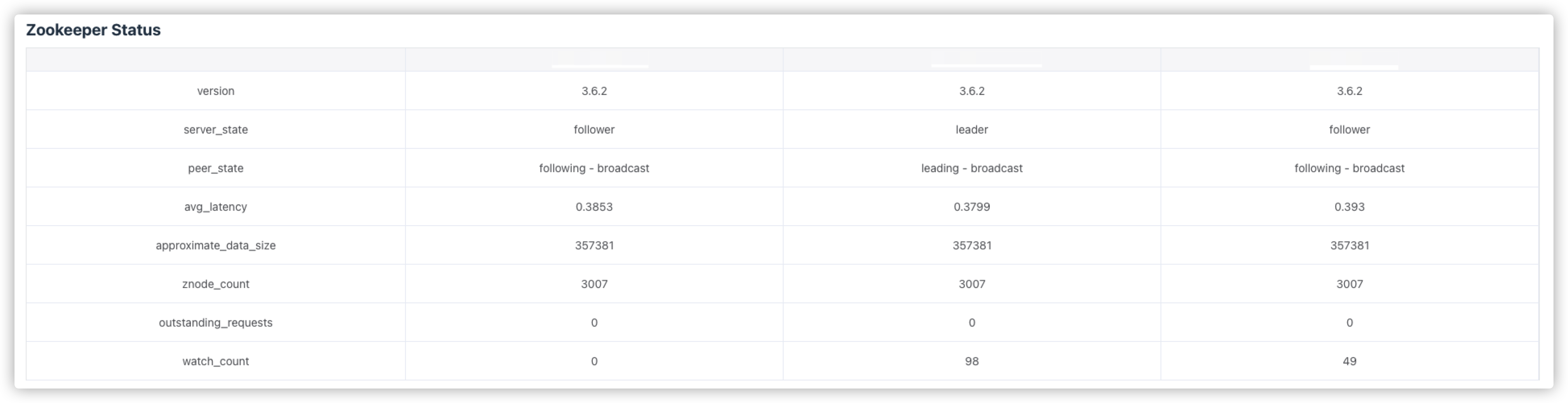
# Zookeeper Status
zookeeper的相关指标查看。zookeeper监控使用的是zookeeper-3.5.0版本新增的特性,通过暴露的8080端口监控mntr指标信息,因此,如果想要看到zookeeper的监控指标,需要保证当前使用的zookeeper版本大于等于3.5.0。
可查看的指标包括:版本,主从状态,平均延迟,近似数据总和大小,znode数等。
# Open Sessions
显示当前正在进行的会话。

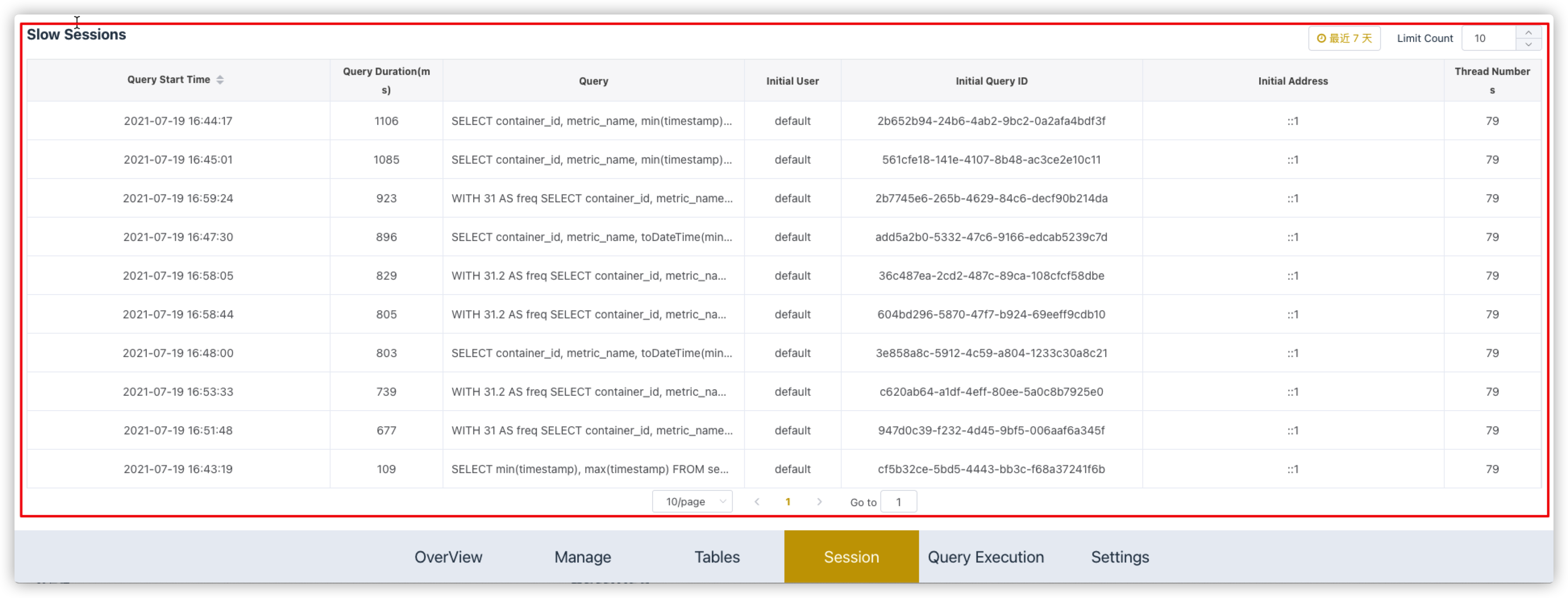
# Slow Sessions
显示7天内最慢的10条SQL语句。
包含SQL的执行时间、SQL耗时、SQL语句、ck用户、query id、查询的IP以及线程号。
# Query查询管理
ckman还提供了简单的clickhouse查询的页面。通过该页面可以查询集群中的数据。
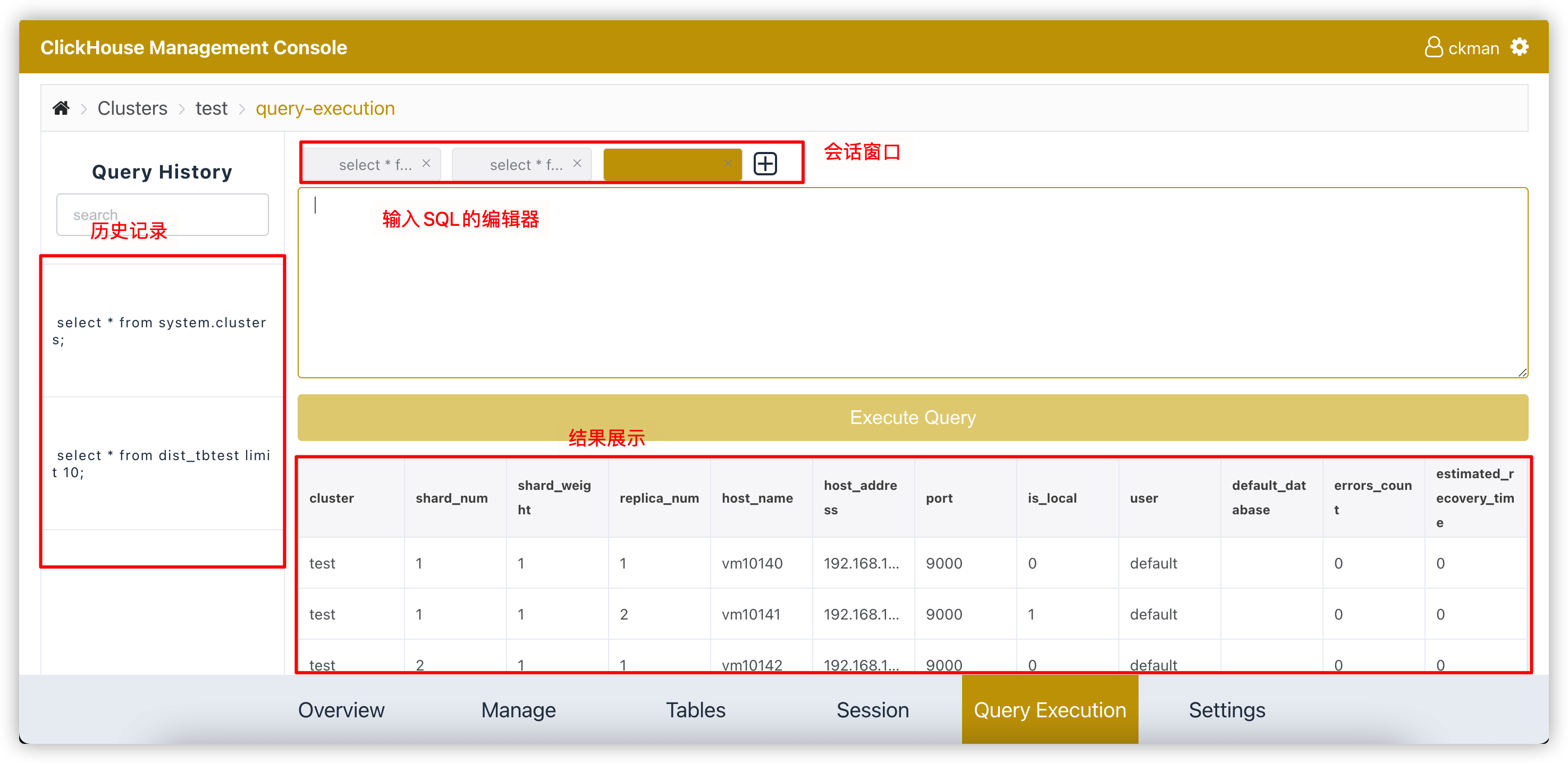
注意:
该工具只能查询,不能进行
mutation的相关操作。该工具主要针对分布式表,本地表也能查,但是如果本地表在集群的其他节点不存在,就会报错。即使表在所有节点都存在,查询出来的数据也是某个节点的数据,因此每次查询出来的数据可能不一致。
# 配置管理
通过集群配置管理页面,可以修改集群的配置,注意对存储策略的配置的修改,如果已有的存储介质上已有数据,则该存储介质不可删除。
ckman会根据修改的集群配置的具体内容来决定集群是否需要重启。
# 配置磁盘策略
参考:https://cloud.tencent.com/developer/article/1649377
Clickhouse对多硬盘的配置是通过Policy实现的,架构图如下:
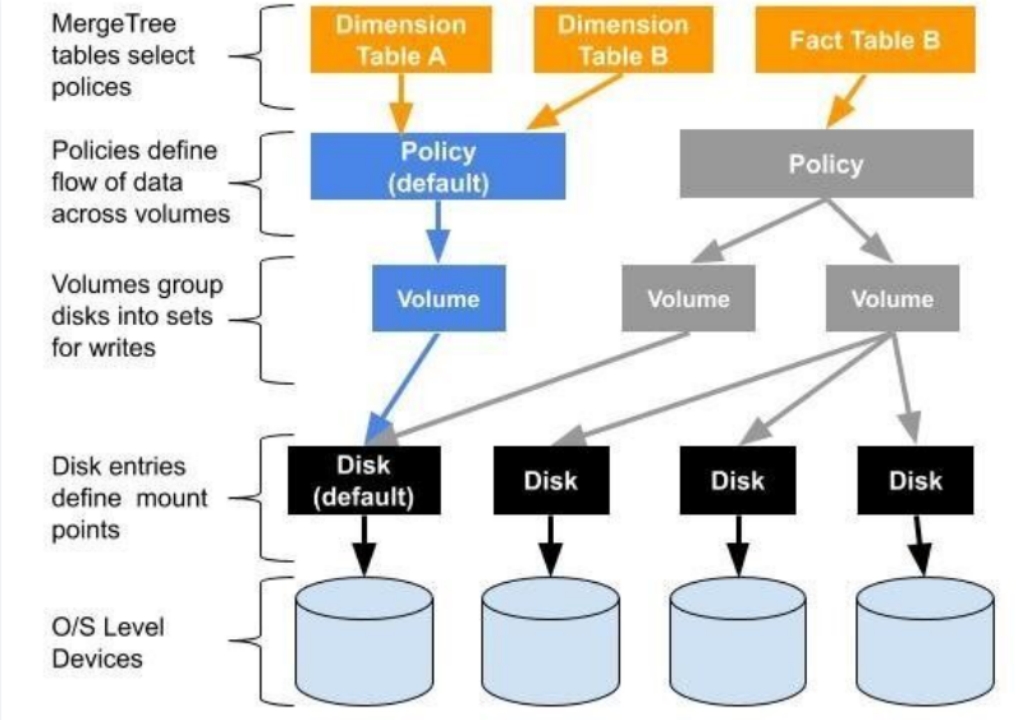
可以看到,对于具体某个表,选择不同的Policy,会决定最终的数据的存储方式。对于数据的存储,到具体的磁盘位置,是需要经过Policy,Volume两层的逻辑关系
Policy可以对接两个Volume,Volume可以对接多个磁盘。简单来说,两个Volume可以实现数据的冷热存储,一个Volume对接多个磁盘,实现数据的分散存储,充分利用多个磁盘的并行处理能力。注意Volume是在Policy里面定义的,所以一个Volume只能对应一个policy
默认的策列defalut,所有表的元数据,是存储在集群创建时候选择的存储路径中,建议这里使用SSD高速磁盘
策列和存储卷可以在这里进行配置:

定义磁盘:
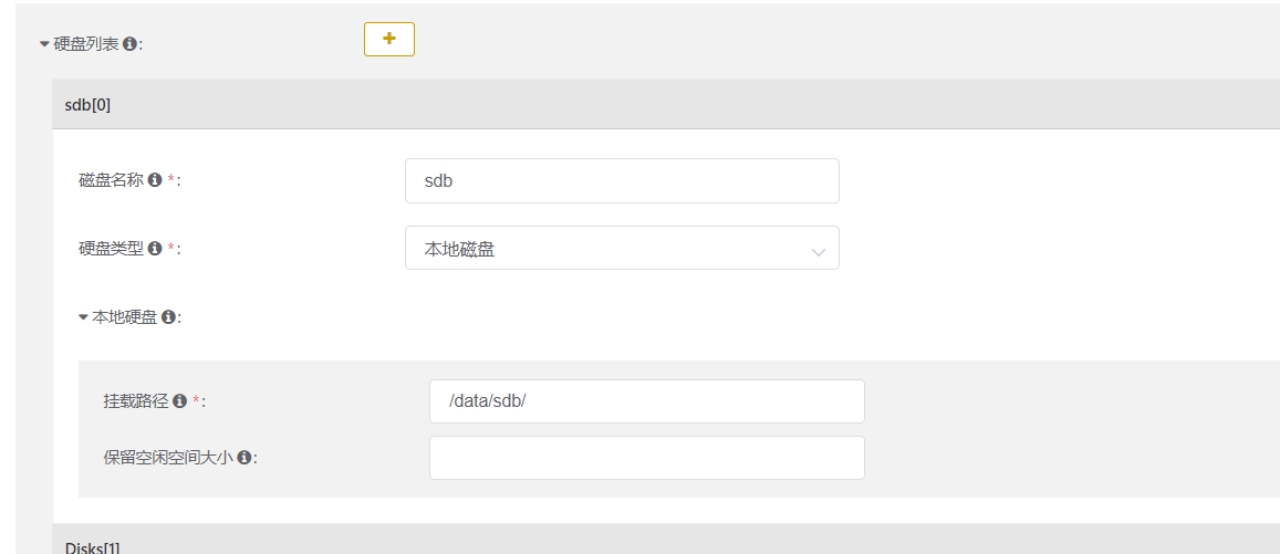
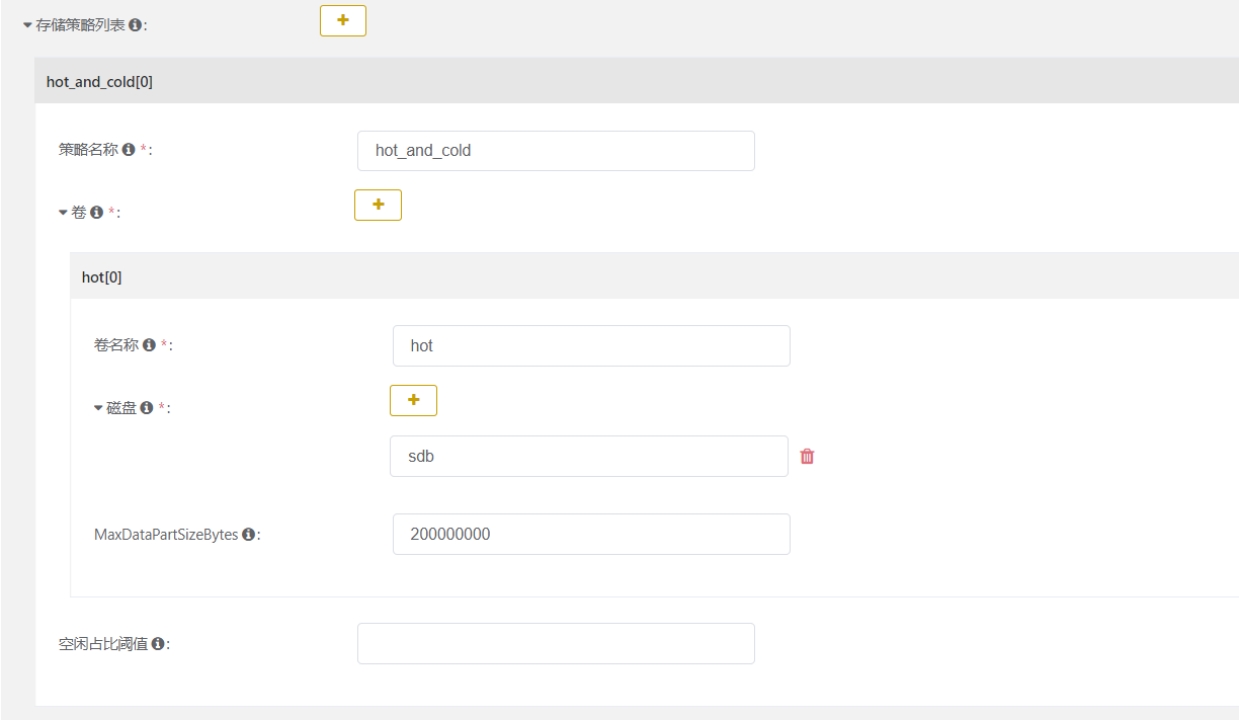
定义policy:
<sdc_sdd_jbod> > <!-- name for new storage policy -->
<volumes>
<sdc_sdd_jbod_volume> <!-- name of volume -->
<!--
the order of listing disks inside
volume defines round-robin sequence
-->
<disk>sdc</disk>
<disk>sdd</disk>
</sdc_sdd_jbod_volume>
</volumes>
</sdc_sdd_jbod>
2
3
4
5
6
7
8
9
10
11
12
实现冷热数据的处理,比如热数据在SSD,冷的数据在普通磁盘
有个重要的参数: max_data_part_size,这个在ckman里面也是可以配置的
注意卷的先后循序很重要,数据是先放在第一个卷里面的
当数据超过阈值,被合并后,合并的结果就会放到第二个卷里面,也就是冷卷
用法:
建表的时候设置 storage_policy
CREATE TABLE sample3 (id UInt64) Engine=MergeTree ORDER BY id SETTINGS storage_policy = 'sdc_sdd_jbod';
# 如何进行监控
# 运维操作语句
查看磁盘空间:
SELECT
name,
path,
formatReadableSize(free_space) AS free,
formatReadableSize(total_space) AS total,
formatReadableSize(keep_free_space) AS reserved
FROM system.disks
2
3
4
5
6
7
# 配置文件说明
# server
idckman集群id,同一个集群的ckman的id号配置必须不同
portckman的监听端口- 默认为
8808
https- 是否监听
https - 默认为
false
- 是否监听
certfilehttps的证书文件,如果开启了https- 默认使用
conf下的server.crt
keyfilehttps的key文件,如果开启了https- 默认使用
conf下的server.key
pprof- 是否支持
pprof监控 - 默认为
true
- 是否支持
session_timeout- 会话超时时间,如果超过该时间没有对
ckman进行任何操作,则token失效,需要重新登录 - 默认超时时间为
3600秒
- 会话超时时间,如果超过该时间没有对
public_key- 用来接入
ckman的公钥 ckman可通过RSA配置公钥的方式跳过token鉴权,只需要在客户端对header配置userToken,并对userToken使用私钥加密,然后在ckman服务端使用该公钥进行解密即可。
- 用来接入
swagger_enable- 是否开启
swagger文档 - 默认不开启
- 是否开启
task_interval- 执行异步运维动作的扫描时间间隔
- 前端请求部署、升级、销毁以及增删节点等比较耗时的操作时,
ckman先记录状态,然后使用另外的协程异步扫描处理,异步扫描的时间间隔通过该参数可配,默认为5秒
persistant_policy- 持久化策略,主要用来存储集群的配置信息,包括集群配置、逻辑集群映射关系 、查询语句历史记录、运维操作状态等。
- 持久化策略支持
local、mysql和postgreslocal:存储到本地,在conf目录下生成一个clusters.json文件,不支持集群,为默认配置mysql:持久化到mysql,支持ckman集群,支持HA,需要提前创建数据库,数据库编码为UTF-8,不需要创建表,ckman会自动创建数据库表postgres:持久化到postgres,支持ckman集群,支持HA,需要提前创建数据库,并且需要提前创建数据库表。建表语句内置在dbscript/postgres.sql中。- 除
local策略外,其他持久化策略都依赖persistent_config中的配置项,当然local也可以配置该项。
示例如下:
server:
id: 1
port: 8808
https: false
#certfile:
#keyfile:
pprof: true
swagger_enable: true
session_timeout: 3600
# support local, mysql, postgres
persistent_policy: local
task_interval: 5
#public_key:
2
3
4
5
6
7
8
9
10
11
12
13
# log
level- 日志打印级别
- 默认为
INFO - 支持
DEBUG、INFO、WARN、ERROR、PANIC、FATAL
max_count- 滚动日志数量
- 默认为
5个
max_age- 日志生命有效期
- 默认为
10天
示例如下:
log:
level: INFO
max_count: 5
# megabyte
max_size: 10
# day
max_age: 10
2
3
4
5
6
7
# persistent_config
# mysql & postgres
mysql和postgres配置项基本一致,主要涉及以下配置项:
host- 连接数据库的ip地址
port- 连接数据库的端口号,如
mysql默认为3306,postgres默认为5432
- 连接数据库的端口号,如
user- 连接数据库的用户
password- 连接数据库的密码,需要加密,可使用下面命令获得密码的密文
ckman --encrypt 123456 E310E892E56801CED9ED98AA177F18E61
2database- 需要连接的数据库,需提前创建,并且保证编码为
UTF-8
- 需要连接的数据库,需提前创建,并且保证编码为
# local
format- 本地文件格式,支持
JSON和yaml,默认为json
- 本地文件格式,支持
config_dir- 本地文件的目录,需要填写路径,默认为
ckman工作路径的conf目录下
- 本地文件的目录,需要填写路径,默认为
config_file- 本地文件的文件名,默认为
clusters
- 本地文件的文件名,默认为
# nacos
enabled- 是否开启
nacos - 默认为不开启
- 是否开启
hostsnacos服务的ip地址- 可以配置多组
portnacos服务的端口
user_name- 登录
nacos的用户名
- 登录
password- 登录
nacos的密码,需要加密,加密规则同持久化策略数据库密码加密规则
- 登录
namespace- 指定
nacos的namespace,默认为DEFAULT
- 指定
group- 向
nacos注册的服务所在的组 - 默认为
DEFAULT_GROUP
- 向
data_id- 向
nacos注册服务名称、数据项名称 - 默认为
ckman
- 向
示例如下:
nacos:
enabled: false
hosts:
- 127.0.0.1
port: 8848
user_name: nacos
password: 0192023A7BBD73250516F069DF18B500
#namespace:
#group:
#data_id:
2
3
4
5
6
7
8
9
10
# 参考文档
- https://github.com/housepower/ckman/blob/main/docs/ckman_v2.0.0.md
- https://github.com/housepower/ckman/blob/main/docs/guide/deploy.md
- 官方教学视频 clickhouse可视化管理工具ckman使用教程_哔哩哔哩_bilibili (opens new window)